嘉为蓝鲸WeOps 3.15产品操作手册
1、资源纳管
1.0 资产关系总图示
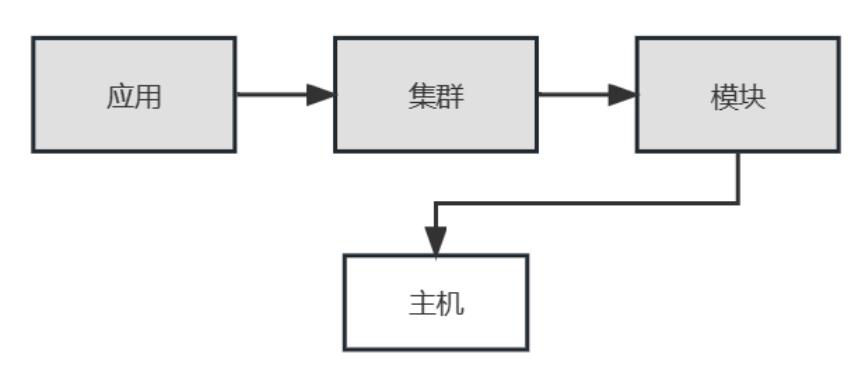
主机
如下图,主机直接与“模块”想关联,其应用归属来自于所属的模块的应用。
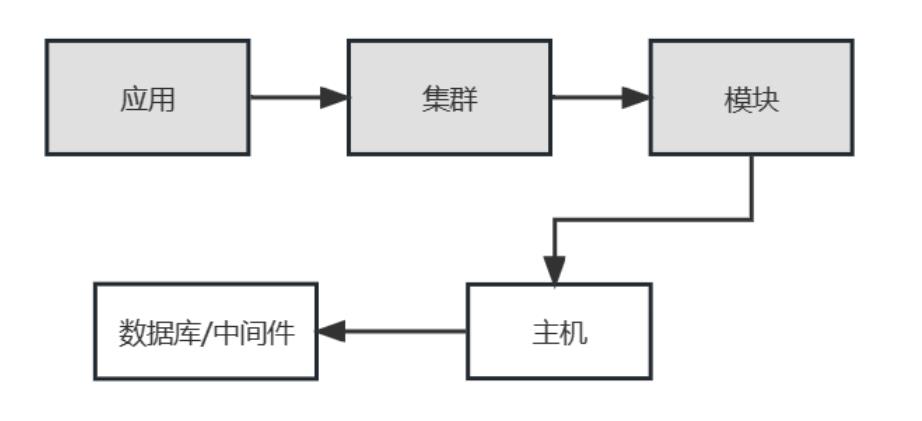
数据库/中间件
如下图,数据库/中间件与主机关联,其应用归属来自于关联的主机应用属性。
K8S
如下图,K8S集群、命名空间、工作负载、pod、node的关联关系如图,各个模型的应用属性描述如下:
K8S集群:直接与集群关联,从而获得应用属性
node:来自于关联的K8S集群的应用属性
命名空间:直接与集群关联,从而获得应用属性
工作负载、pod:来自于所关联的命名空间的应用属性

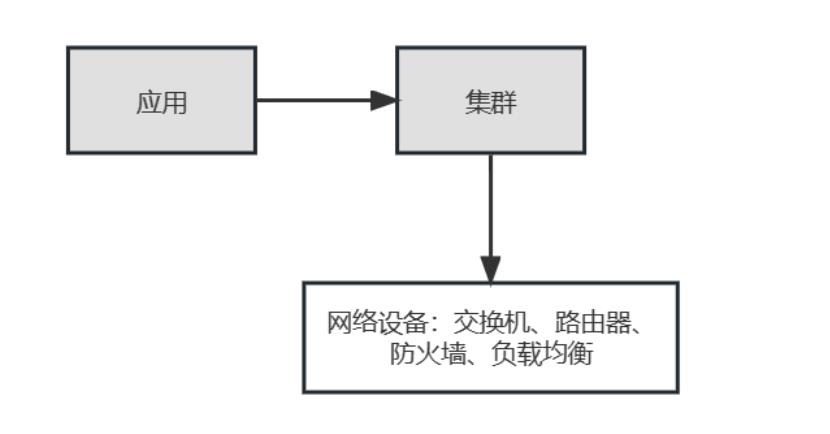
网络设备
如下图,交换机、路由器、负载均衡、防火墙等网络设备直接与集群关联,从而获得对应的应用属性。
云平台-VMware
如下图,Vcenter、虚拟机、ESXI、数据存储直接的关联关系如图,各个模型的应用属性描述如下
vcenter:直接与集群关联,从而获得应用属性
虚拟机、ESXI、数据存储:各自直接与模型关联,从而获得应用属性

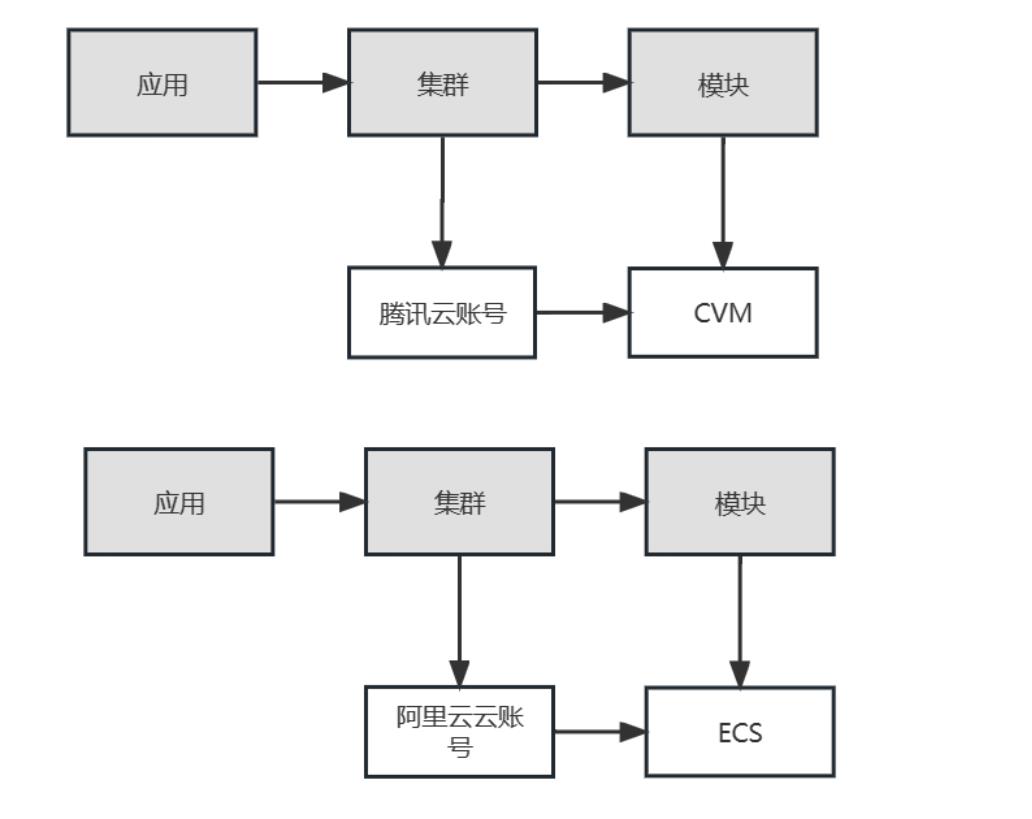
云平台-腾讯云/阿里云
如下图,云账户直接与集群关联,从而获得应用属性,云服务器(CVM、ECS)直接与模块关联,从而获得应用属性。
1.1 主机纳管
背景介绍:需要把主机纳入到WeOps的管理中,有两种方式进行:一是手动创建仅记录主机信息,二是安装Agent进行主机信息的自动采集
方式一:手动创建
路径:资产-资产记录-主机
手动创建仅录入主机的相关信息,进行主机的信息管理和拓扑展示,若需要对手动创建的主机进行监控数据采集,需要对其进行Agent安装。
Step1:进入界面,点击“新建”
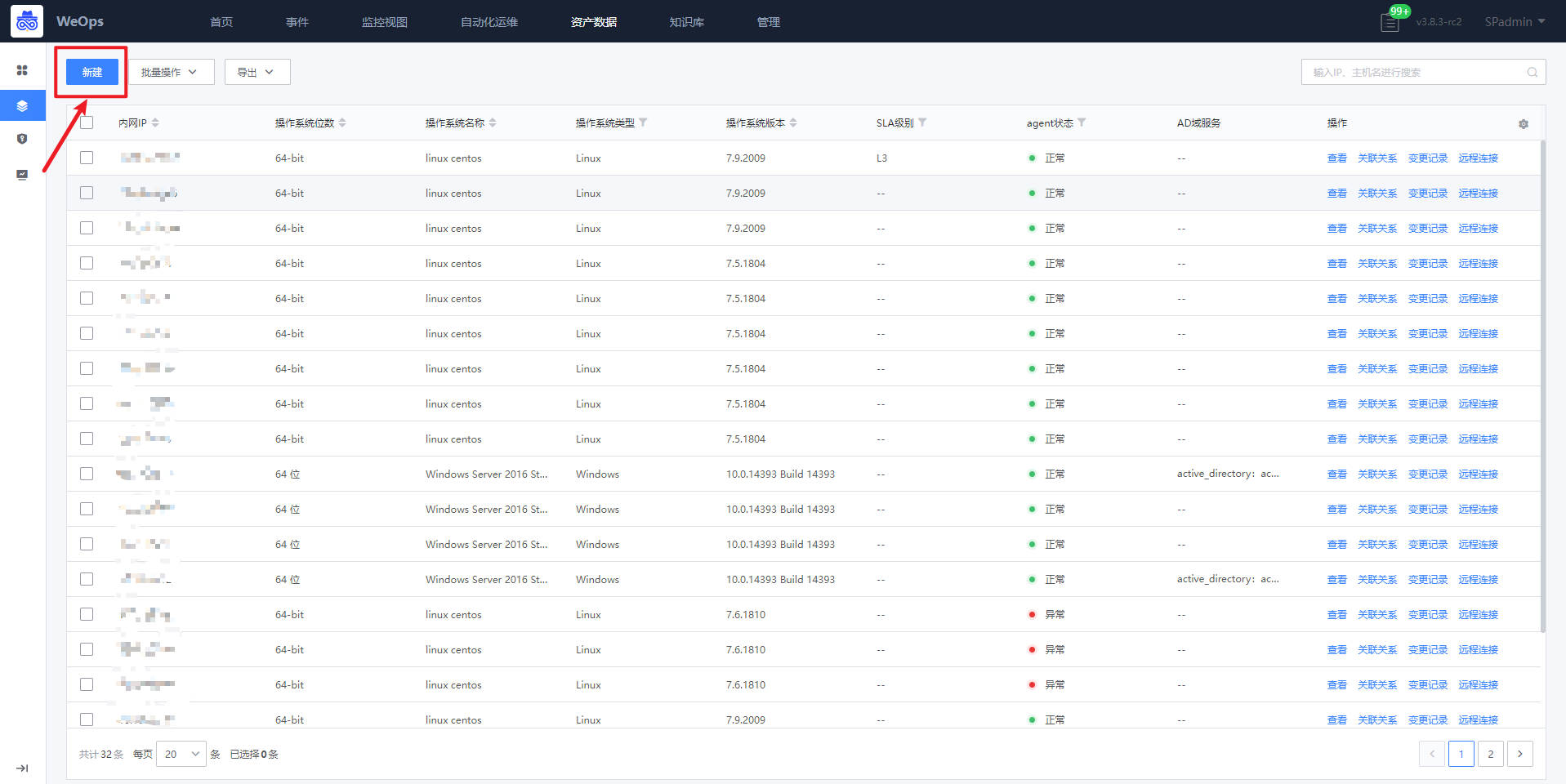
Step2:填写主机相关信息
在弹出的抽屉中填写相关主机信息,必填字段包括:内网IP、云区域

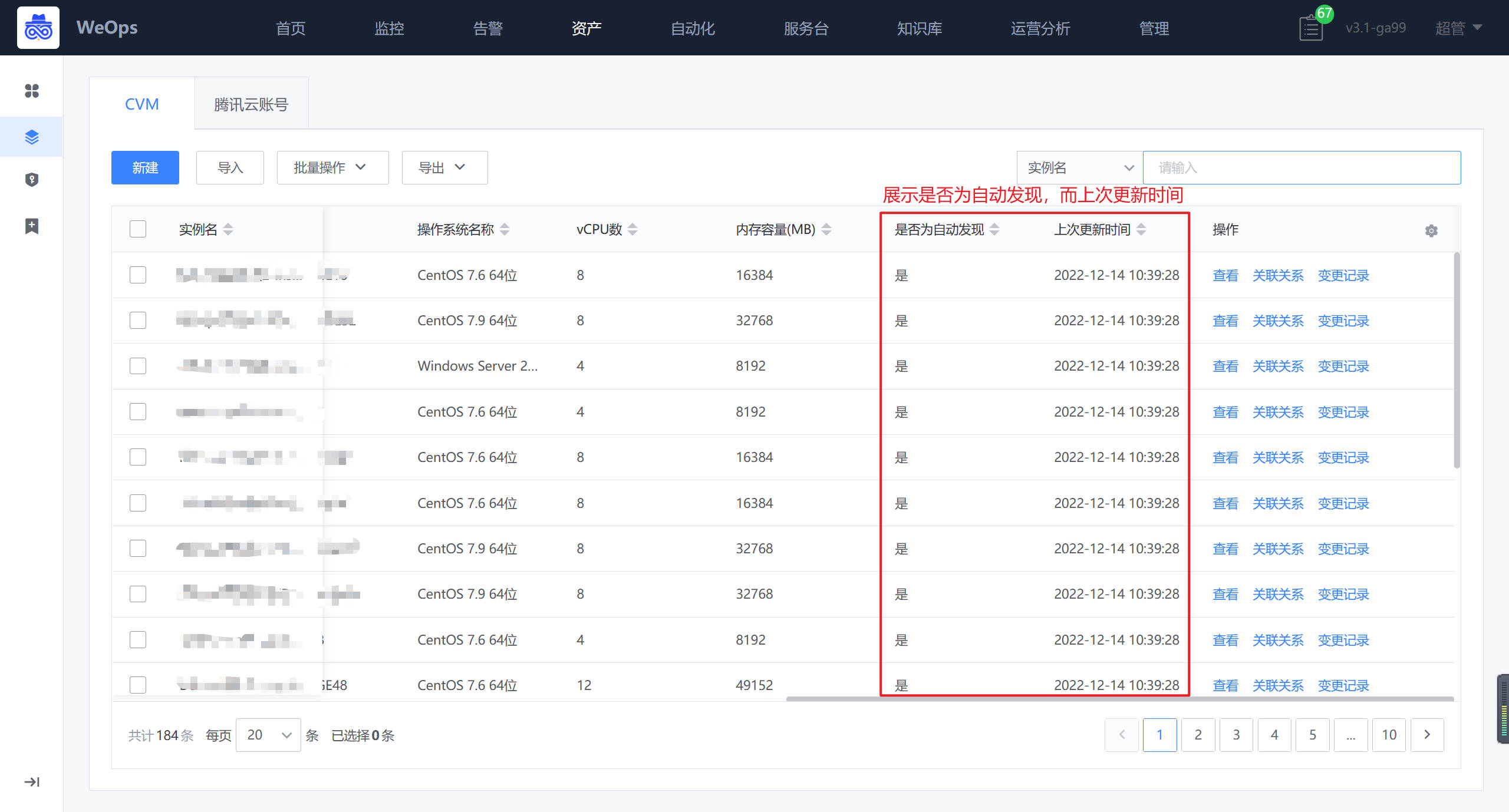
手动创建的主机agent状态为“未安装”,若需要安装agent,则前往“管理-管理中心-监控管理-监控采集”进行agent的安装。
方式二:安装Agent
路径:管理-监控管理-监控采集
以安装agent的方式进行主机的纳管,在agent安装后,可在“资产数据-资产记录(主机)”中形成对应的主机信息,同时支持监控数据的采集。可以选择手动单个agent安装,或者利用表格导入进行批量安装,安装步骤基本一致。
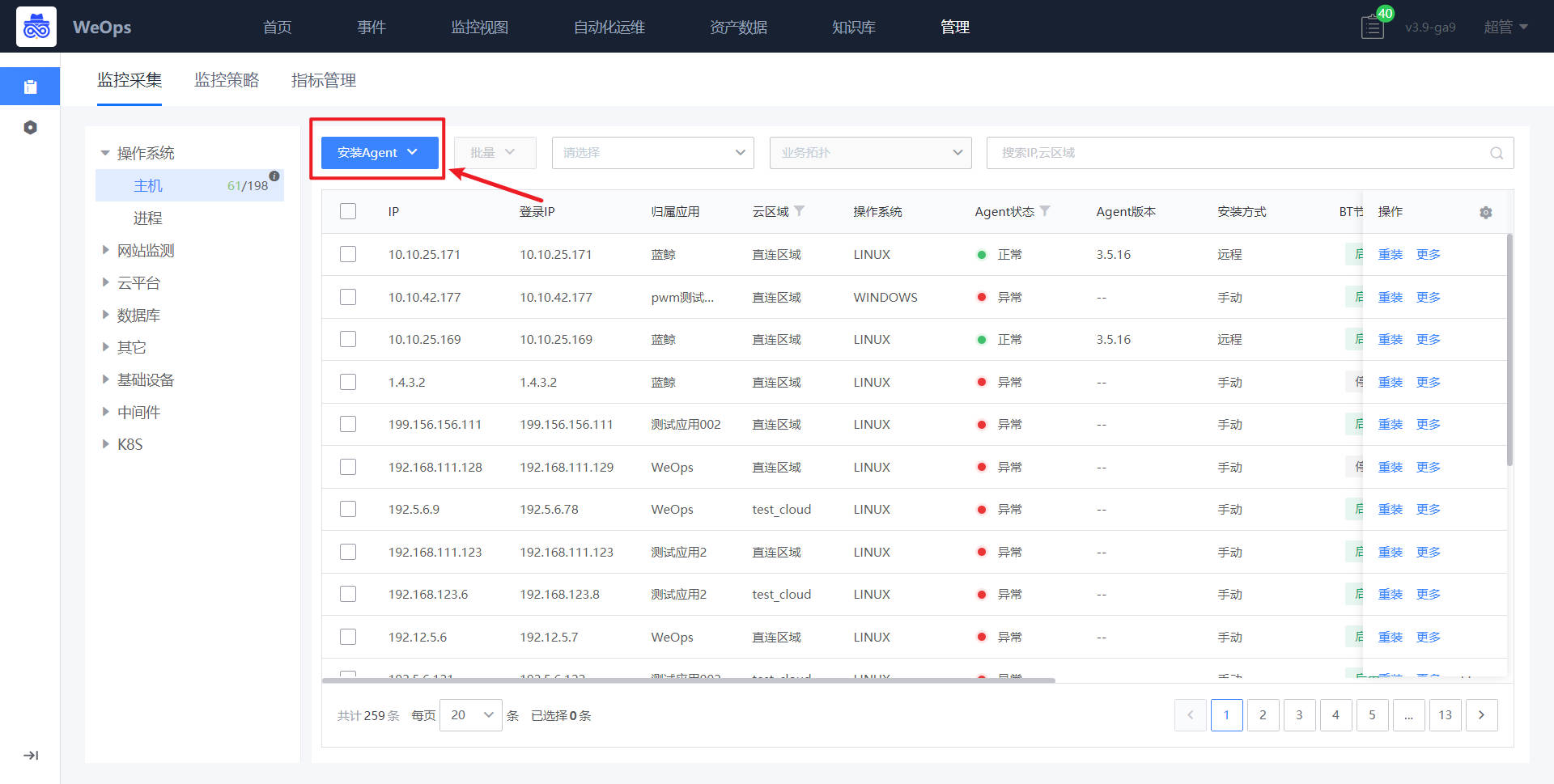
Step1:进入界面,点击安装Agent
如下图所示,选择“操作系统-主机”,进入主机Agent安装界面,点击“安装Agent”
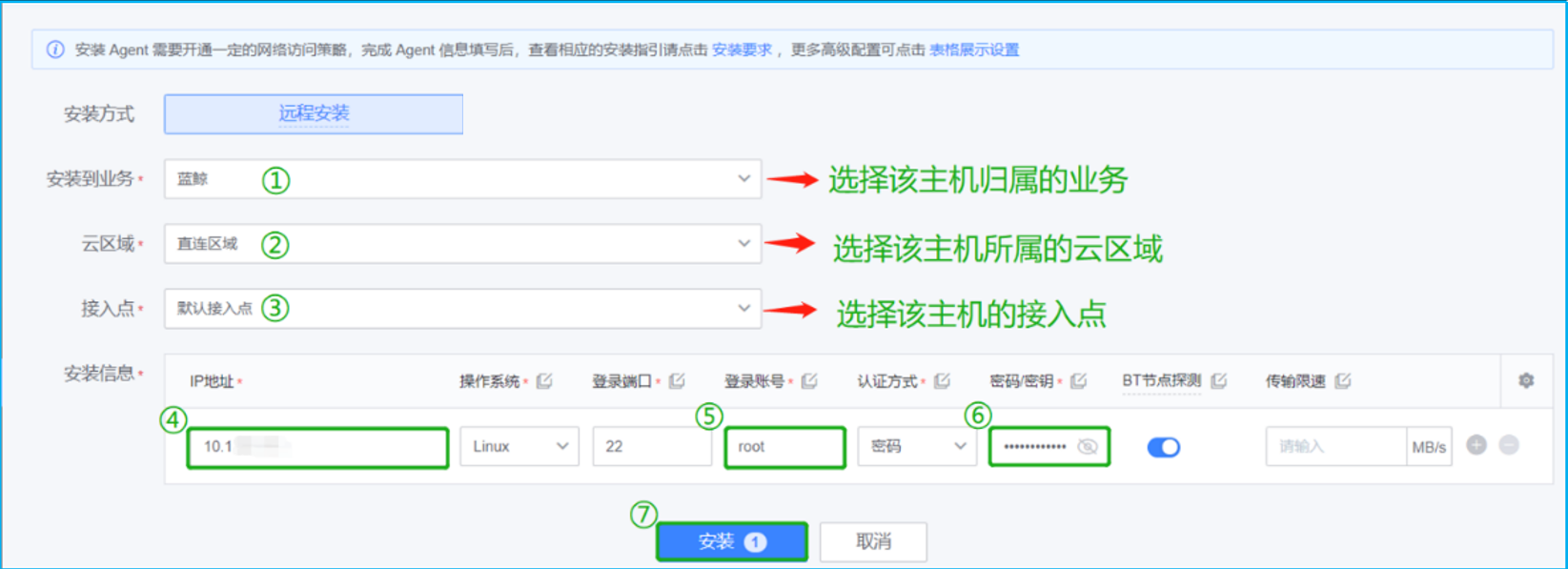
Step2:填写相关信息
在安装的界面,选择该主机归属的业务、云区域以及接入点。随后在安装信息输入该纳管主机的IP地址,登录账号和密码等核心配置。输入完成之后点击[安装]按钮即可将agent部署至该主机。
Step3:等待安装成功
上一步骤点击安装将会跳转至安装界面,可以查看执行状态,点击查看日志可以查阅安装过程。
安装完成回到主机纳管的界面可以看到该主机的Agent已经顺利安装。
1.2 应用新建
背景介绍:当有新应用上线时,需要在WeOps的应用管理对该应用进行纳管,具体步骤如下:新建应用,填写该应用相关信息→确定该应用层级并配置拓扑→添加主机,进行管理。
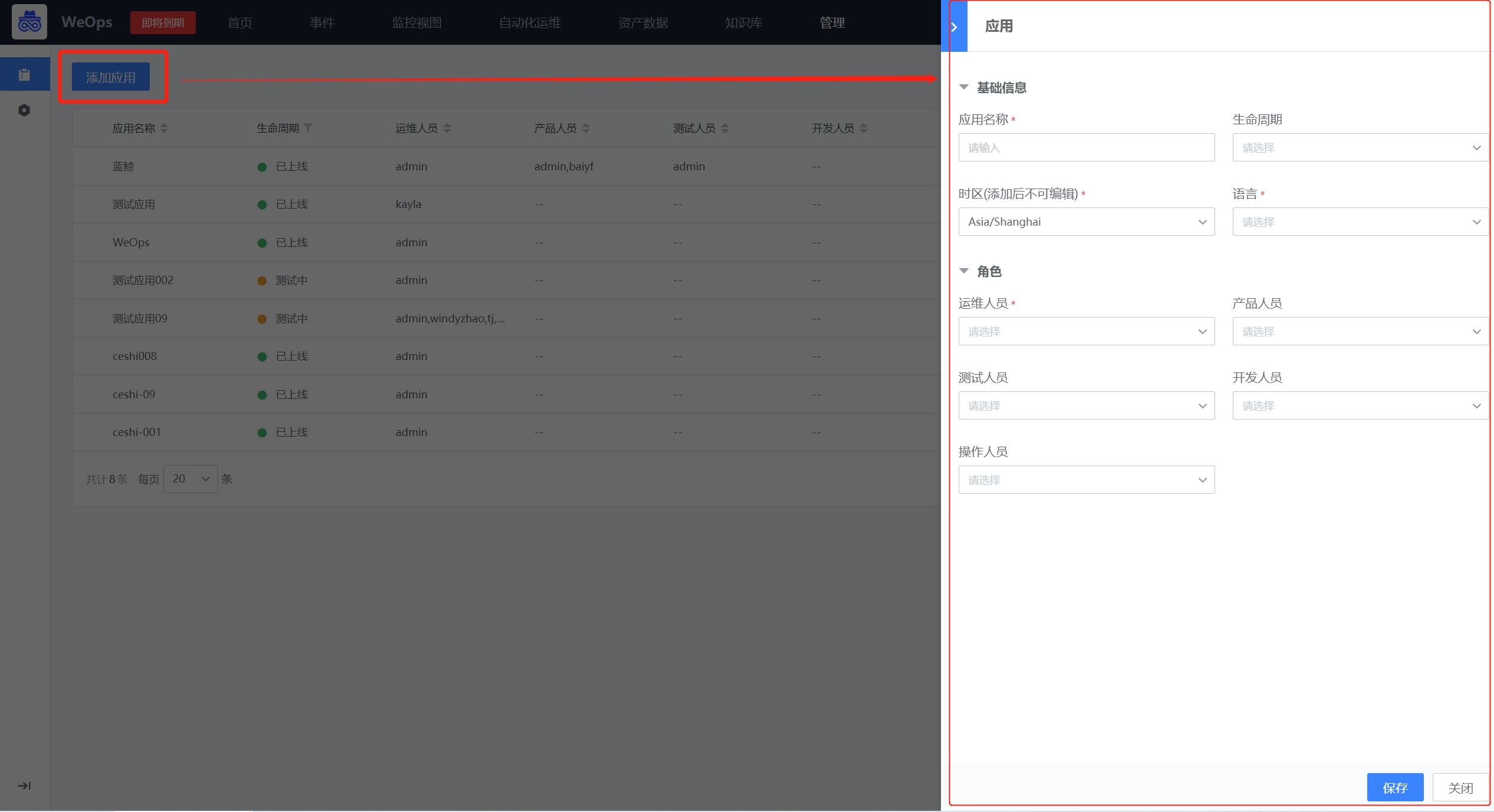
Step1:新建业务
路径:资产-应用
在应用列表页面,点击“添加应用”按钮,可以进行应用的新建。需填写基础信息和角色信息。
Step2:配置应用拓扑
路径:资产-应用
进入新创建的应用的详情页面,点击左侧的节点信息,展示该应用的拓扑
点击页面左侧的拓扑的对应节点,可依据实际情况依次添加“子应用”、“集群”和“模块”等层级
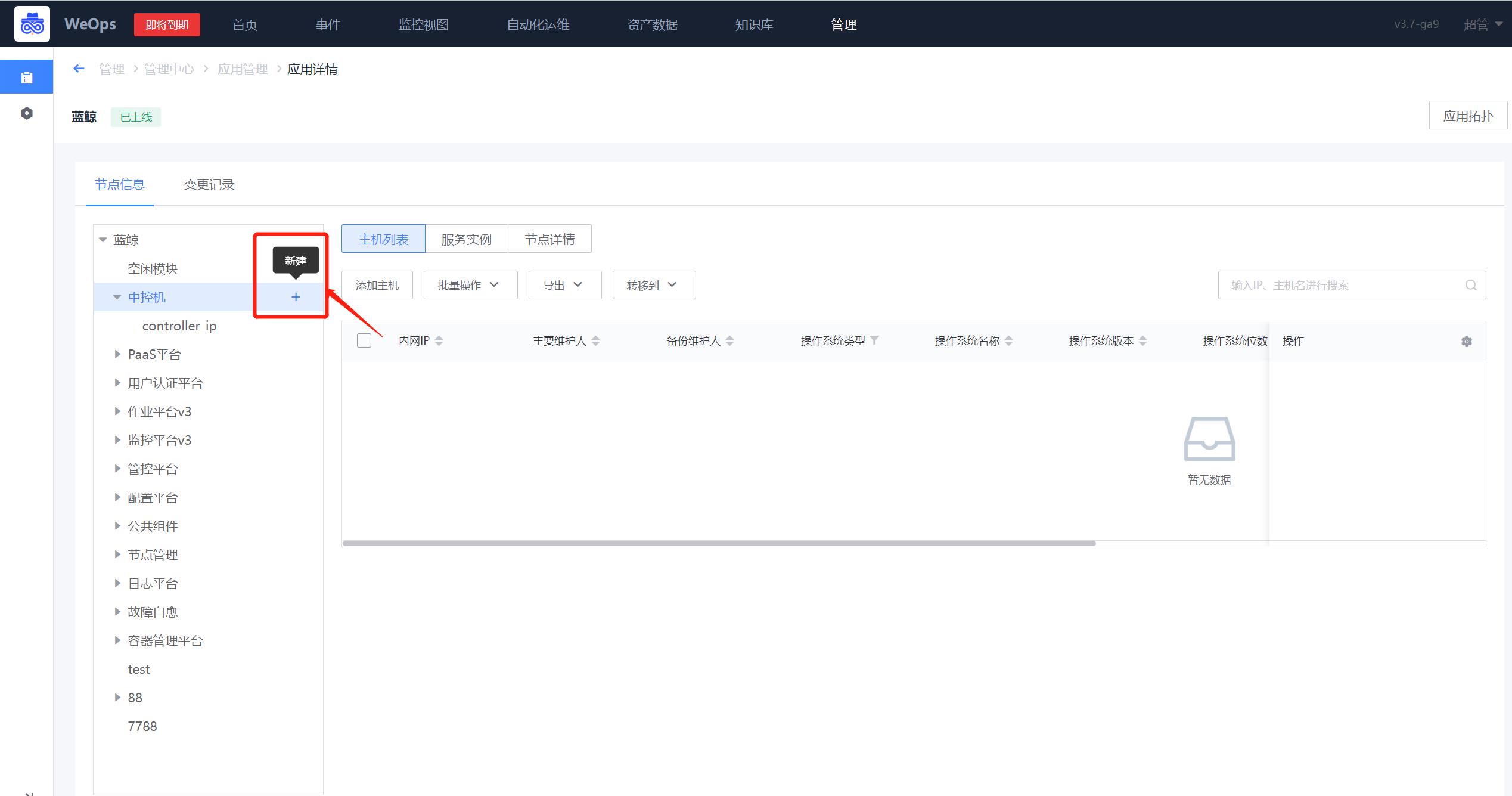
Step3:主机分配和移动
路径:资产-应用
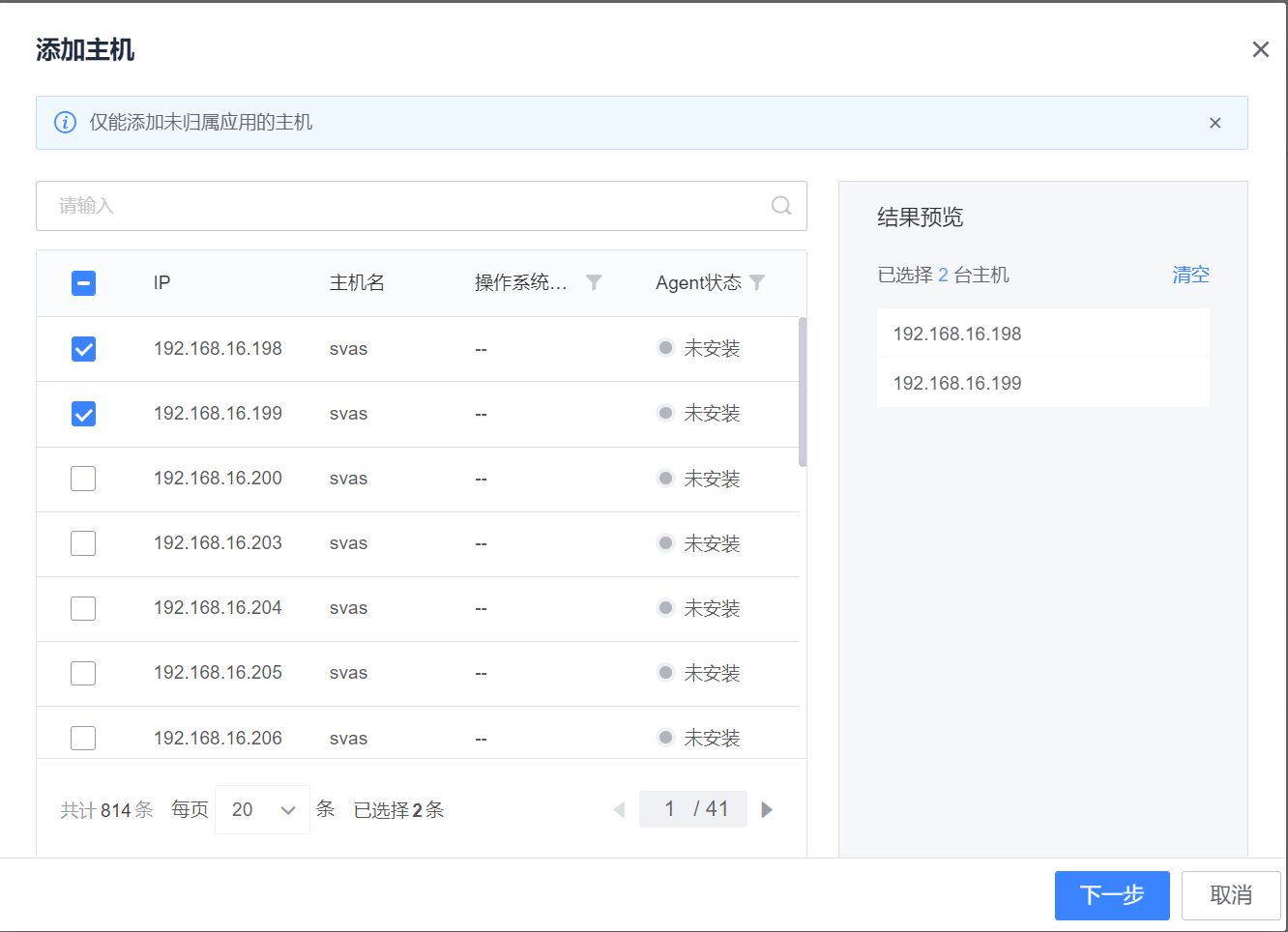
应用的拓扑新建完成后,可以向各个节点添加主机。选中需要添加的节点,点击“主机列表”下的“添加主机”按钮,这里展示了所有没有归属应用的主机列表(展示手动创建/安装Agent两种方式下未归属应用主机),选择需要加入的主机,点击下一步,选择模块即可添加成功。

