其他配置
6.1 资源模型配置
背景介绍:内置的资源模型不满足公司对于资源纳管的需求,需要增加新的资源模型,并配置该资源模型与其他模型之间的关联关系。
整体步骤:新建模型分组——新建模型——设置模型字段和关联关系——模型使用
step1:新建模型分组
路径:管理-管理中心-资产模型管理
- 点击在“资源模型管理”界面点击“新建分组”按钮,在新建抽屉中填写分组的中英文名称即可,内置分组不允许修改和删除,自创分组允许修改中文名称和删除


step2:新建模型
路径:管理-管理中心-资产模型管理
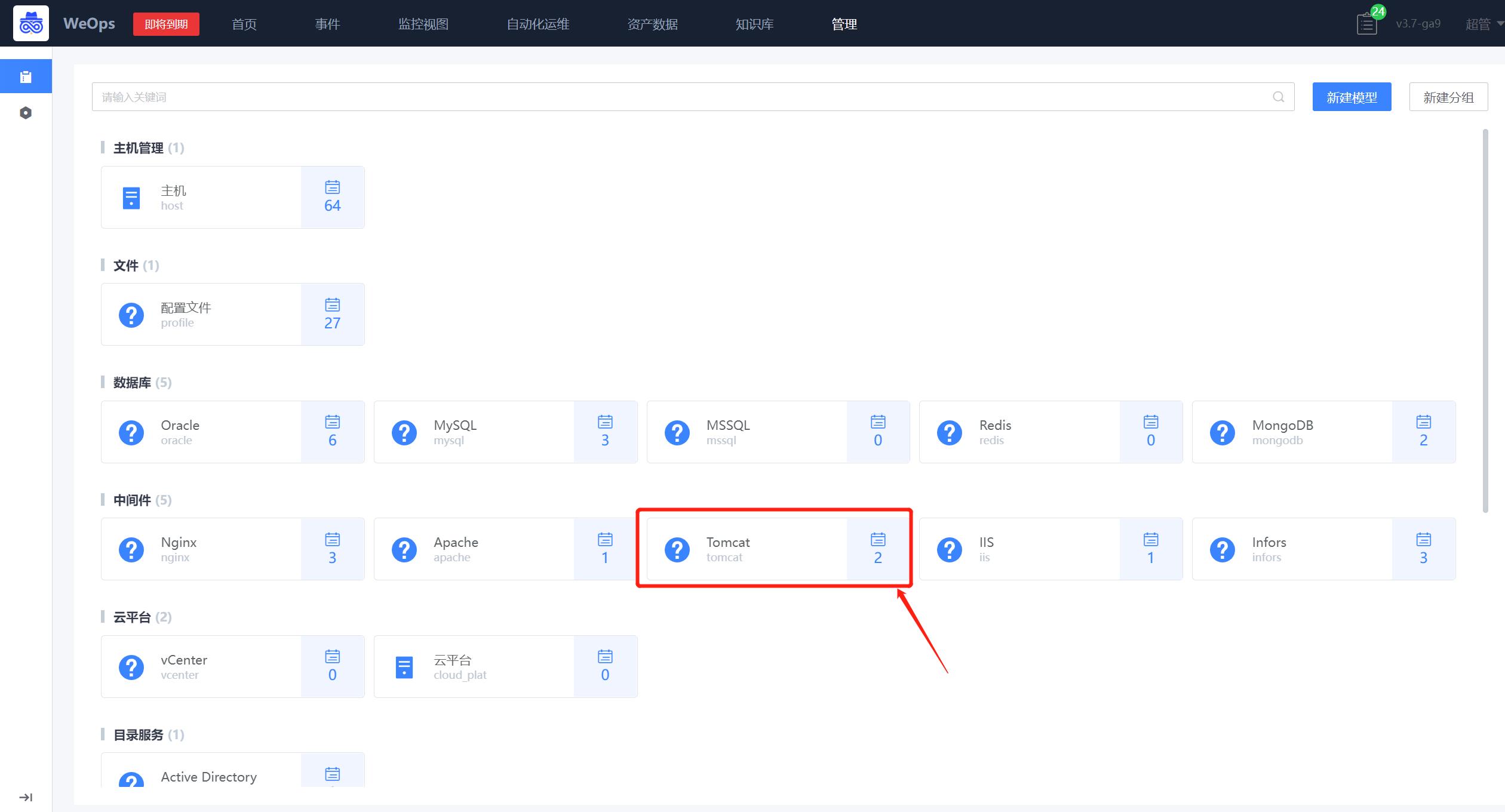
- 点击在“资源模型管理”界面点击“新建模型”按钮,在新建界面选择模型图标、模型分组,填写模型的标识和名称。


- 模型新建完成后,将在“WeOps-资产记录/主机/数据库/其他”中展示新建的模型tab
step3:填写模型属性字段和关联关系
路径:管理-管理中心-资产模型管理
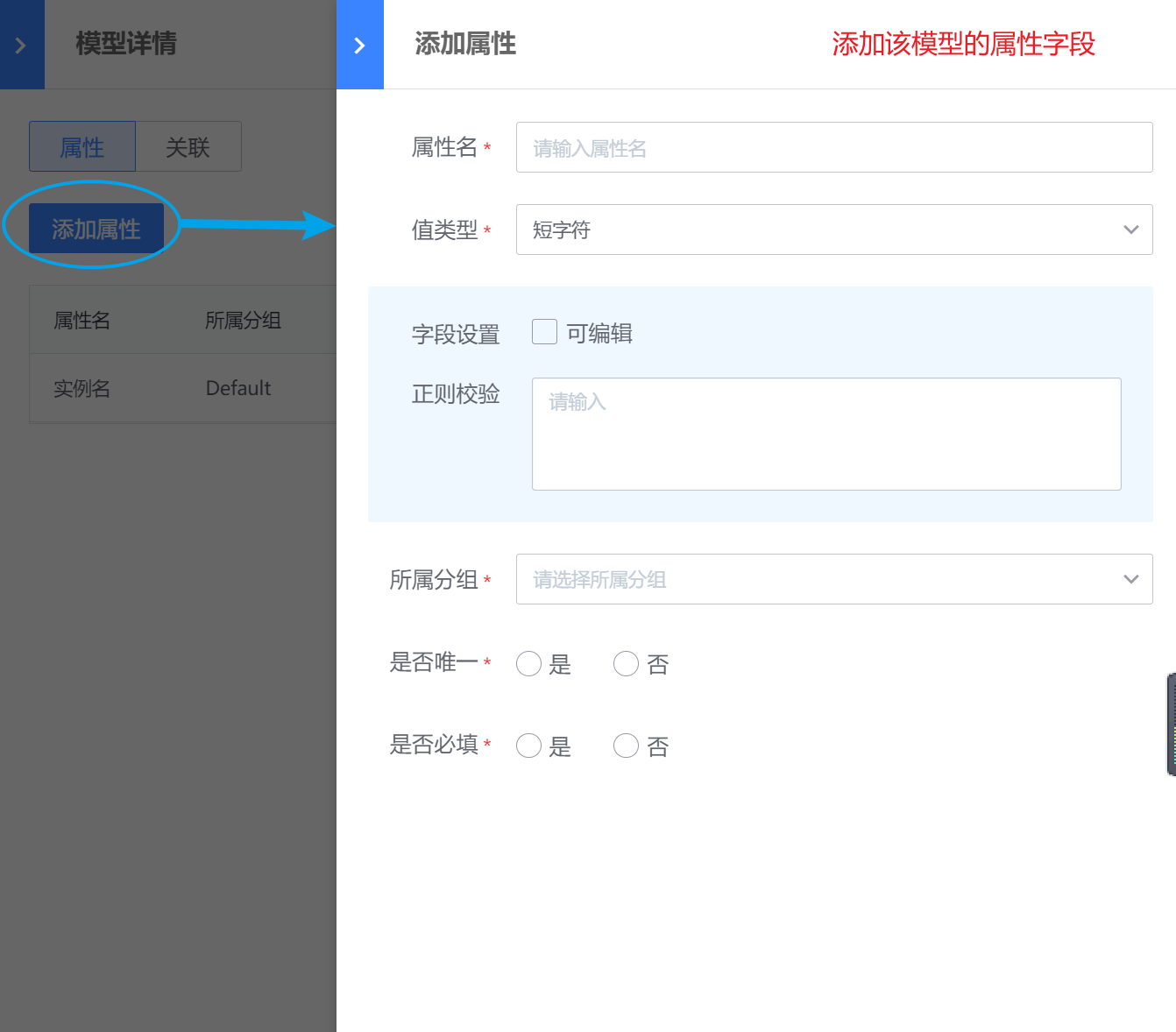
模型新建完成后,点击该模型图标,可以进行“属性”和“关联”新建和管理。
可以进行“属性”字段的新增和编辑,在后续为该模型增加实例时,这些属性字段将作为实例信息字段填写
进行“模型关联”模型关联建立后,可以在新建实例后,进行实例的关联建立。

step4:模型的使用
路径:资产数据-资产记录-对应模块
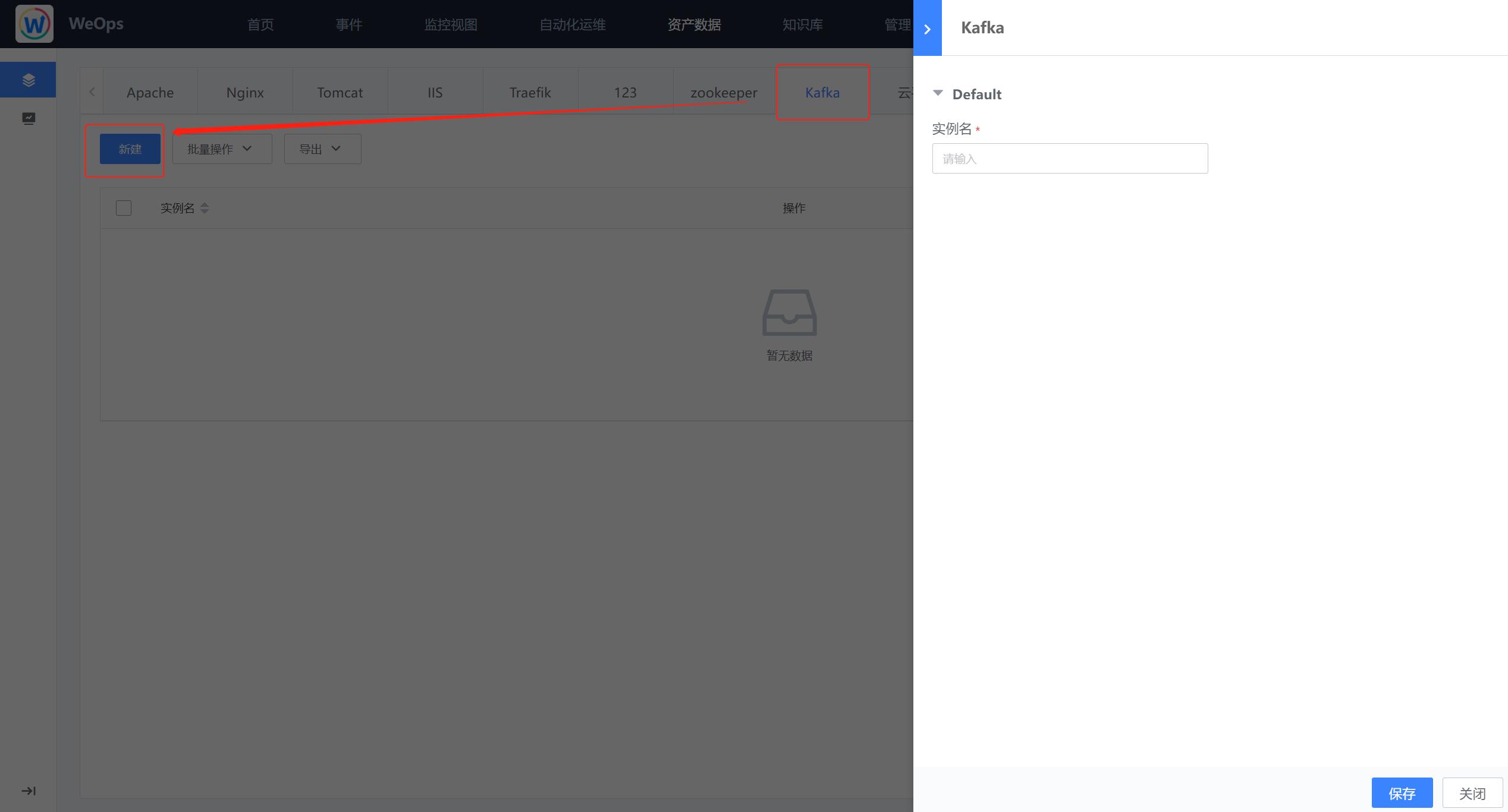
- 在资产记录中,找到新建的模型tab,点击“新建”按钮,可以进行实例的新增,这里需要填写的字段信息是在“资产模型管理-属性”中建立的属性字段。
- 在实例新建完成后,点击“查看”按钮,进入到实例的详情页,在“关联管理”中可以进行该实例与其他模型实例的关联关系的新建,这里可选择实例其他模型实例的关联关系与“资产模型管理-关联”中模型之间的关联关系一致。
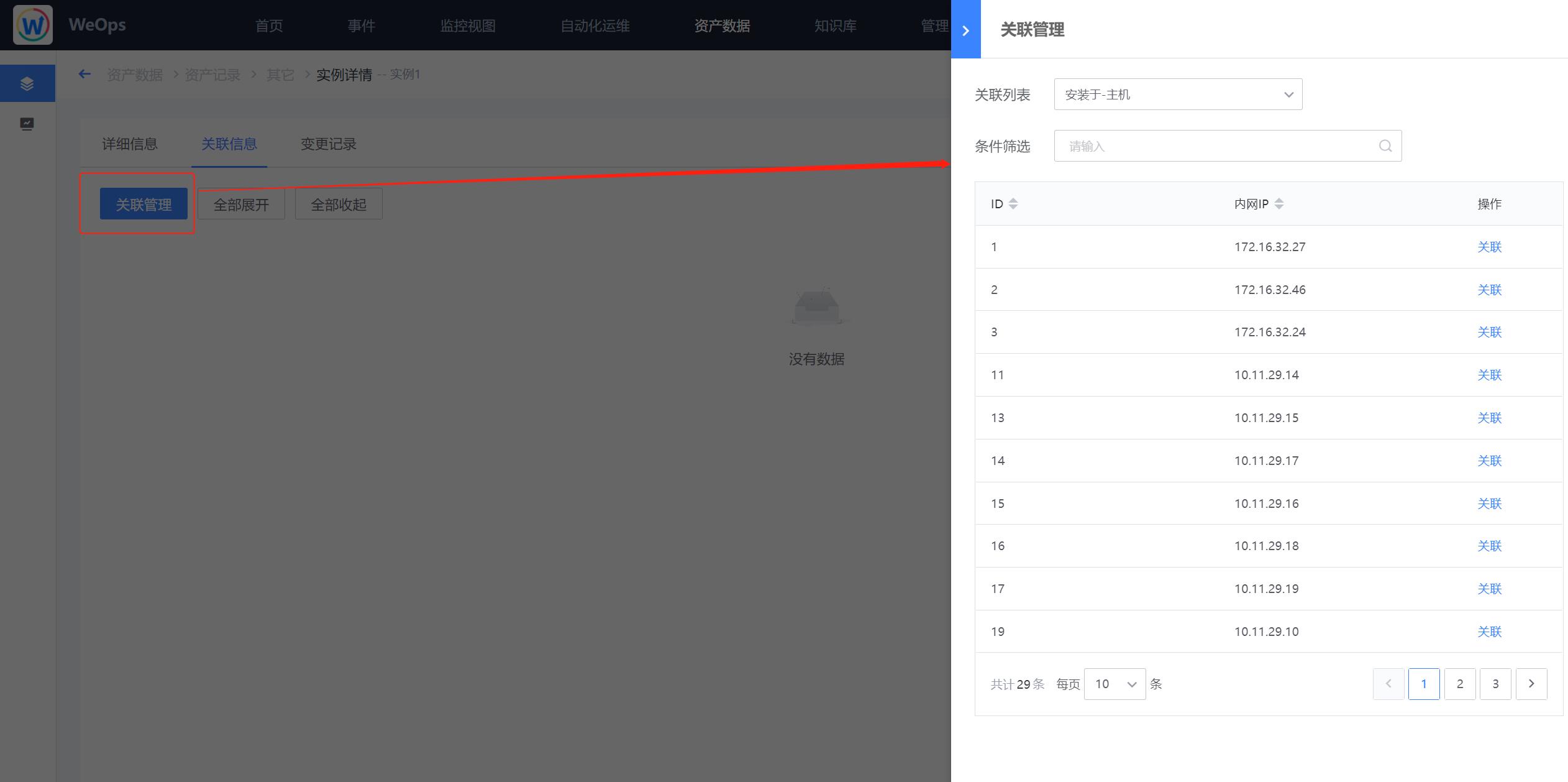
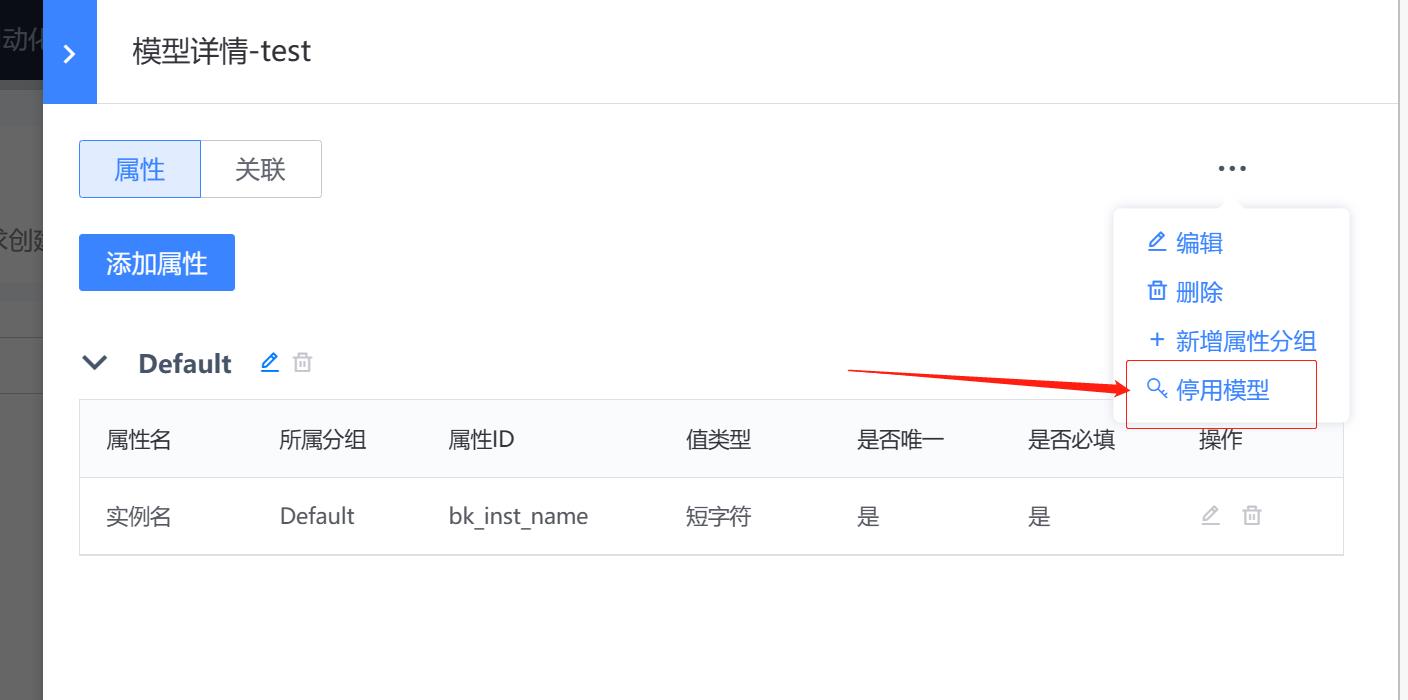
step5:模型的停用
路径:管理-管理中心-资产模型管理
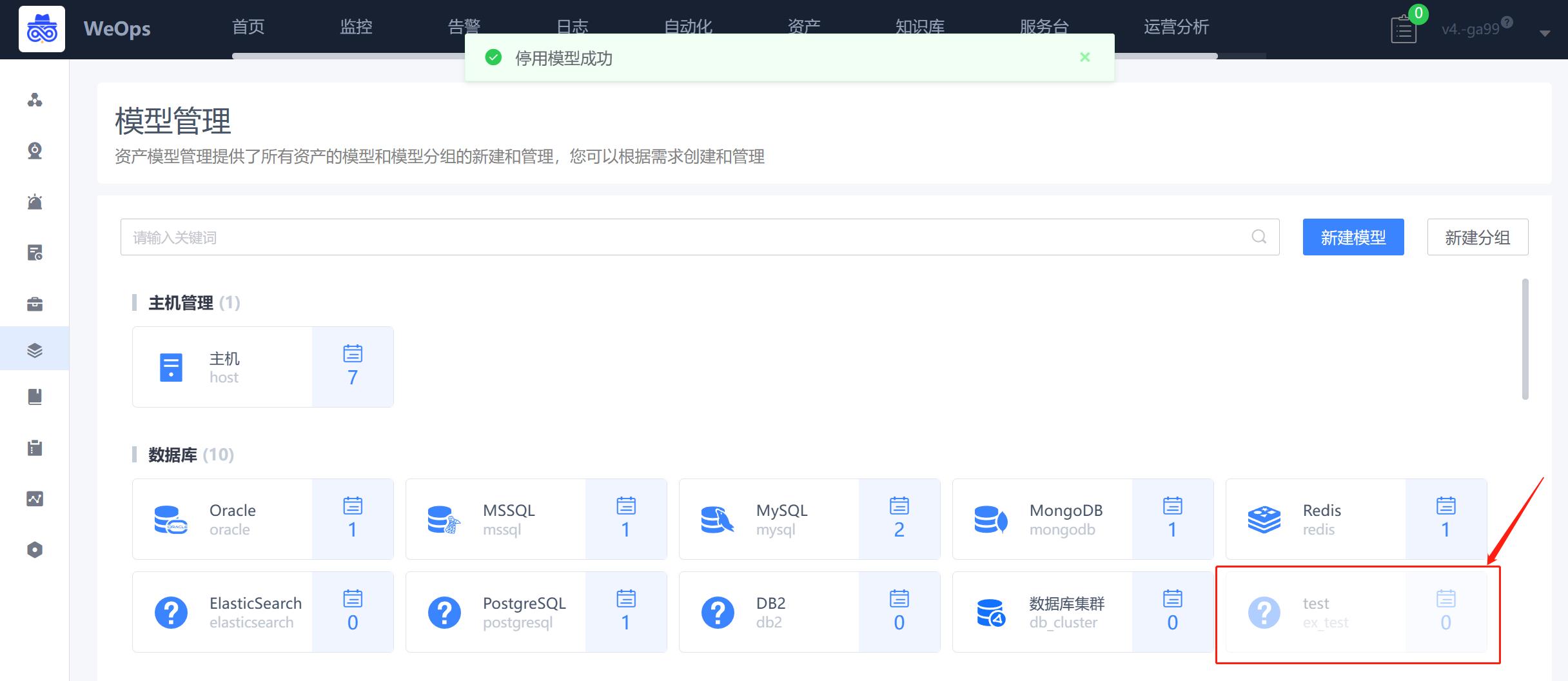
- 当该模型不再使用,支持对模型进行停用,停用后,在模型管理中变暗,同时在资产记录中该模型已经相关资产也不再显示。
6.2 云区域接入点指引
0x00 先决条件
WeOps接入点包括:
- Auto-Mate边缘节点
- WeOps-Proxy边缘节点
两个服务,这两个服务都通过docker拉起。
要求接入点服务器安装了20.10.23版本以上的docker。
需要开通以下网络策略:
| 源地址 | 目标地址 | 默认端口 |
|---|---|---|
| 接入点服务器 | 蓝鲸redis | 6379 |
| 接入点服务器 | 蓝鲸nginx | 80,443 |
| 接入点服务器 | WeOps consul | 8501 |
| 接入点服务器 | WeOps Promtheus | 9093 |
| 接入点服务器 | WeOps vault | 8200 |
| 蓝鲸APPO | 接入点服务器 | 8089 |
在接入点主机上,需能正常解析到蓝鲸的paas域名或写入了正确的hosts
Step1 部署服务
启动Automate服务,具体镜像tag视关联的WeOps版本/服务器cpu架构而定
在新的接入点操作
#!/bin/bash
# 创建日志目录并授权
mkdir -p /data/bkce/logs/automate/automate && chown -R 1001:1001 /data/bkce/logs/automate
# 输入预定义的环境变量
export PROMEHTEUS_URL={{WeOps的prometheus地址,如http://10.10.10.10:9093}}
export PROMETHEUS_USER={{WeOps的prometheus用户,默认admin}}
export PROMETHEUS_PWD={{WeOps的promtheus密码,默认admin}}
export APP_PORT={{Automate的监听端口,默认为8089}}
export REDIS_IP={{蓝鲸Redis的ip}}
export REDIS_PASSWORD={{蓝鲸Redis的密码}}
export REDIS_DB={{Redis使用的DB,注意不同接入点需要使用不同的DB,默认用11和14}}
export VAULT_URL={{WeOps Vault的url,如http://10.10.10.10:8200}}
export VAULT_ROOT_TOKEN={{WeOps Vault的token}}
export ACCESS_POINT_URL={{接入点自身的服务信息,如10.10.10.10:8089}}
export BK_DOMAIN_URL={{蓝鲸域名,需要确保能正常解析,如http://paas.weops.com/o/weops_saas}}
# 启动Auto-Mate容器
docker run -d --restart=always --net=host \
-e APP_PORT=8089 \
-e CELERY_BROKER=redis://:${REDIS_PASSWORD}@${REDIS_IP}:6379/11 \
-e CELERY_BACKEND=redis://:${REDIS_PASSWORD}@${REDIS_IP}:6379/14 \
-e VAULT_URL=${VAULT_URL} \
-e VAULT_TOKEN=${VAULT_ROOT_TOKEN} \
-e REDIS_URL=redis://:${REDIS_PASSWORD}@${REDIS_IP}:6379/14 \
-e WEOPS_PATH=${BK_DOMAIN_URL} \
-e PROMETHEUS_RW_URL=${PROMEHTEUS_URL} \
-e PROMETHEUS_USER=${PROMETHEUS_USER} \
-e PROMETHEUS_PWD=${PROMETHEUS_PWD} \
-e ACCESS_POINT_URL=${ACCESS_POINT_URL} \
-e ENABLE_OTEL=false \