1.3 数据库/中间件纳管
背景介绍:关联主机已经进行Agent的安装,并且Agent正常(主机Agent安装详见1.1主机纳管),这里以Oracle为例进行介绍,有两种方式进行资源的纳管,一种是手动纳管,一种是创建自动发现任务进行资产纳管。
方法一:手动纳管
路径:资源-资源记录-数据库(Oracle)
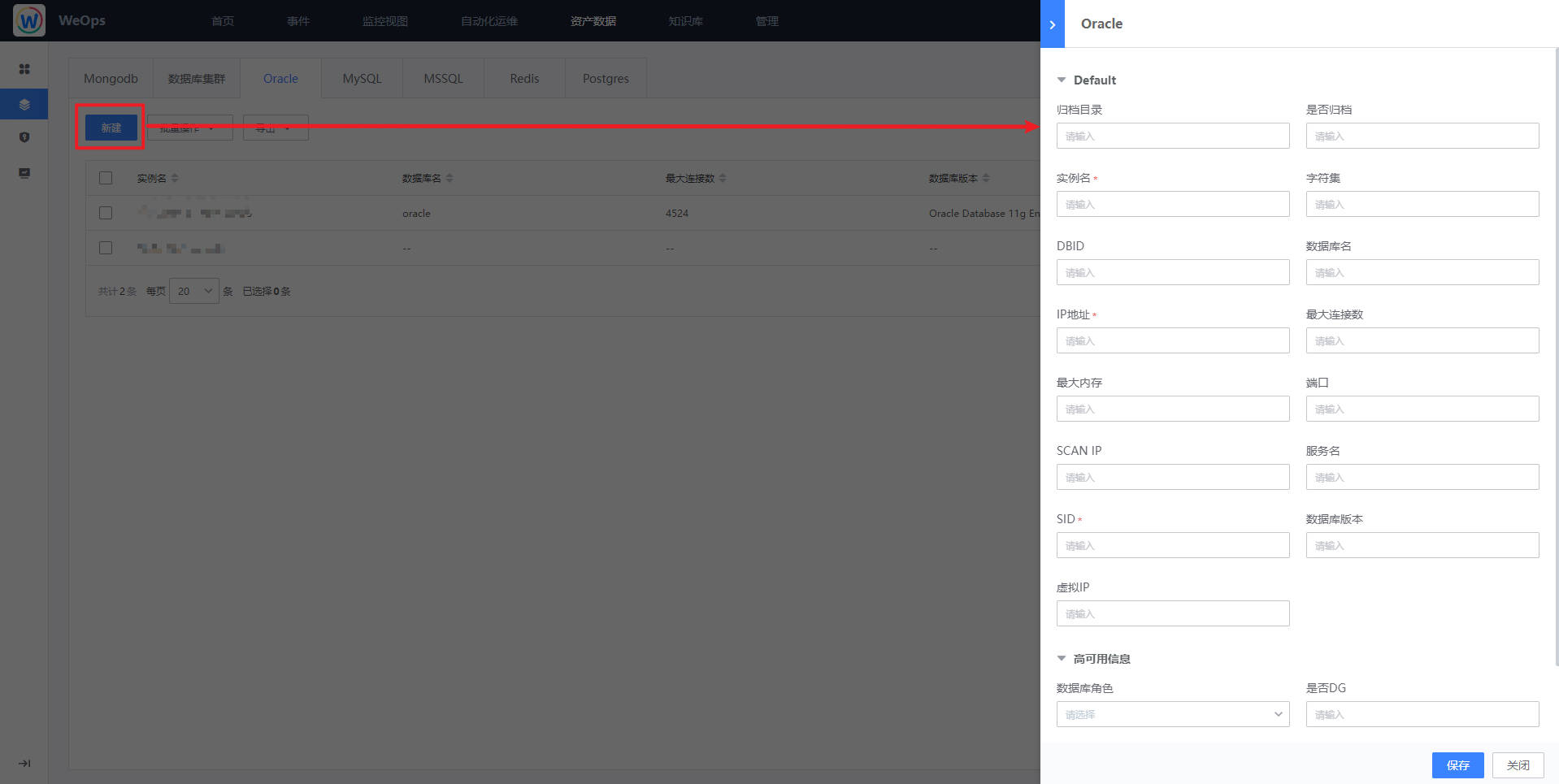
Step1:进入界面,点击“新建”,进行实例信息录入
点击“新建”按钮后,在弹出的抽屉中,填入Oracle的相关信息。
Step2:建立与主机的关联
实例新建完成后,点击“查看”按钮,进入到该实例的详情页。
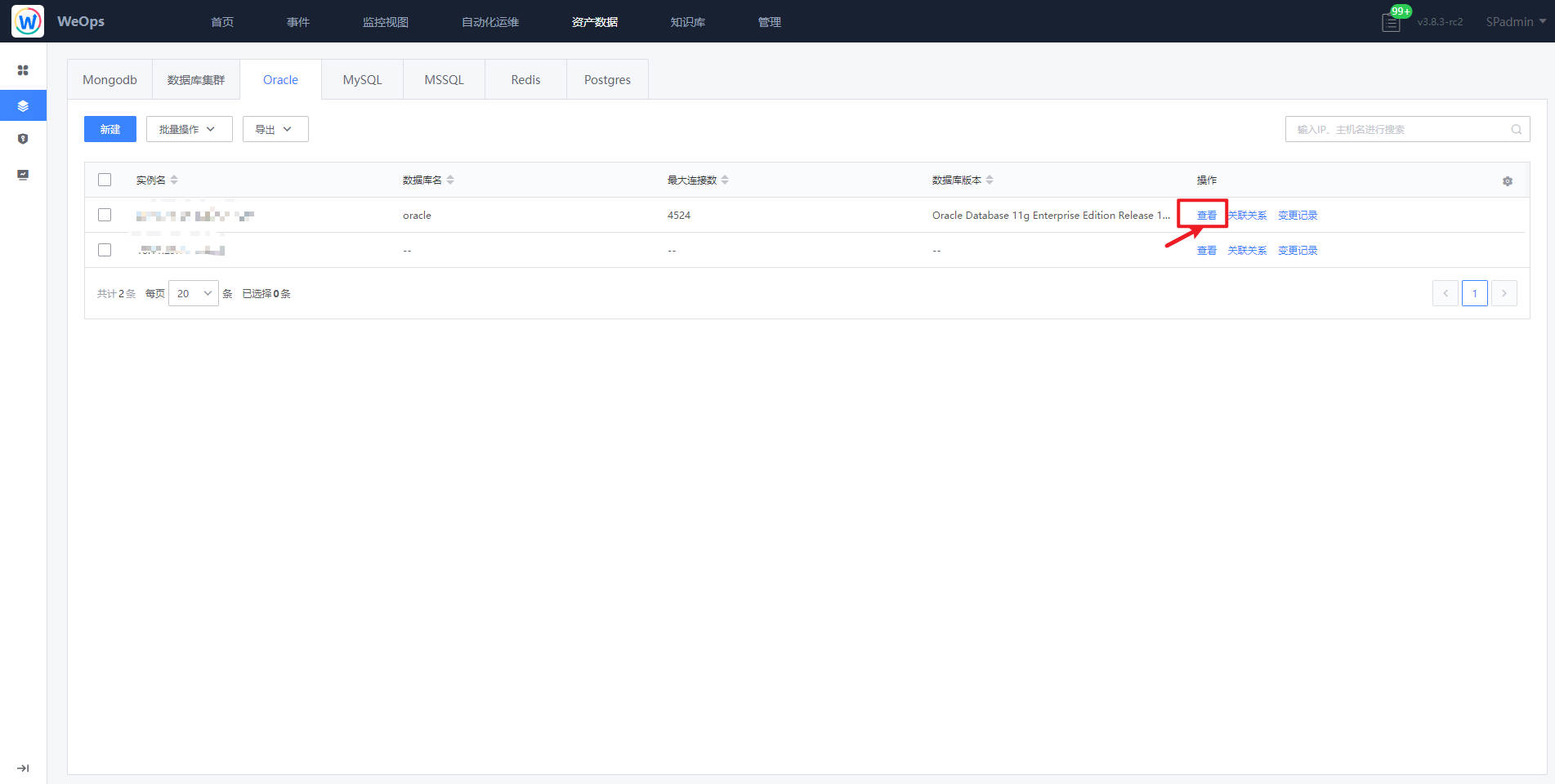
点击“关联信息”中的“关联管理”,建立该Oracle数据库和对应主机的关联关系。

手动创建的资产的配置信息需求手动维护和更新。
方法二:自动发现
路径:管理-资产管理-自动发现
选择数据库-Oracle,创建自动发现任务,新建任务时,选择资产的IP范围、输入对应凭据
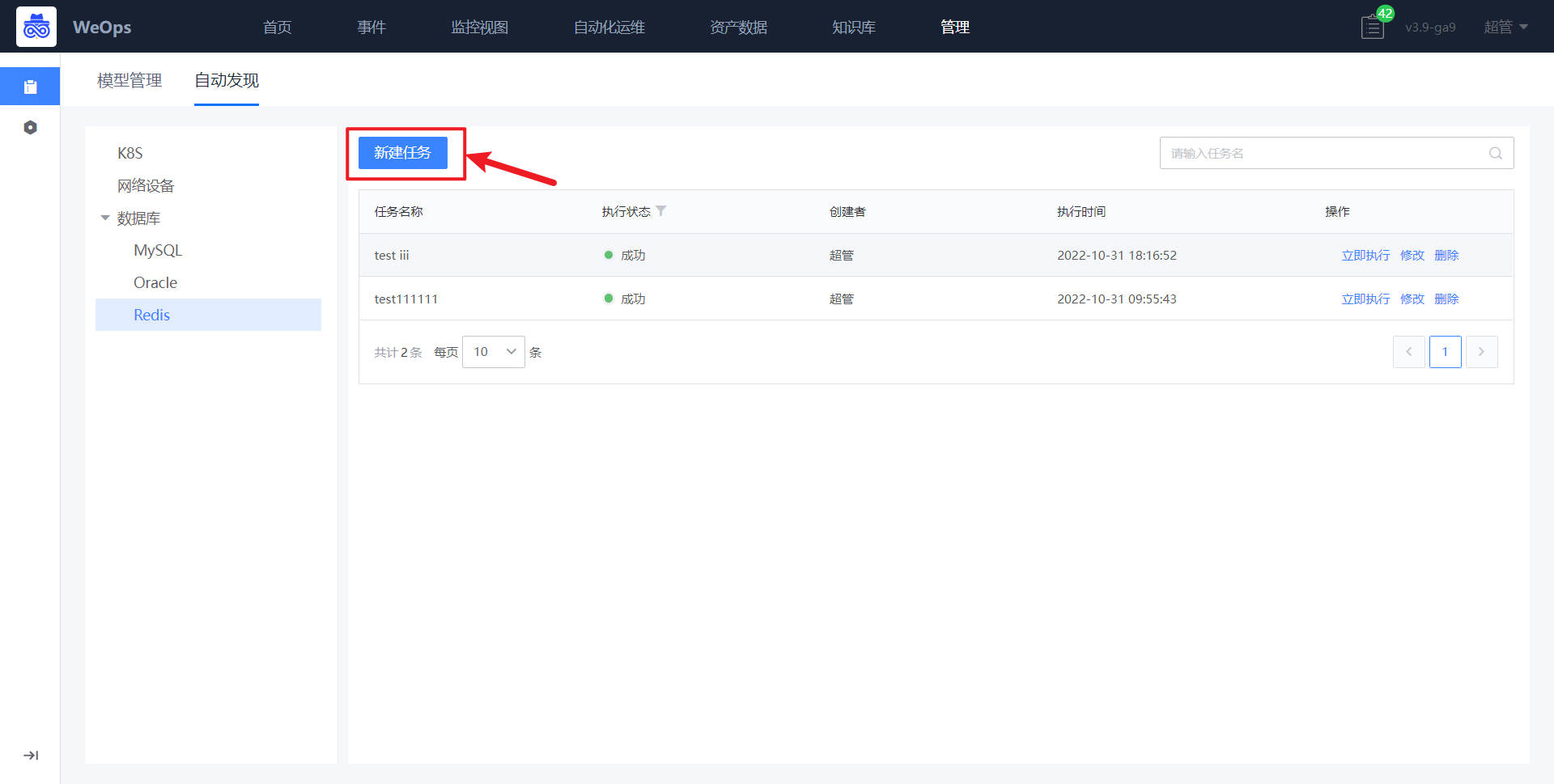
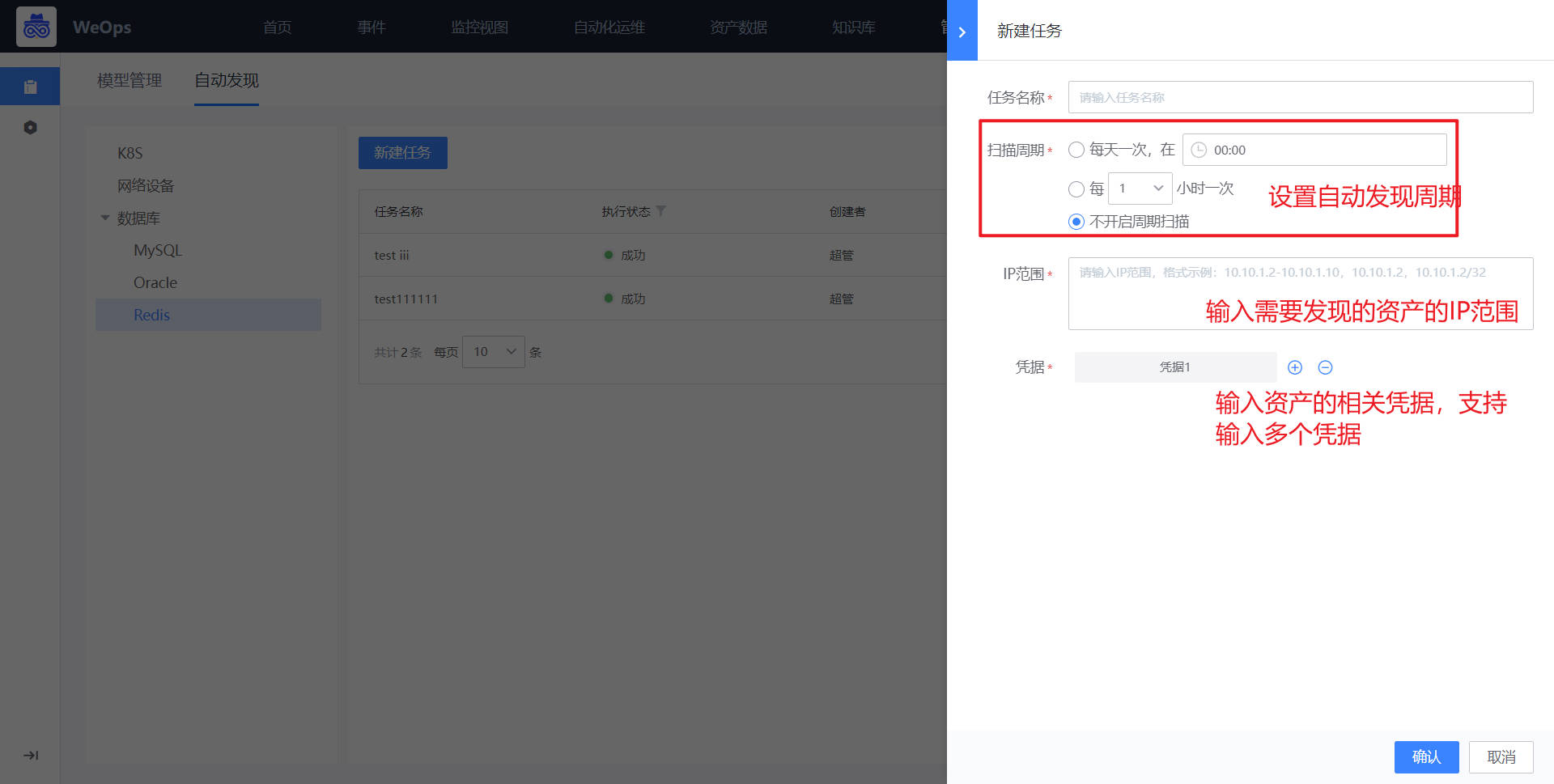
自动发现任务执行完成后,资产数据有如下更新:新增Oracle资产、根据周期实时更新资产配置信息、自动关联对应主机。


1.4 云平台纳管(以腾讯云为例)preview
背景介绍:运维部门需要对云平台(VMware/阿里云/腾讯云)进行资产管理,并展示其直接的关联关系,可以在WeOps的资产数据进行管理,进行云平台的纳管,有两种方式进行:一是手动纳管,手动维护资产信息和关联关系,二是自动发现,自动发现资产信息、关联关系,并自动更新。这里以阿里云为例进行介绍。
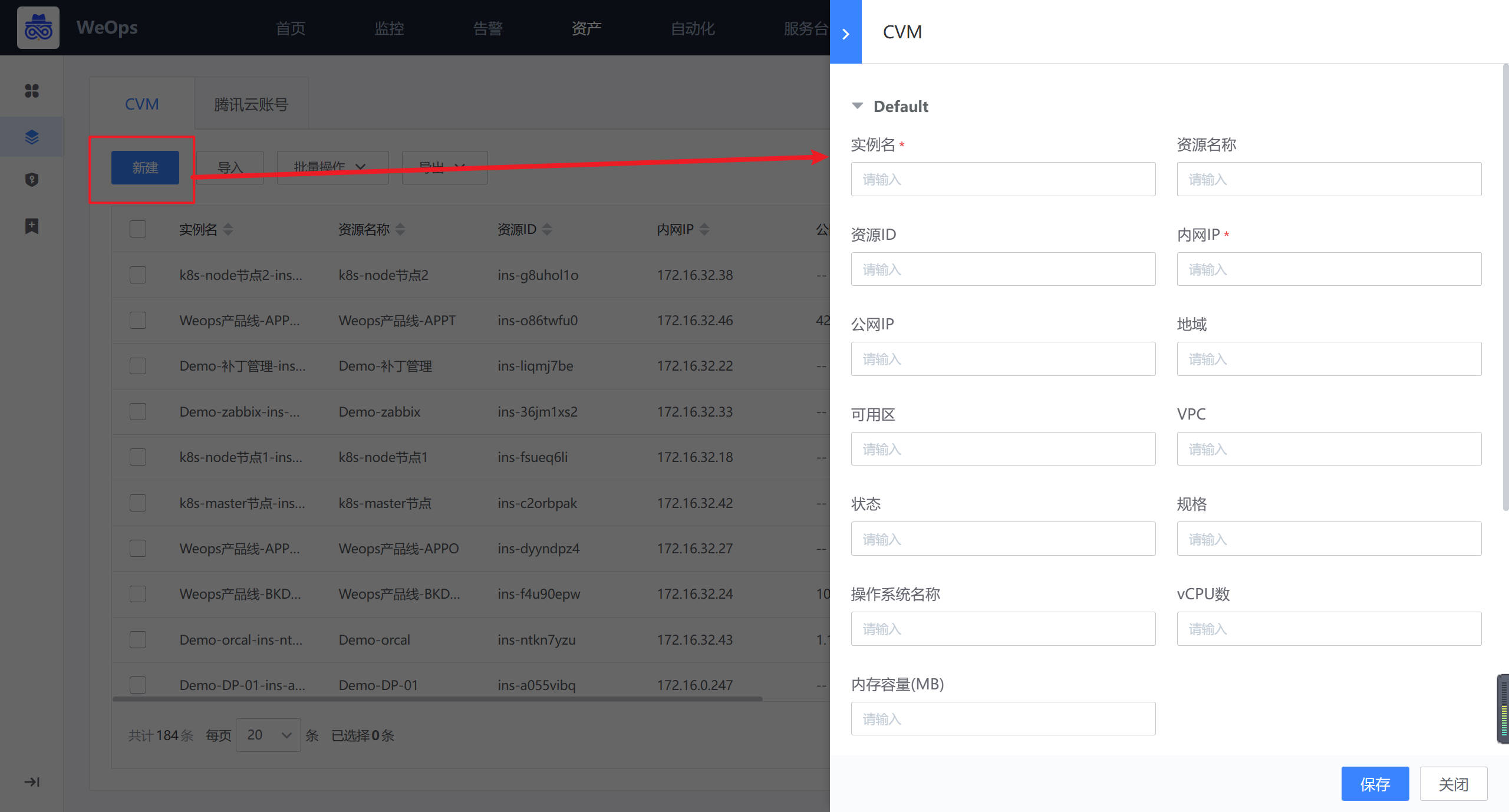
方法一:手动纳管
路径:资源-资源记录-腾讯云
如下图,在“腾讯云—云账户”页面,点击“新建”按钮,进行腾讯云账号的创建,这里的“腾讯云账号”是为了区分不同账号下的云服务器而创建的资产模型

如下图,在“腾讯云-CVM”页面,点击“新建”按钮,进行云服务器的创建,并手动填写对应信息。
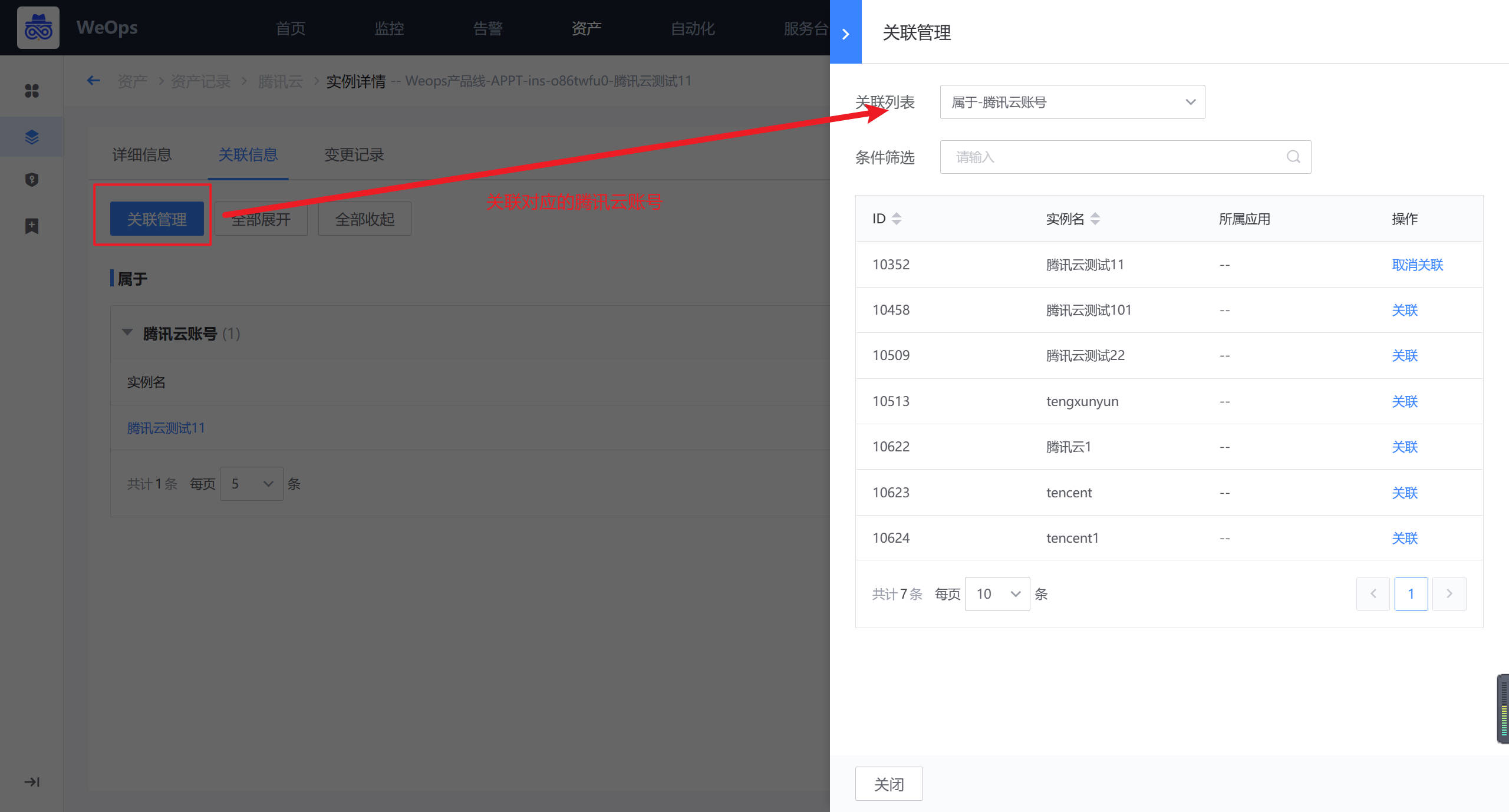
创建完成后,在CVM的实例详情中,进行其与云账户的关联。
方法二:自动发现
路径:资源-资源记录-腾讯云
如下图,在“腾讯云—云账户”页面,点击“新建”按钮,先进行腾讯云账号的创建。
路径:管理-资产管理-自动发现(腾讯云)
在自动发现页面,选择腾讯云,进行腾讯云某个账号下云服务器的发现和采集。在创建采集任务时,可以选择使用已有的凭据,云平台的凭据可在“资产-凭据管理-云平台”中维护,若无关联凭据,在新建自动发现任务时可以新建凭据。
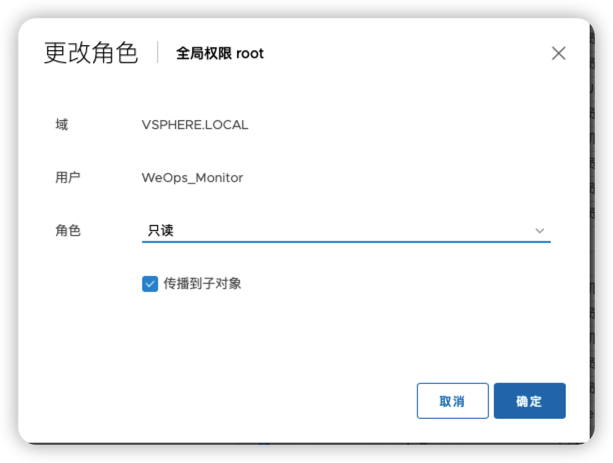
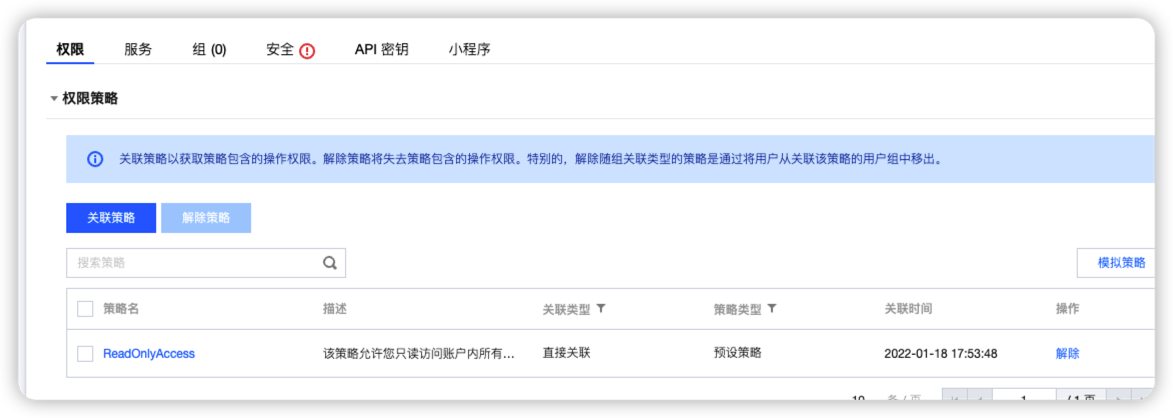
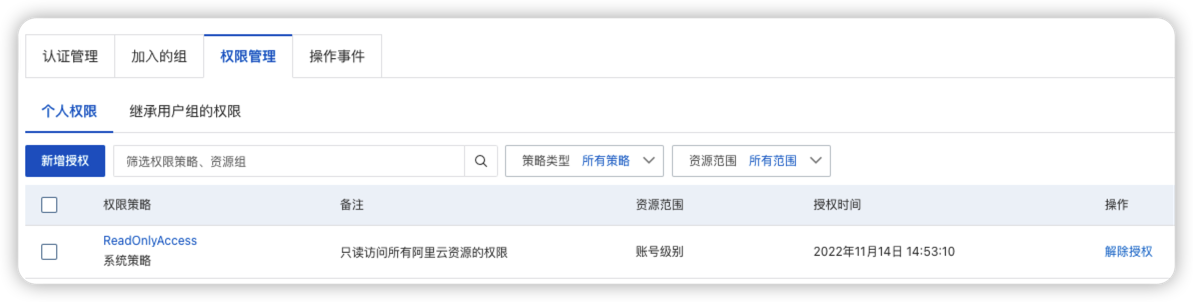
- 阿里云/腾讯云/VMware设置自动发现的账号需要的最小化权限为:只读权限,具体如下
- 域名配置如下:阿里云的域名都是带{资源}+{region}的,例如ecs.cn-guangzhou.aliyuncs.com。腾讯云的域名带{资源}的,例如cvm.tencentcloudapi.com
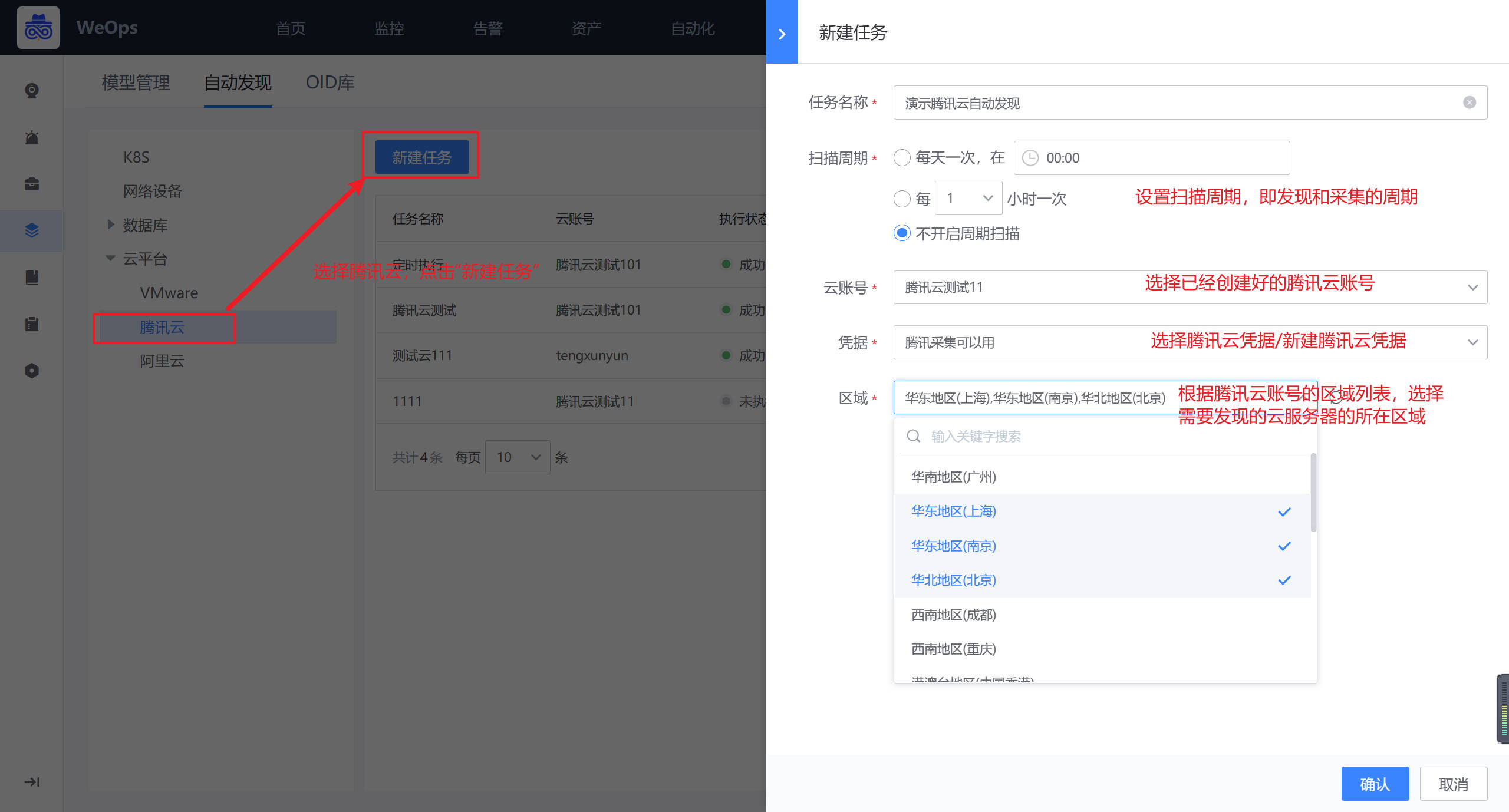
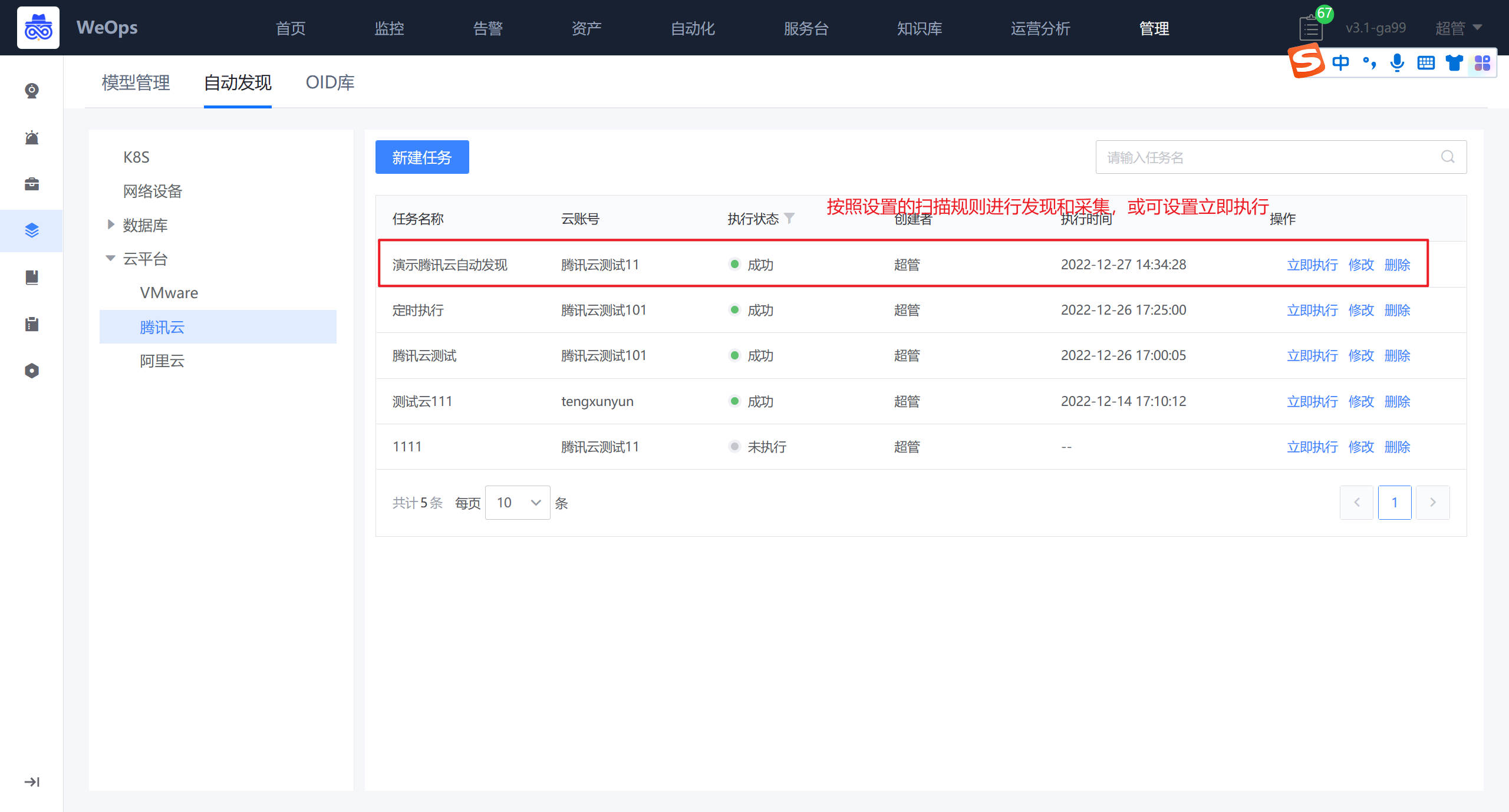
自动发现完之后,自动采集该腾讯云账号下的所有的CVM及其信息,并在“资产记录-腾讯云-CVM”中自动新增/更新信息。
1.5 K8S纳管preview
背景介绍:需要对K8S集群以及相关的命名空间、工作负载、pod、node的信息进行采集和呈现。“WeOps-资产记录”已经内置K8S五项模型及关联关系,包括“K8S集群”、“K8S命名空间”、“K8S工作负载”、“Pod”、“Node”
原理介绍:
WeOps对k8s进行配置发现与采集的原理如图
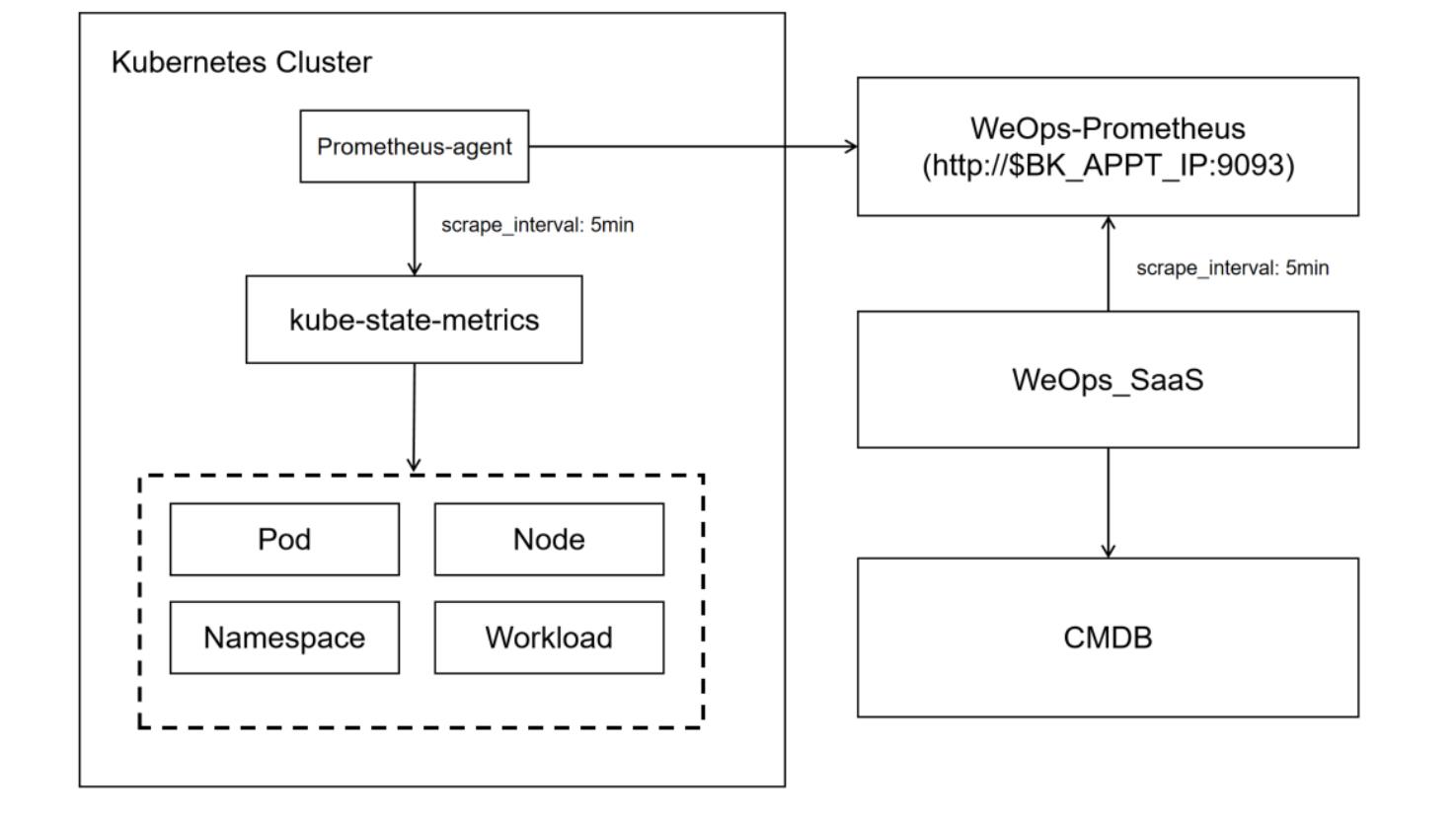
需要额外部署的组件和功能:
1、kube-state-metrics: 集群配置信息的发现采集,需要其他服务主动调取,采用helm的形式在k8s中部署
2、Prometheus-agent: 从kube-state-metrics中获取数据,并推送到weops-prometheus,用helm chart的形式在k8s中部署
3、weops-promtheus: 数据临时存储,weops从此获取原始的资产数据,用docker的形式部署在appt
整体步骤:K8S部署操作——手动创建K8S集群实例——设置自动采集任务——自动采集K8S命名空间、工作负载、pod、node信息,并形成关联拓扑图
Step1:K8S部署操作
1、环境准备(basic auth的用户名密码默认为admin:admin,可按需调整)
在蓝鲸配置平台导入k8s模型组(关联关系必须准确)
#!/bin/bash
mkdir /data/weops/prometheus/tsdb -p
cd /data/weops/prometheus
cat << "EOF" > prometheus-web.yml
basic_auth_users:
admin: $2y$12$Dx1PAPXkUcW10NhuRh.3iuHHDzmT7h6sgv1siHXksRbYk8RrqKkvC
EOF
cat << "EOF" > prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
EOF
docker load < prometheus.tgz
2、在appt启动weops附带的prometheus实例:
docker run -d --net=host -v /data/weops/prometheus/prometheus-web.yml:/opt/bitnami/prometheus/conf/prometheus-web.yml -v /data/weops/prometheus/prometheus.yml:/opt/bitnami/prometheus/conf/prometheus.yml bitnami/prometheus --name=prometheus --web.listen-address=0.0.0.0:9093 --web.enable-remote-write-receiver --web.config.file=/opt/bitnami/prometheus/conf/prometheus-web.yml --config.file=/opt/bitnami/prometheus/conf/prometheus.yml --storage.tsdb.retention.time=30m
运行后telnet localhost 9093 验证部署是否成功
3、在k8s集群中部署kube-state-metrics和promtheus(要求客户的镜像仓库中已有kube-state-metricsd:v2.5.0和prometheus:2.38.0镜像,附件附带镜像包可供客户导入)
在k8s的control-plane上解压helm chart
tar -zxvf weops-kubenetes-discovery-3.10.0.tgz && cd weops-kubenetes-discovery/
修改values.yml:
# prometheus镜像
image:
repository: bitnami/prometheus:2.38.0
tag: 2.38.0
pullPolicy: IfNotPresent
# prometheus资源限制
resources: {}
# limits:
# cpu: 100m
# memory: 64Mi
# requests:
# cpu: 10m
# memory: 32Mi
# weops内置的Prometheus目录,默认开启basic auth,这里的ip是weops附带的prometheus实例ip,推荐为appt
weopsPrometheusUrl: http://admin:admin@10.10.25.156:9093
# 想要使用其他kube-state-metrics时填写,仅在kubeStateMetrics.enable为false时生效
kubeStateMetricsUrl: ""
# k8s集群标签,用于区分多集群接入
kubeClusterLabel: k8s-1
# 数据采集时间,发现默认5分钟
scrape_interval: 5m
evaluation_interval: 5m
# 启用内置kube-state-metrics
kubeStateMetrics:
enabled: true
image:
repository: registry.k8s.io/kube-state-metrics/kube-state-metrics
tag: v2.5.0
pullPolicy: IfNotPresent
imagePullSecrets: []
resources: {}
# limits:
# cpu: 100m
# memory: 64Mi
# requests:
# cpu: 10m
# memory: 32Mi
部署采集端:
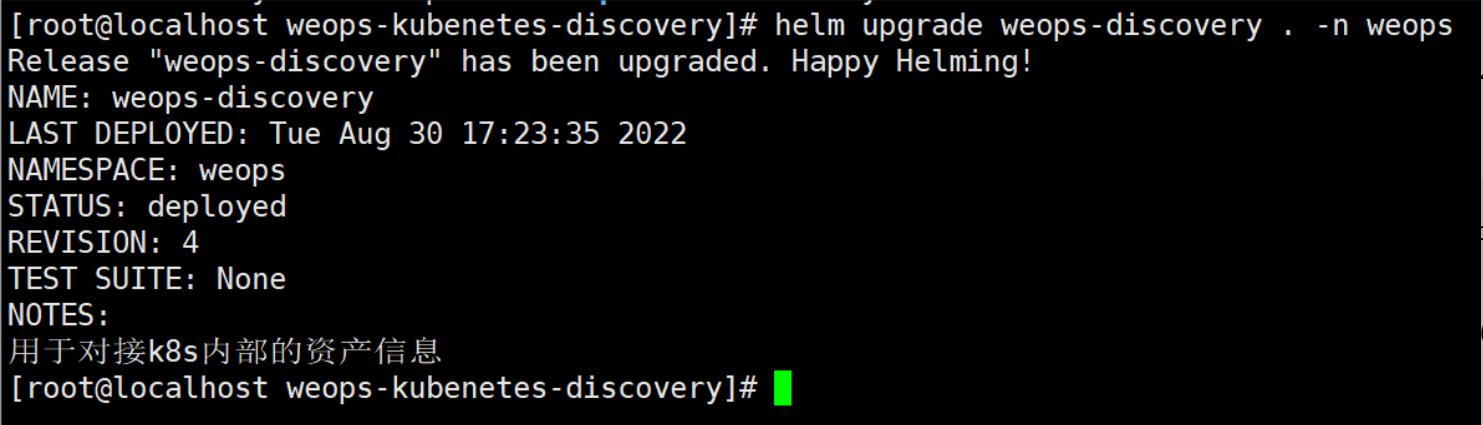
helm install weops-discovery . -n weops --create-namespace
正常应输出(REVISION: 1):
检查pod状态:
kubectl get po -n weops

检查prometheus-agent状态:
Step2:创建K8S集群实例
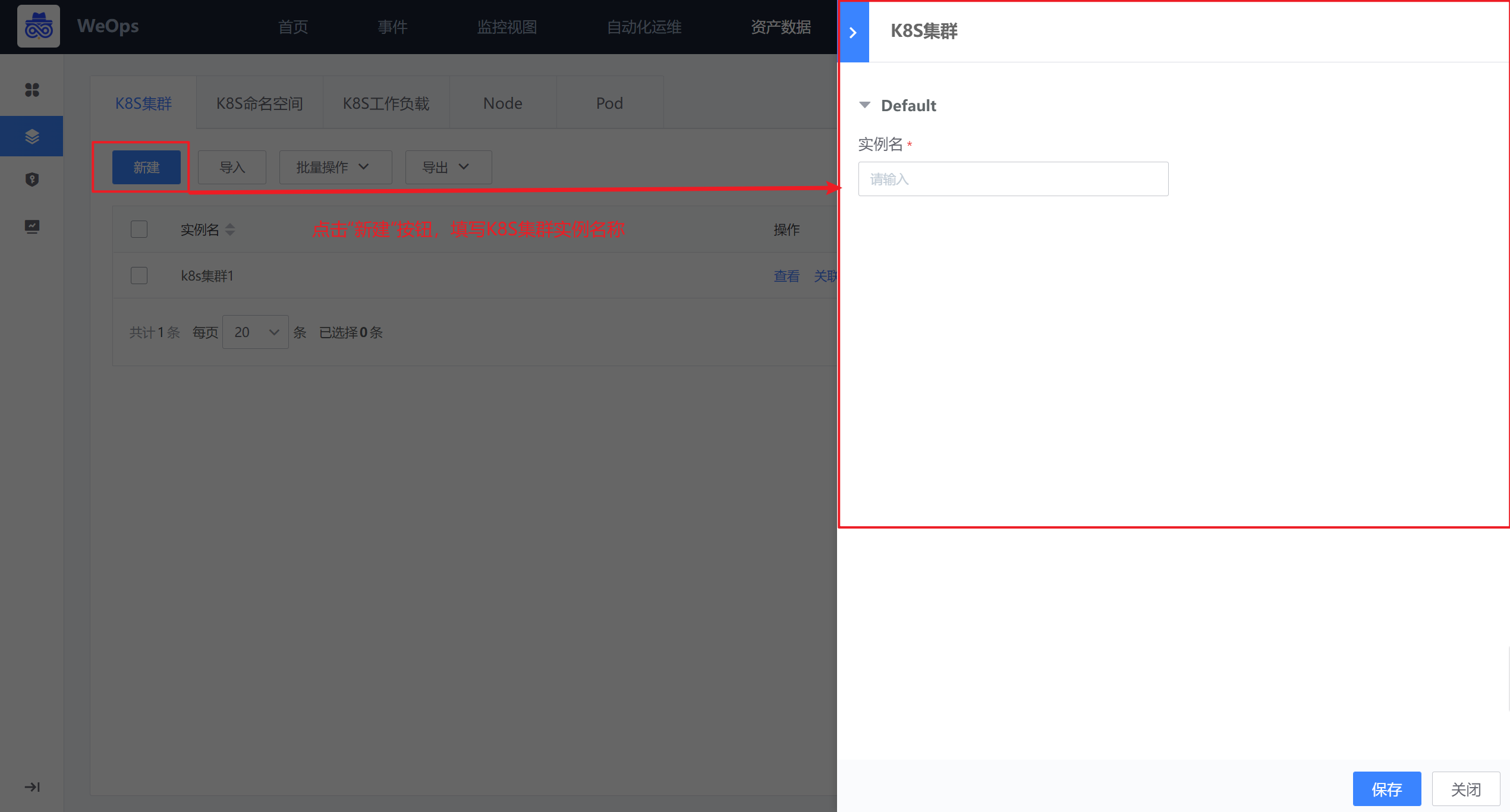
路径:资源-资源记录-K8S(K8S集群)
如下图,在K8S集群页面中点击“新建”按钮,进行K8S集群实例的创建
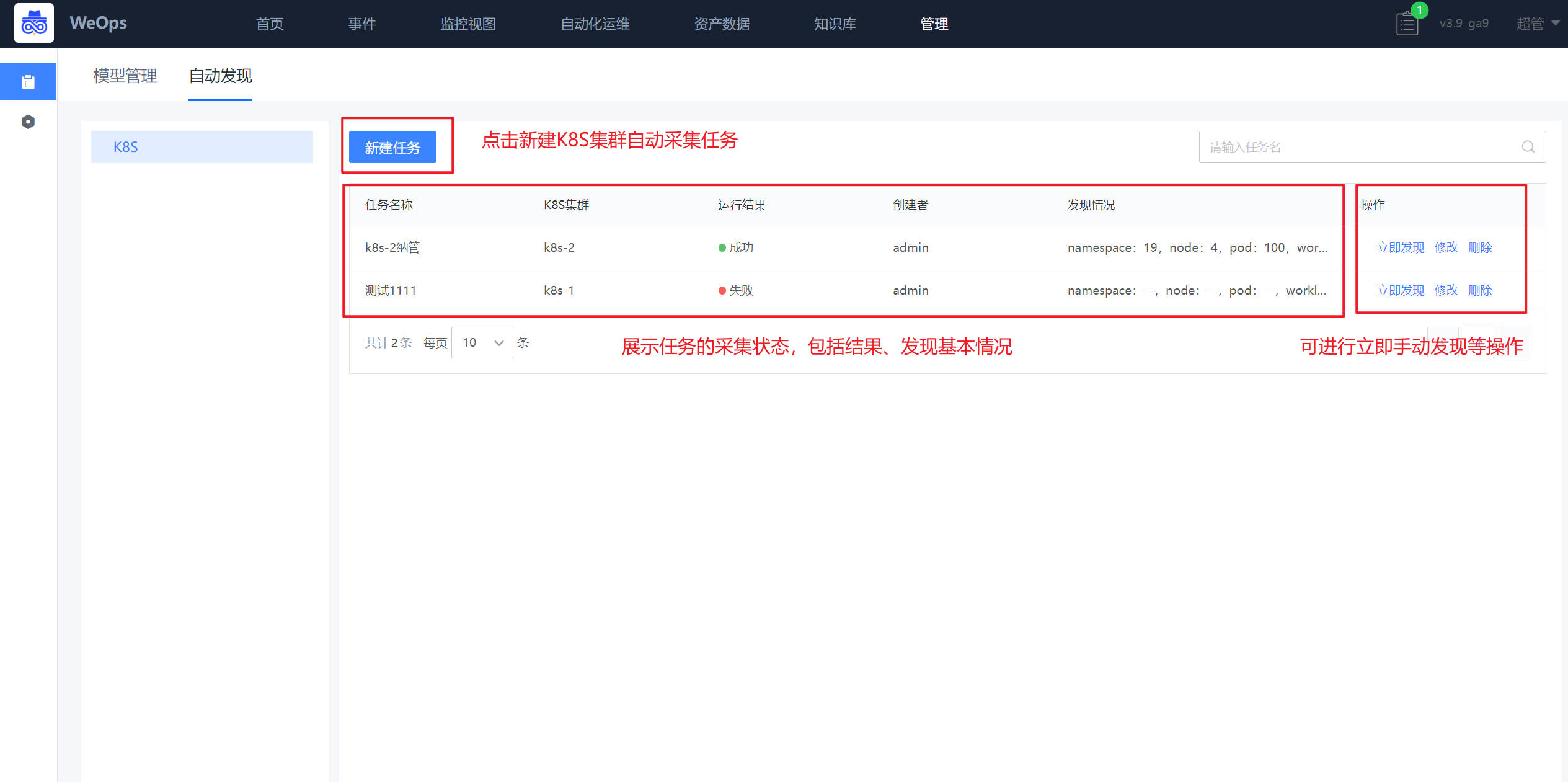
Step3:创建K8S集群自动发现
路径:管理-资产管理-自动发现
如下图,在自动页面中点击“新建”按钮,进行K8S集群自动发现的任务的创建,创建时仅需要填写任务名称、选择需要采集K8S集群实例名称、设置采集频率即可。
任务创建完成后,可根据设置的采集频率进行采集,也可点击“立即发现”

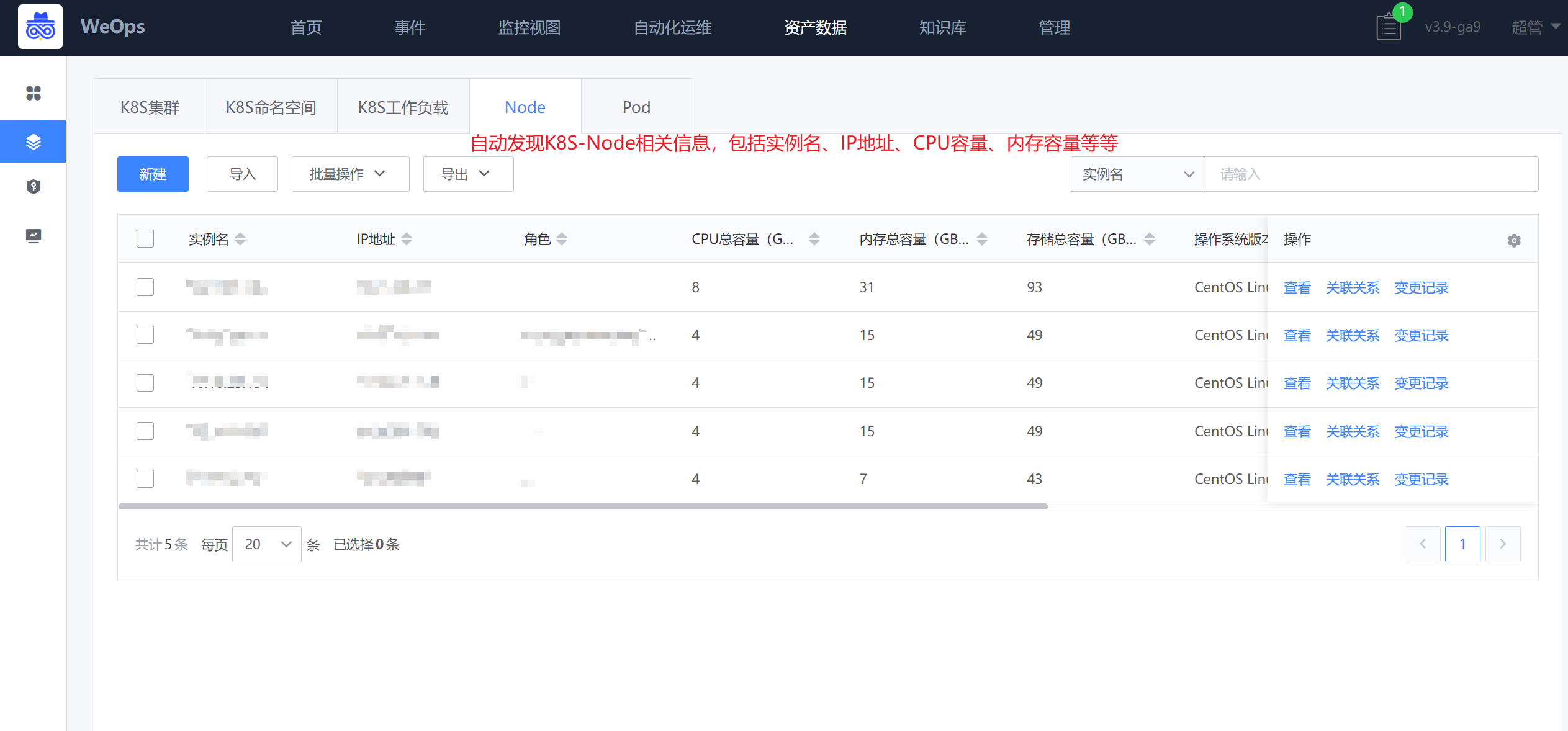
Step4:自动发现相关信息
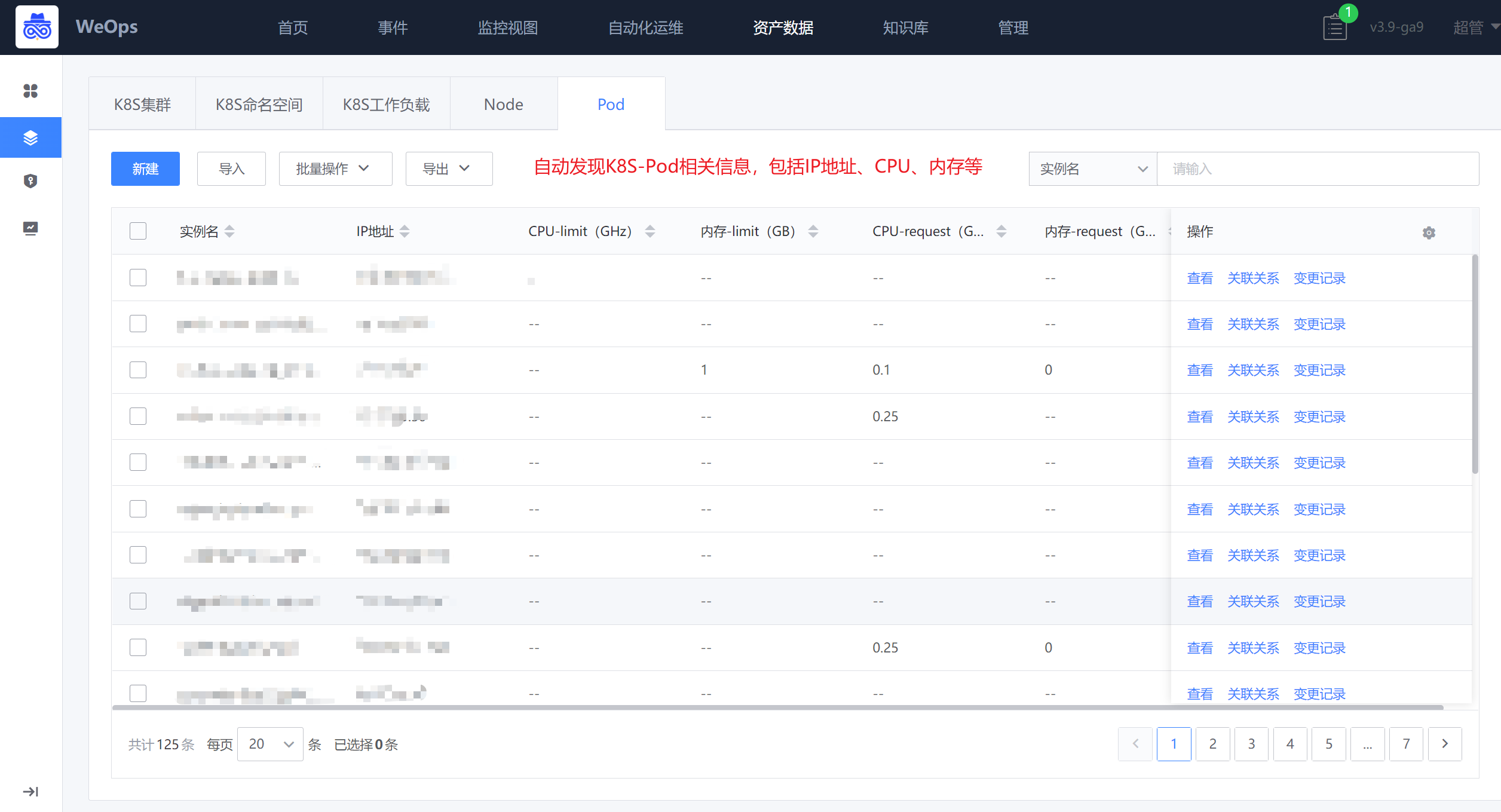
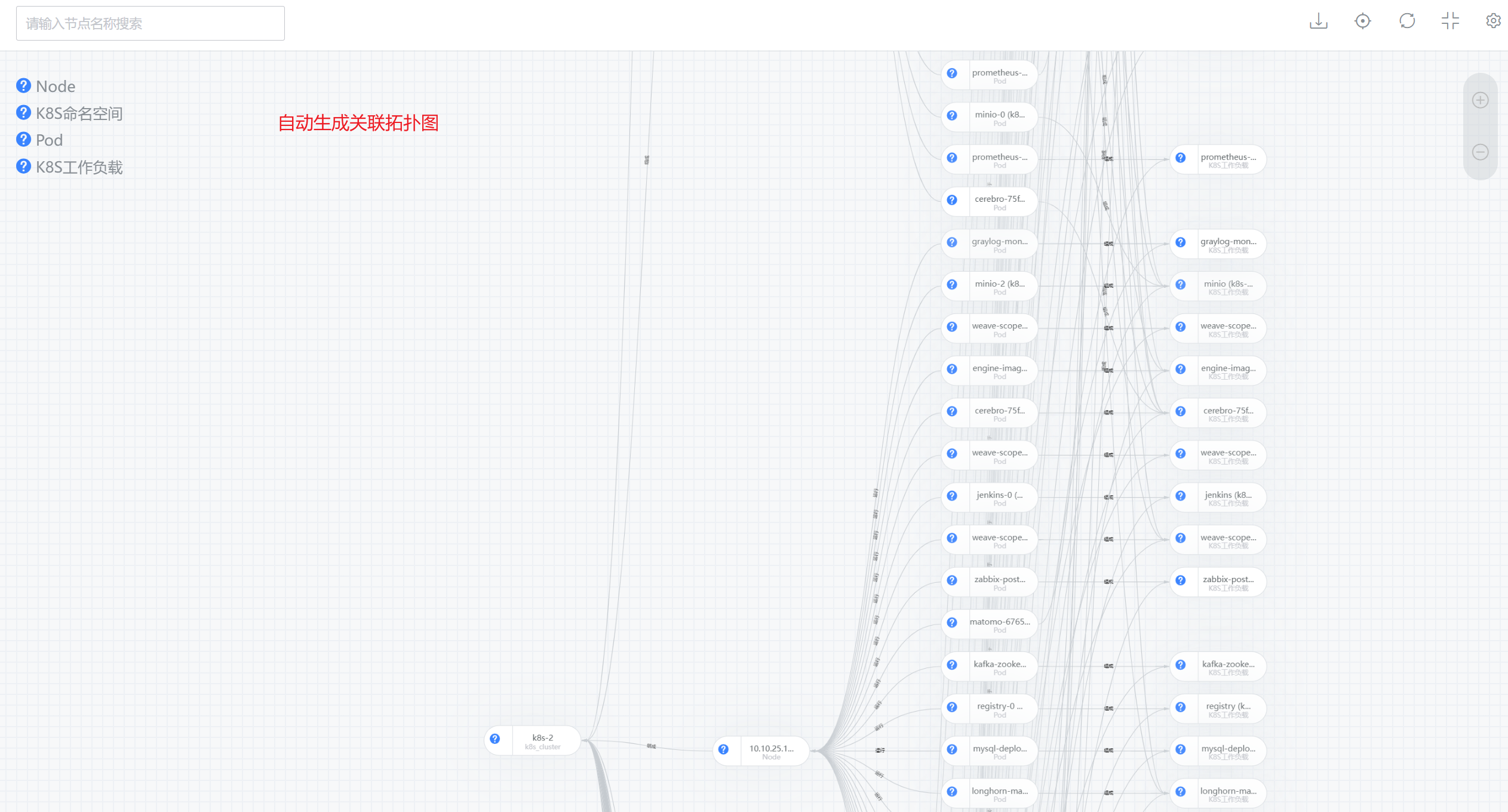
路径:资源-资源记录-K8S(K8S命名空间、K8S工作负载、Pod、Node)
设置自动发现任务后,自动发现该K8S集群下的命名空间、工作负载、Pod、Node相关实例信息,及其关联关系