-v /data/bkce/logs/automate:/app/logs \
--name=auto-mate docker-bkrepo.cwoa.net/ce1b09/weops-docker/auto-mate:v1.0.14
启动WeOps Proxy服务,具体镜像tag视关联的WeOps版本/服务器cpu架构而定
在新的接入点操作
#!/bin/bash
# 创建需要的目录并授权
mkdir -p /data/weops/proxy
mkdir -p /data/bkce/logs/weopsproxy
chown -R 1001:1001 /data/bkce/logs/weopsproxy
# 输入预定义的环境变量
export PROMEHTEUS_URL={{WeOps的prometheus地址,如http://admin:admin@10.10.10.10:9093}}
export CONSUL_URL={{weops proxy的consul ip, 如http://10.10.10.10:8501}}
# 启动WeOps Proxy容器
docker run -d -e CONSUL_ADDR=${CONSUL_URL} \
-e REMOTE_URL=${PROMEHTEUS_URL} \
--net=host --restart=always --name=weops-proxy \
-v /data/bkce/logs/weopsproxy:/app/log \
docker-bkrepo.cwoa.net/ce1b09/weops-docker/weopsproxy:1.0.3
Step2 注册接入点
注册新建的接入点到weops
在蓝鲸的APPT服务器操作
#!/bin/bash
# 输入预定义的环境变量
export ACCESS_POINT_URL={{接入点自身的服务信息,如10.10.10.10:8089}}
export ACCESS_POINT_DESC={{接入点的描述,如阿里云-香港接入点}}
export CONSUL_URL={{weops proxy的consul ip, 如http://10.10.10.10:8501}}
export ZONE={{接入点所属的云区域ID,如蓝鲸的云区域默认为0}}
# 生成接入点的uuid
export UUID=$(uuid)
proxy_url="${CONSUL_ADDR}/v1/kv/weops/access_points/${UUID}"
req=$(cat << EOF
{
"ip":"${ACCESS_POINT_URL}",
"name":"${ACCESS_POINT_DESC}",
"zone":"${ZONE}",
"port": 8089
}
EOF
)
# 注册接入点到consul
curl --request PUT --data "$(jq -r <<<$req)" $proxy_url
# 检查接入点是否注册成功
curl --request GET $proxy_url | jq -r .[].Value| base64 -d
6.3 凭据的配置和使用
背景介绍:运维管理员统一管理资产的凭据,并且在使用时可以快捷的选择已经保存的凭据,目前支持主机/AD两类凭据的管理和使用。
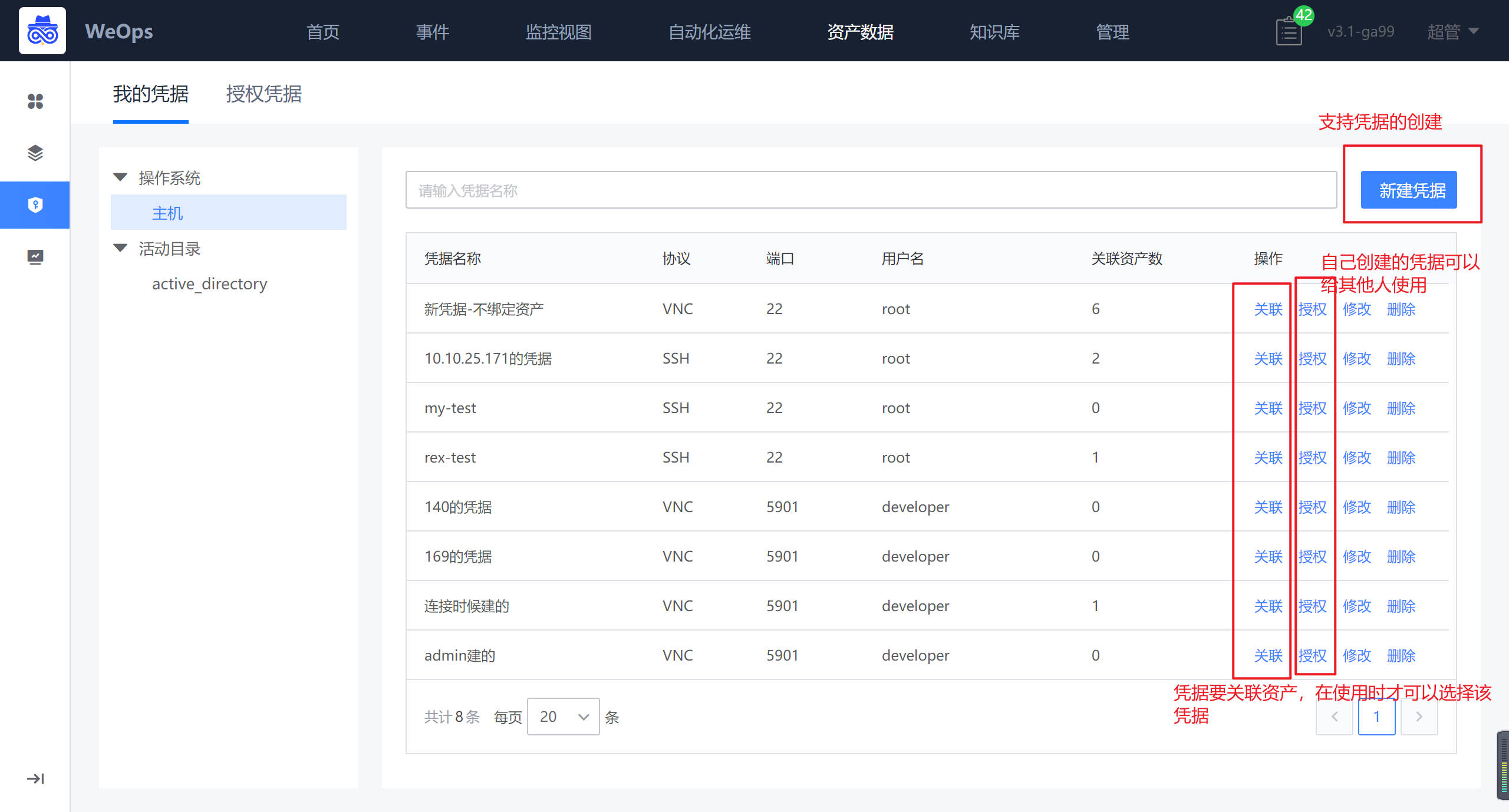
创建凭据
路径:资产数据-凭据管理-我的凭据
支持主机/AD/网络设备的凭据新建,主机支持SSH/RDP/VNC协议、AD支持LDAP/LDAPS协议,创建的凭据需要关联资产,对应的资产才可以使用这条凭据。(注:网络设备不需要关联资产)

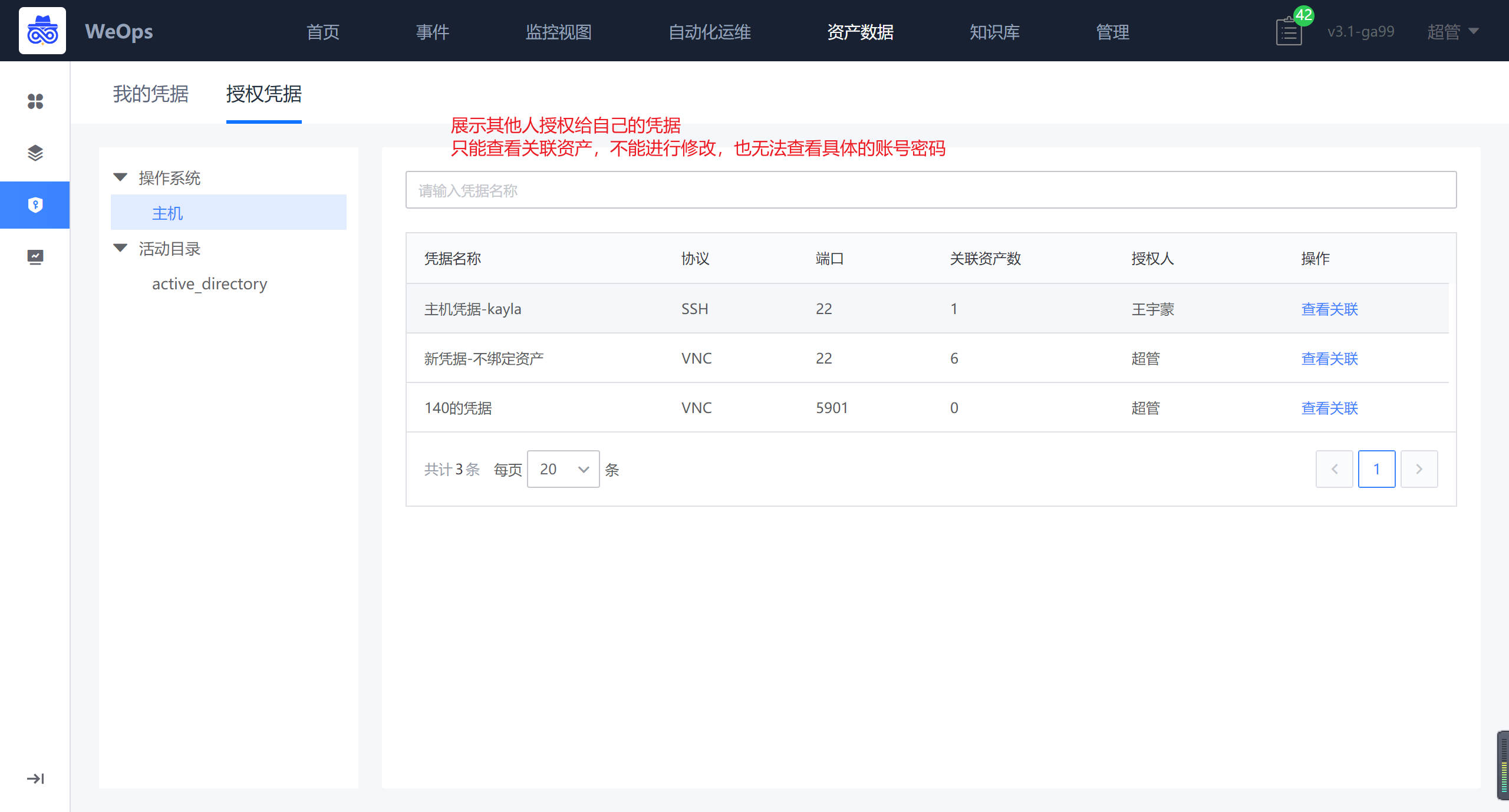
授权凭据
路径:资产数据-凭据管理-授权凭据
展示其他人授权给自己的凭据。
凭据使用
用户可以在某个资产使用的凭据场景包括两类:一类是自己创建的凭据,并且这个资产已经绑定凭据;另一类是别人把创建的凭据授权给自己,且这个凭据绑定了这个资产。
主机凭据使用有如下两个途径:在资产列表-主机中,可以点击“远程连接”快捷选择已有的凭据进行远程连接;在告警——告警详情中,若是主机产生了告警,可以快捷使用已经的凭据进行远程连接。使用ssh协议时,要求对端的ssh服务器运行使用rsa密钥,如果ssh版本高于8,需将HostKeyAlgorithms +ssh-rsa添加到/etc/ssh/sshd_config中
AD的凭据使用:AD目前使用在weops-内置的自动化工单流程中,作为AD账号创建/修改/禁用/删除的前置条件,具体的自动化工单流程可详见“内容说明——7、内置的工单流程”
网络设备的凭据使用:设置自动发现网络设备的时候可以使用已有的网络设备凭据,设置网络设备监控采集的时候可以使用已有的网络设备凭据。
云平台的凭据使用:设置自动发现网络设备的时候可以使用已有的网络设备凭据,设置网络设备监控采集的时候可以使用已有的网络设备凭据。
6.4 知识库配置
背景介绍:对知识库文章的标签进行管理,若需要重复撰写同类文章通过新建文章模型的形式实现。
整体步骤:管理标签——管理模板
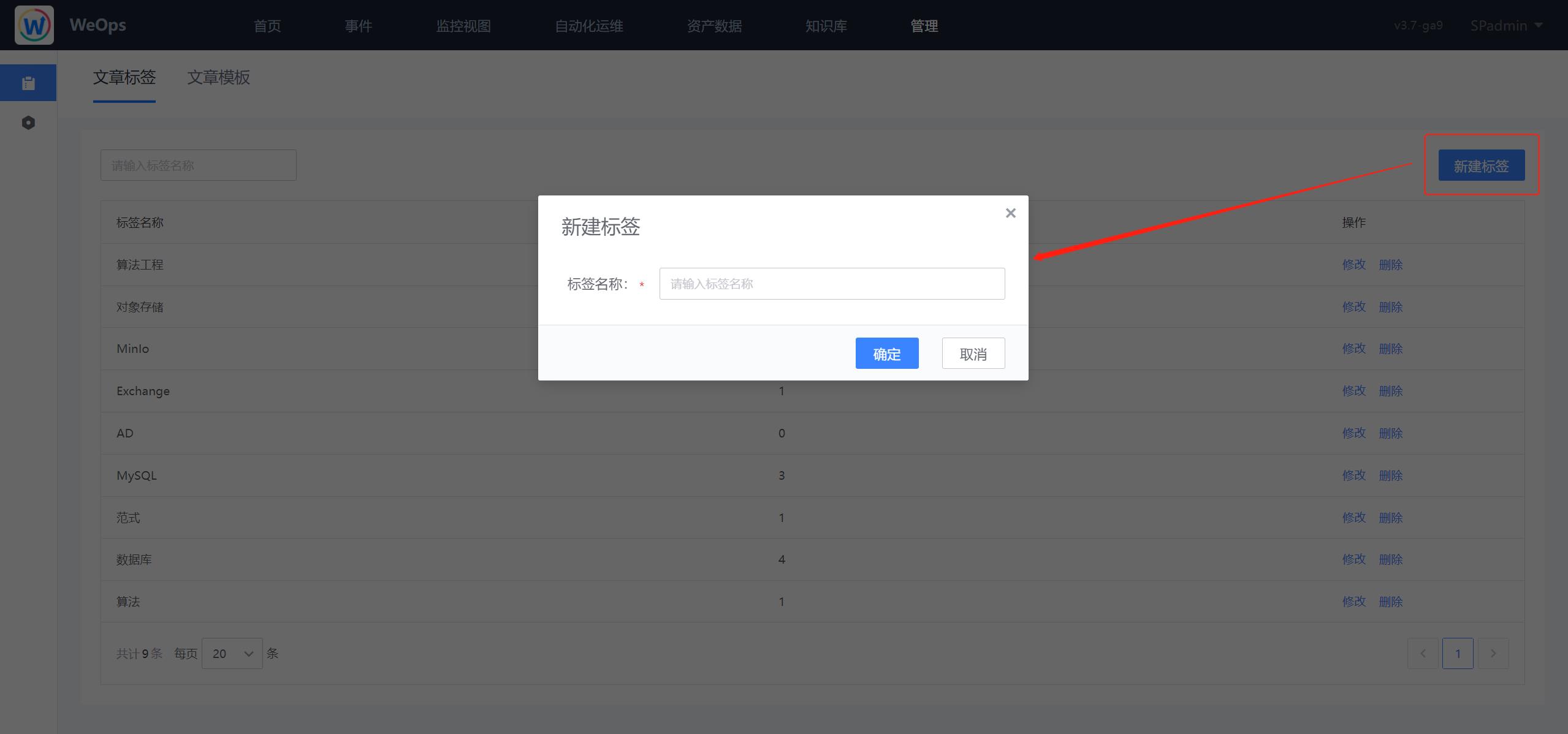
管理标签
路径:管理-管理中心-知识库管理-文章标签
- 在“知识库管理”中可以对标签进行新增/编辑/修改,也可以查看各类标签的引用情况。知识库所有的标签可被文章撰写/模板撰写所引用。
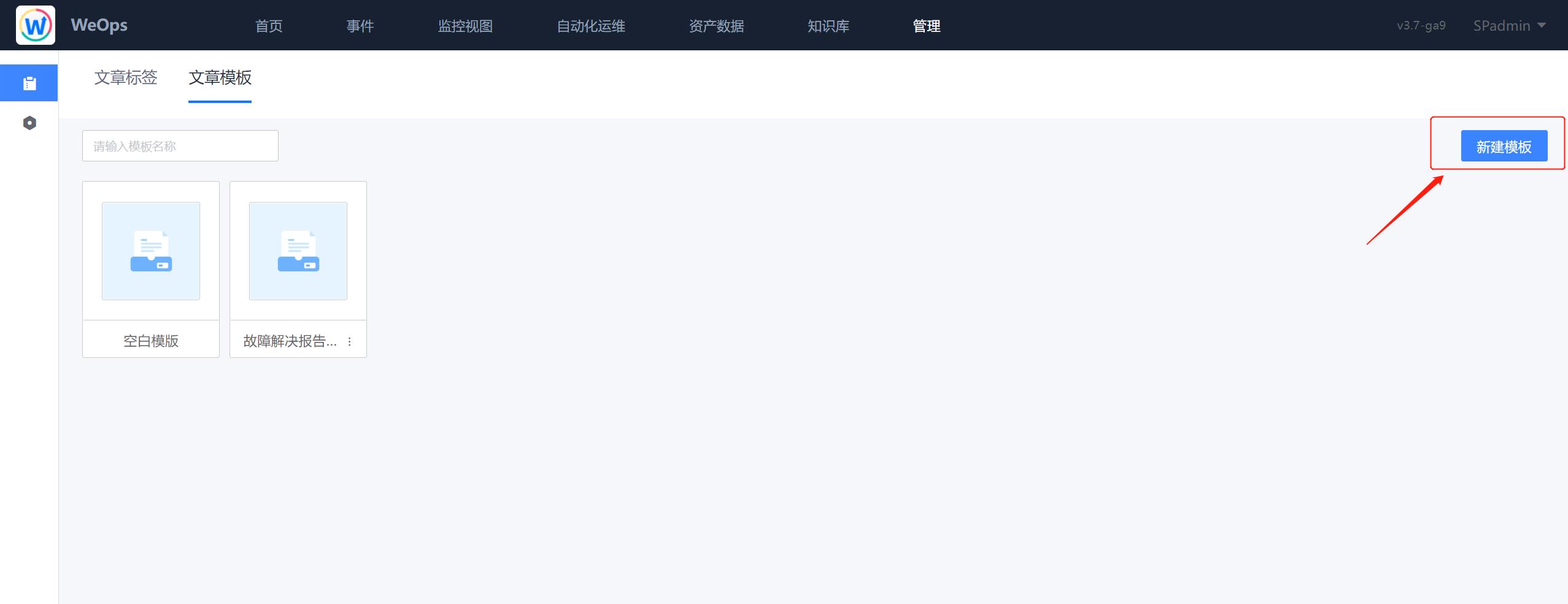
管理模板
路径:管理-管理中心-知识库管理-文章模板
在“知识库管理”中可以对模板进行新增/编辑/修改,知识库所有新建的模板可以在“写文章”时被使用。
点击“新建模板”可以进行模板的创建,创建模板的时候可以上传图片作为模板封面。
6.5 高级仪表盘配置
背景介绍:运维人员需要在仪表盘中配置并查看监控、告警、ITSM、日志等功能模块的数据,默认的组件和数据无法支持选择时,可以通过撰写Trino语句的方式,进行高级仪表盘的配置和使用
整体步骤:选择仪表盘组件→填写Trino语句→配置组件显示项
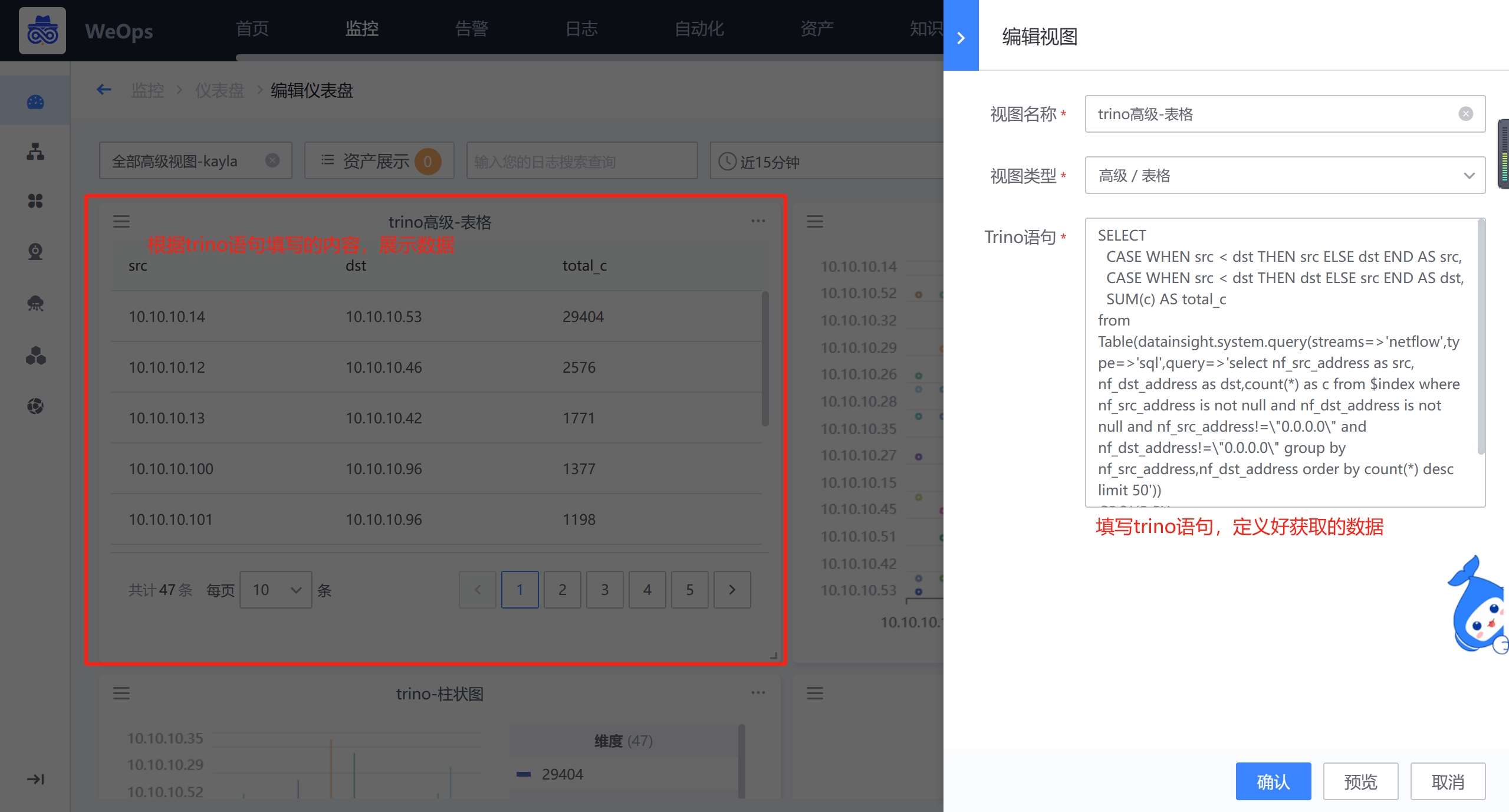
表格/单值
高级组件的表格和单值只需要填写Trino语句,在Trino中定义好需要获取的数据,就会以表格/单值的形式呈现