1.6 网络设备纳管preview
背景介绍:运维部门需要对网络设备(交换机/路由器/负载均衡/防火墙)进行资产管理,并展示其直接的关联关系,可以在WeOps的资产数据进行管理,第一步需要进行网络设备的纳管,有两种方式进行:一是手动纳管,手动维护资产信息和关联关系,二是自动发现,自动发现资产信息、关联关系,并自动更新。这里以交换机为例进行介绍。
方法一:手动纳管
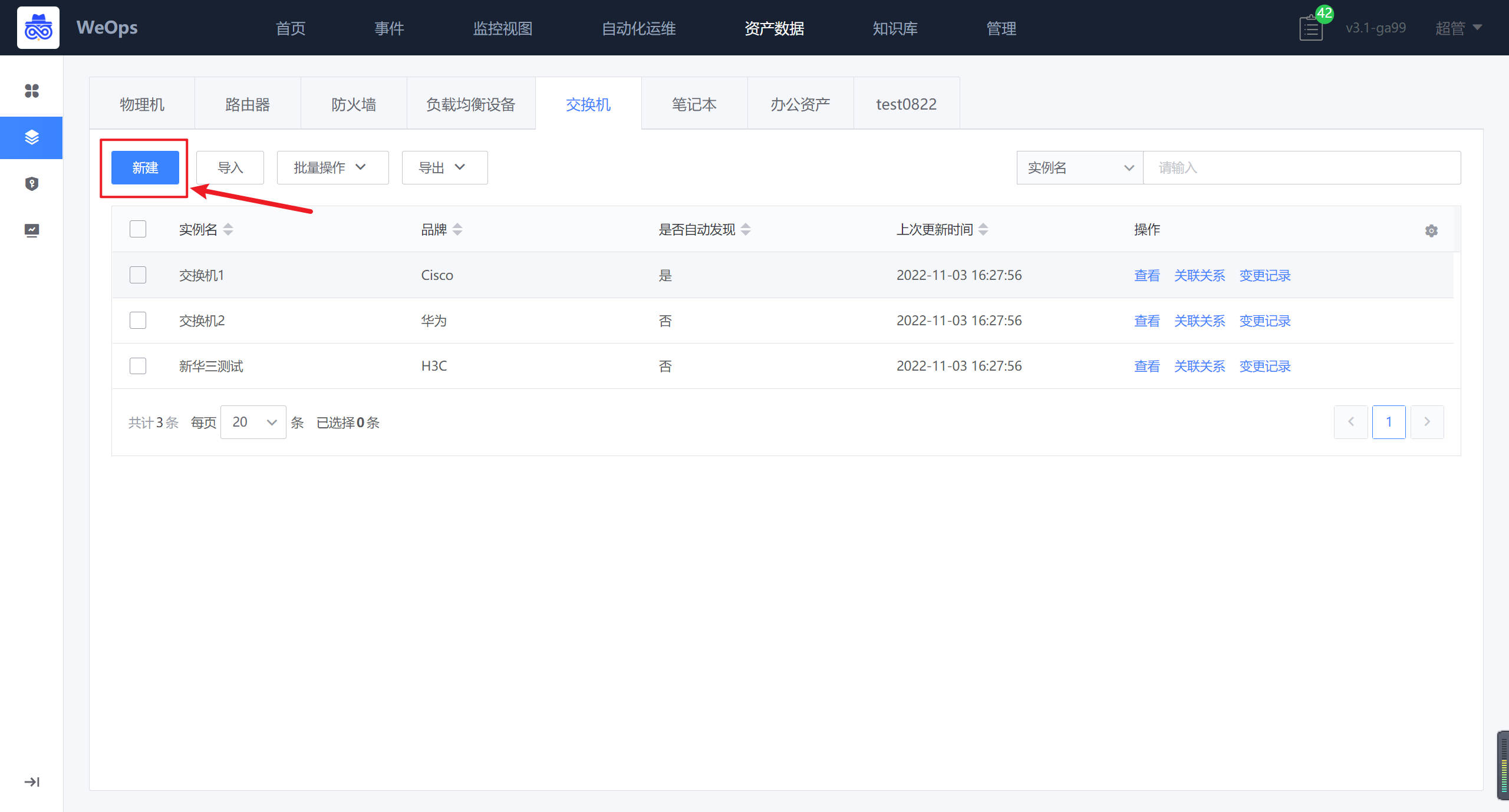
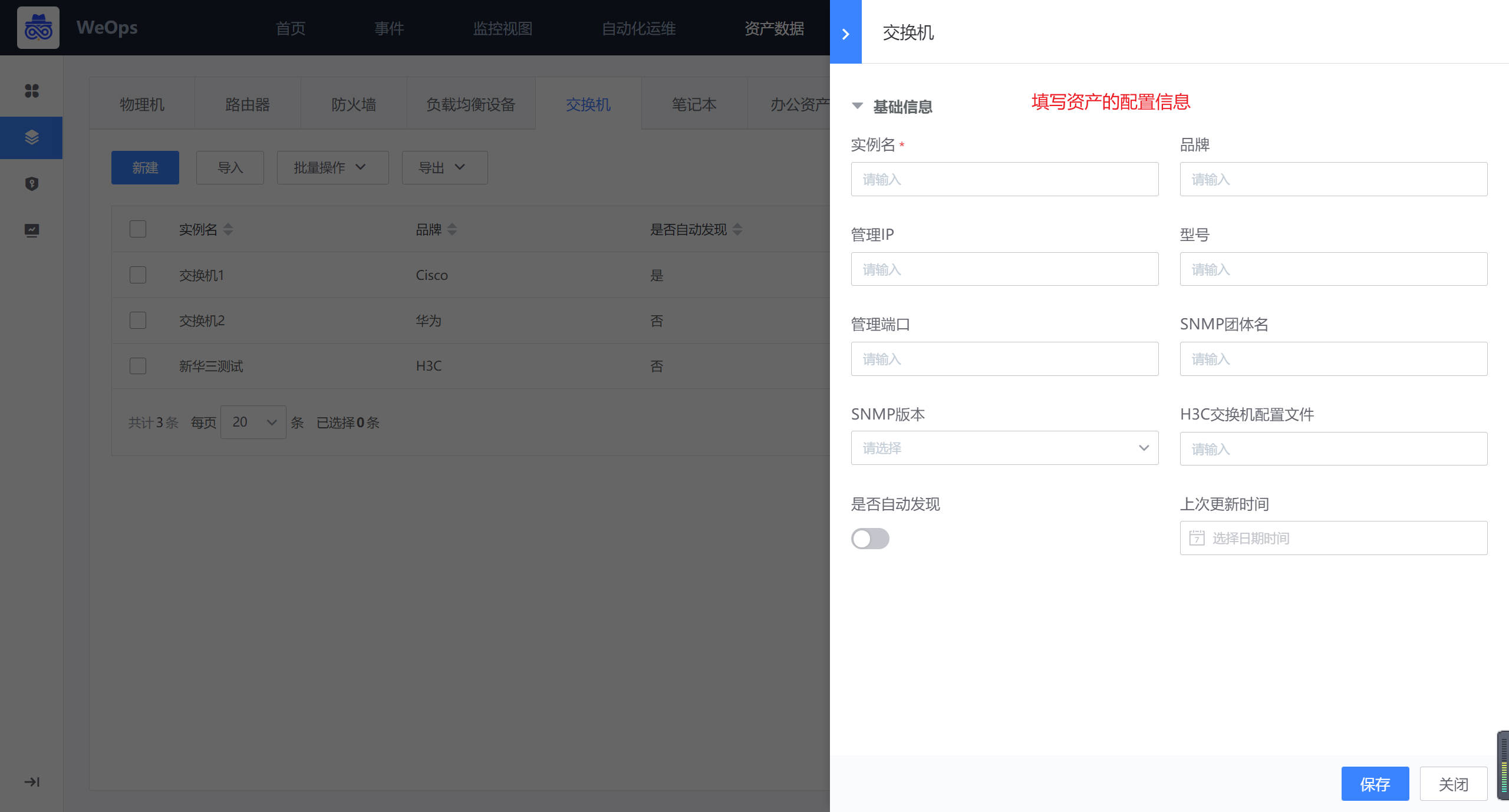
路径:资源-资源记录-基础设备(交换机)
在交换机的页面,点击“新建”按钮,进行资产的新建,填写必要的信息,包括品牌/型号等等,手动创建的资产需要手动维护/更新配置信息。
方法二:自动发现
路径:管理-资产管理-自动发现(网络设备)
在自动发现页面,选择网络设备,进行网络设备的自动发现任务的创建。
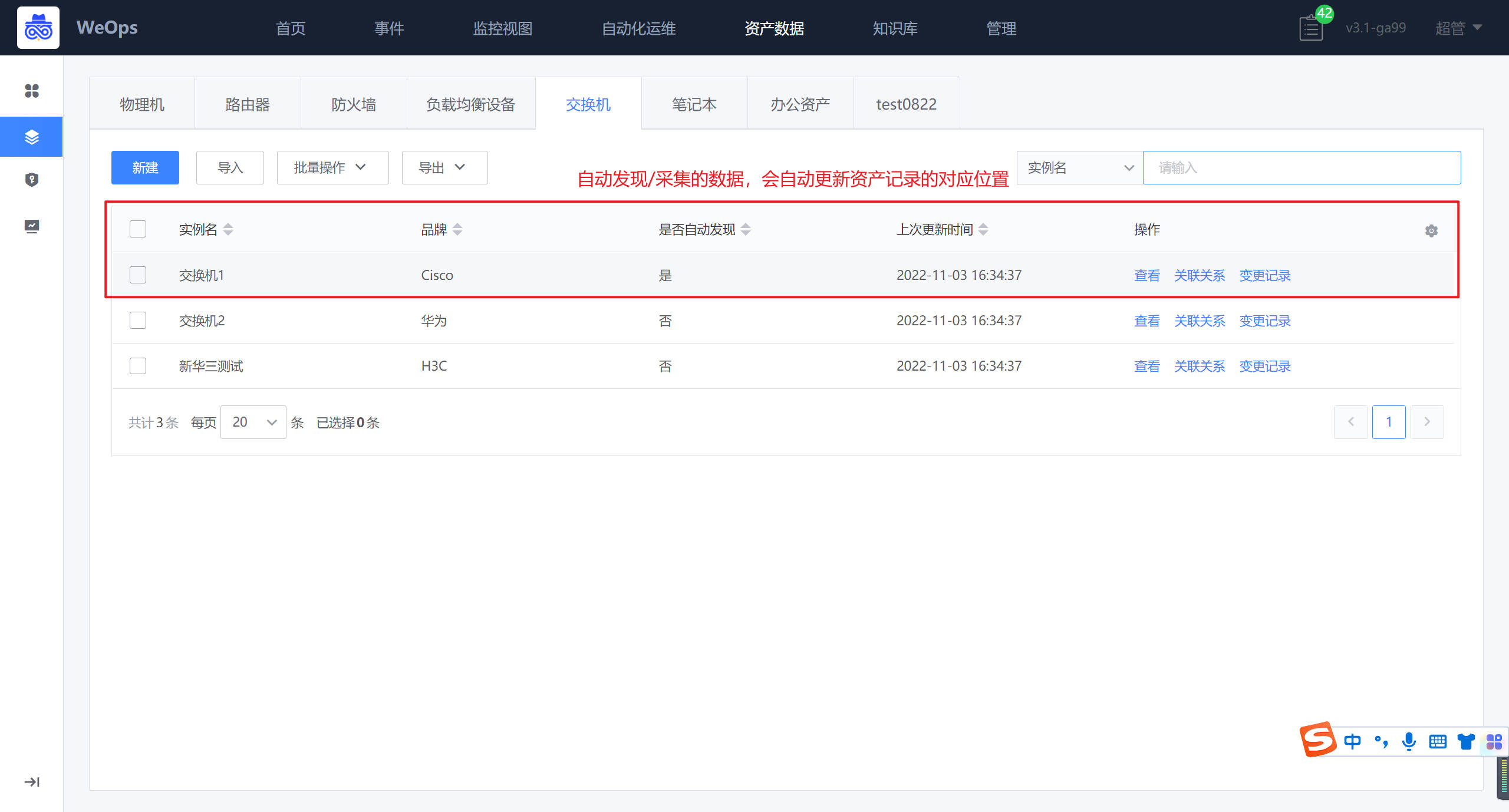
自动发现完成以后,自动采集到的网络设备已经对应的品牌、型号会自动更新到“资产数据-资产记录-交换机“里面
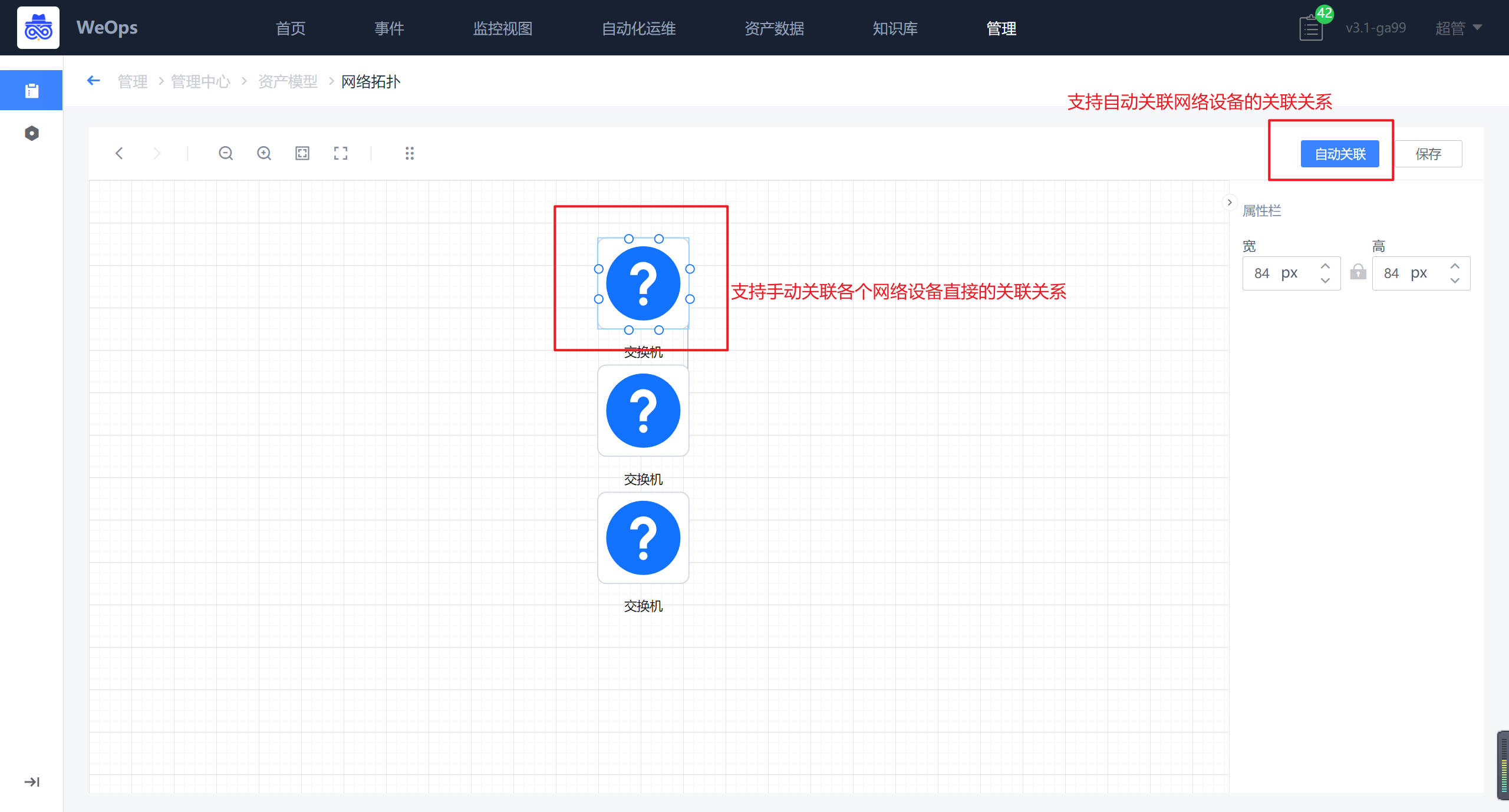
网络拓扑,对于自动发现的网络设备,展示了各个设备的拓扑图,可以通过自动关联/手动关联的方式,完善网络设备的拓扑图。

- 注:只有符合内置OID库的网络设备品牌和型号的设备才可以被自动发现,若需要拓展OID库,如下图,可进行不同品牌型号的网络设备的OID新增,新增完成后,可进行自动发现和采集。

1.7 配置文件纳管
背景介绍:运维部门需要对资源的配置文件进行资产管理,方便查看和使用,目前WeOps已经内置好“配置文件”的模型,将需要配置文件的资源模型与“配置文件”的模型相关联,即可对该资源的配置文件进行管理
Step1:创建关联
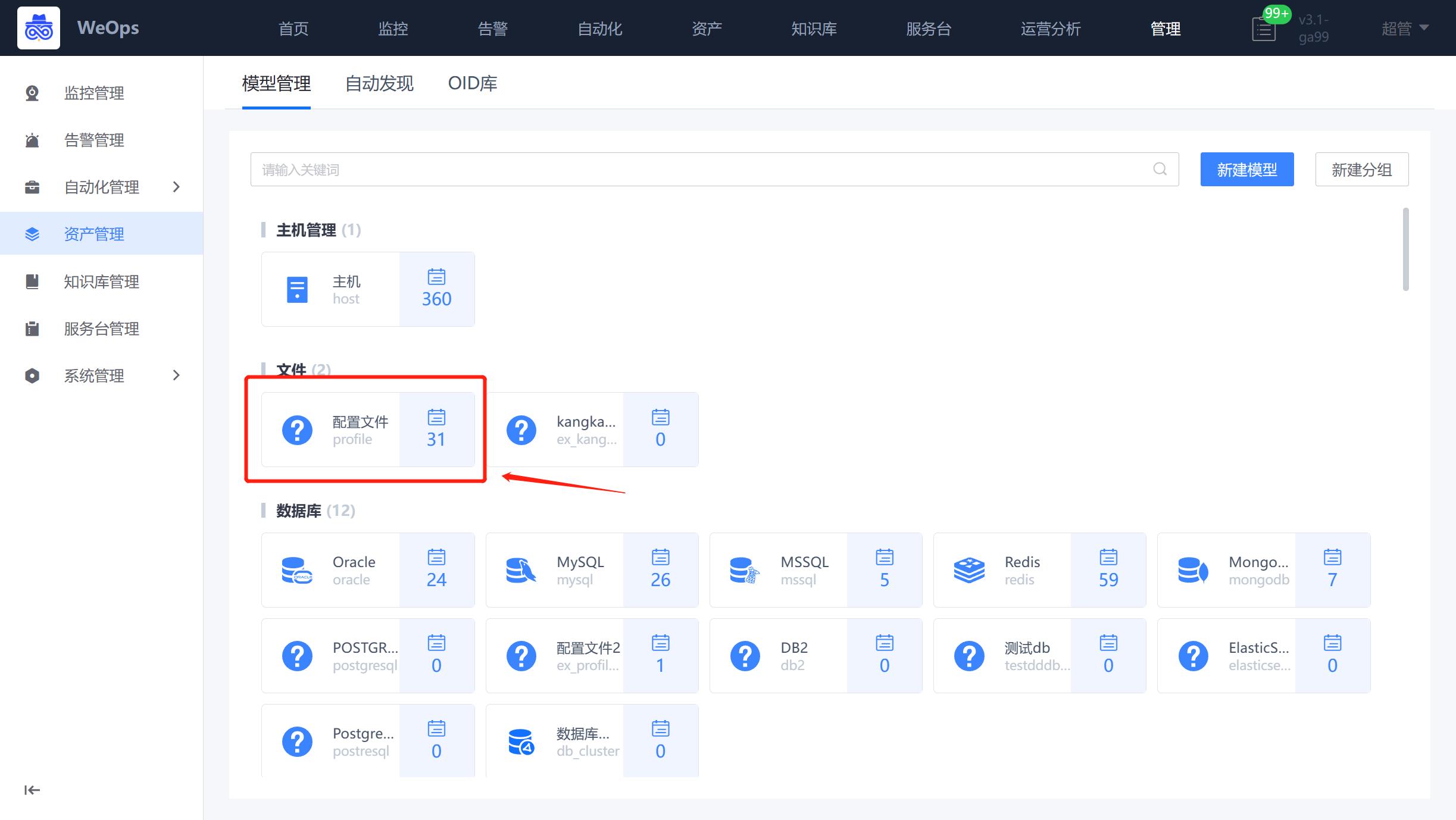
路径:管理-资产管理-模型管理
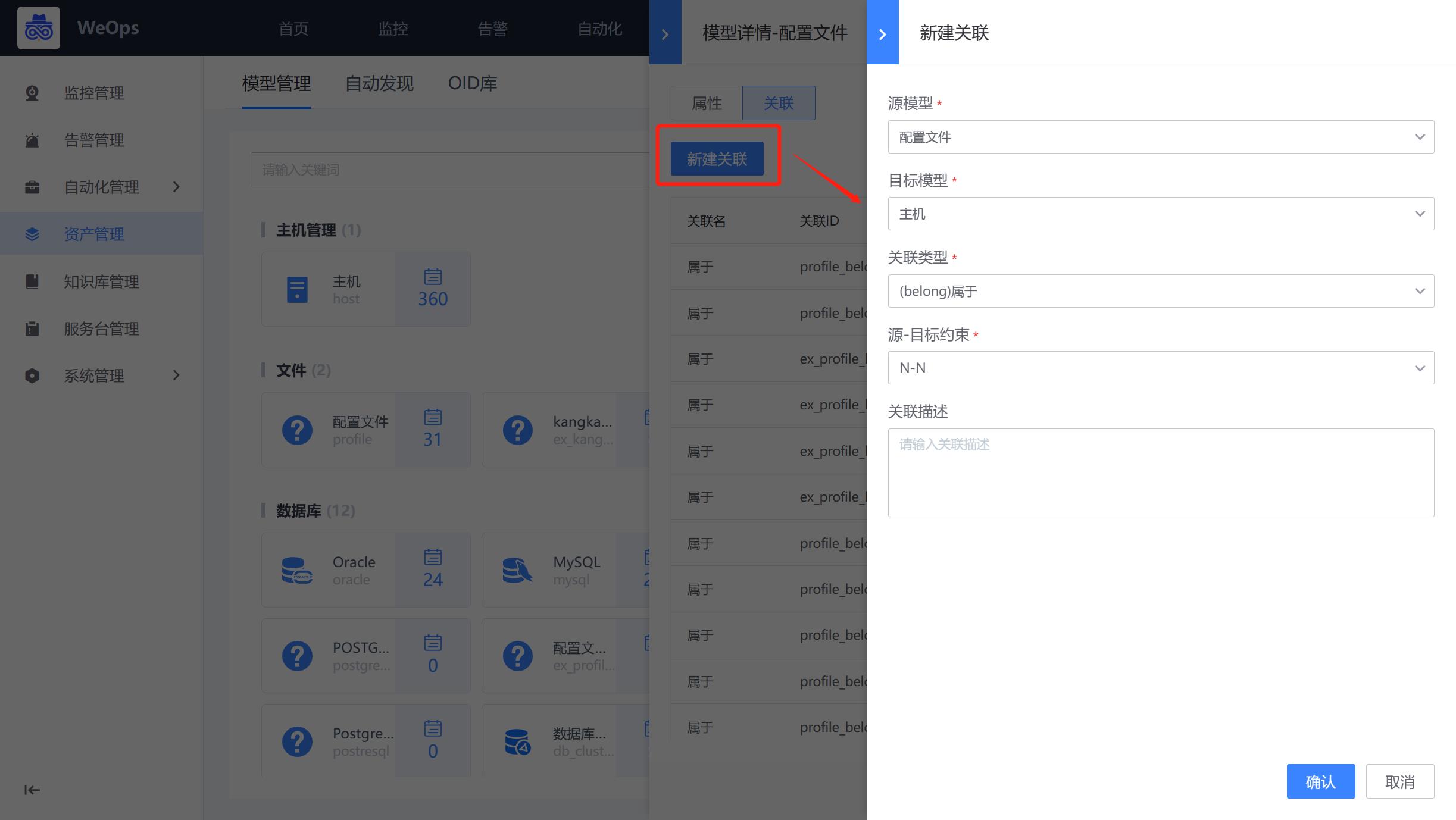
如下图,以主机为例,在资产管理-模型管理中,点击“配置文件”模型的按钮,在“关联”中,创建关联,选择目标模型“主机”,关联类型“belong”,约束条件“N-N”
Step2:配置文件管理
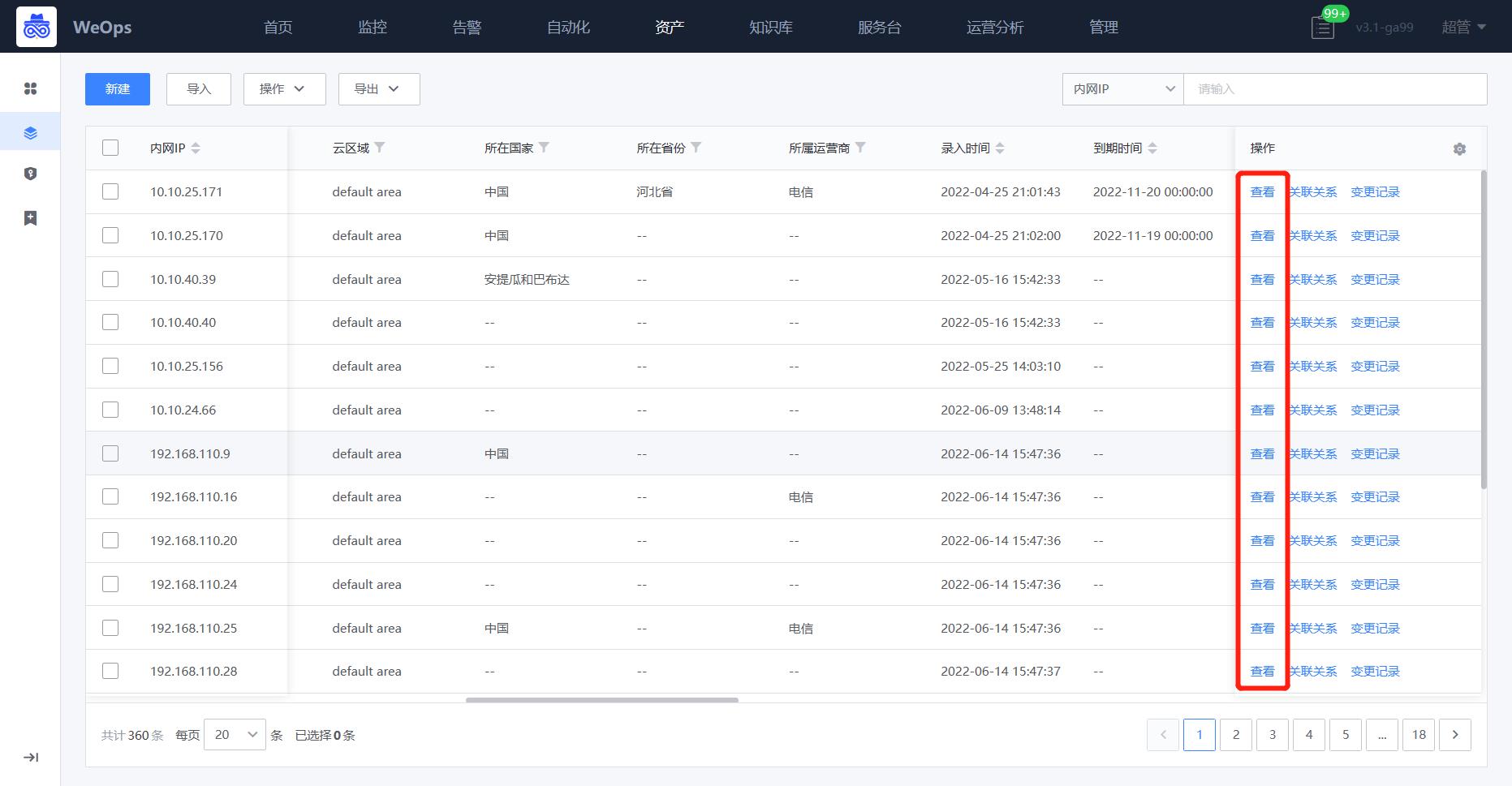
路径:资源-资源记录-主机
当资源模型的关联配置完成以后,就可以在主机的详情页看到配置文件的tab,如下图,在主机列表中,点击“查看”按钮
如下图,配置文件进行管理,可以进行配置文件的创建,选择对应的维护人,每个配置文件点击详情后,可以查看这个配置文件的具体内容,包括基本信息、版本列表和具体文档、变更记录等信息。
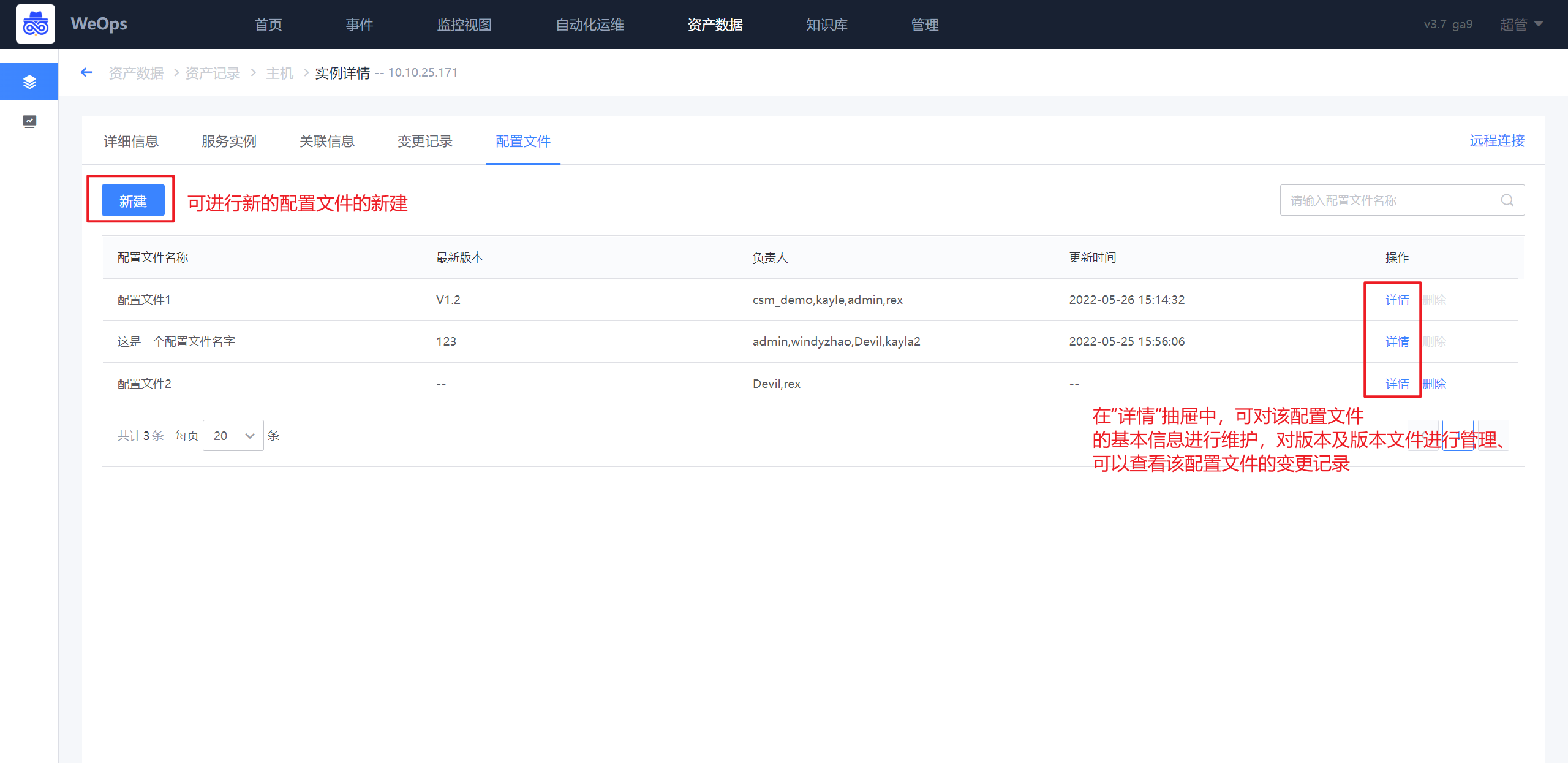
针对版本列表,支持上传不同版本文档的上传、下载、预览、删除等等
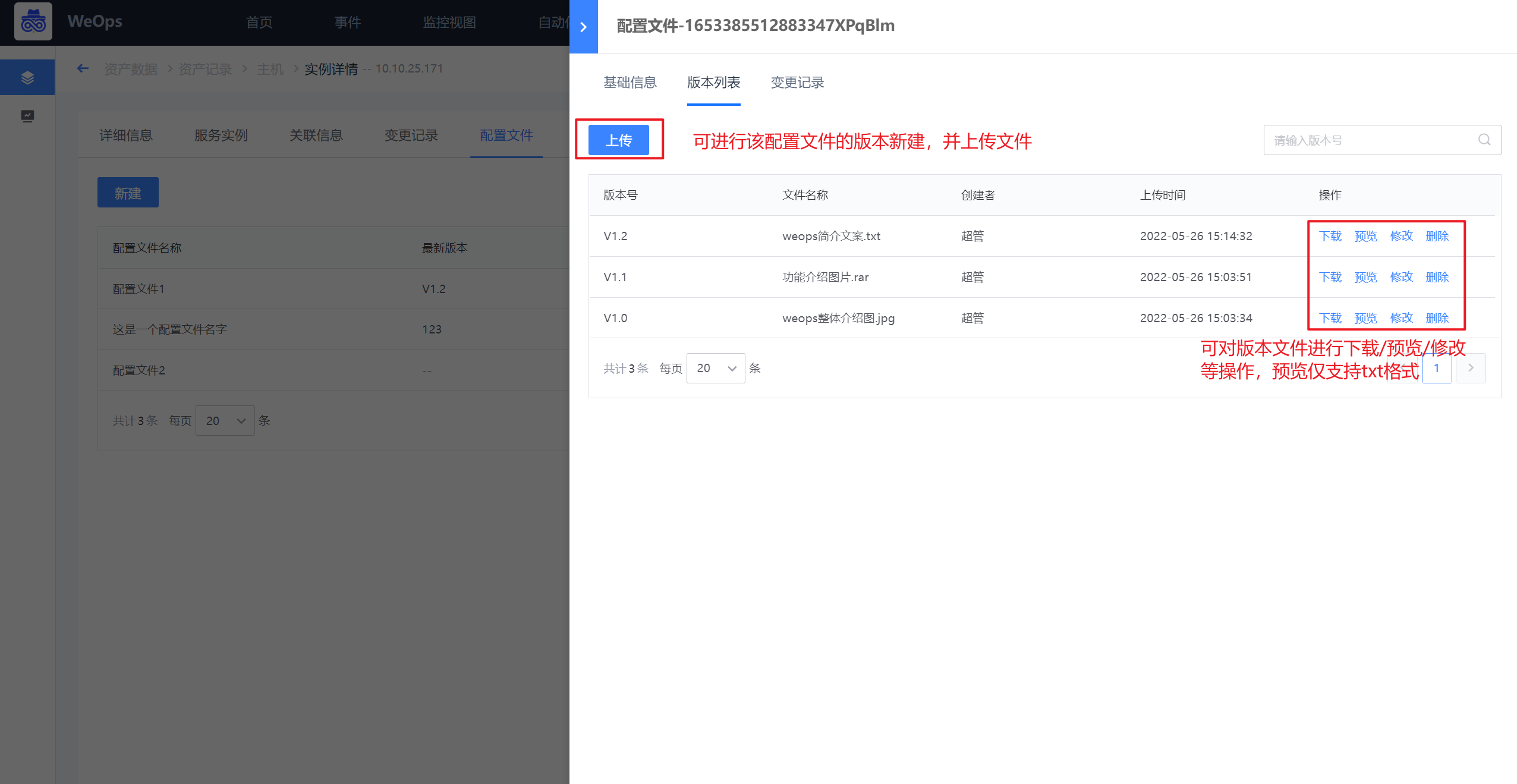
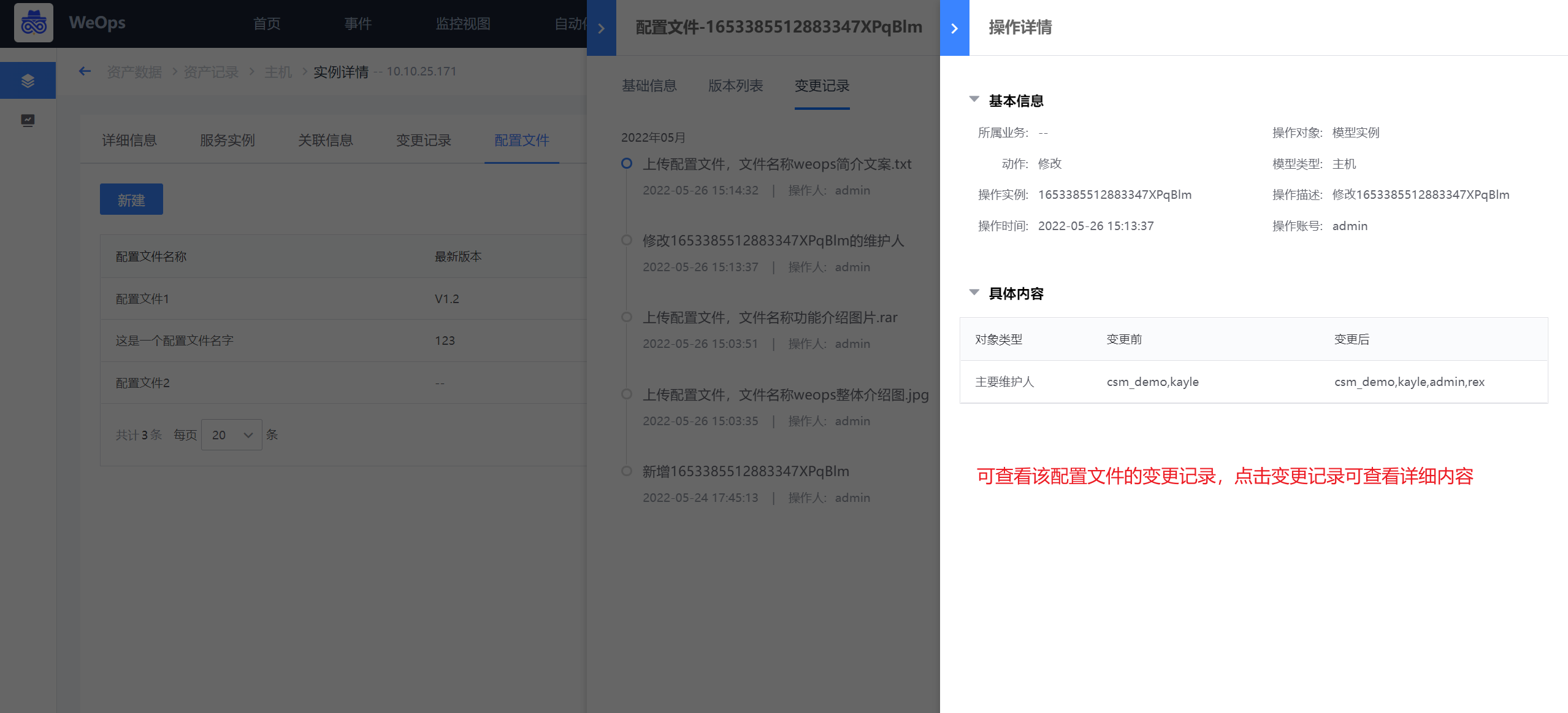
针对变更记录,可查看每个配置文件的变更情况,以及变更前后的对比。
2、监控告警配置
关于WeOps各个对象的监控告警配置总示意图如下
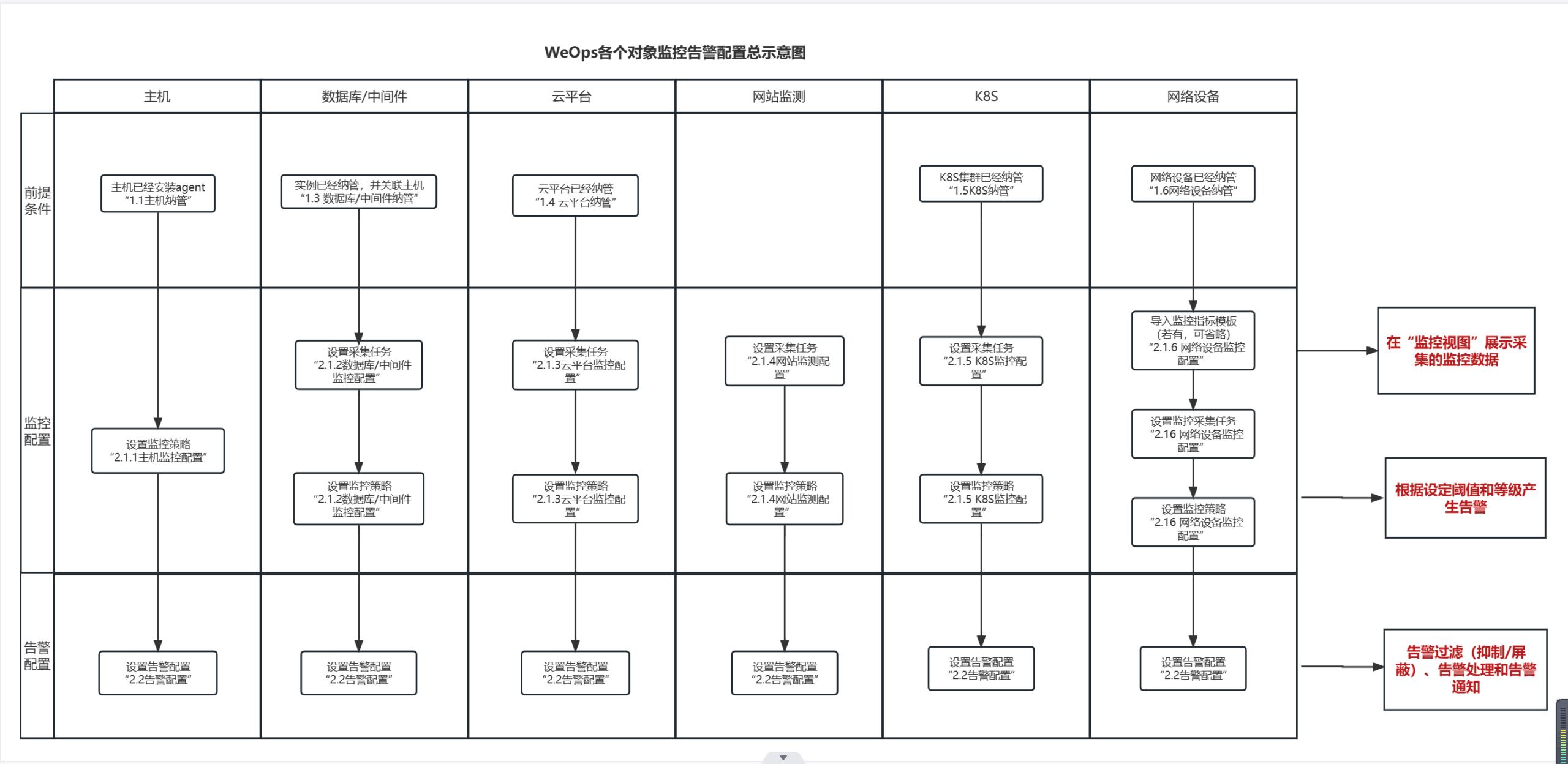
- 关于主机/数据库/中间件/k8s/云平台/网络设备的纳管,详情可参考“1、资源纳管”
- 各类对象的监控采集和监控策略配置,详情可参考“2.1 监控配置-分对象介绍”
- 各类对象的告警配置,包括告警抑制/告警屏蔽/自动处理/自动分派、人员通知,详情可参考“2.2告警配置”,各对象配置方法通用
2.1 监控配置
2.1.1主机监控配置
背景介绍:主机已经安装完Agent,已经完成纳管,纳管的步骤详情可见“1、资源纳管-主机纳管”,现需要对主机的监控策略进行配置。
Step1:监控采集
主机已经安装完Agent,就已经可以进行监控数据的采集,详情可见“1、资源纳管-主机纳管”这里不在赘述。
Step2:监控策略配置
路径:管理-监控管理-监控策略-主机
- 进入WeOps的管理中心的监控管理,找到监控策略。
- 如下图所示,进入新建监控模板配置界面,默认填写策略名称、监控对象
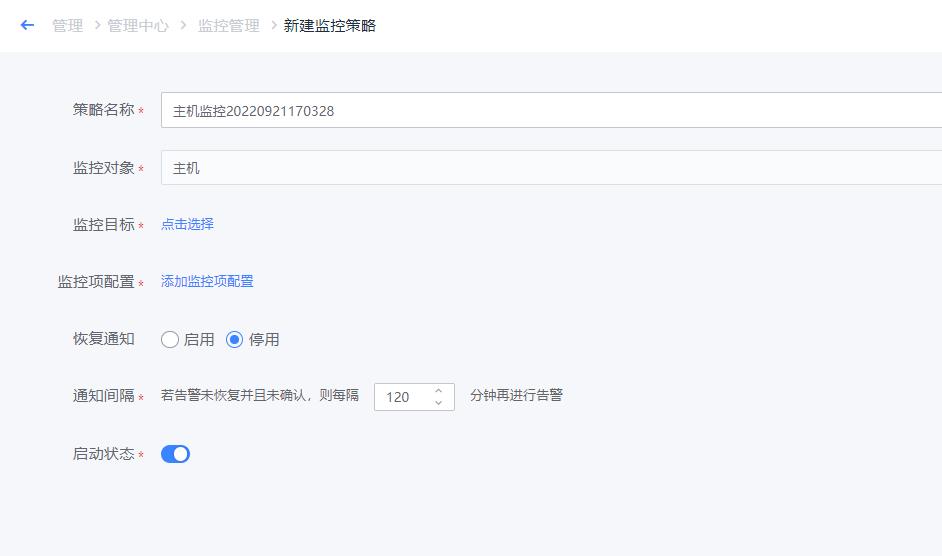
- 如下图所示,点击“选择监控目标”,可以采用列表选择/静态拓扑选择的方式,选择需要监控的目标。

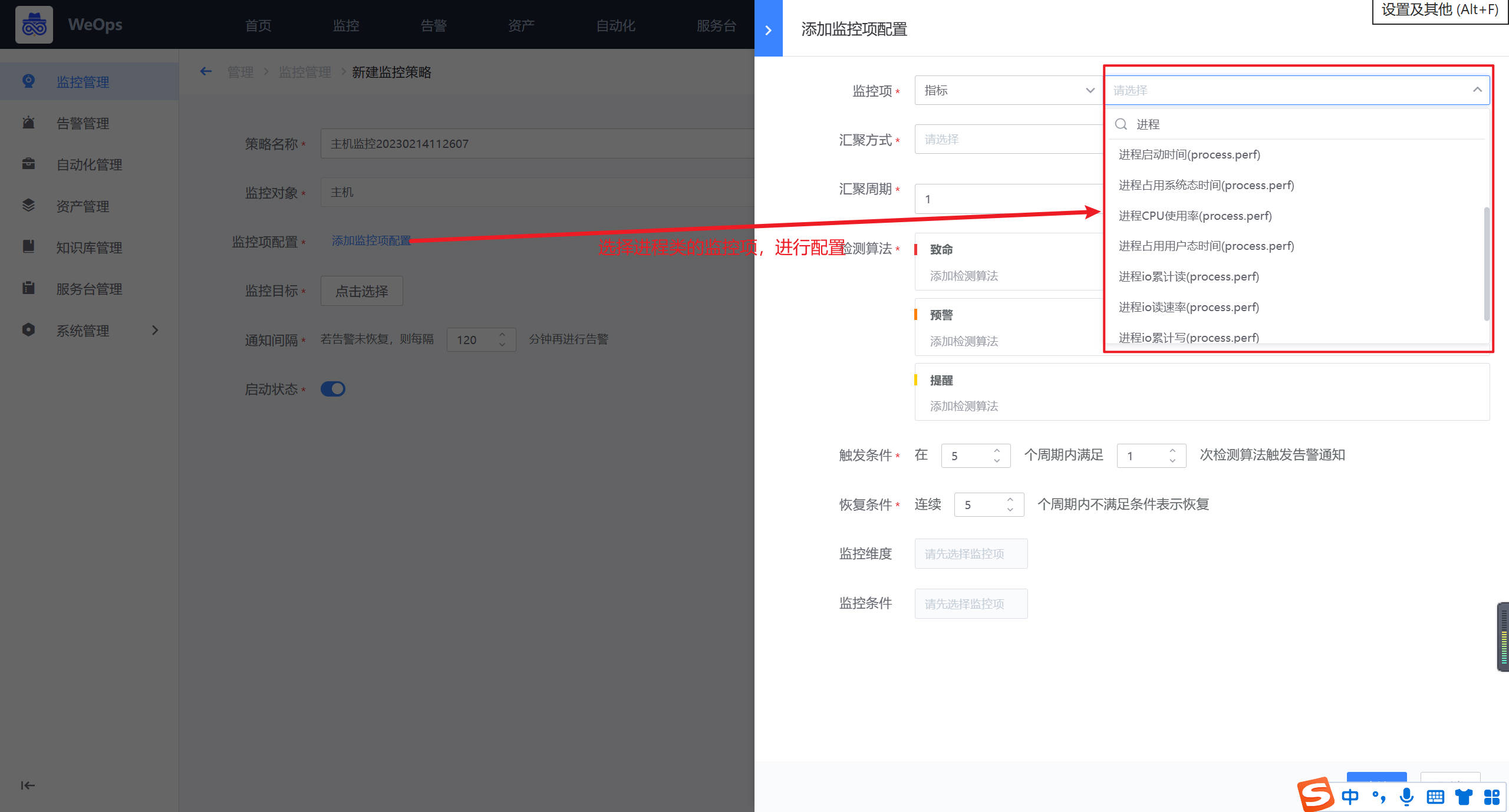
- 如下图所示,点击蓝色字体【添加监控项配置】即会弹出对应界面。主机监控项分为“指标”和“事件”两类。指标主要为常见的CPU、内存、磁盘、进程等监控指标。而事件则是指Agent心跳、Ping可达、主机重启等。

选择监控项为指标类,搜索监控项
选择汇聚方式为平均数,即AVG方式。SUM代表总数,AVG代表平均数,MAX代表最大值,MIN代表最小值,COUNT代表计数/总数。
选择汇聚周期,汇聚周期即采集数据的周期。(注:汇聚1min即是服务端每分钟向Agent采集1次数据。若是汇聚周期设置为5min则表示服务端向Agent每5分钟采集1次数据,此刻的Agent已经采集到了5次数据。之后,并根据汇聚方式将这5个数据进行计算(AVG/MAX/MIN等),计算得出的数值再于检测算法设置的阈值进行比较。)
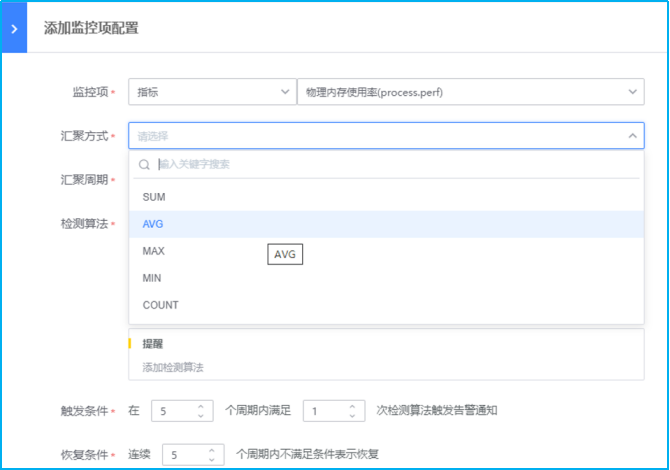
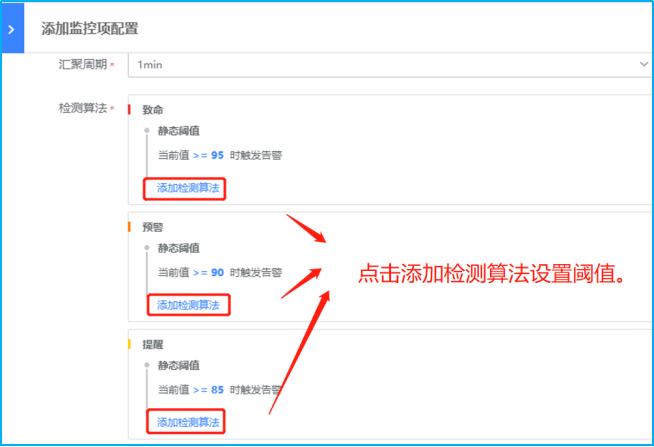
- 如下图所示,点击蓝色字体添加检测算法,进行不同监控等级阈值的设置。以下示例采用检测静态阈值触发告警。此外还有高级的阈值检测方式可选择:各种同比/环比策略,共有8种算法
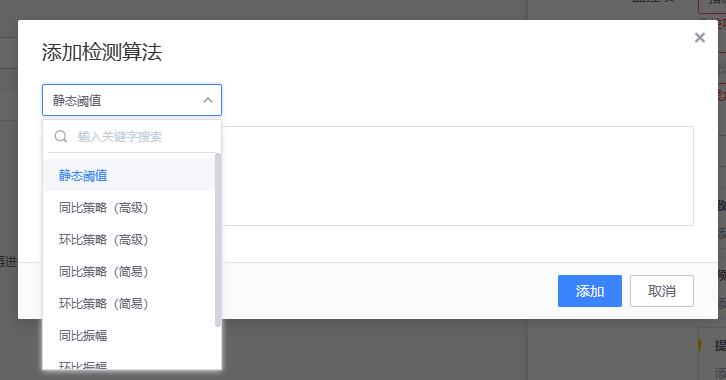
8种算法具体解释如下
【1、静态阈值】静态阈值是最简单也是使用最普遍的检测算法,只要值满足条件即为异常。是一种固定的设定方法。大多数的都是以静态阈值为主。
适用场景: 适用于许多场景,适用可以通过固定值进行异常判断的。如磁盘使用率检测,机器负载等。
配置方法
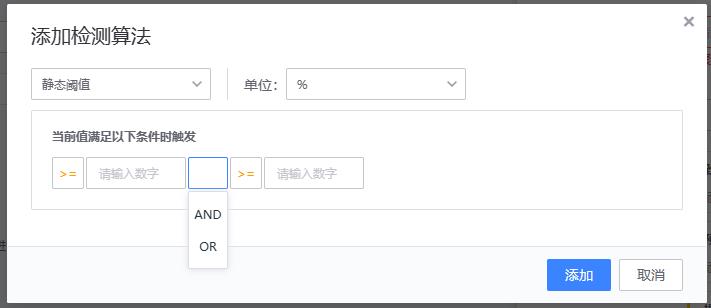
实现原理
{value} {method} {threshold}
# value:当前值
# method:比较运算符(=,>, >=, <, <=, !=)
# threshold: 阈值
# 当前值 (value) 和阈值 (threshold) 进行比较运算
多条件时,使用and或or关联。 判断规则:or 之前为一组
例:
>= 10 and <= 100 or = 0 or >= 120 and <= 200
(>= 10 and <= 100) or (= 0) or (>= 120 and <= 200)【2、同比策略(简易)/同比策略(高级)】
适用场景:适用于以周为周期的曲线场景。比如 pv、在线人数等
配置方法
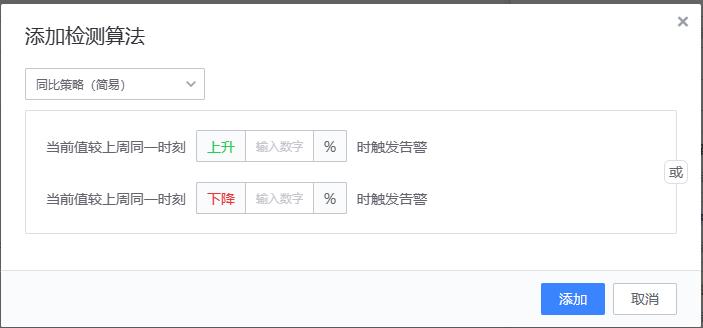
- 实现原理
同比策略(简易)
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:上周同一时刻值
# ceil:升幅
# floor:降幅
# 当前值(value) 与上周同一时刻值 (history_value)进行升幅/降幅计算
示例:当 value(90),ceil(100),history_value(40)时,则判断为异常
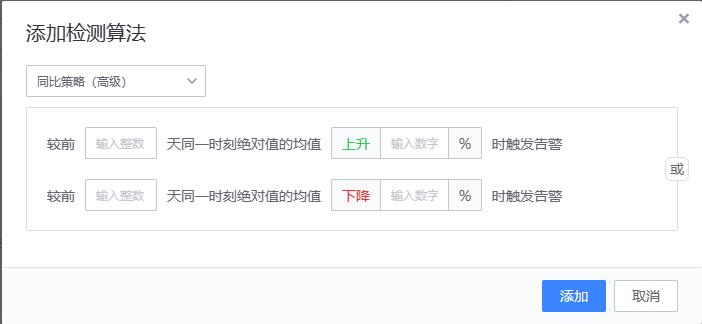
同比策略(高级)
# 算法原理和同比策略(简易)一致,只是用来做比较的历史值含义不一样。
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:前n天同一时刻绝对值的均值
# ceil:升幅
# floor:降幅
# 当前值(value) 与前n天同一时刻绝对值的均值 (history_value)进行升幅/降幅计算
# 前n天同一时刻绝对值的均值计算示例
以日期2019-08-26 12:00:00为例,如果n为7,历史时刻和对应值如下:
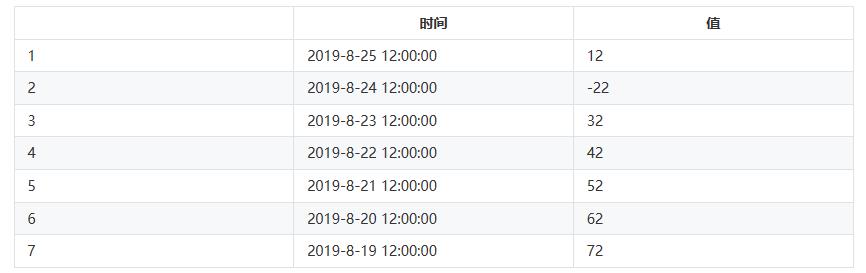
取绝对值,因此所有的值为正数
history_value = (12 + 22 + 32 + 42 + 52 + 62 +72) / 7 = 42
示例:当 value(90),ceil(100),history_value(42)时,则判断为异常
- 【3、环比策略(简易)/环比策略(高级)】
适用场景:适用于需要检测数据陡增或陡降的场景。如交易成功率、接口访问成功率等
配置方法
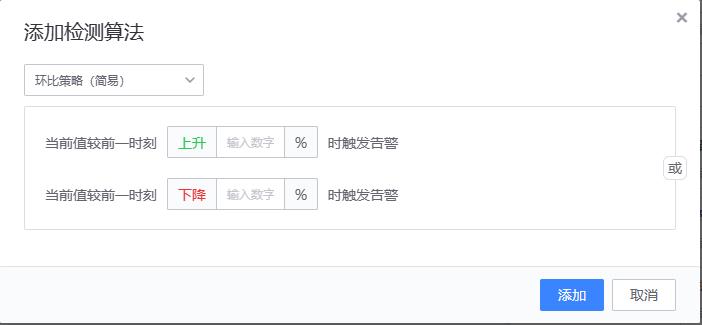
- 实现原理
环比策略(简易)
算法原理和同比策略(简易)一致,只是用来做比较的历史值含义不一样。
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:前一时刻值
# ceil:升幅
# floor:降幅
# 当前值(value) 与前一时刻值 (history_value)进行升幅/降幅计算
示例:当 value(90),ceil(100),history_value(40)时,则判断为异常
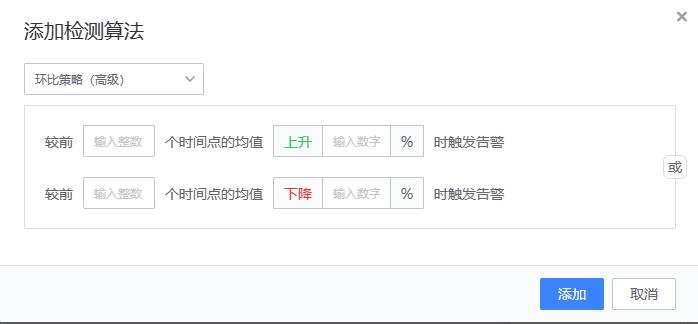
环比策略(高级)
# 算法原理和同比策略(简易)一致,只是用来做比较的历史值含义不一样。
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:前n个时间点的均值
# ceil:升幅
# floor:降幅
# 当前值(value) 与前个时间点的均值 (history_value)进行升幅/降幅计算
# 前n个时间点的均值计算示例(数据周期1分钟)
以日期2019-08-26 12:00:00为例,如果n为5,历史时刻和对应值如下:

history_value = (12 + 22 + 32 + 42 + 52) / 5 = 32
示例:当 value(90),ceil(100),history_value(32)时,则判断为异常
【4、同比振幅】
适用场景:场景:适用于监控以天为周期的事件,该事件会明确导致指标的升高或者下降,但需要监控超过合理范围幅度变化的场景。比如每天上午 10 点有一个抢购活动,活动内容不变,因此请求量每天 10:00 相比 09:59 会有一定的升幅。因为活动内容不变,所以请求量的升幅是在一定范围内的。使用该策略可以发现异常的请求量。
配置方法
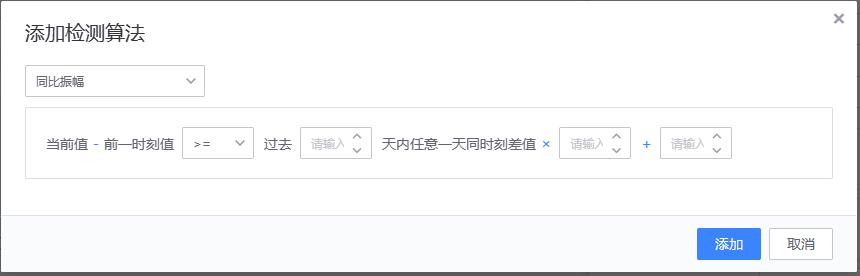
实现原理
# 算法示例:
当前值 − 前一时刻值 >= 过去 5 天内任意一天同时刻差值 × 2 + 3
以日期2019-08-26 12:00:00为例,如果n为5,历史时刻和对应值如下:
# 当前值
value = 26
# 前一时刻值
prev_value = 10
# 比较运算符(=,>, >=, <, <=, !=)
method = ">="
# 波动率
ratio = 2
# 振幅
shock = 3
# 当前值一前一时刻值的差值
current_diff = 16
# 5天内同时刻差值
prev5_diffs = [7, 6, 8, 10, 12]
前第二天(2019-8-24)同时刻差值: 6 * ratio(2) + shock(3) = 15
current_diff(16) >= 15
# 当前值(26) - 前一时刻值(10) >= 2天前的同一时刻差值6 * 2 + 3
此时算法检测判定为检测结果为异常:
【5、同比区间】
适用场景:温水煮青蛙型 - 数据缓慢上升或下降,适用于以天为周期的曲线场景。由于该模型中数据是缓慢变化的,所以使用【环比策略】、【同比振几幅】都检测不出告警,因为这两种模型主要使用于突升、突降、大于或小于指定值的情况。【同比区间】才适用于这种情况,因为随着数据的变化,当前值和模型值差距越来越大,而区间比较主要就是那当前值和历史模型值做比较。
配置方法