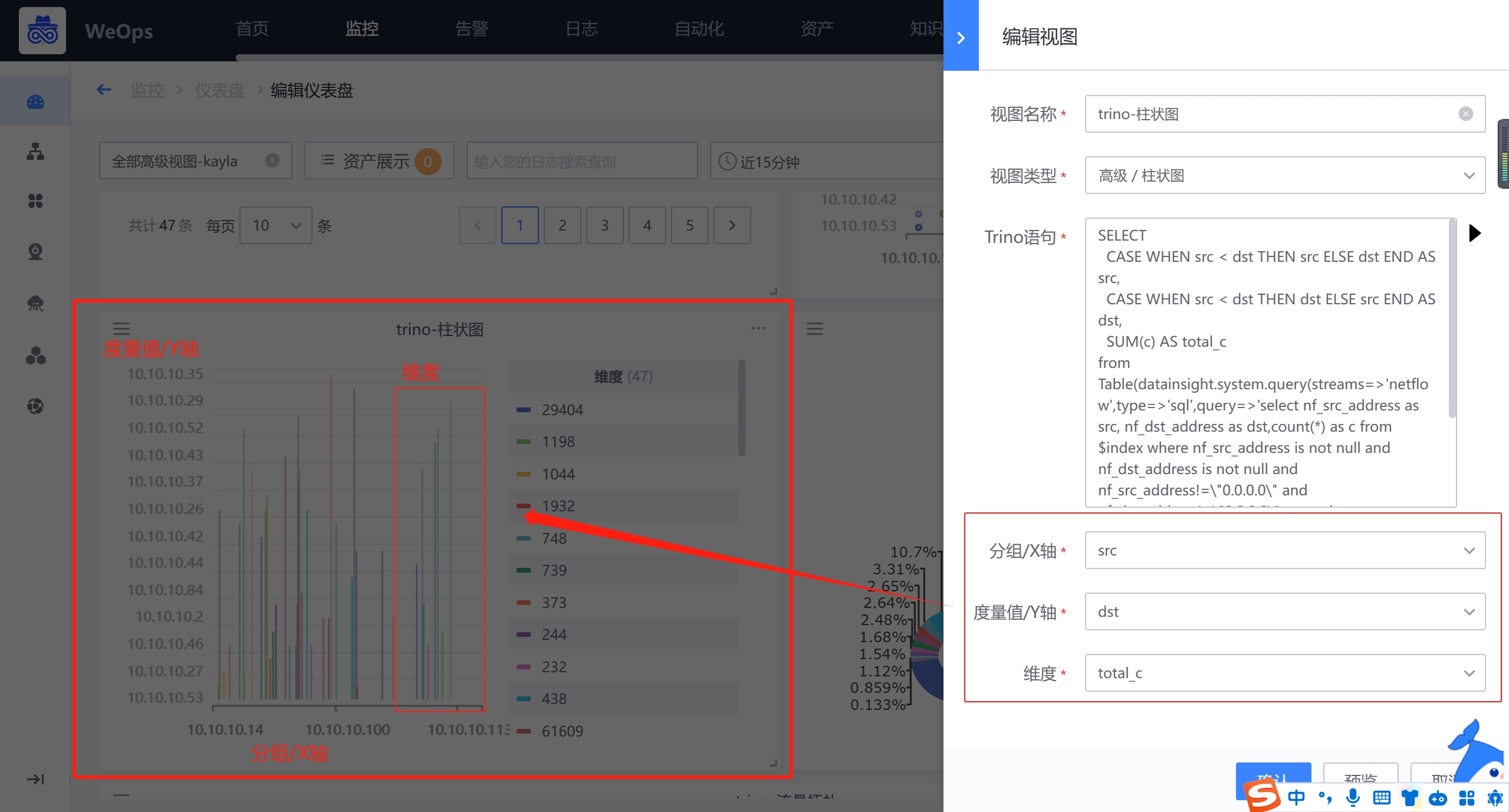
折线图/柱状图
高级组件的折线图和柱状图主要展示各个分组的变化情况,需要填写Trino语句,点击执行从Trino语句获取返回字段,选择成为分组/X轴,度量/Y轴和维度信息,以便使用
分组/X轴:就是类别,为折线图和柱状图的X轴,呈现各个分组情况。比如告警的所属应用,每个应用就是一个分组。
度量/Y轴:就是数值,为折线图和柱状图的Y轴,展示各个分组的具体的值的情况。比如告警的处理时长,展示每个应用的告警处理时长。
维度:当分组的数值有多种情况时,需要选择展示维度,比如告警区分优先级,需要分开展示每个应用致命/预警/提醒三个等级的处理时长
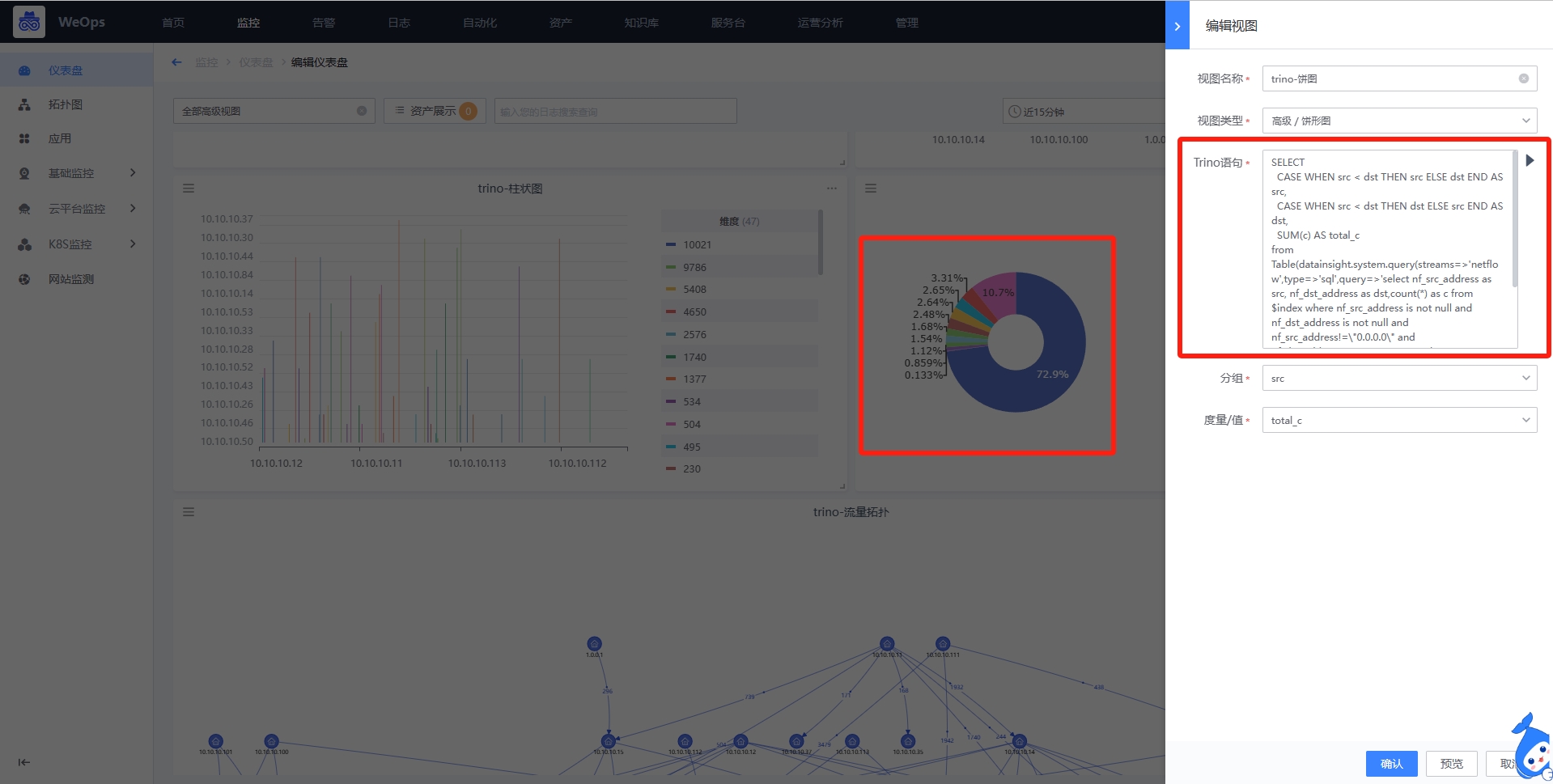
饼形图
高级组件的饼形图主要展示各个类别的百分比,需要填写Trino语句,点击执行从Trino语句获取返回字段,并且选择成为分组、度量值。
分组:就是类别,呈现各个分组情况,饼形图的每一块就是一个分组。比如分组是IP地址
度量值:就是数值,展示各个分组的具体的值的百分比情况,比如数值是IP地址的数量,则饼形图则表示所有IP地址数量的百分比。
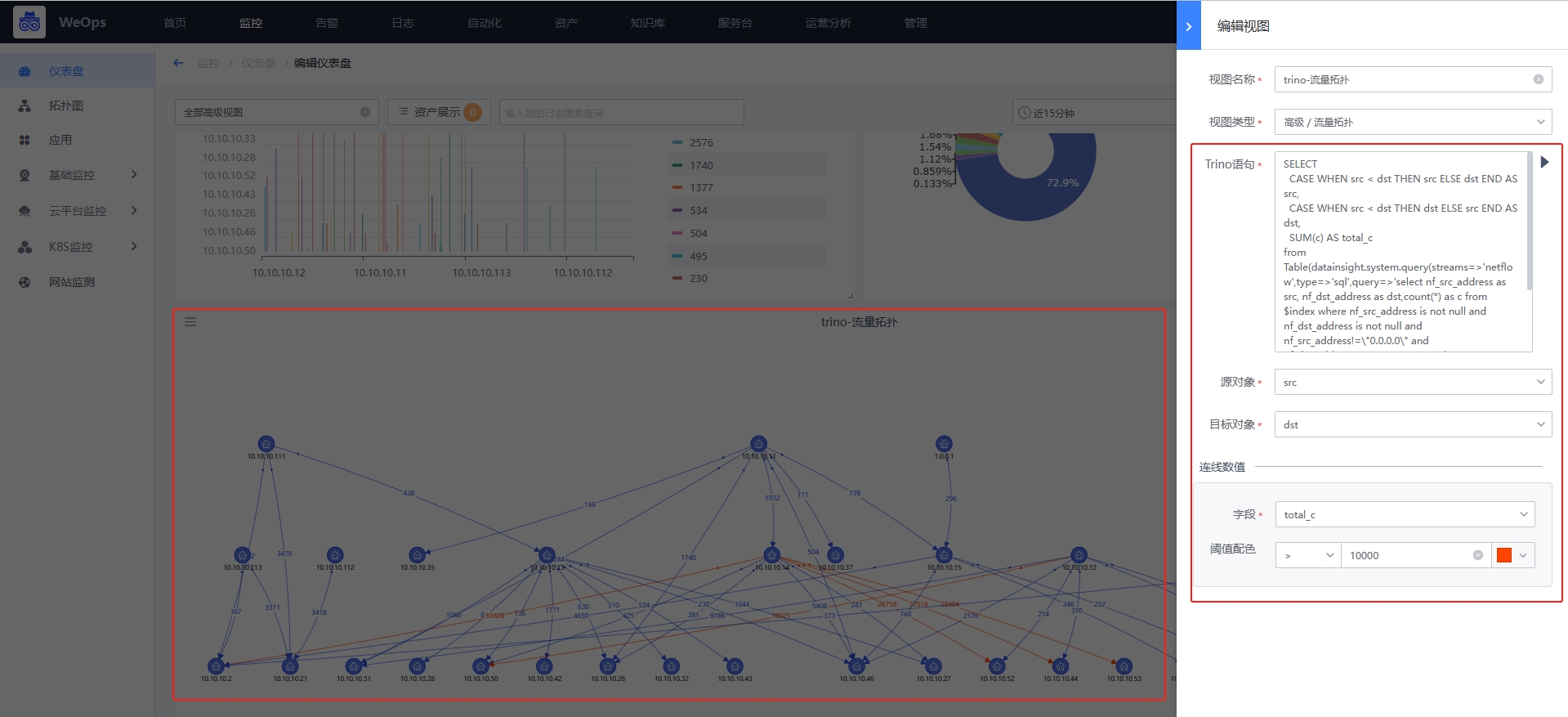
流量拓扑图
高级组件的流量拓扑图主要展示源和目标直接的流向关系,需要填写Trino语句,点击执行从Trino语句获取返回字段,并选择为源对象、目标对象,以及连线上的数值
源对象:即开始的对象,比如网络五元组中的源IP
目标对象:结束的对象,比如网络五元组中的目标IP
连线数值:连线上面的数值(从源到目标的数值),比如从源IP到目标IP直接响应时长的数值等
桑基图
高级组件的桑基图主要展示源和目标直接的流量大小情况,需要填写Trino语句,点击执行从Trino语句获取返回字段,并选择为源对象、目标对象,以及度量值
源对象:即开始的对象,比如网络五元组中的源IP
目标对象:结束的对象,比如网络五元组中的目标IP
度量值:度量值决定了连线的宽窄,越宽说明流量/数值越大

Trino语句的撰写示例具体如下
Trino语法官网为:https://ta.thinkingdata.cn/trino-docs/sql/select.html
(1)时间配置
在撰写Trino语句时,定义好$DATE_START$,$DATE_ END$,仪表盘的时间选择器就对该组件的时间范围生效。
select
count(*) as ticket_run
from
bk_itsm.ticket_ticket
where
current_status NOT IN ('FINISHED',REVOKED',DRAFT')
AND DATE FORMAT (create at,Y-%m-d')>=$DATE_START$
AND DATE_FORMAT (create_at,'%Y-%m-名d')<=$DATE _END$
WeOps对常用的场景进行了封装,封装的汇总表如下
| 模块 | 函数名 | 数据源 | 支持参数过滤 | 返回值 | 介绍 |
|---|---|---|---|---|---|
| 资产 | 查询资产列表 | mongodb | 模型ID、所属应用、属性值 | 资产列表,包含资产的字段信息和所属应用 | 支持通过该函数快速筛选出指定模型和要求的资产列表,例如:所有蓝鲸应用下bk_os_type属性为Linux的主机 |
| 告警 | 查询告警列表 | es | 时间段、所属应用、对象类型、告警状态、告警等级 | 告警列表,包含WeOps告警详情的告警信息、对象信息、策略信息、处理信息 | 支持通过该函数快速筛选出告警列表,例如:15-17日,所有蓝鲸应用未关闭的危险告警 |
| IT服务台 | 查询工单列表 | mysql | 提单时间段、服务名称、工单状态 | 工单列表,包含工单标题、工单号、服务名称等ITSM工单列表页能看到的信息 | 支持通过该函数快速筛选出工单列表,例如:15-17日,所有笔记本申请服务的已完成工单 |
| 监控 | 查询agent信息 | mysql | agent状态、主机名、操作系统类型、biz id、云区域id | 主机配置信息,主机名称、inner_ip、业务id、云id、agent状态、操作系统类型 | 查看主机agent状态信息,筛选出不正常的agent,操作系统为LINUX的主机 |
| 监控 | 查询监控指标 | influxdb | 对象、data id、时间段 | 查看监控指标情况,支持日期时间聚合,计算最大、最小、平均值。 |
(2)CMDB资产
- 原始功能:语法复杂,不建议使用
SELECT
*
FROM
TABLE (
mongodb.system.query (
database=>'cmdb',
collection=>'cc_objectbase_0_pub_k8s_namespace',
filter=>'{ bk_inst_name: {$regex: "ch"}}'
)
);
- 封装场景:可以直接使用封装后的,编写简单
封装功能说明: fields选择字段,regex填写正则匹配字段,database可不填写,默认会选择cmdb数据库。
bk_obj_id: cmdb中的对象ID
fields: CMDB中资产对应字段
regex: 在选择的fields字段中进行模糊查询
例1: 查询交换机中品牌为华为的资产信息
SELECT
*
FROM
TABLE (
mongodb.system.get_inst (
database=>'cmdb',
bk_obj_id=>'bk_switch',
fields=>'brand',
regex=>'华为'
)
);
例2: 查询主机中操作系统为linux的资产信息
SELECT
*
FROM
TABLE (
mongodb.system.get_inst (
bk_obj_id=>'host',
fields=>'bk_os_name',
regex=>'linux'
)
);
例3: 查询业务名和id 只需要出现biz字段并且不填''空即可触发
SELECT
*
FROM
TABLE (mongodb.system.get_inst (biz=>'biz'));
(3)告警列表
- 原始功能:语法复杂,不建议使用
SELECT *
FROM TABLE (
elasticsearch.system.raw_query(
schema => 'default',
index => 'cw_uac_alarm_event',
query => '{
"query": {
"bool": {
"must": [
{
"range": {
"alarm_time": {
"gte": "' || CONCAT($DATE_START$, ' 00:00:00') || '",
"lte": "' || CONCAT($DATE_END$, ' 23:59:59') || '"
}
}
}
],
"must_not": [
{
"term": {
"status": "converged"
}
}
]
}
},
"size": 0,
"track_total_hits": true
}'
)
)
)
- 封装场景:可以直接使用封装后的,编写简单
查询对应时间段、所属应用、对象类型、告警状态、告警等级的告警信息。
schema:
index:es告警索引
bk_obj_id: 蓝鲸对象ID
size: 返回数据大小(条)
bk_biz_id: 业务ID
alarm_level: 告警等级,
alarm_status:告警状态
start_time: 起始时间
end_time: 结束时间
SELECT
*
FROM
TABLE (
elasticsearch.system.alarm_info (
schema=>'default',
index=>'cw_uac_alarm_event',
bk_obj_id=>'host',
size=>'3',
bk_biz_id=>'2',
alarm_status=>'restored',
alarm_level=>'fatal',
start_time=>'2023-09-04 02:45:51',
end_time=>'2023-09-04 03:45:51'
)
);
(4)ITSM工单
- 原始功能:语法复杂,不建议使用
已支持mysql原生sql
query: mysql原生sql语句,注意不能用;结尾,mysql会自动添加该结尾符。
SELECT
*
FROM
TABLE (
mysql.system.query (
query=>'SELECT ticket.* FROM bk_itsm.ticket_ticket AS ticket JOIN bk_itsm.service_service AS service where ticket.service_id = service.id'
)
);
- 封装场景:可以直接使用封装后的,编写简单
查询某时间段、服务名称、具体状态的工单。
scene: ticket_filter 工单过滤场景
service_name: 服务名称
ticket_status: 工单状态,支持多状态,以,作为分隔
start_time: 起始时间,取工单创建时间
end_time: 结束时间,取工单创建时间
SELECT
*
FROM
TABLE (
mysql.system.custom (
scene=>'ticket_filter',
service_name=>'工单',
ticket_status=>'FINISHED, REVOKED',
start_time=>'2023-08-11 20:00:00',
end_time=>'2023-09-11 10:00:00'
)
);
SELECT
*
FROM
TABLE (
mysql.system.custom (
scene=>'ticket_filter',
service_name=>'审批',
ticket_status=>'',
start_time=>'2023-08-01',
end_time=>'2023-09-12'
)
);
(5)监控
5.1 查找业务名称
填写biz字段不为空即可
SELECT
bk_biz_name
FROM
TABLE (mongodb.system.get_inst (biz=>'biz'));
5.2 统计主机agent状态
scene: 固定场景,目前只支持 host_agent_info 主机agent状态
host_name: 主机名称
agent_status: agent状态
host_os_type: 操作系统类型
bk_biz_id: 业务ID
cloud_id:云区域ID
SELECT
*
FROM
TABLE (
mysql.system.custom (
scene=>'host_agent_info',
host_name=>'',
agent_status=>'RUNNING, NOT_INSTALLED, TERMINATED',
host_os_type=>'LINUX, WINDOWS',
bk_biz_id=>'1, 2',
cloud_id=>'0'
)
);
5.3 监控指标
- 原始功能:语法复杂,不建议使用
SELECT
time,
usage,
nice
FROM
TABLE (
influxdb.system.raw_query (schema=>'system',
index=>'cpu_summary',
query=>'
SELECT
mean(usage) as usage,
max(usage) as nice
FROM
cpu_summary limit 10'
)
);
以下是低负载报表中用到的场景
SELECT
usage,
nice
FROM
TABLE (
influxdb.system.raw_query (
schema=>'system',
index=>'cpu_summary',
query=>'
SELECT
mean(usage) as usage,
max(usage) as nice
FROM
cpu_summary
GROUP BY
hostname,
ip,
bk_cloud_id,
bk_biz_id
'
)
);
注意group_by是额外聚合的字段,建议使用time(1h),每小时,否则数据量过多性能会较差,如果使用到time(1h)这种额外的时序聚合,需要再次对数据进行聚合过滤等操作,比如在低负载报表中是这样处理的:
WHERE
EXTRACT(
HOUR
FROM
time
) BETWEEN $TIME_START$
AND $TIME_END$