实现原理
# 算法示例:
当前值 >= 过去 5 天内同时刻绝对值 × 2 + 3
以日期2019-08-26 12:00:00为例,如果n为5,历史时刻和对应值如下:
# 当前值
value = 11
# 比较运算符(=,>, >=, <, <=, !=)
method = ">="
# 波动率
ratio = 2
# 振幅
shock = 3
前第3天(2019-8-23)同时刻值: 13 * ratio(2) + shock(3) = 26
value(26) >= 26
# 当前值(26) >= 3天前的同一时刻绝对值13 * 2 + 3
此时算法检测判定为检测结果为异常:【6、环比振幅】
适用场景:适用于指标陡增或陡降的场景,如果陡降场景,ratio(波动率)配置的值需要 < -1 该算法将环比算法自由开放,可以通过配置 波动率 和 振幅,来达到对数据陡变的监控。同时最小阈值可以过滤无效的数据
配置方法

实现原理
# 当前值(value) 与前一时刻值 (prev_value)均>= (threshold),且之间差值>=前一时刻值 (prev_value) * (ratio) + (shock)
# value:当前值
# prev_value:前一时刻值
# threshold:阈值下限
# ratio:波动率
# shock:振幅
以日期2019-08-26 12:00:00为例:
# 当前值
value = 46
# 前一时刻值
prev_value = 12
# 波动率
ratio = 2
# 振幅
shock = 3
value(46) >= 10 and prev_value(12) >=10
value(46) >= prev_value(12) * (ratio(2) + 1) + shock(3)
此时算法检测判定为检测结果为异常:
# 当前值(46)与前一时刻值(12)均>= (10),且之间差值>=前一时刻值 (12) * (2) + (3)
- 如下图所示,进行“触发条件”、“恢复条件”、“无数据告警”、“监控纬度”以及“监控条件”的设置。
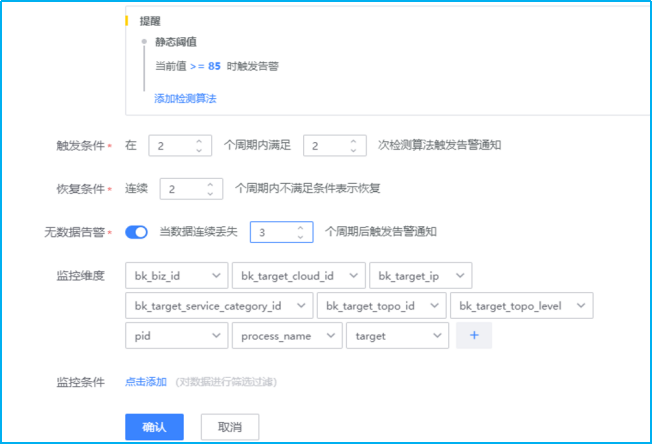
触发条件:2个周期内满足2次检测算法触发告警。结合以上汇聚周期1min(监控数据采集周期也是1min),汇聚方式设置为AVG平均数(1个数的平均数亦是其本身)。综上,每分钟检测1次,连续2次检测满足检测算法设置的阈值即会触发对应的告警等级。
恢复条件:连续2个周期内不满足条件表示恢复。表示:每分钟检测1次,连续2次检测不满足即表示恢复。
无数据告警:开启。当数据连续丢失3个周期后触发告警通知。表示:每分钟检测1次数据汇聚情况,若是连续3次(即3分钟内无任何数据),则触发无数据告警通知。
监控纬度:不同的监控项有不同的监控纬度。默认监控所有纬度,可以根据需求进行增删。默认情况下是监控所有纬度。例如监控项磁盘空间,那么windows的监控纬度则会是自发现的C:\ D:\ E:\等,而Linux则会是/、/root、/dev等。
监控条件:监控条件是对监控纬度的筛选,若是不选择则代表监控所有纬度。磁盘监控项中若是监控条件选择C:\则代表只监控磁盘C分区。
如下图所示,对监控项进行一一添加后再进行其他配置即可完成监控策略的配置。
主机监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
下一步“告警配置”可查看“2.2告警配置”
2.1.2 进程监控配置
背景介绍:进程监控采集任务配置好下发到目标机器后,会基于采集的任务信息进行工作。通过配置需要监控的进程名,条件可以选择包含/不包含(排除)某些命令行的关键字,过滤出需要的进程,然后探测该进程是否开启端口(可选功能),同时会采集该进程的相关使用情况。
Step1:监控采集
路径:管理-监控管理-监控采集
如下图,进入到进程采集的页面,点击进行端口采集新建。目前仅支持主机的进程采集和监控。

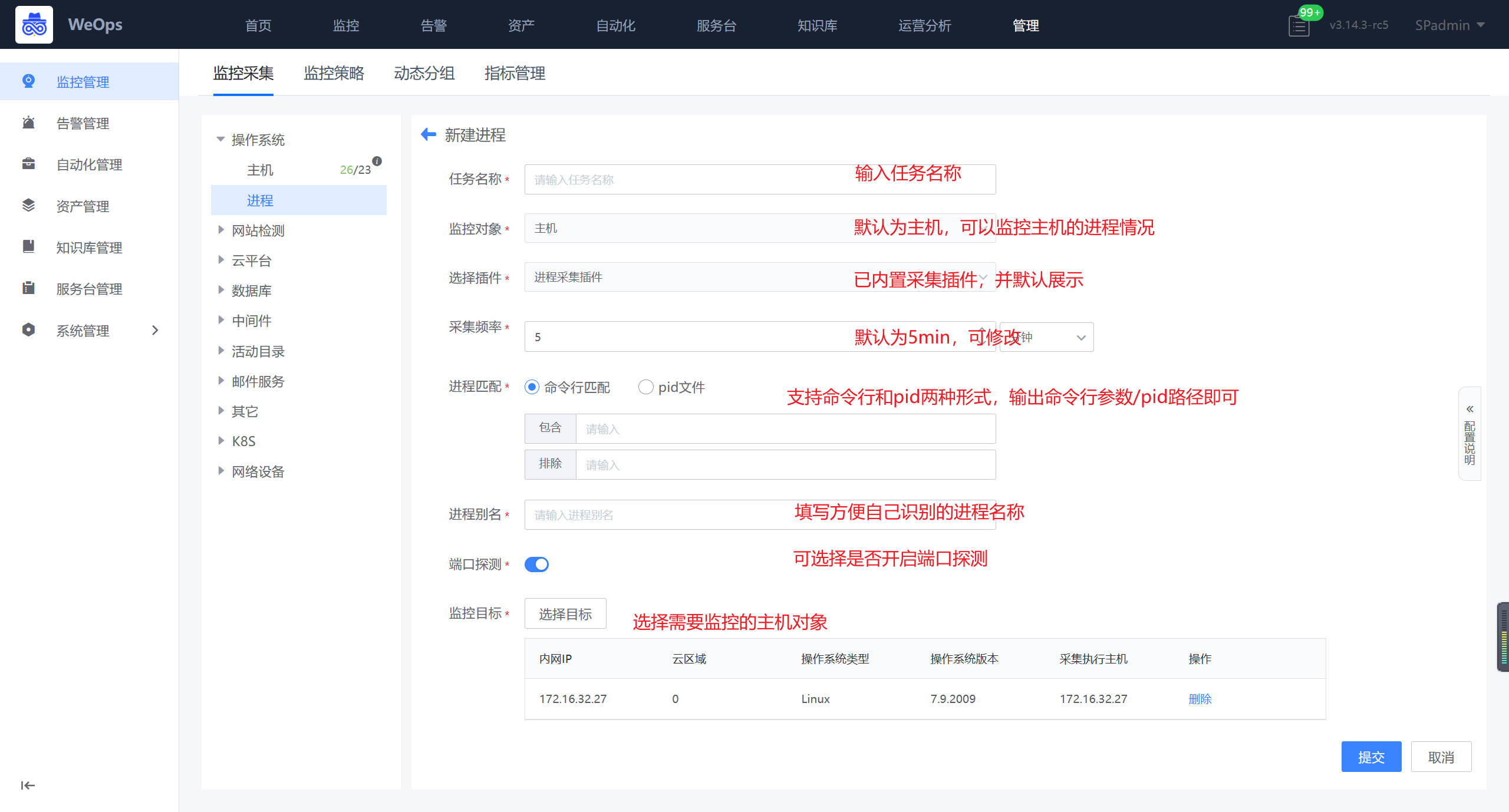
- 两种匹配方式,一种是命令行匹配,把命令行参数复制进来就可以了,一种是pid路径匹配,把pid路径复制进来,命令行和pid两类的对比如下
1、命令行较简单,但是有些场景覆盖不到,如两个进程的启动命令是一样的,命令行区分不了。包含:进程匹配字符串,一般是进程的名称,注意Linux是cmdline, windows是匹配进程名。排除:即不上报的进程,可以填写正则表达式,如(\d+),不采集匹配数字的进程
2、pid比较准确,但是对程序的运行有要求,不是每个进程都会有pid文件
主机的进程采集设置完成后,可以在主机的对应监控视图中,查看该主机所有进程的监控情况,如下图

Step2:监控策略配置
路径:管理-监控管理-监控策略
如下图,在监控策略页面,找到主机,点击“创建”按钮,进行主机进程的监控策略的创建
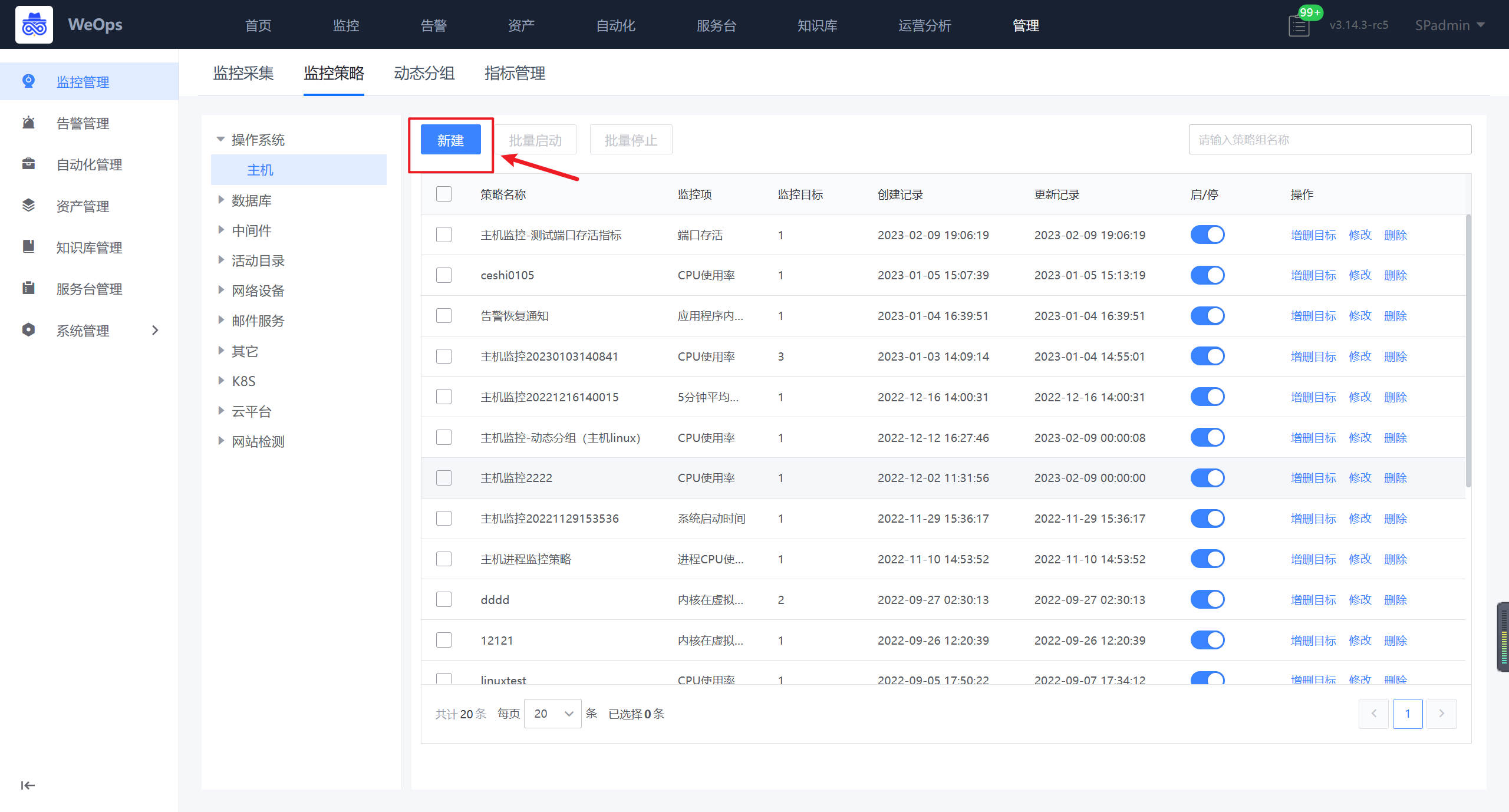
- 如下图所示,填写策略名称,进行监控项的添加(选择进程类的指标)、监控阈值的配置、监控对象的选择等之后,点击保存即完成监控阈值的配置。
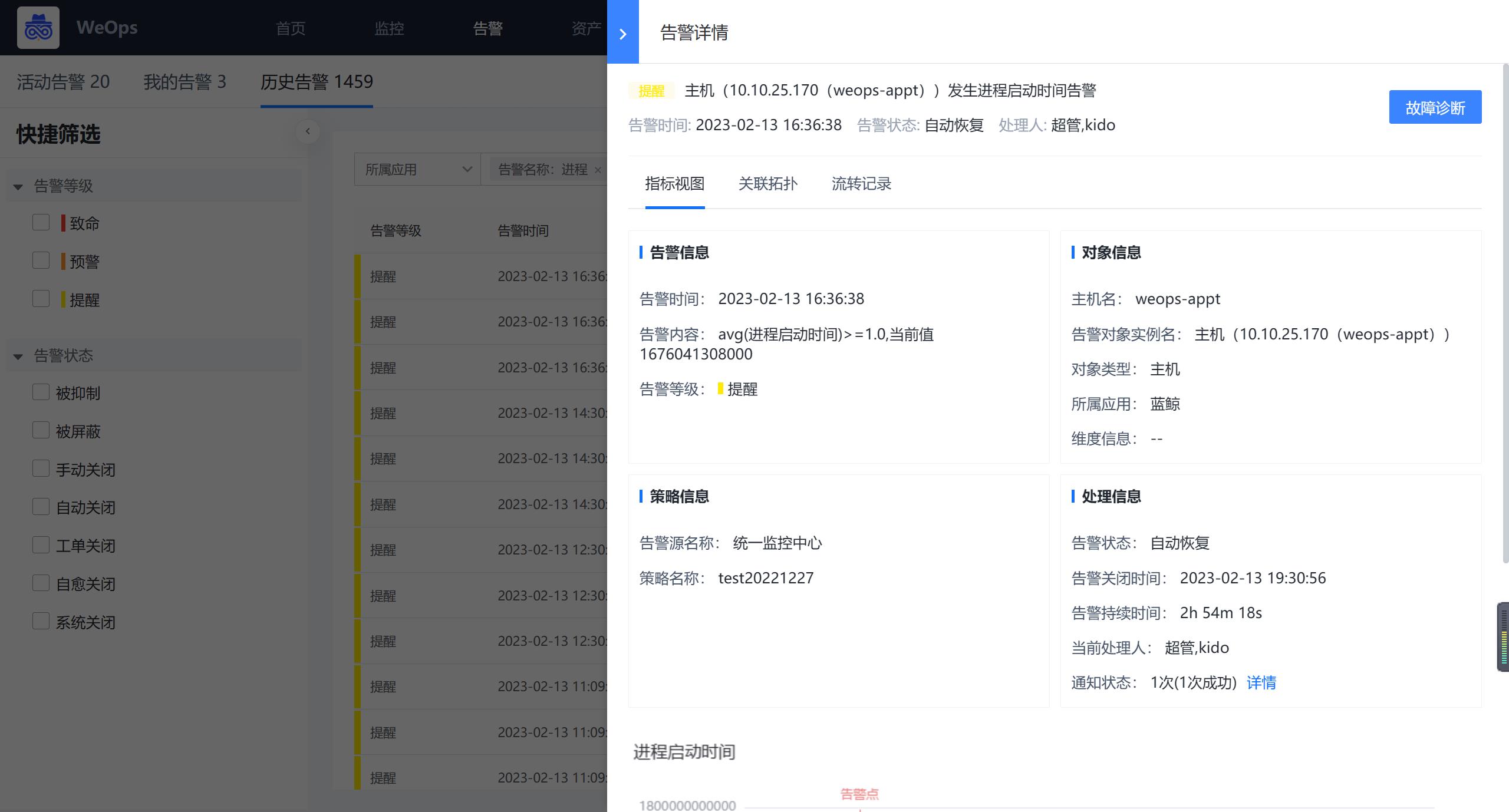
配置完成后,可以根据设定的指标、阈值和告警等级等产生对应的告警。
2.1.3 数据库/中间件监控配置
背景介绍:需要将数据库/中间件的实例已经新建完成,并且与对应主机已经建立了关联,数据库/中间件纳管的步骤详情可见“1.3 数据库/中间件纳管”,现需要对该实例进行监控采集和监控策略的设置。(这里以oracle为例进行介绍。)
Step1:监控采集
路径:管理-监控管理-监控采集
- 如下图所示,进入监控采集页面,点击数据库-oracle,进行oracle监控采集任务新建。
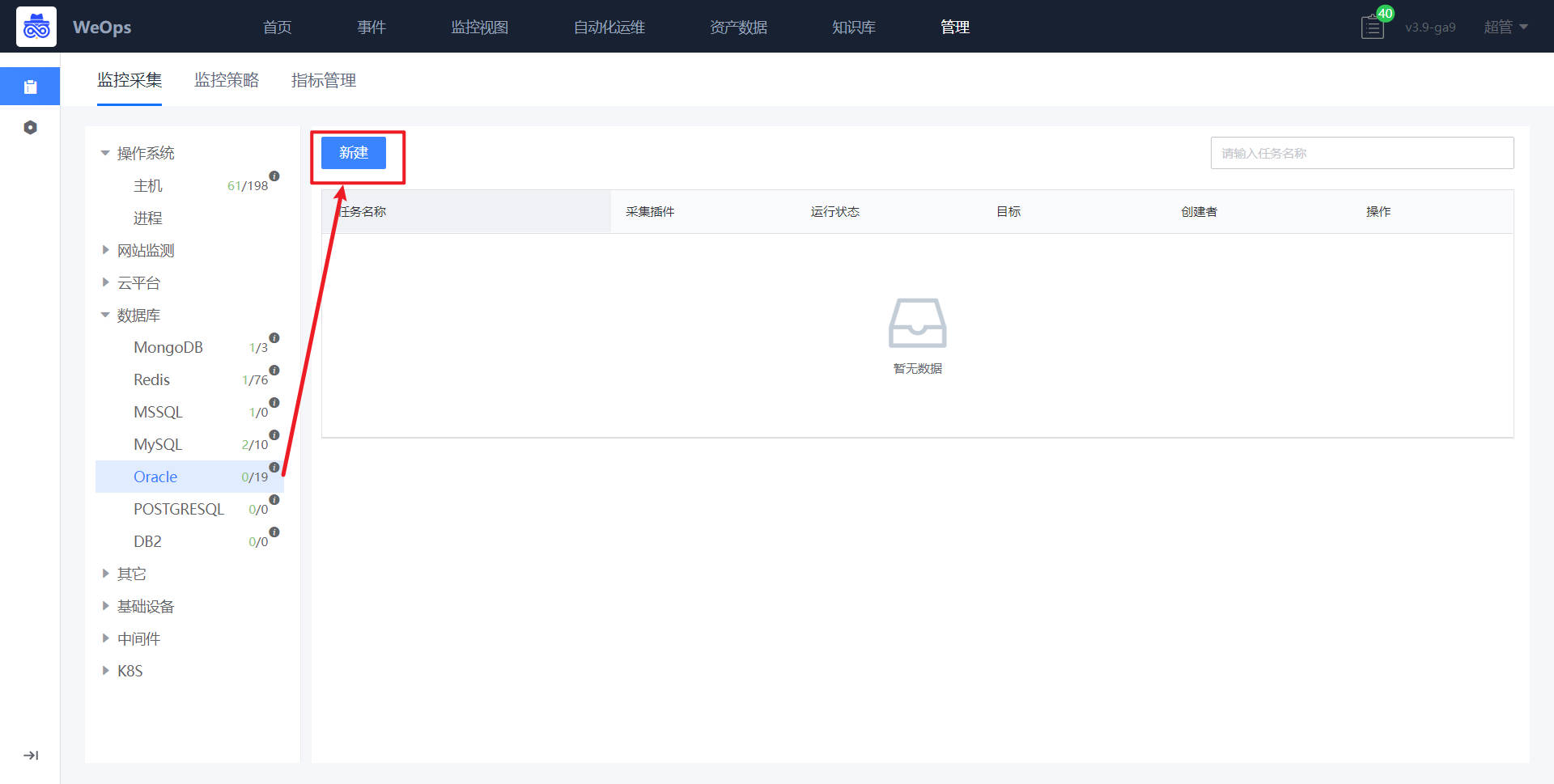
如下图所示,采集任务、监控对象、采集插件、采集频率等信息已经默认填写,只需要选择目标(监控oracle主机)
如下图所示,在选择完监控目标后,若所有目标的监控采集参数一致,则在全局参数中填写,若是特殊oracle主机节点有不同的监控采集参数,例如账号密码等,则在对应监控目标后填写。
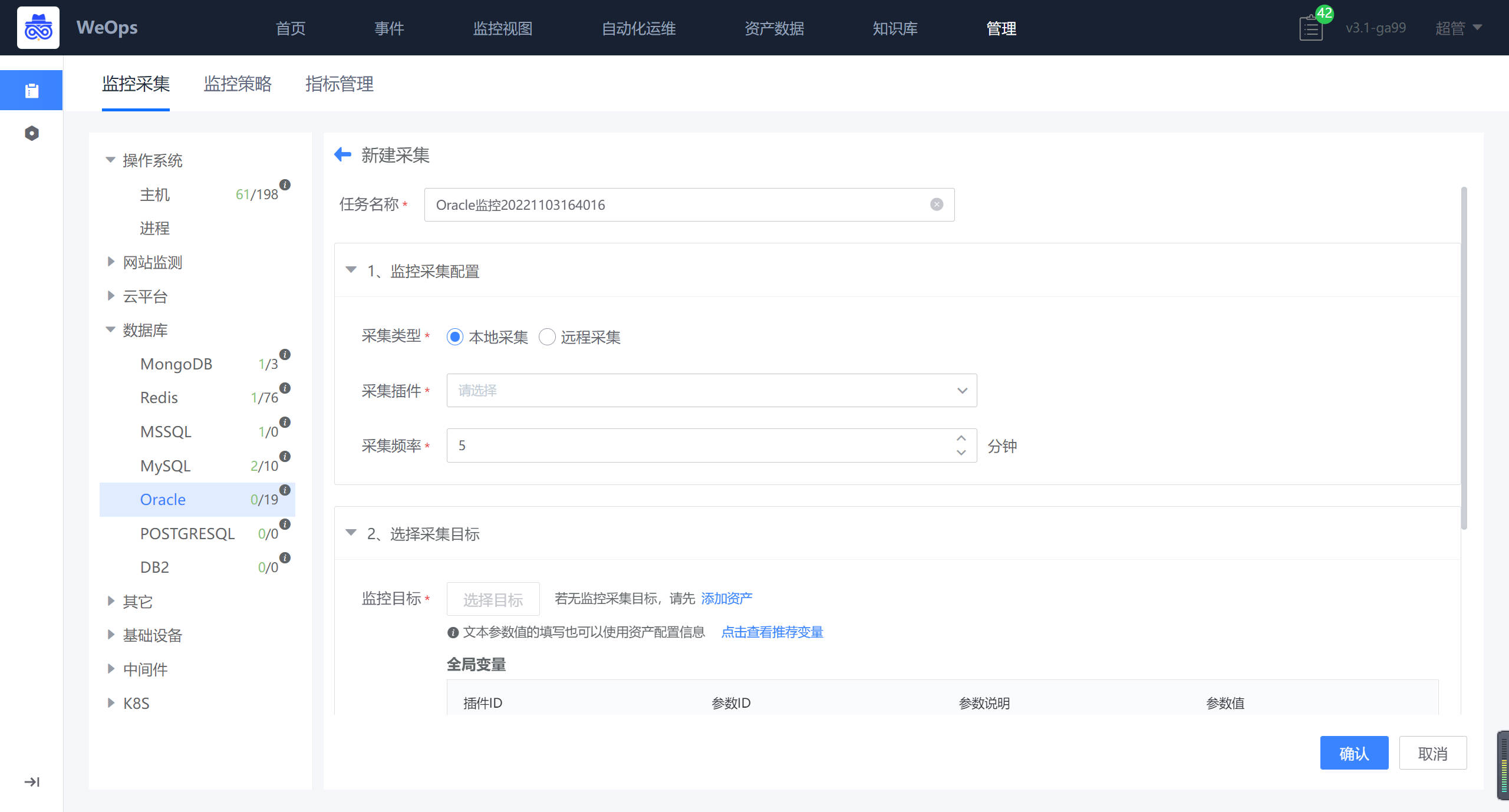
- 数据库/中间件的监控采集配置完成后,可在“监控视图-基础监控-数据库/中间件”中查看对应的监控情况和监控视图。
Step2:监控策略配置
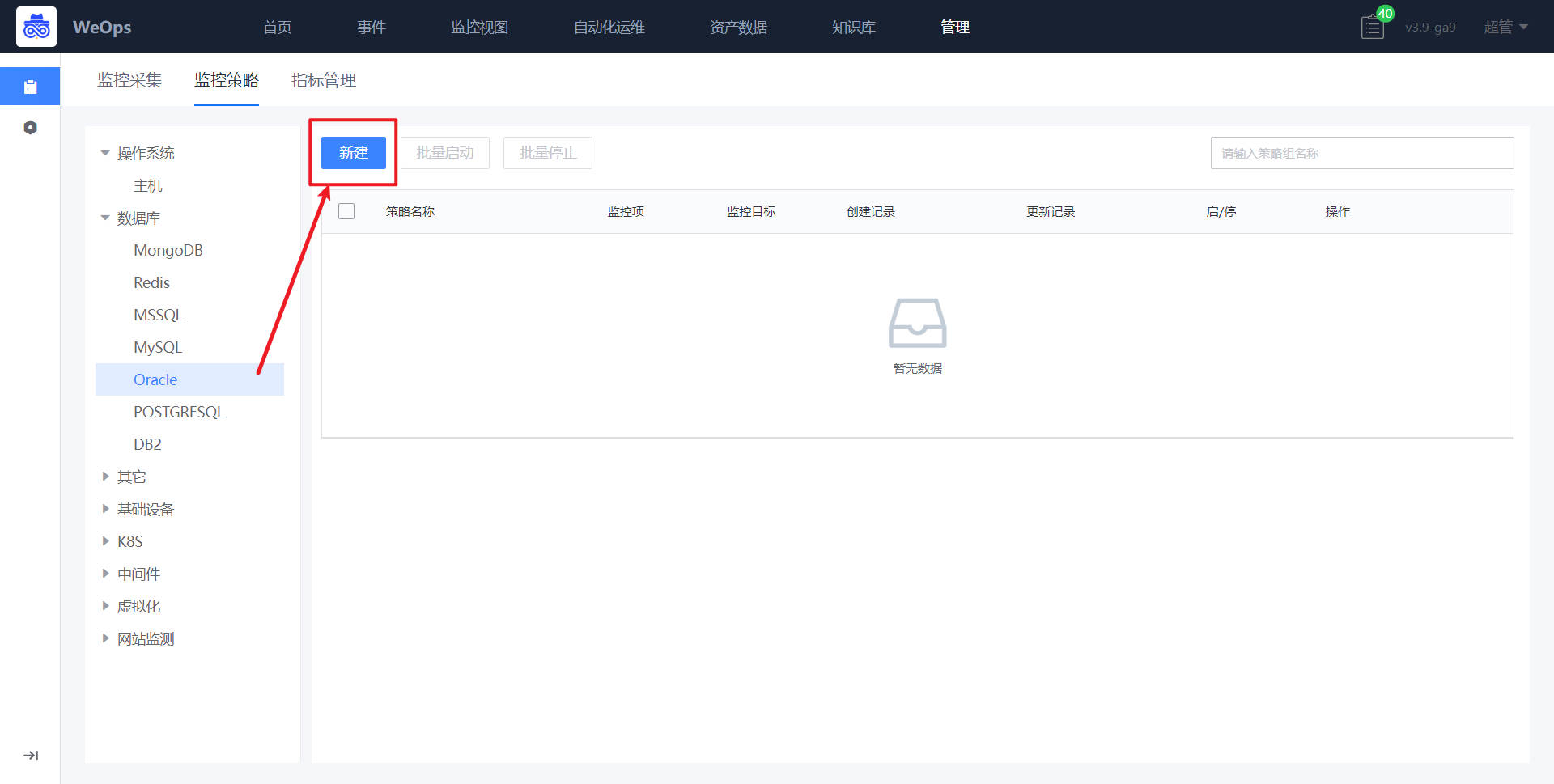
路径:管理-监控管理-监控策略
- 如下图所示,进入到监控管理的监控策略页面,点击新增监控配置。
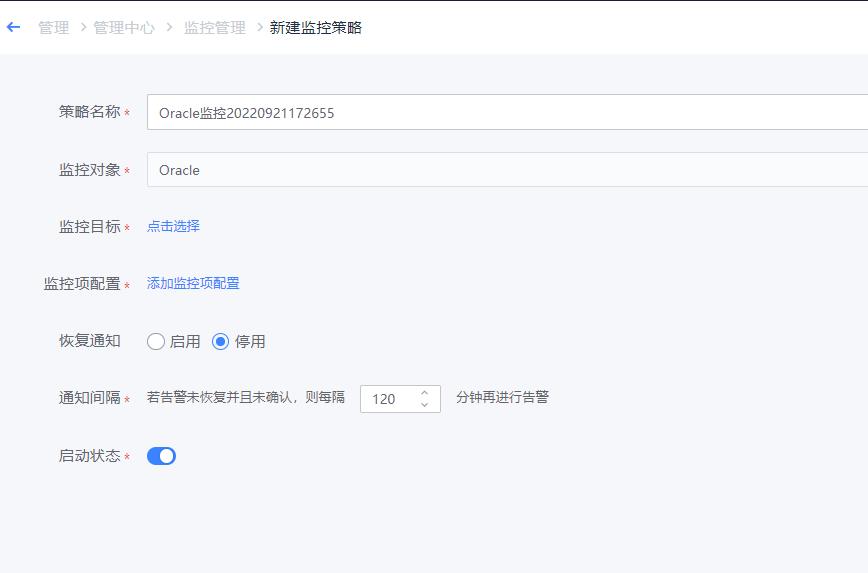
- 如下图所示,依照主机监控配置方式(可参见“1、资源配置-监控配置-主机监控配置”),进行监控项的添加、监控阈值的配置、监控对象的选择等之后,点击保存即完成监控阈值的配置。
- 数据库/中间件监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
2.1.4 云平台监控配置(以腾讯云为例)preview
背景介绍:需要将云平台纳入监控数据采集中,包括VMware、腾讯云和阿里云等,并设置对应监控策略。
Step1:监控采集
路径:管理-监控管理-监控采集
- 如下图所示,进入云平台的监控采集界面,进行新增。
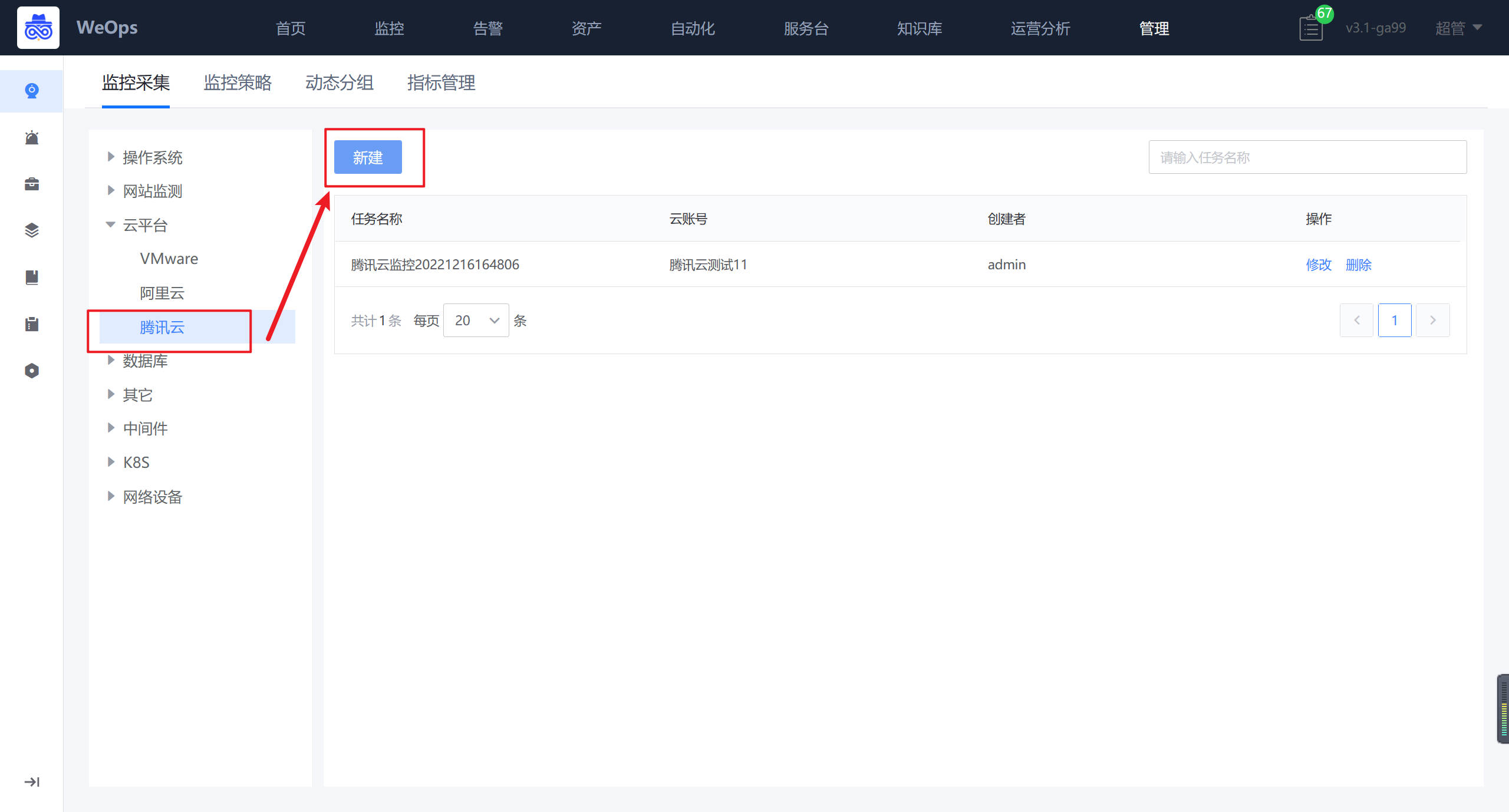
- 如下图所示,依次填写任务名称、腾讯云账号、对应凭据、采集频率等