注意! influxdb查询中如果在query里面更改了字段名,选择字段需要注意不能用*,必须用sql会返回的字段。 因为字段问题可能会报错Cannot invoke "java.lang.Integer.intValue()" because the return value of "java.util.Map.get(Object)" is null
一般的插件监控指标字段含有
time
bk_biz_id
bk_cloud_id
bk_collect_config_id
bk_supplier_id
bk_target_cloud_id
bk_target_ip
ip
metric_name 指标名称
metric_value 指标值
指标的维度名称会作为额外字段,这类字段随指标动态变化就不写在上方,需自行识别。
- 封装场景:可以直接使用封装后的,编写简单
封装场景中select后都不能使用*
scene: 场景,支持host主机性能,plugin 监控探针
schema:数据库名
index: 表名
metric:指标ID名称(英文)
function: 必填否则报错,influxdb计算功能,支持min、max、mean
时间范围需满足起始时间和结束时间,否则默认使用7天内的时间范围。
start_time: 起始时间
end_time: 结束时间
① 监控插件指标
注意!schema处需要手动添加字段,比如监控exporter类的需要添加exporter_
SELECT
metric_value
FROM
TABLE (
influxdb.system.raw_query (
scene=>'plugin',
schema=>'exporter_weops_postgres_exporter',
index=>'lock',
metric=>'pg_locks_count',
function=>'mean',
start_time=>'2023-09-20T14:12:56Z',
end_time=>'2023-09-21T15:12:56Z'
)
);
② 主机性能
主机性能表固定为
system
主机性能指标表名
cpu_detail
cpu_summary
disk
env
inode
io
load
mem
net
netstat
proc
proc_port
swap
半封装场景
SELECT
time,
hostname,
ip,
bk_cloud_id,
bk_biz_id,
nice
FROM
TABLE (
influxdb.system.raw_query (
scene=>'host',
schema=>'system',
index=>'cpu_summary',
metric=>'nice',
function=>'max',
group_by=>'time(1h)',
start_time=>'2023-09-01T14:12:56Z',
end_time=>'2023-09-18T15:12:56Z'
)
);
③ cpu性能指标(已封装)
scene填入host,metric填入cpu_info则是计算cpu_usage的值
默认group_by字段为hostname, ip, bk_cloud_id, bk_biz_id
SELECT
time,
hostname,
ip,
bk_cloud_id,
bk_biz_id,
usage
FROM
TABLE (
influxdb.system.raw_query (
scene=>'host',
metric=>'cpu_info',
function=>'max',
group_by=>'time(1h)',
start_time=>'2023-09-01T14:12:56Z',
end_time=>'2023-09-18T15:12:56Z'
)
);
SELECT
hostname,
ip,
bk_cloud_id,
bk_biz_id,
usage
FROM
TABLE (
influxdb.system.raw_query (
scene=>'host',
metric=>'cpu_info',
function=>'mean'
)
);
④ 内存性能指标(已封装)
scene填入host,metric填入memory_info则是计算pct_used的值
默认group_by字段为hostname, ip, bk_cloud_id, bk_biz_id
SELECT
time,
hostname,
ip,
bk_cloud_id,
bk_biz_id,
pct_used
FROM
TABLE (
influxdb.system.raw_query (
scene=>'host',
metric=>'memory_info',
function=>'max',
group_by=>'time(1h)',
start_time=>'2023-09-01T14:12:56Z',
end_time=>'2023-09-18T15:12:56Z'
)
);
SELECT
hostname,
ip,
bk_cloud_id,
bk_biz_id,
pct_used
FROM
TABLE (
influxdb.system.raw_query (
scene=>'host',
metric=>'memory_info',
function=>'max',
start_time=>'2023-09-01T14:12:56Z',
end_time=>'2023-09-18T15:12:56Z'
)
);
(6)日志
支持对datainsight数据源查询,query内容支持sql模式,可参考https://opensearch.org/docs/1.1/search-plugins/sql/index/
语法为
Table(datainsight.system.query(streams=>'stream_name',type=>'sql',query='sql_str'))streams:对应datainsight的消息流,即weops的日志分组。可支持传一个或多个,
,号进行分隔,如netflow,http也可以传空
'',代表所有消息流(不建议,性能相对较差)type:目前支持sql模式(ppl模式也支持,但仅限于单消息流,不支持多个和为空)
query:
$index为固定写法,即opensearch的索引概念,如了解索引名也可以写对应索引,否则从填写的streams中获取sql模式语法为
SELECT [DISTINCT] (* | expression) [[AS] alias] [, ...]
FROM $index
[WHERE predicates]
[GROUP BY expression [, ...]
[HAVING predicates]]
[ORDER BY expression [IS [NOT] NULL] [ASC | DESC] [, ...]]
[LIMIT [offset, ] size]
流量拓扑图,桑基图
SELECT
CASE WHEN src < dst THEN src ELSE dst END AS src,
CASE WHEN src < dst THEN dst ELSE src END AS dst,
SUM(c) AS total_c
from Table(datainsight.system.query(streams=>'netflow',type=>'sql',query=>'select nf_src_address as src, nf_dst_address as dst,count(*) as c from $index where nf_src_address is not null and nf_dst_address is not null and nf_src_address!=\"0.0.0.0\" and nf_dst_address!=\"0.0.0.0\" group by nf_src_address,nf_dst_address order by count(*) desc limit 10'))
GROUP BY
CASE WHEN src < dst THEN src ELSE dst END,
CASE WHEN src < dst THEN dst ELSE src END
;
6.6 自定义菜单
背景介绍:随着菜单项的增加,为了满足不同用户的需求,WeOps可支持自定义菜单,不同的客户环境可根据自己的使用习惯对菜单项进行重新排序的分层级。(目前还不支持按照某个用户/角色进行自定义菜单)
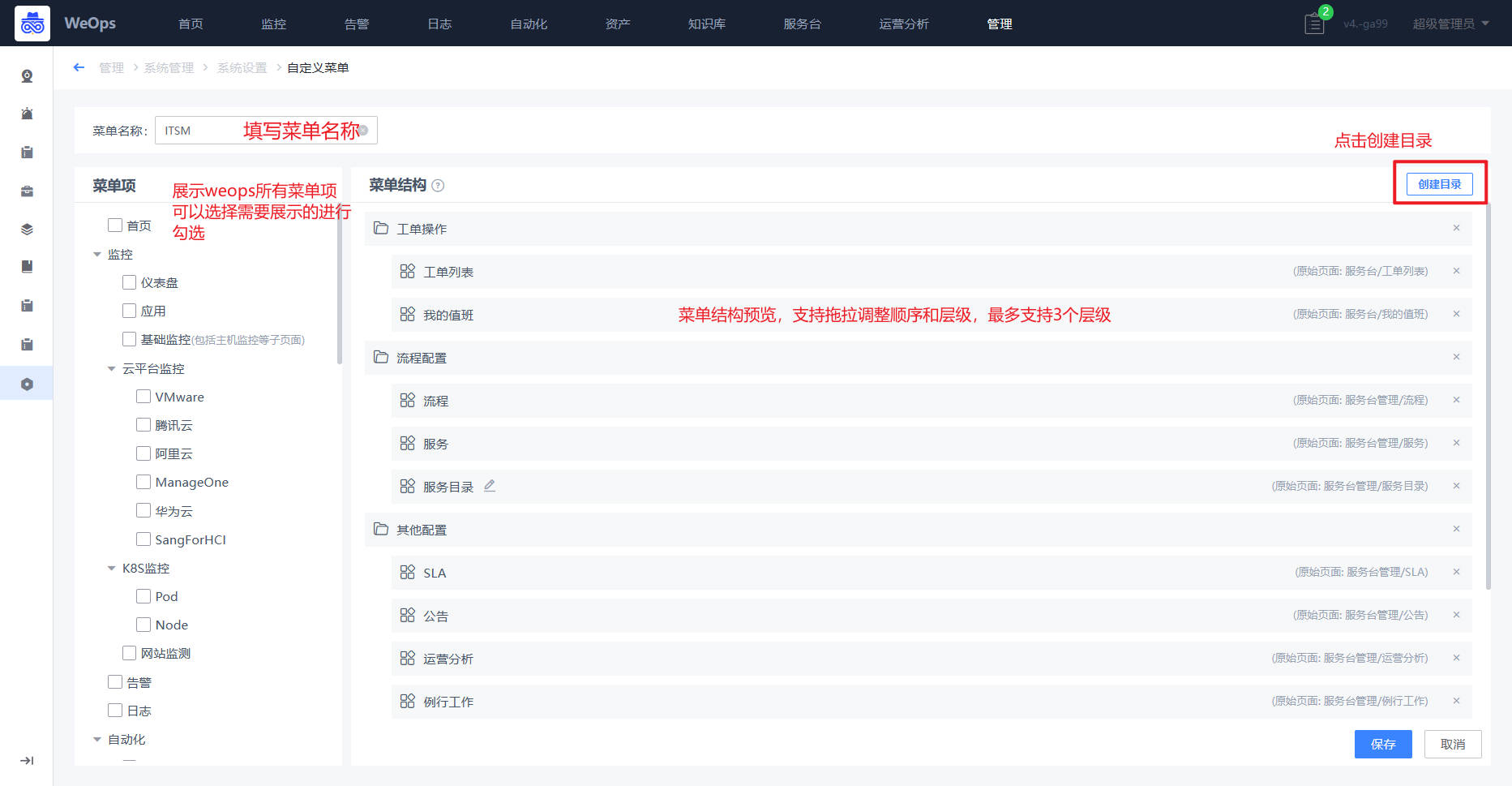
Step1:菜单的设置
路径:管理-系统管理-菜单设置
- 如下图,点击“新建菜单”按钮,可以创建一个新的菜单,并按照自己的需求进行编辑。
如下图,菜单的具体配置页面,具体说明如下
菜单项:展示了WeOps所有带页面的菜单项,支持勾选进入新菜单的编辑。其中“监控-基础监控”和“资产-资产记录”两个为菜单项组,下面带了动态的子页面,菜单项支持重新命名。
目录:支持新建目录对新菜单的菜单项进行分类展示。
其他说明:目前最高层级仅支持3层,目录下面必须包括菜单项,菜单项下面不可增加其他菜单项
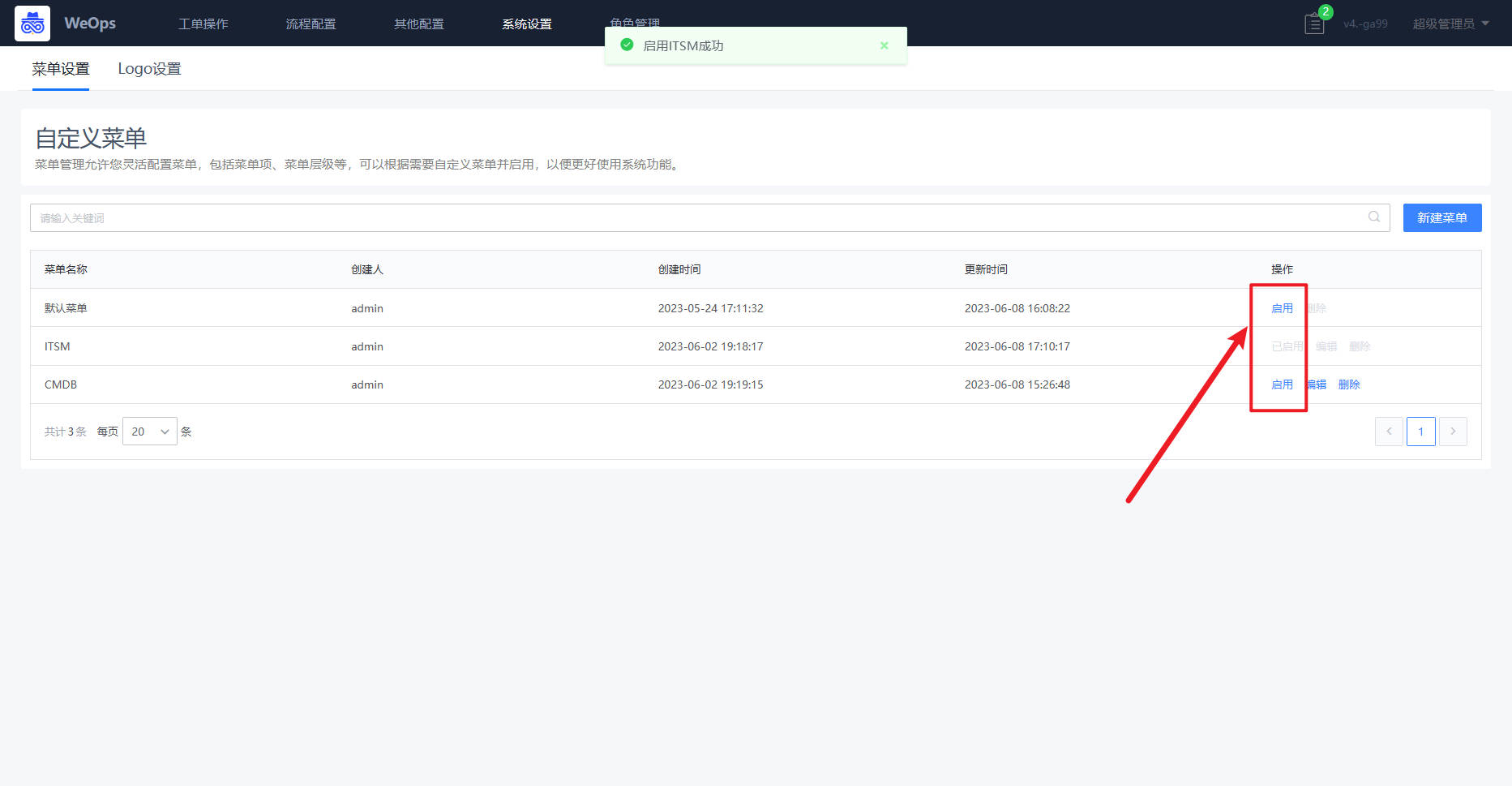
Step2:菜单的启用
- 点击“启用”按钮,就行菜单的启用,整体菜单结构立刻生效。
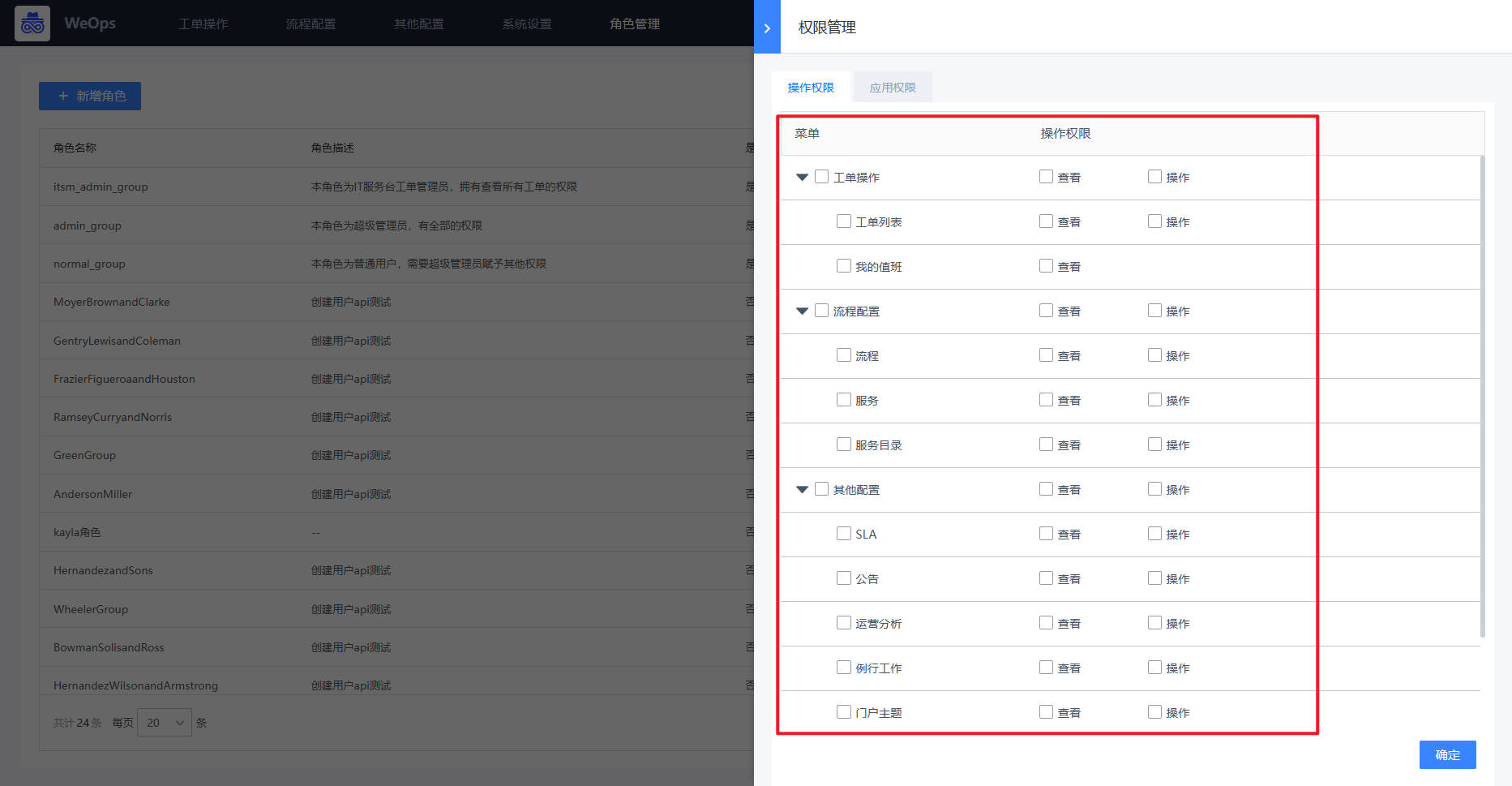