- 新建完成后,,可对该腾讯云账号下所有的CVM进行监控数据的采集,并可以在WeOps-监控视图-云平台监控-腾讯云(CVM)中查看已经采集监控数据和监控视图
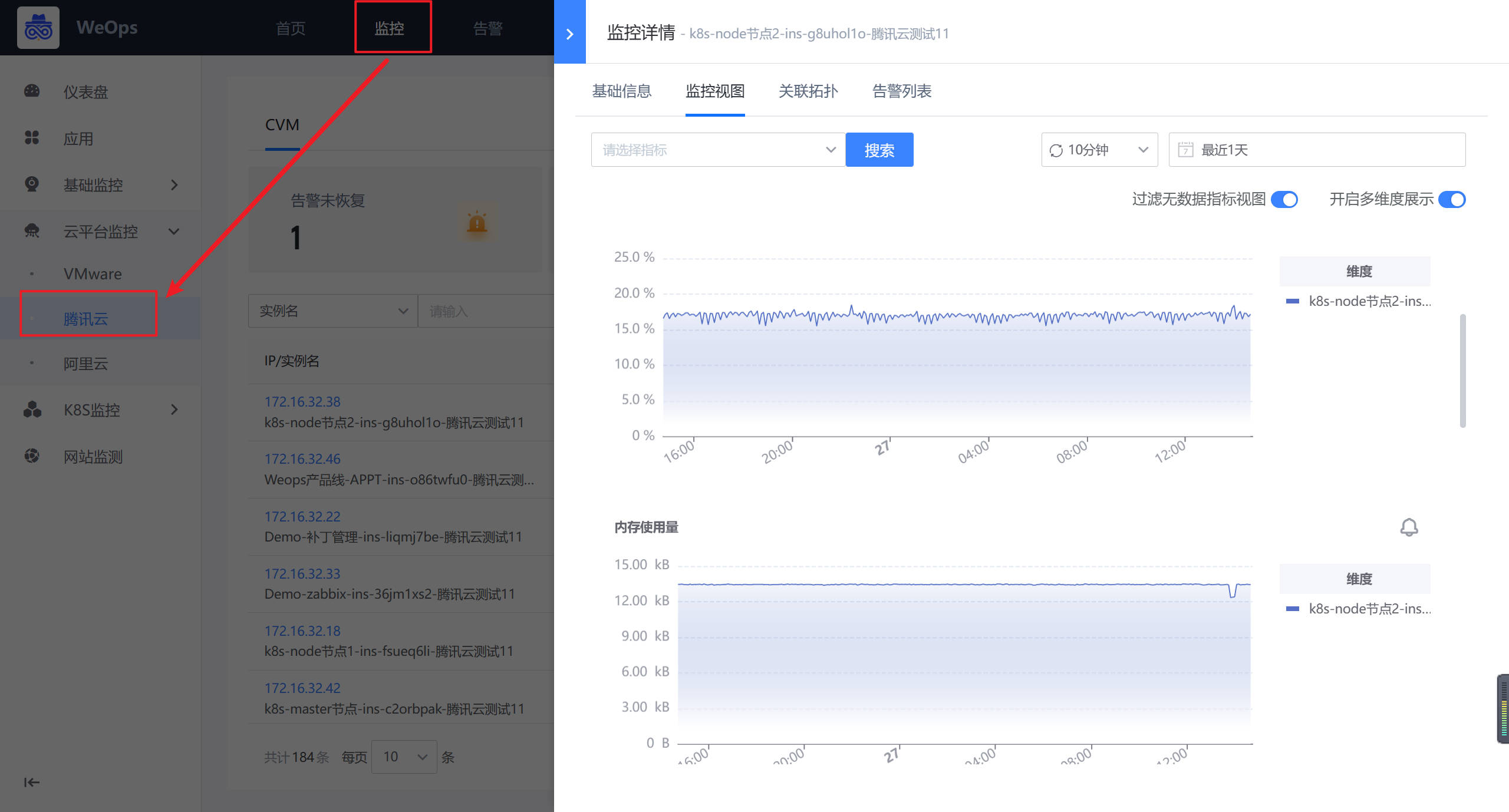
Step2:监控策略配置
路径:管理-监控管理-监控策略(虚拟化监控)
- 如下图所示,进入到监控管理的监控策略页面,点击新增云平台-腾讯云监控策略。

- 如下图所示,默认填写策略名称、监控对象,只需要选择监控项和监控目标即可(与主机监控策略配置操作一致)

- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。

- 下一步“告警配置”可查看“2.2告警配置”
2.1.5 网站监控配置
背景介绍:需要将新的网站纳入拨测监控中,并配置相应的监控策略。
Step1:监控采集
路径:管理-监控管理-网站监测
- 如下图所示,进入网站监测的纳管界面,进行新增拨测任务。
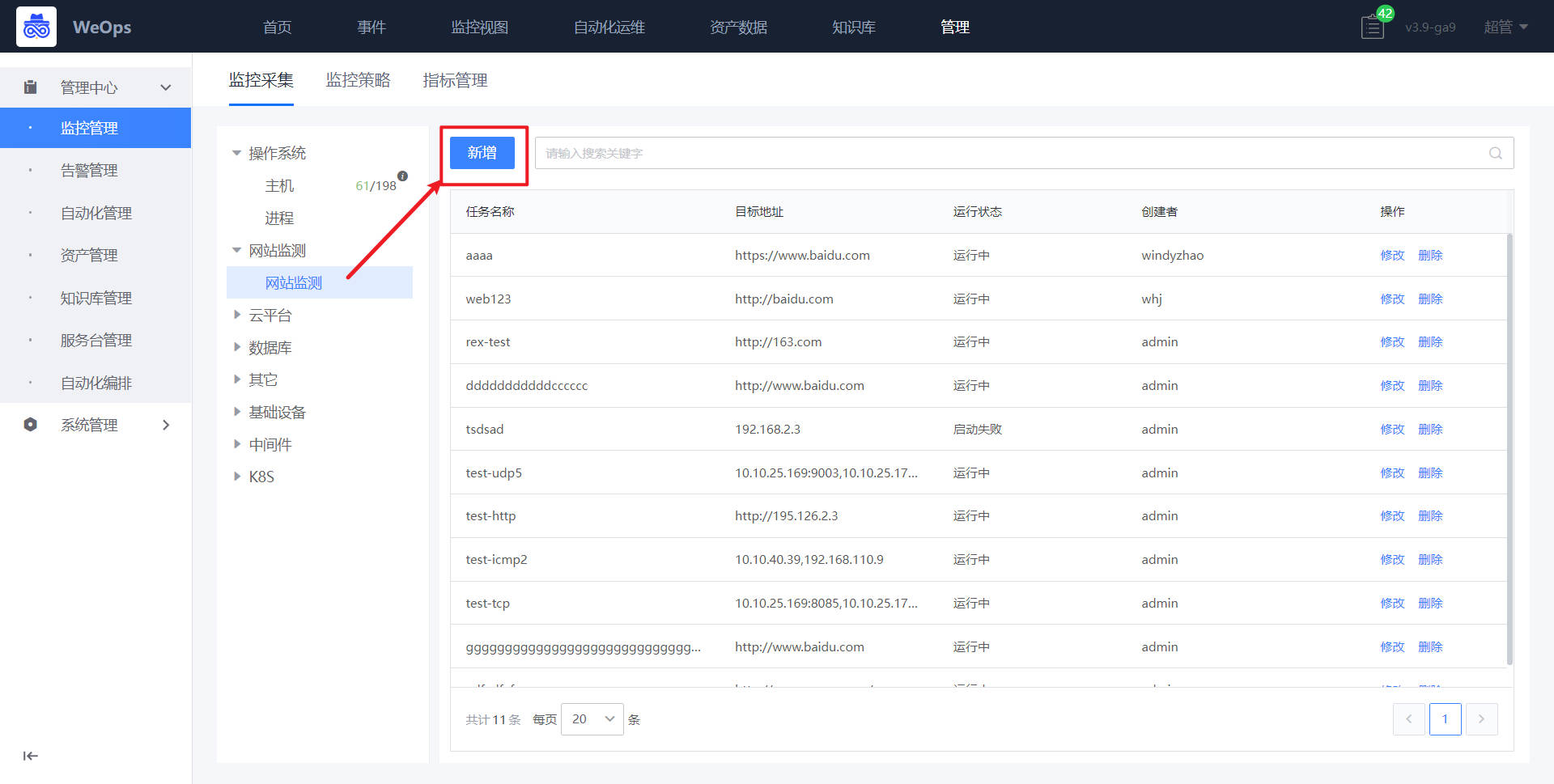
- 如下图所示,对任务进行配置后点击提交。提交之际系统会进行一次拨测,拨测成功后该任务才算创建成功,否则无法创建。若是创建失败请检查相关配置。

- 新建完成后,可以在监控视图-网站监测中查看已经采集监控数据和监控视图
Step2:监控策略配置
路径:管理-监控管理-监控策略(网站监测)
- 如下图所示,进入网站监测的配置界面,进行新增拨测监控。
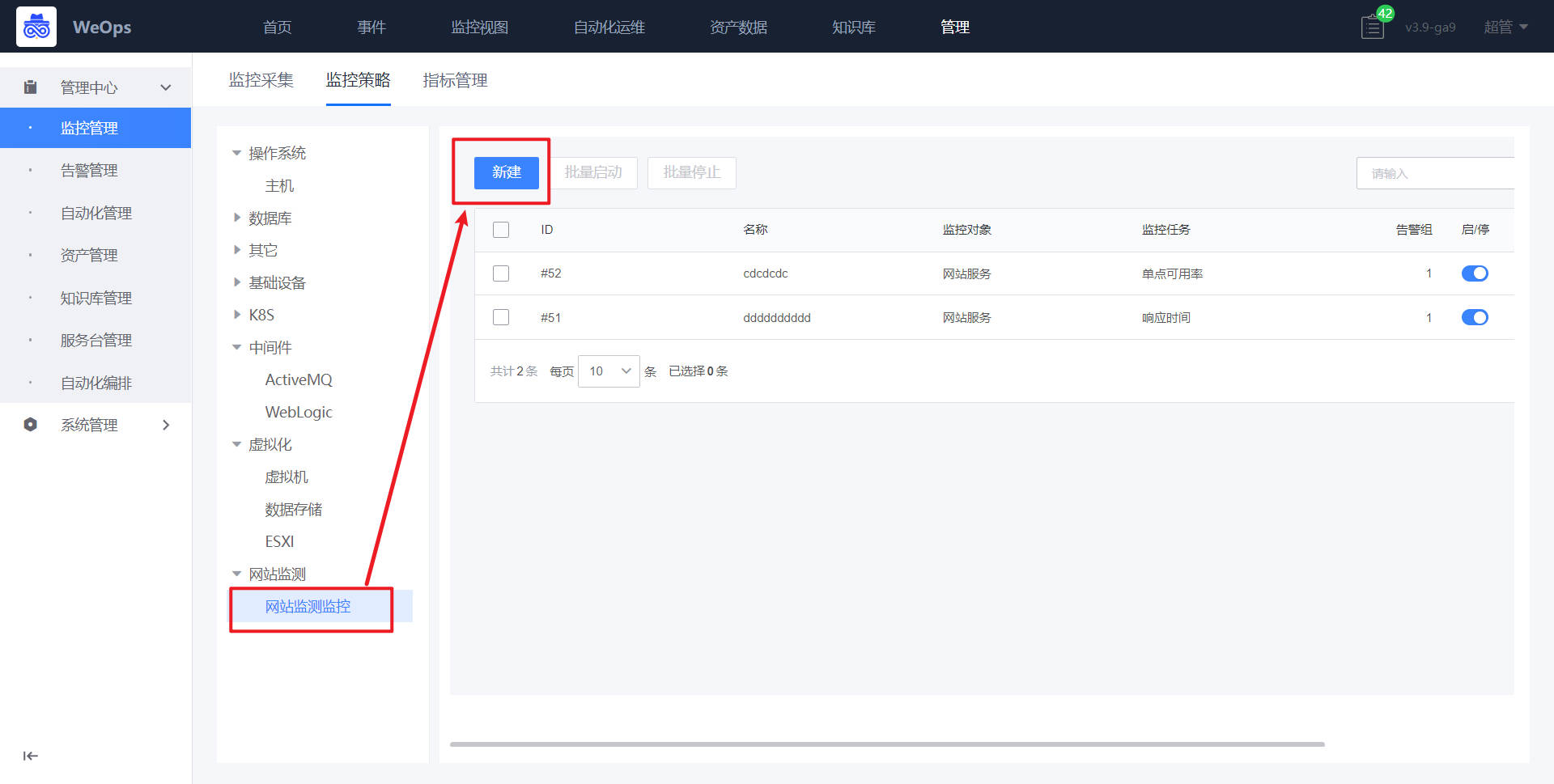
- 如下图所示,进行监控项的相关配置,并配置触发和恢复规则,以及选择监控对象,点击确定,即完成对应服务拨测的监控配置
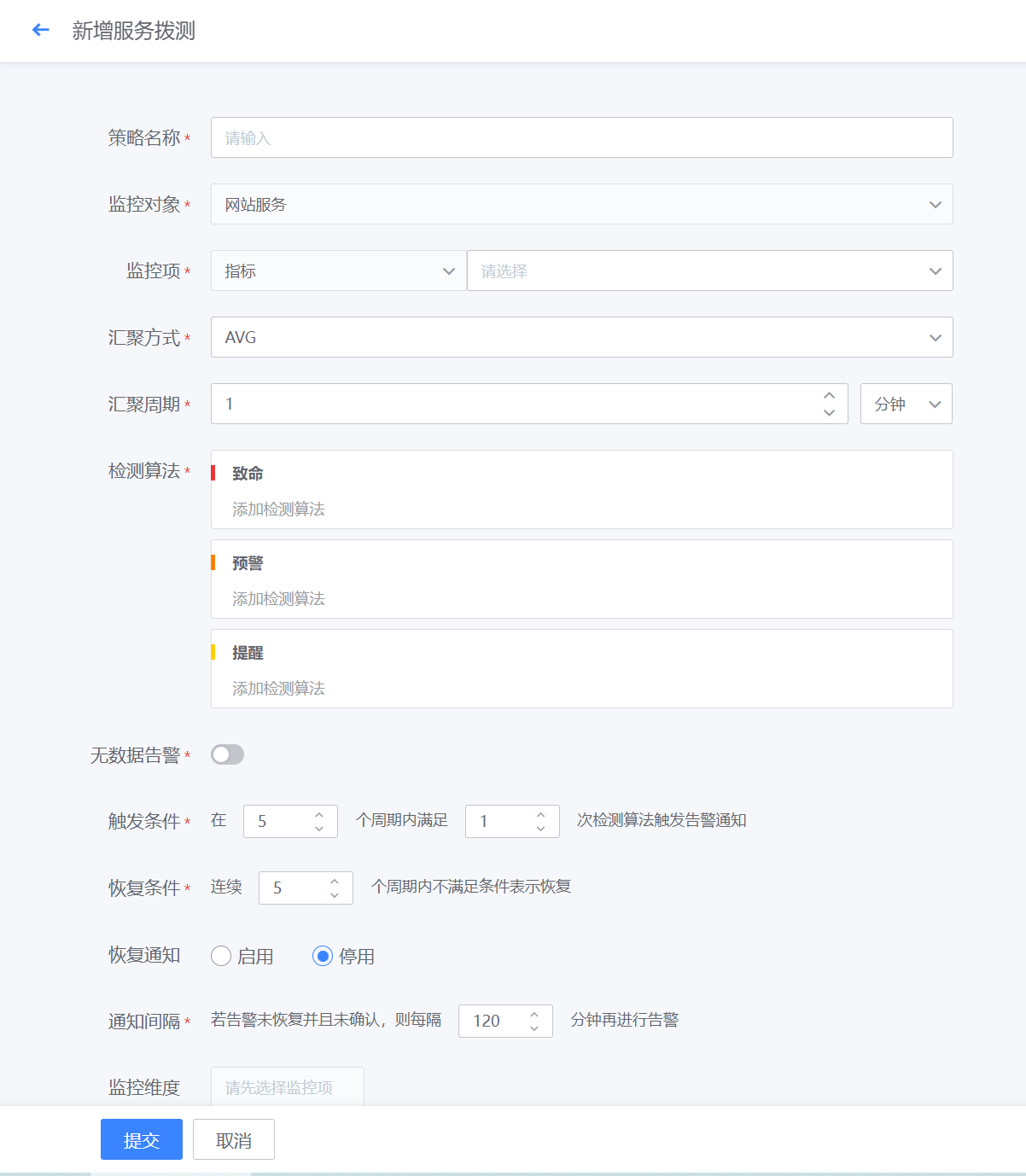
- 网站监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
2.1.6 K8S监控配置preview
背景介绍:需要将K8S集群中的pod/node纳入监控中,并配置相应的监控策略。
Step1:监控采集
路径:管理-监控管理-监控采集
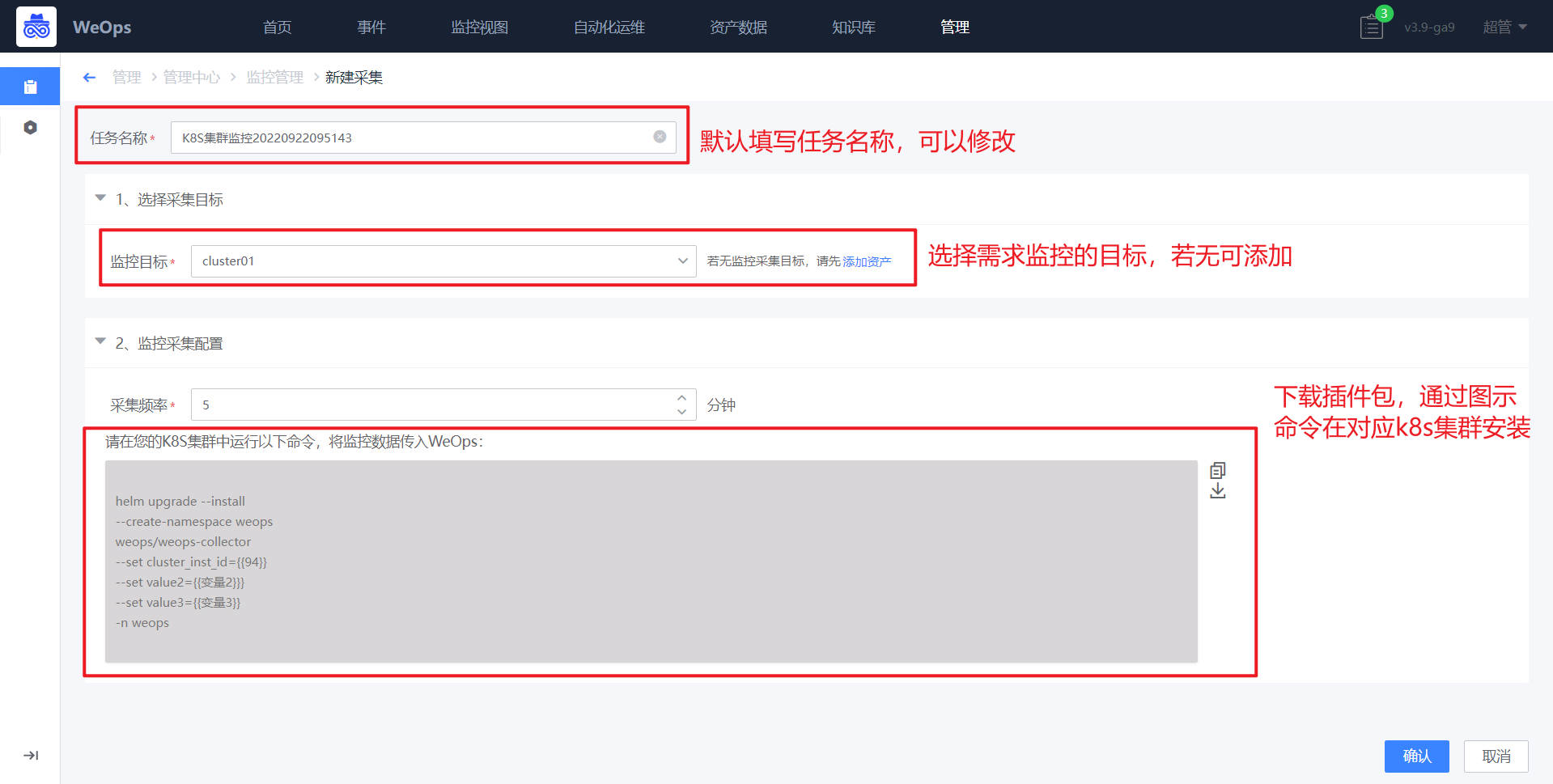
- 如下图,进入监控采集页面,选择K8S,K8S采集任务的新建。