其他补充说明,菜单启用之后,角色的权限授权会跟随使用的菜单变动。
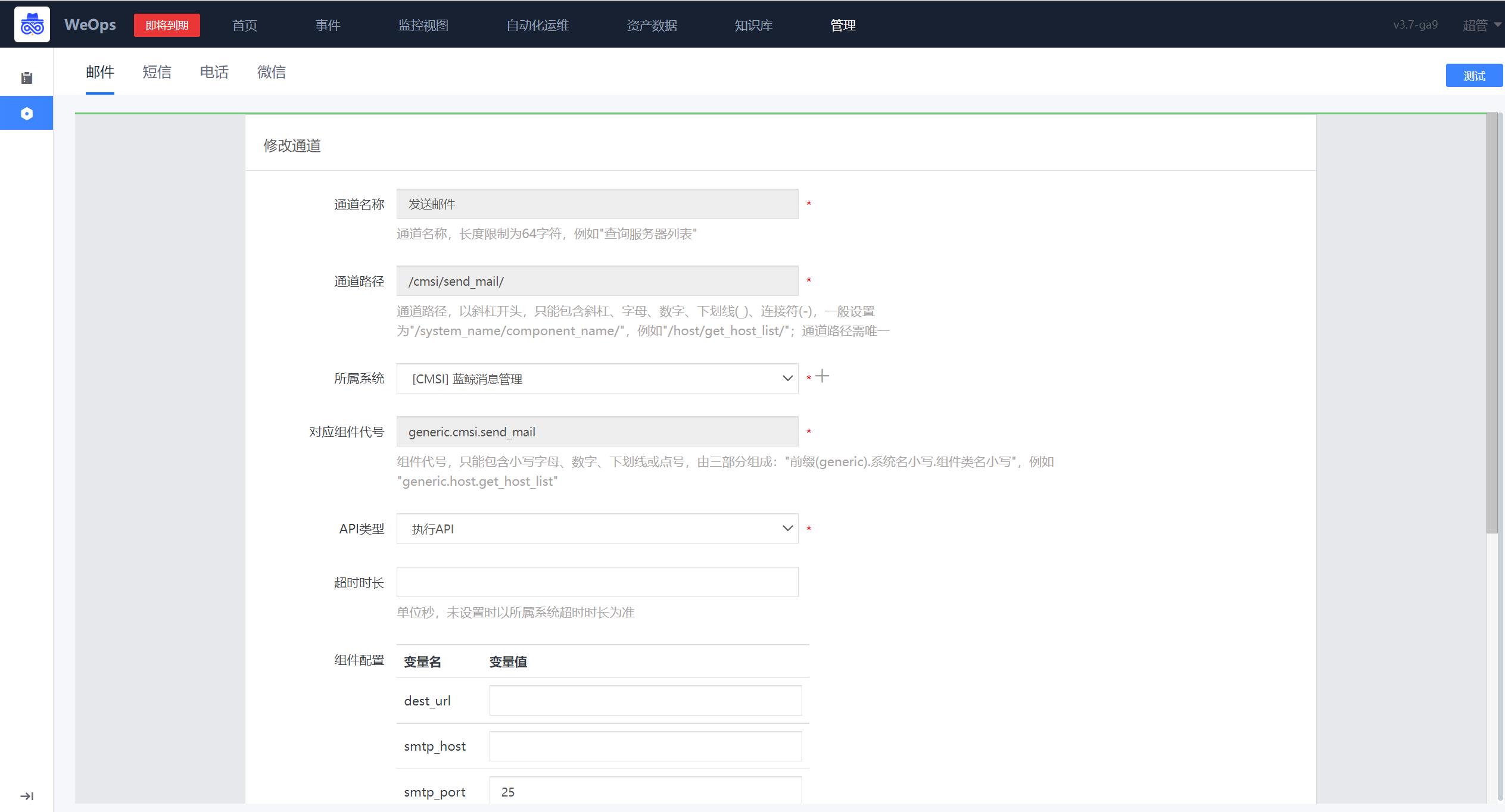
6.7 通知渠道配置
路径:管理-系统管理-通知渠道
邮件
邮件是相对较为常见的通知方式,对接配置比较简便,需提供一个发件箱,并允许蓝鲸对SMTP服务器的访问权限。参数说明如下:
dest_url: 若用户不擅长用 Python,可以提供一个其他语言的接口,填到dest_url,ESB 仅作请求转发即可打通邮件配置
smtp_host: SMTP 服务器地址 (注意区分企业邮箱还是个人邮箱)
smtp_port: SMTP 服务器端口 (注意区分企业邮箱还是个人邮箱)
smtp_user: SMTP 服务器帐号
smtp_pwd: SMTP 服务器帐号密码 (一般为授权码)
smtp_usessl: 默认为 False
smtp_usetls: 默认为 False
mail_sender: 默认的邮件发送者 (smtp_user 相同)
短信
企业采用的短信服务厂商不尽相同,目前蓝鲸仅支持腾讯云sms服务开箱即用,其他厂商对接需企业提供短信服务接口文档,并在蓝鲸侧做定制适配,以下以腾讯云sms为例列举参数说明:
dest_url: 若用户不擅长用 Python,可以提供一个其他语言的接口,填到 dest_url,ESB 仅作请求转发即可打通短信配置
qcloud_app_id: SDK AppID
qcloud_app_key: App Key
qcloud_sms_sign: 在腾讯云 SMS 申请的签名,比如:腾讯科技
微信公众号
1)微信公众号对接需要满足以下先决条件:
a)企业需提供一个微信公众号;
b)蓝鲸平台发布在公网。
2)创建微信公众号:打开微信公众平台(https://mp.weixin.qq.com/)自行注册微信公众号服务号,所在行业选择IT科技/IT软件与服务(和后面的模板消息有关联);
3)添加模板消息
4)统一告警中心配置公众号相关信息:
APPID,AppSecret:在服务号管理后台-开发-基本配置中可获取到
Token:自行设置 (必须是英文或数字, 长度3-32字符)
template_id:在服务号管理后台-功能-模板消息中可获取到
5)然后,在微信服务号管理后台-开发-基本配置,须填写以下参数:
IP白名单:填写统一告警中心服务器出口IP
服务器地址:填写内容为{{alarmcenter_url}}/alarm/mobile/wechat/event/,{{alarmcenter_url}}为统一告警中心地址
令牌(token):上一步中填写的token
消息加解密密钥:不需要设定
消息加解密方式:选择 “明文模式”
6)在服务号管理后台-设置-公众号设置-功能设置,设置网页授权域名处需下载授权文件提供给实施工程师进行蓝鲸服务器Nginx配置,然后填写网页授权域名为paas域名, 即可通过验证。

企业微信 1)企业微信对接需要满足以下先决条件:
a)统一告警中心SaaS(这里指SaaS所在蓝鲸appo服务器)能够访问外网(统一告警中心的告警会先把消息推送到企业微信服务器,然后企业微信再转发推送到客户的企业微信上,所以蓝鲸服务器需要能够访问公网);
b)蓝鲸平台的域名需要发布在公网;
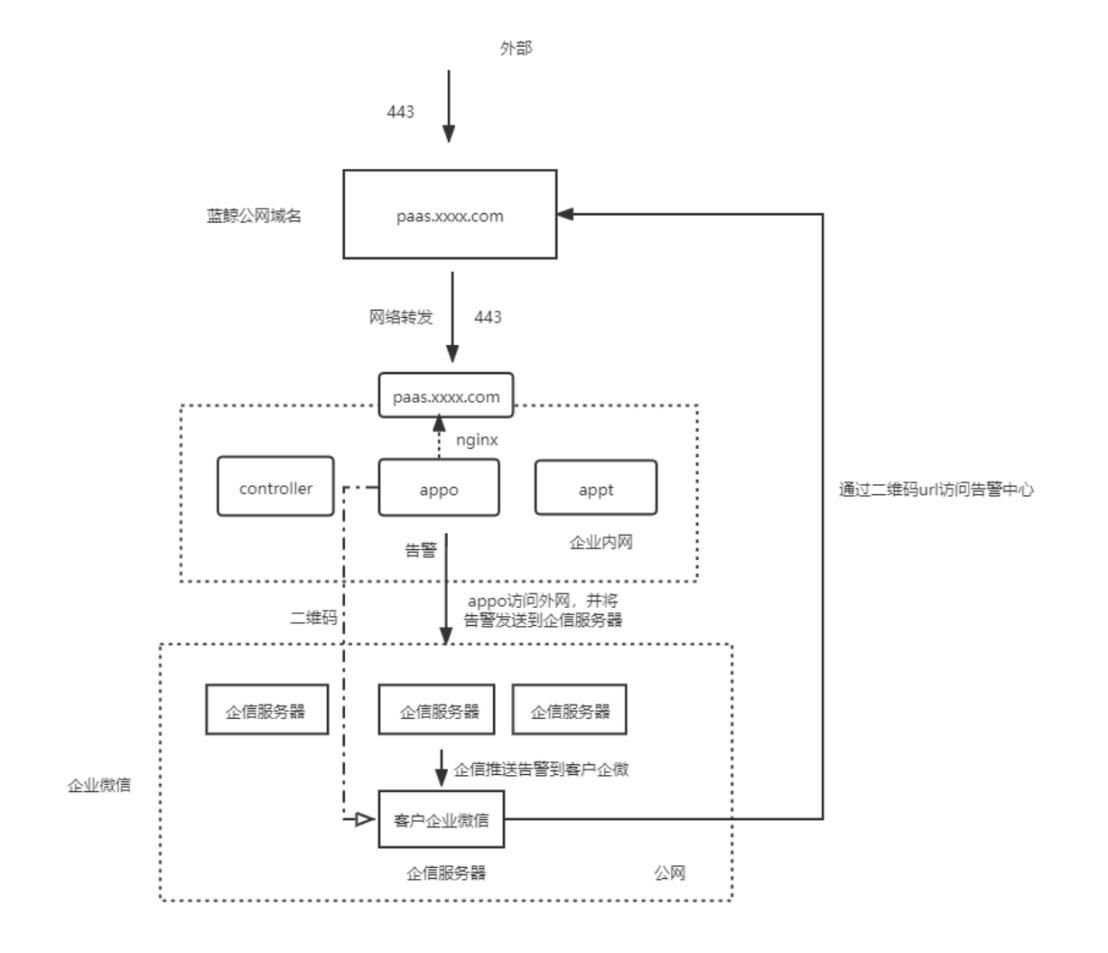
c)外部访问蓝鲸公网域名+端口和在客户内网环境访问蓝鲸域名+端口需要一致,这是由告警中心这个SaaS的底层代码和企信的回调域设置决定的。事实上,告警中心移动端的配置是通过企信扫二维码实现的,这个二维码由SaaS生成,其实质是一个url,这个url只能从内网的蓝鲸服务器获取。因此,企信去访问这个url时,要先访问发布在公网的蓝鲸域名。强烈推荐蓝鲸平台采用https方式部署。
2)逻辑架构参考下图:
3)企业微信对接需在统一告警中心填写以下参数:
企业ID:在企业微信后台“我的企业”中可以获取到;
AgentID,Secret:在应用的基础信息中可以获取到

6.8 许可管理配置
背景介绍:企业客户想了解该系统的可用节点信息和许可有效期,并设置到期提醒。
路径:管理-系统管理-许可管理
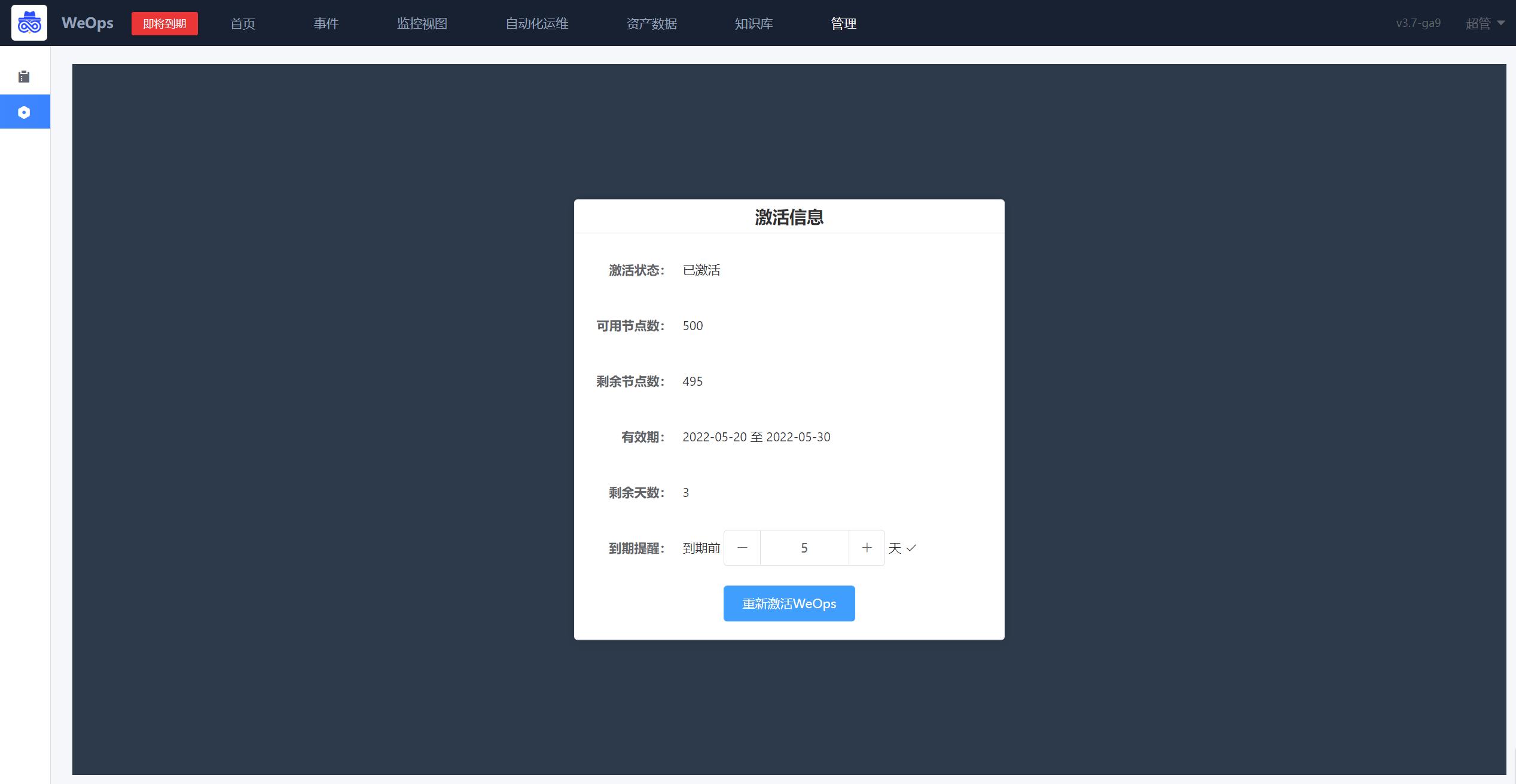
可以查看激活状态,可用节点数量、有效期等信息,可设置到期提醒,设置成功后,可在菜单的左上角收到到期提醒提示。
6.9 用户和角色配置
背景介绍:需要配置新角色,并对新角色授权对应权限,把对应用户赋予新角色。
整体步骤:新建角色——角色授权——赋予人员角色
新建角色
路径:管理-系统管理-角色管理
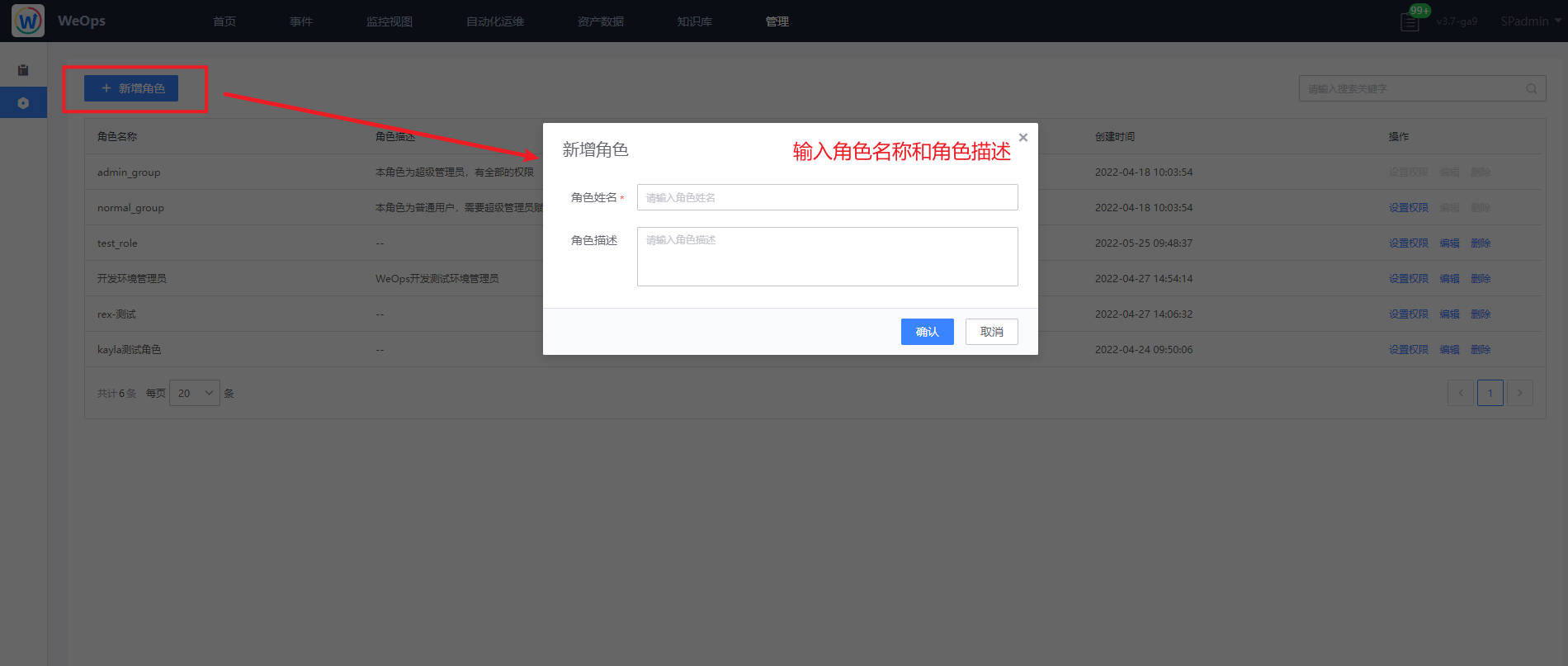
- 如下图,点击“新建”按钮,填写角色名称和描述
角色授权
路径:管理-系统管理-角色管理
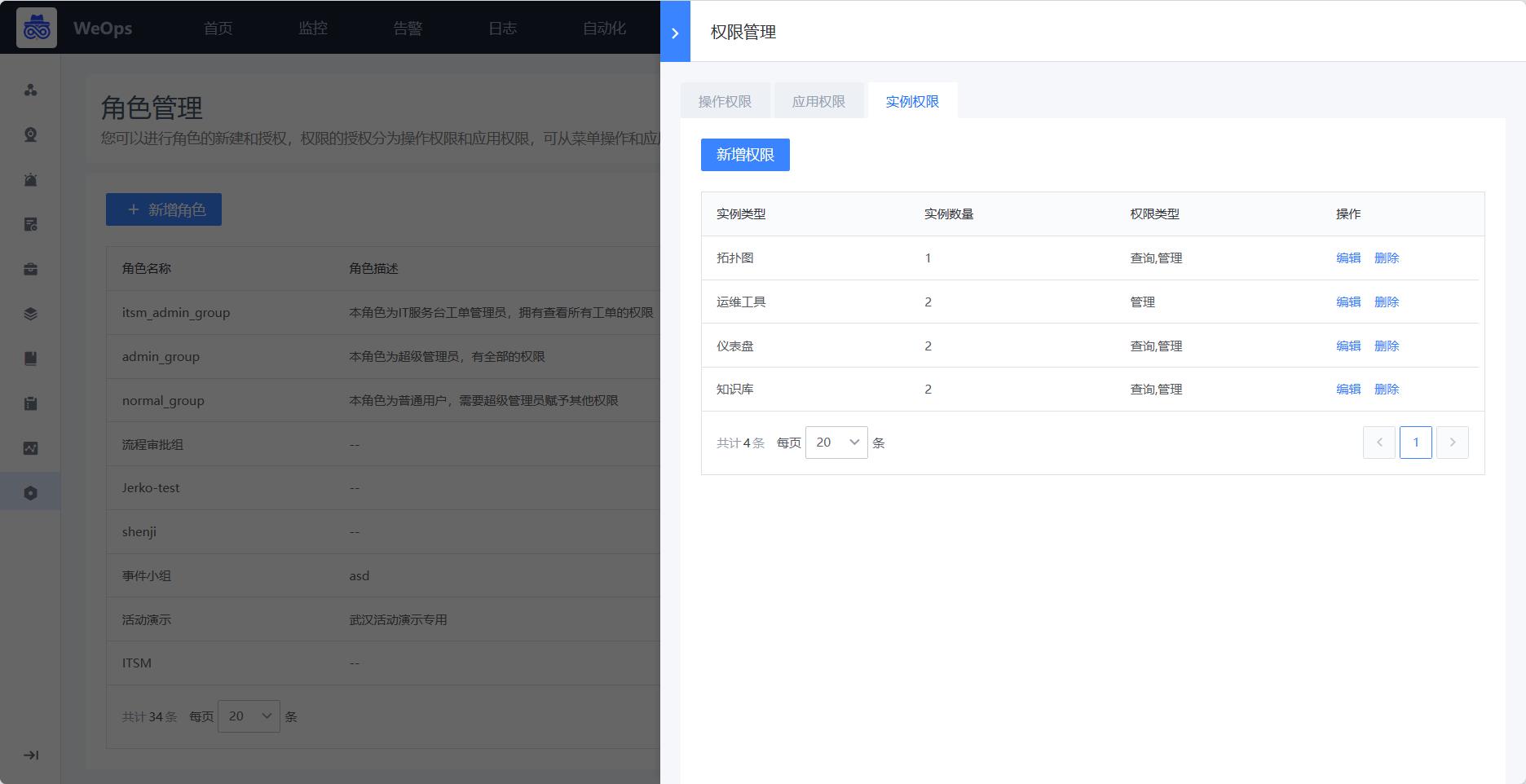
点击角色后的“设置权限”,对该角色进行授权,包括操作权限、应用权限、实例权限。
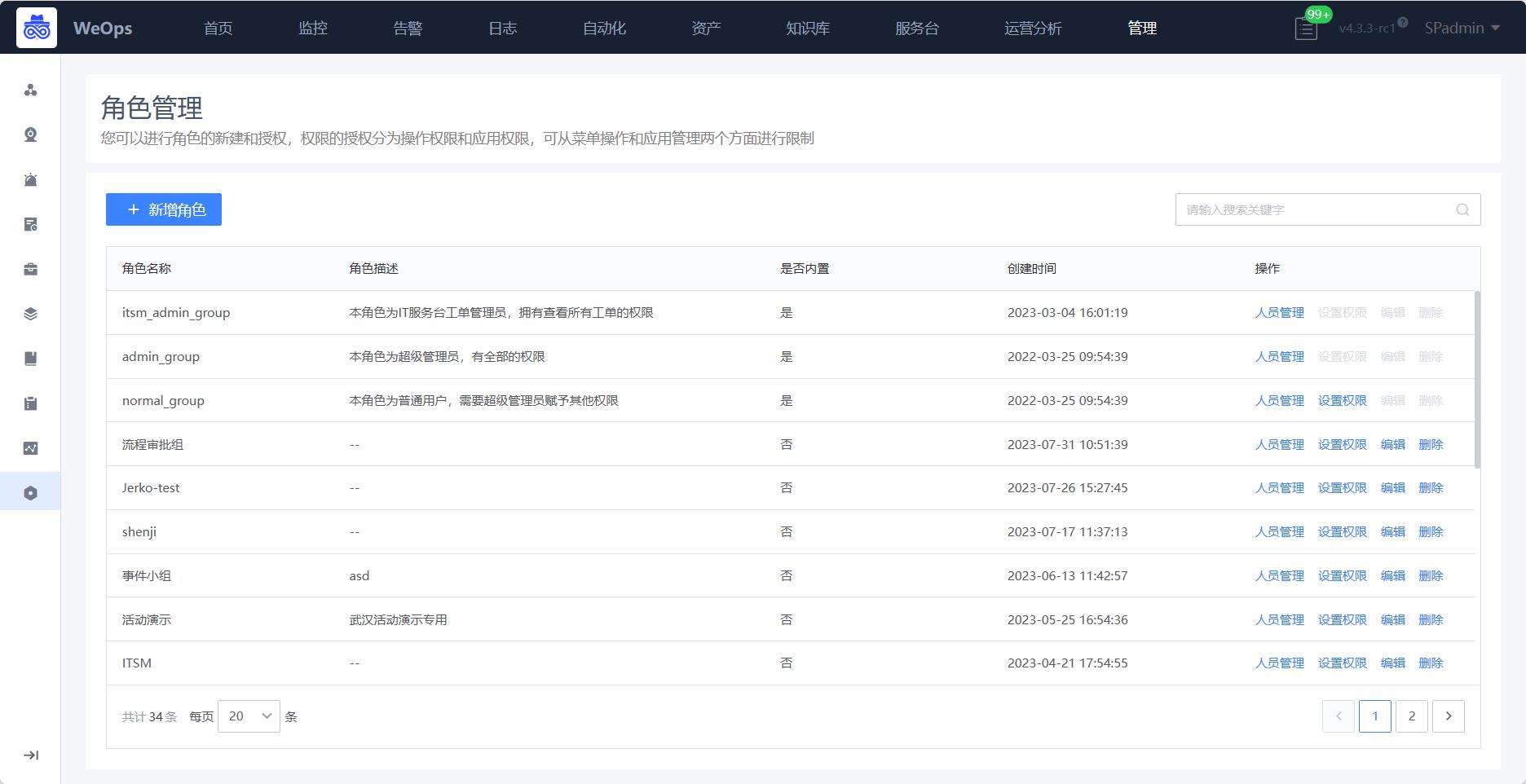
菜单操作权限:操作权限包括菜单权限和操作权限,用于限制该角色是否可以看到该菜单、以及对该菜单下的页面是否有查看/操作权限
应用权限:应用权限用于限制该角色是否可以看到该应用数据已经该应用下的资产数据,用户拥有该应用的权限,即拥有该应用下资产的查看/管理/监控/自动化操作等权限

实例权限:目前包括以下六类实例权限,拓扑图、仪表盘、文章、运维工具、监控采集任务、监控策略任务。用户拥有某些实例的权限,可以进行该实例的查看/操作。
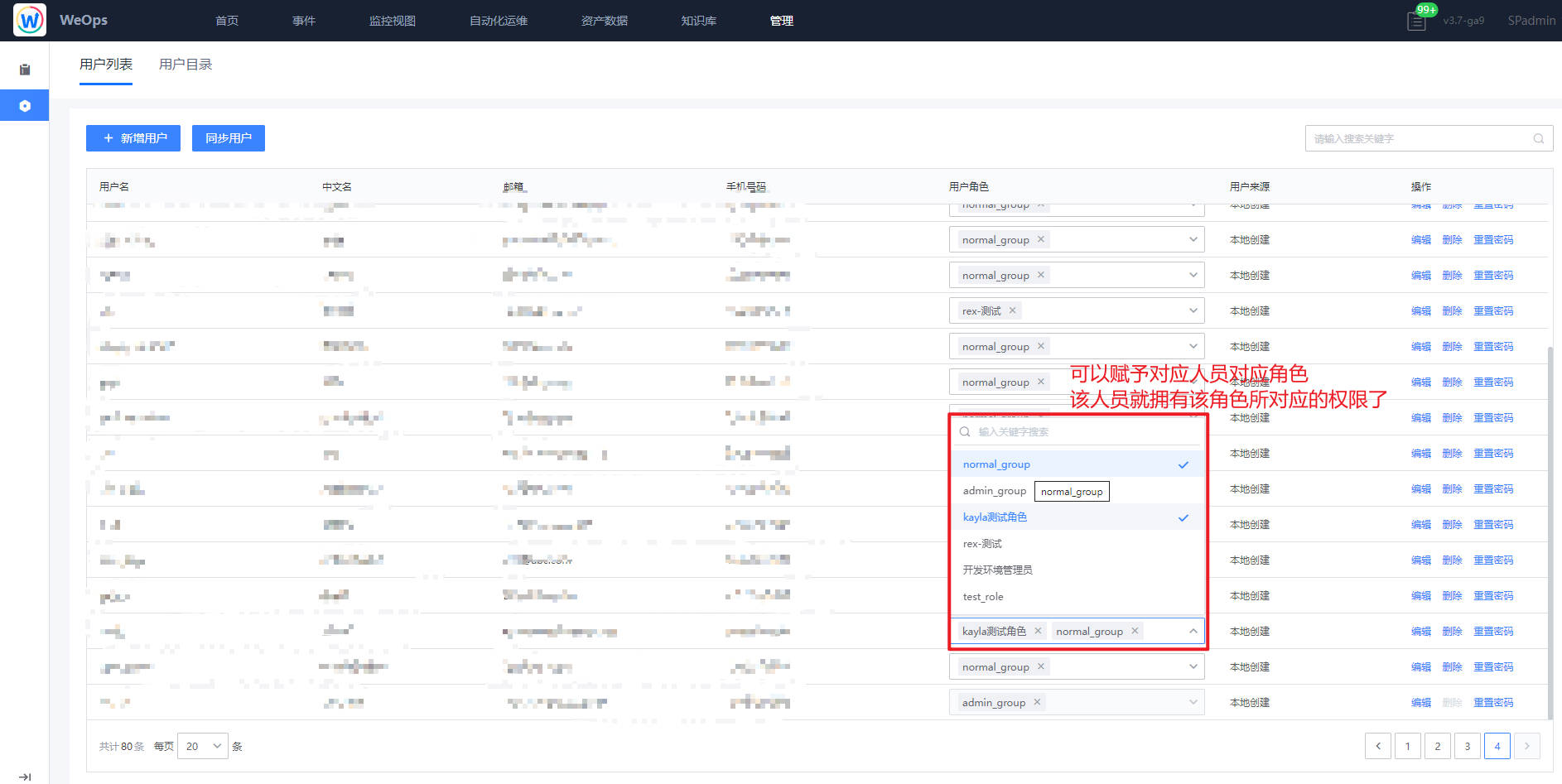
赋予人员角色
路径:管理-系统管理-人员管理
- 如下图,在“人员管理”中,选择需要设置的人员,在用户角色中选择对应角色,即可把该角色的权限赋予对应人员。若某人员赋予多个角色,则他将会拥有这多个角色的所有权限。