- 如下图,在采集新建界面,选择需要采集的K8S集群名称(若无可以在该页面进行添加)、配置采集频率,进行K8S监控需要将对应的安装包安装到对应的k8s集群里面,可以从该界面下载安装包,并运行一下命令进行安装
注:有以下两种情况
(1)若集群可以使用公网镜像源时,解压安装包,进行安装即可
tar -zxvf weops-kubernetes.tgz
helm install weops-collecter weops-kubenetes-discovery-3.11.0.tgz -n weops --create-namespace --set remoteWrtieUrl=http://$(接收数据的Prometheus IP,一版为weops的appt ip):$(接收数据的Prometheus端口,一般为9093)/api/v1/write
(2)若不能使用公网镜像源时,需要先手动导入镜像并推送到私有仓库中,当集群不能使用公网镜像源时,需要手动导入镜像并推送到私有仓库中,压缩包里附带了需要用到的镜像文件,kube-state-metrics.tgz,node_exporter.tgz,cadvisor.tgz,prometheus.tgz
需要在helm install时指定本地仓库镜像helm install weops-collecter weops-kubenetes-discovery-3.11.0.tgz -n weops --create-namespace \
--set remoteWrtieUrl=http://$(接收数据的Prometheus IP,一般为weops的appt ip):$(接收数据的Prometheus端口,一般为9093)/api/v1/write \
--set image.repository=$(prometheus的私有仓库,如10.10.10.10:5000\prometheus) \
--set kube-state-metrics.image.repository=$(kube-state-metrics的私有仓库,如10.10.10.10:5000\kube-state-metrics) \
--set cadvisor-exporter.image=$(cadvisor的私有仓库,如10.10.10.10:5000\cadvisor):latest \
--set node-exporter.image=$(node-exporter的私有仓库,如.10.10.10:5000\cadvisor):latest
Step2:监控策略配置(以node为例)
路径:管理-监控管理-监控策略(K8S)
K8S集群监控采集新建完成以后,可以对pod和node进行监控策略的配置。
如下图,进入到监控策略页面,选择K8S-node,点击“新建”按钮
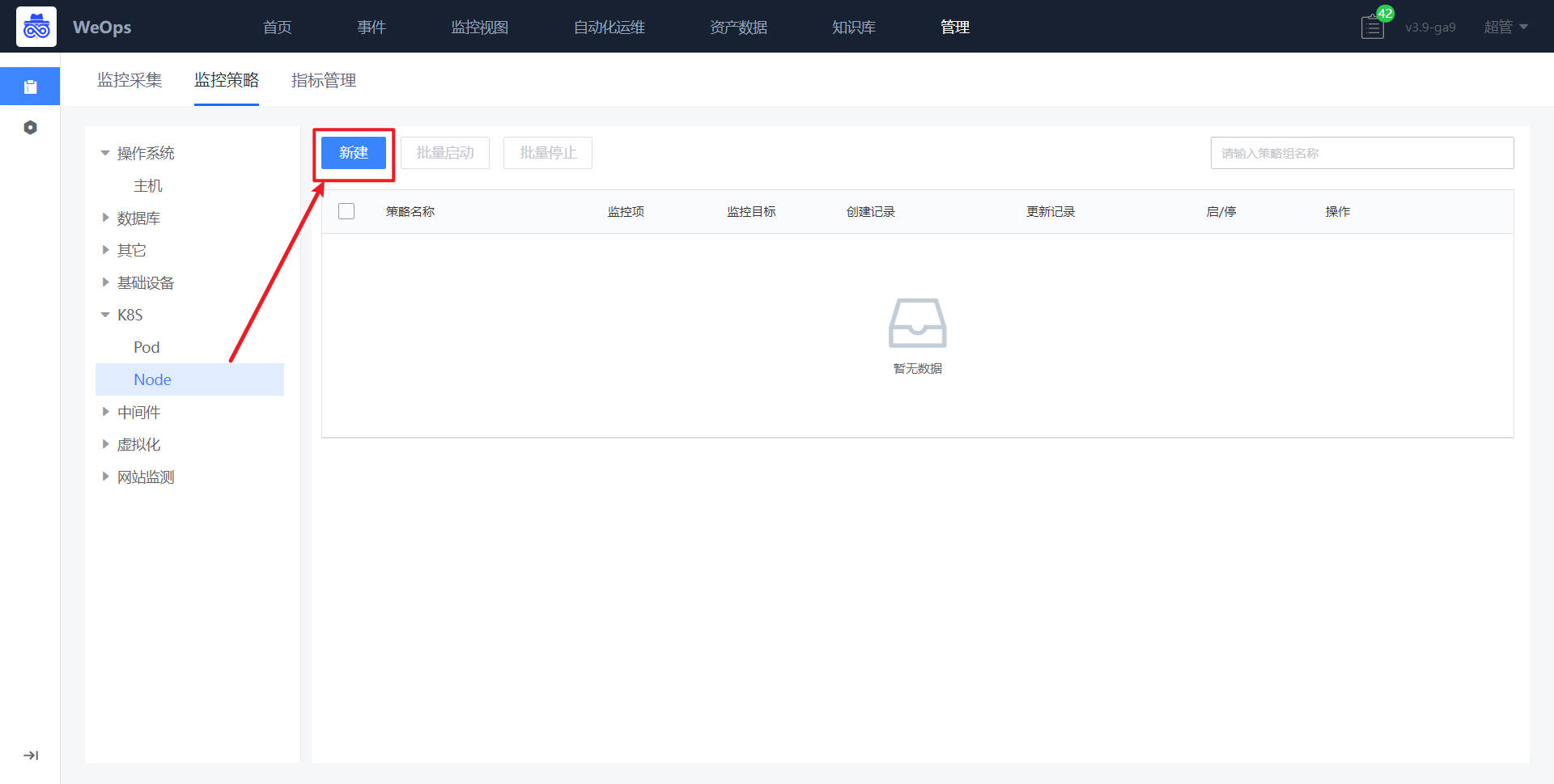
- 在新建界面,策略名称、和监控对象已经默认填写。
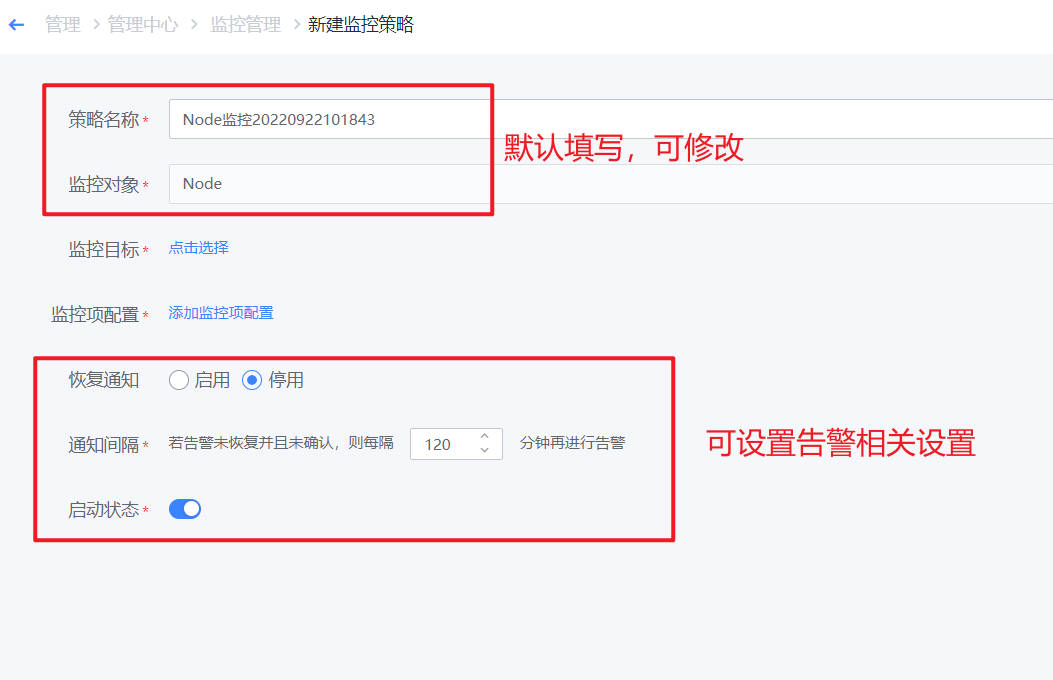
- 如下图,点击“选择监控目标”,进行监控对象的选择
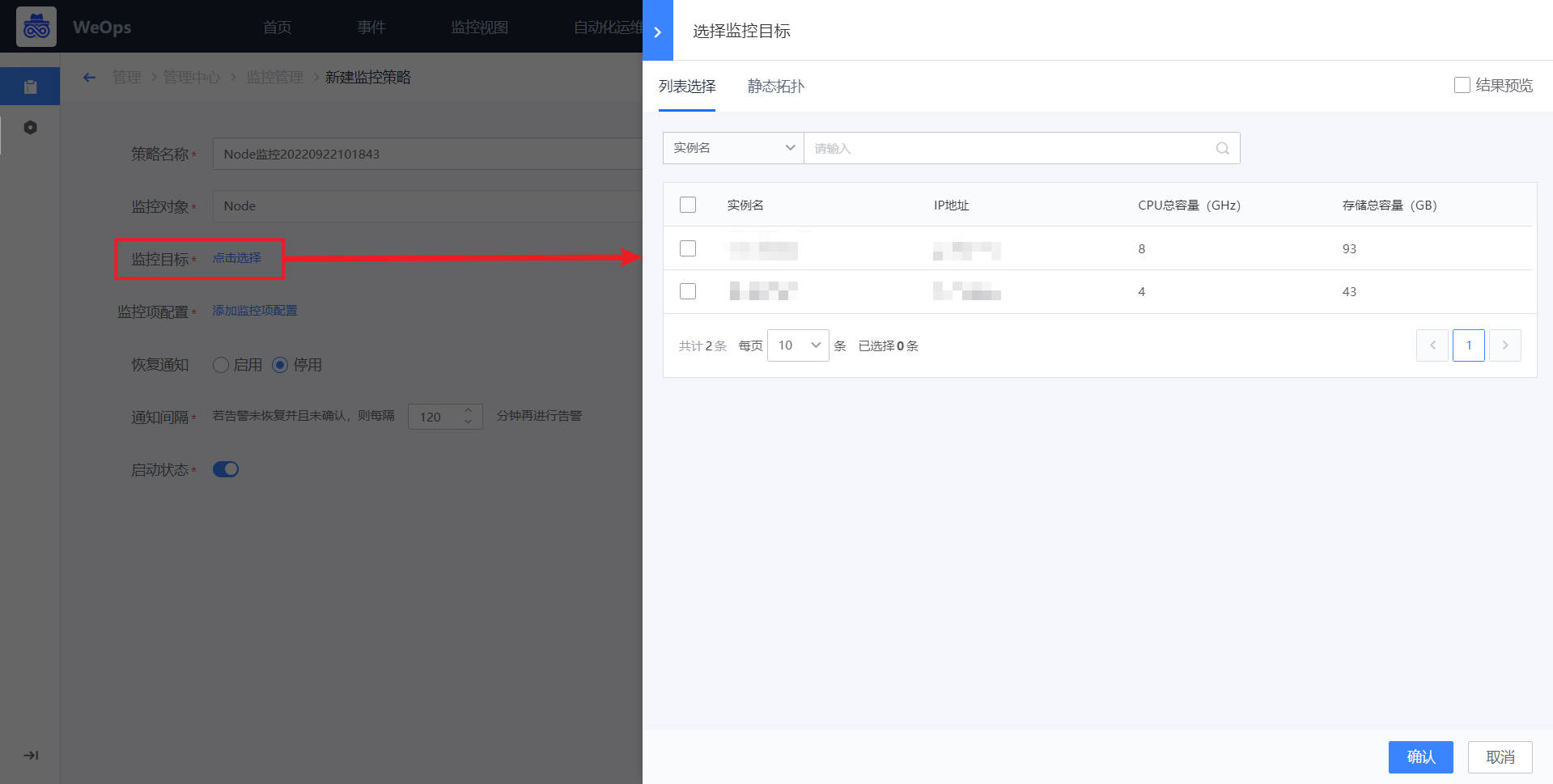
*如下图,点击“添加监控项配置”,可进行监控项的选择和配置,这里需要说明的是,由于K8S的特性,监控目标(pod和node)常常处于变化中,可以采取设置监控维度的方式,对某个集群/某个命名空间/某个工作负载下的pod/node进行监控策略的配置,配置成功后,无需选择具体的监控目标,该策略即可生效。
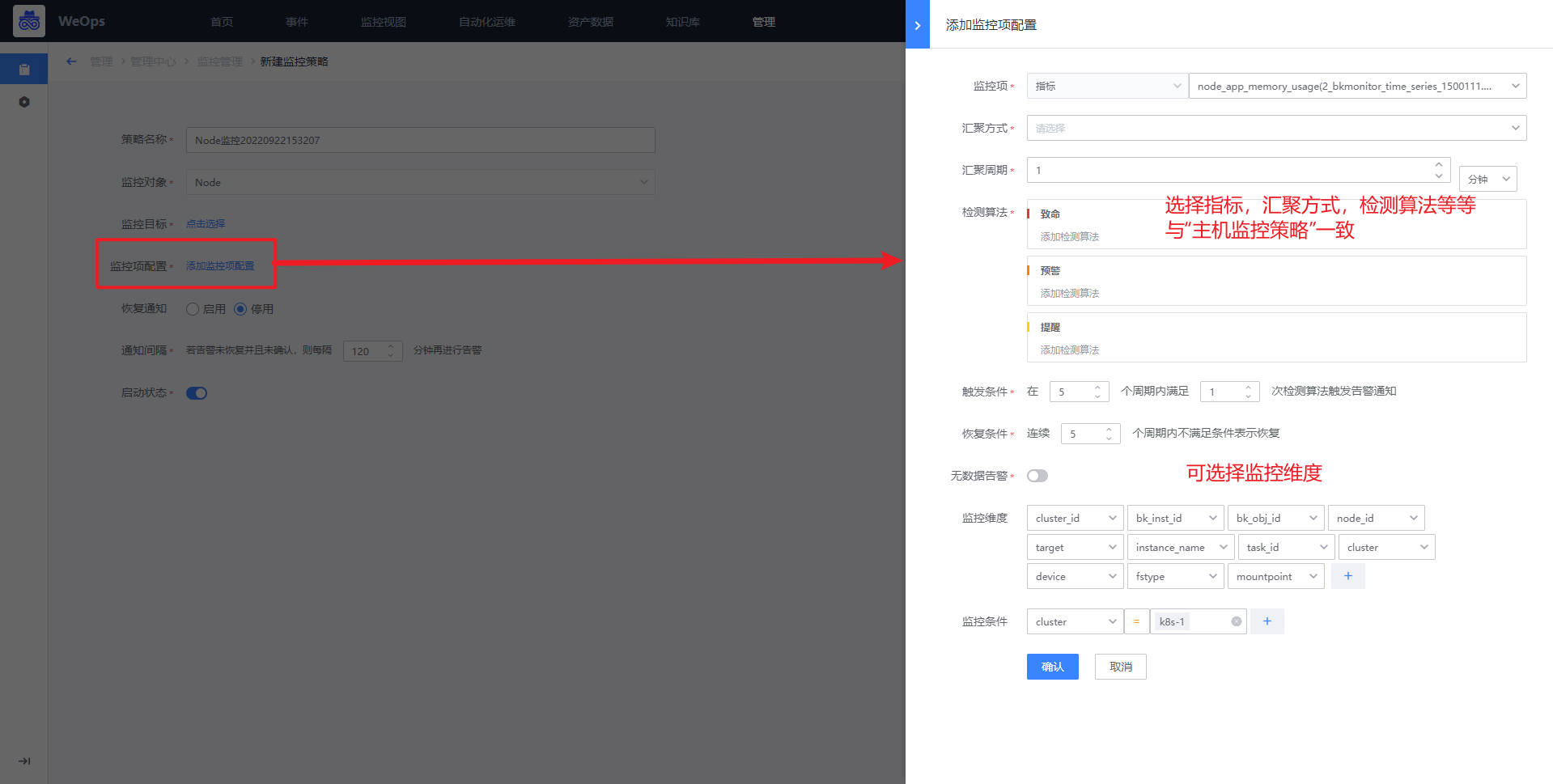
- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
2.1.7 网络设备监控配置(以交换机为例)preview
背景介绍:需要将网络设备纳入监控中,并配置相应的监控策略,前提是已经将网络设备手动/自动发现纳入到资产中了
Step1:导入网络设备指标模板
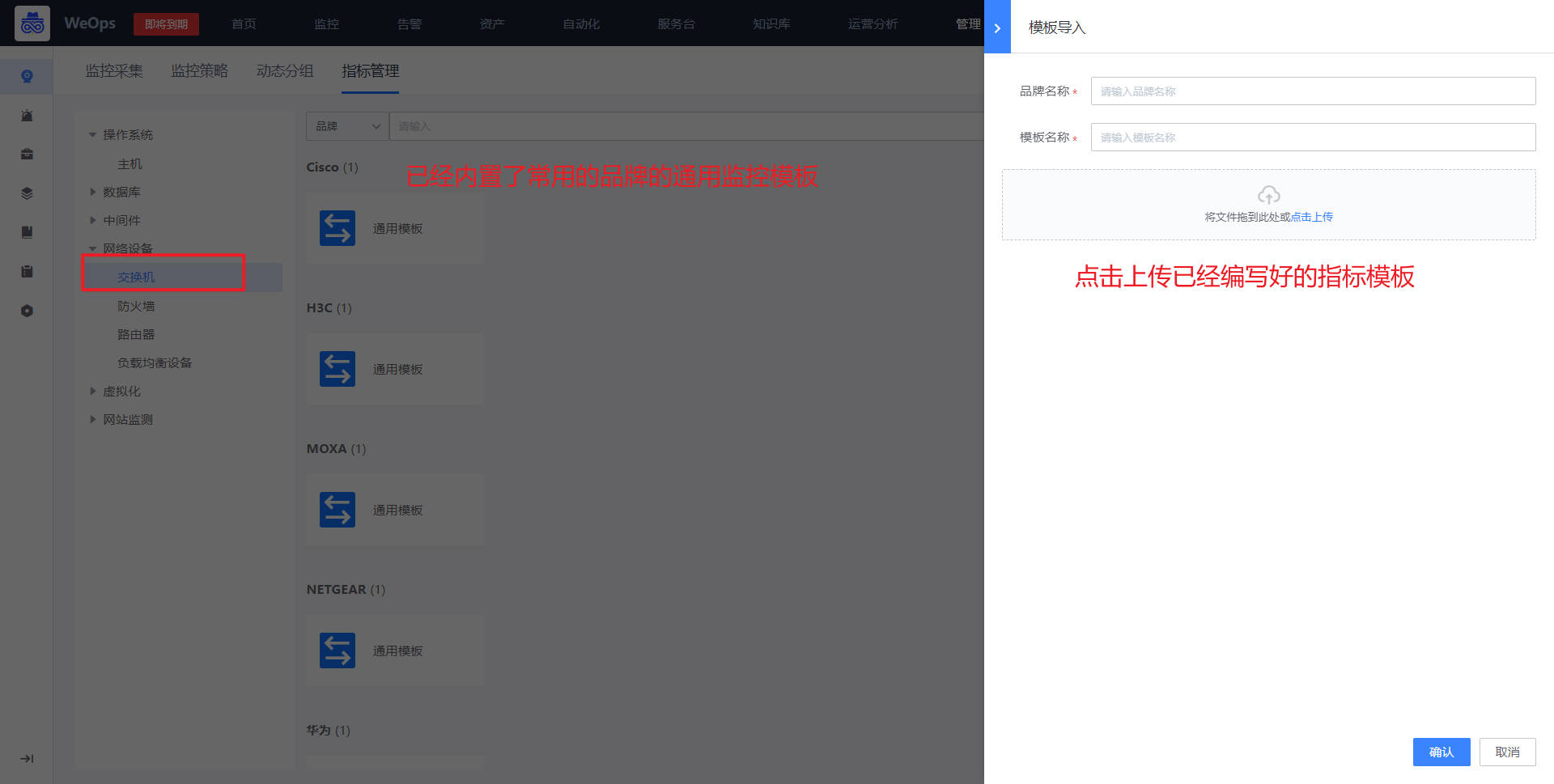
路径:管理-监控管理-指标管理
如下图,在指标管理中,选择网络设备-交换机,点击导入模板,可以进行不同品牌和型号的指标模板导入(WeOps提供了网络设备指标模板导入的入口,可监控的设备品牌、型号等支持拓展。)
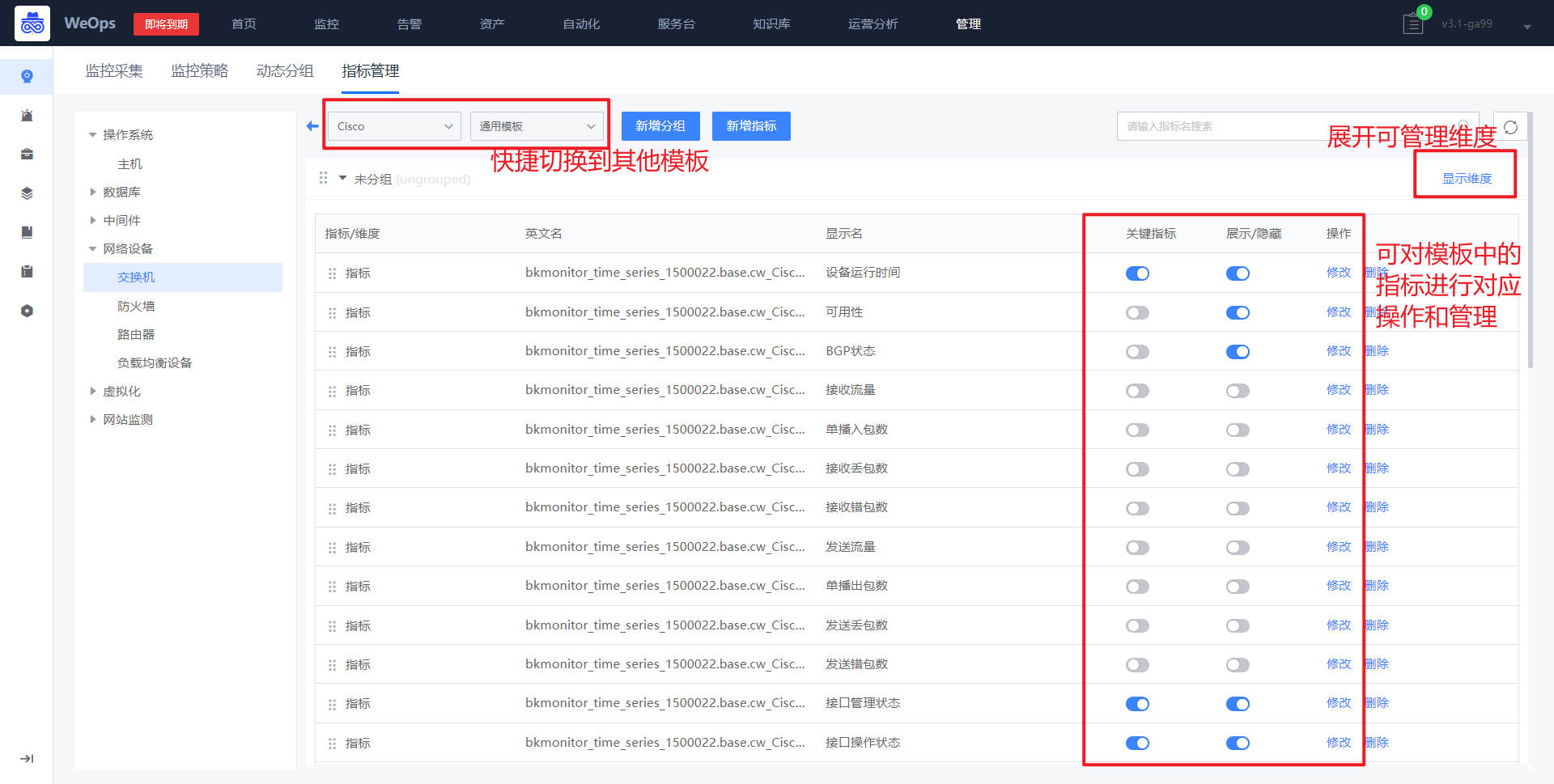
如下图,对于导入好的指标模板可以进行对应维度/指标的编辑,便于后续使用。
Step2:监控采集
当需要监控的网络设备已经纳管,并且有适用的监控指标模板(可以是内置的,也可以是导入创建的),可以对网络设备进行监控采集的创建,选择对应的目标,适用的指标模板,并填写凭据信息。


如下图,监控采集创建完成以后,可以在监控视图中,查看对应监控对象的监控信息
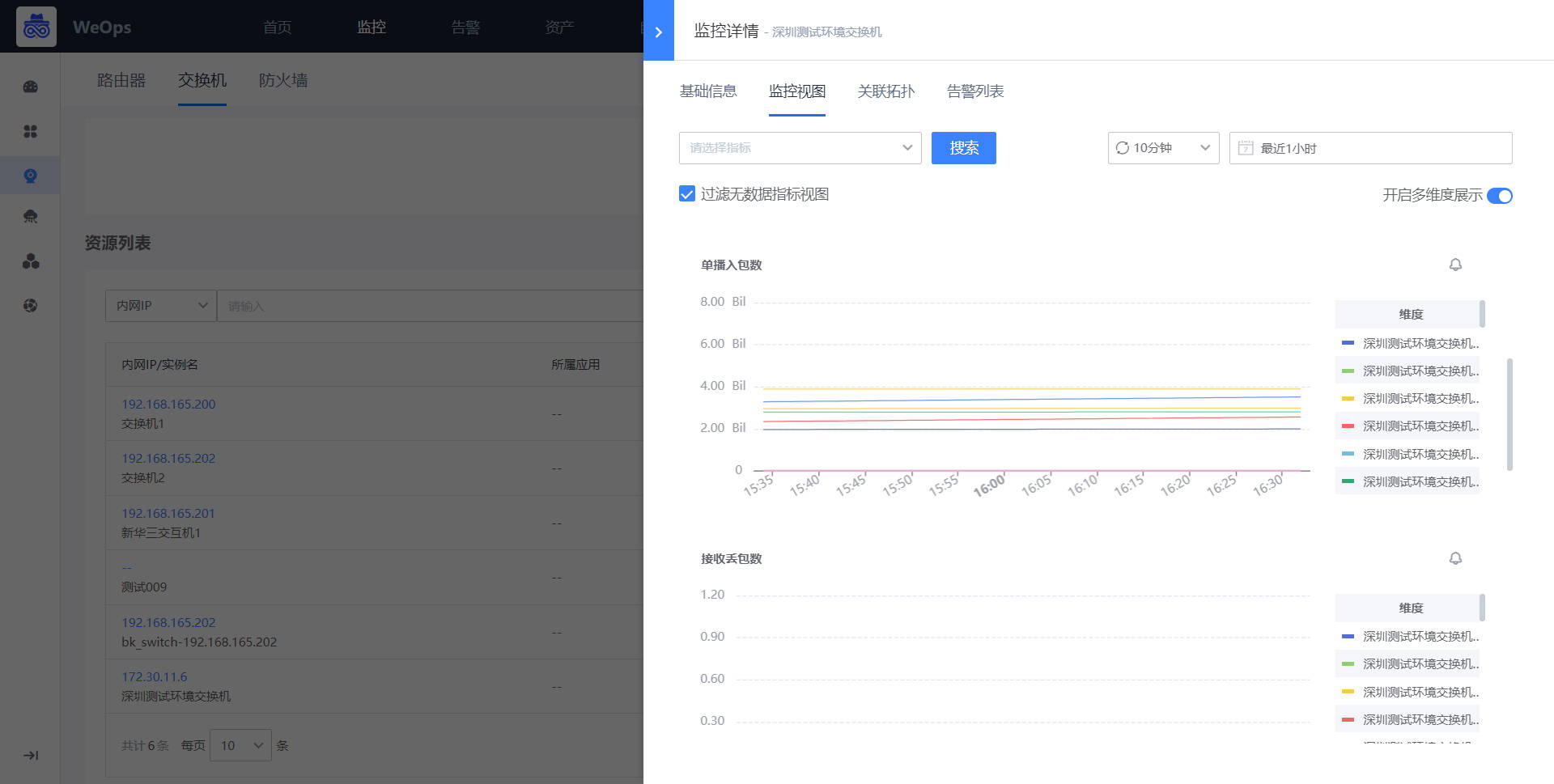
Step3:监控策略配置(以交换机为例)
网络设备监控采集新建完成以后,可以网络设备进行监控策略的配置。
如下图,进入到监控策略页面,选择网络设备-交换机,点击“新建”按钮
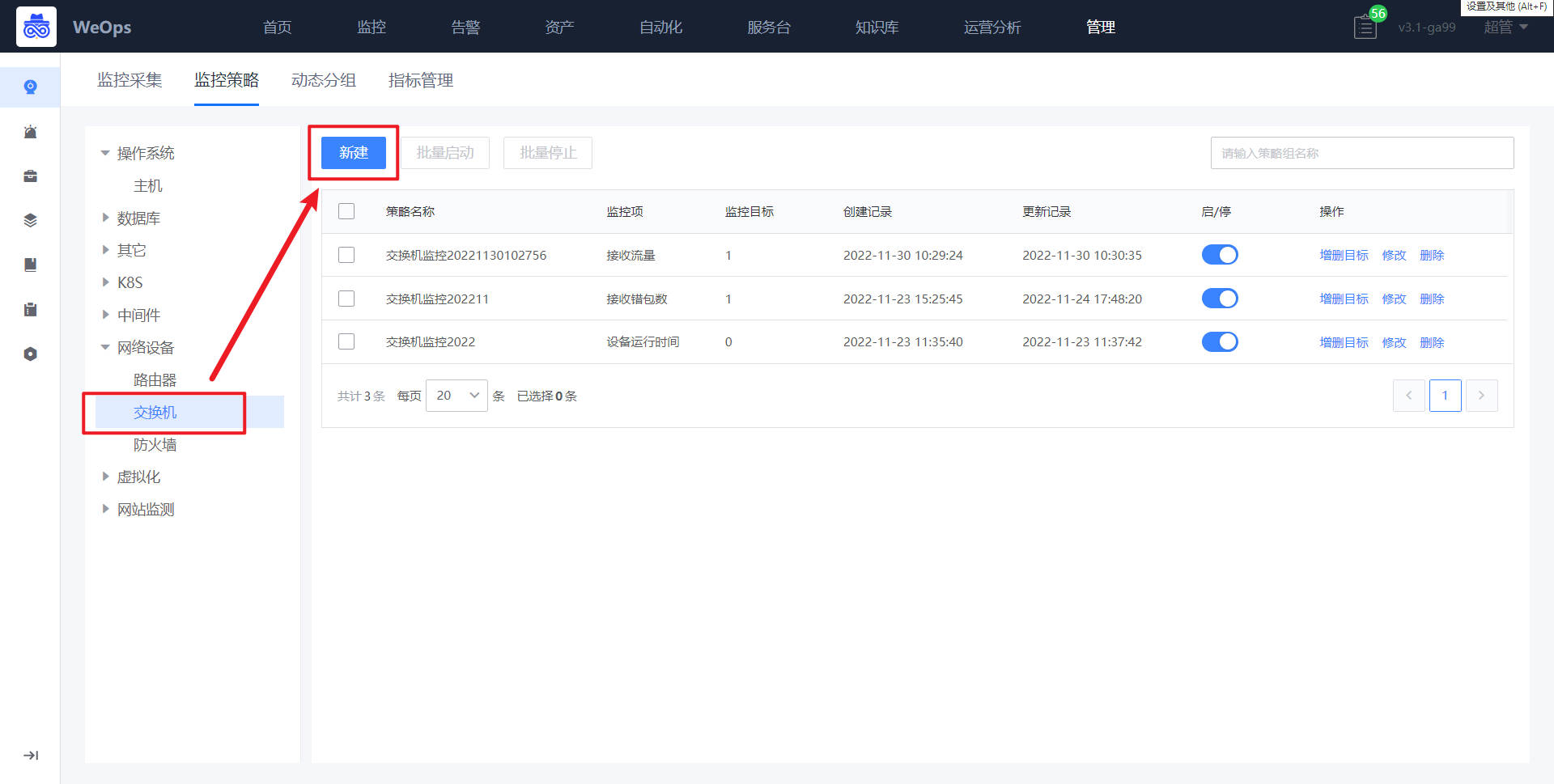
- 在新建界面,策略名称、和监控对象已经默认填写。点击“选择监控目标”,进行监控对象的选择点击“添加监控项配置”,可进行监控项的选择和配置
- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
2.1.8 硬件设备监控配置preview
背景介绍:需要将硬件设备纳入监控数据采集中,并设置对应监控策略。
Step1:监控采集
路径:管理-监控管理-监控采集
- 如下图所示,进入硬件服务器的监控采集界面,进行新增。

- 如下图所示,依次填写任务名称、腾讯云账号、对应凭据、采集频率等

- 新建完成后,可对该设置的硬件设备进行监控数据的采集,并可以在WeOps-监控视图-基础监控-硬件设备中查看已经采集监控数据和监控视图

Step2:监控策略配置
路径:管理-监控管理-监控策略(硬件监控)
- 如下图所示,进入到监控管理的监控策略页面,点击新增硬件设备-硬件服务器监控策略。

- 如下图所示,默认填写策略名称、监控对象,只需要选择监控项和监控目标即可(与主机监控策略配置操作一致)

- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。

- 下一步“告警配置”可查看“2.2告警配置”
2.2 告警配置
背景介绍:监控对象已经进行监控数据采集,并配置好相关的监控策略,需要对产生的告警配置抑制、屏蔽、自动分派、自动处理等策略,或设置人员通知。各个对象的告警配置一致,此处介绍通用方法。
告警抑制
通过用户自定义配置告警抑制策略,让符合筛选条件的告警被抑制(即不会成为有效告警)。
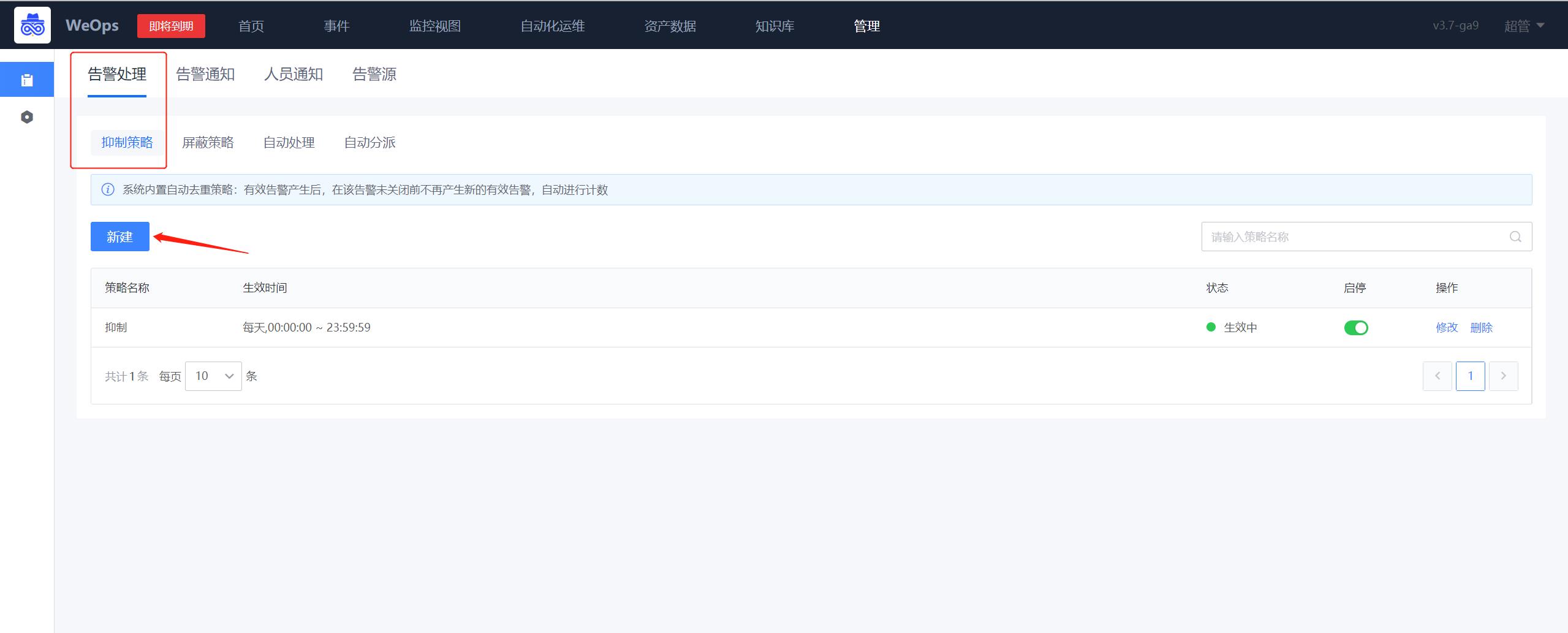
路径:管理-告警管理-告警处理-抑制策略
- 如下图所示,点击新增告警抑制策略规则。
- 如下图所示,按照如下指示输入匹配规则相关信息,随后点击提交即可完成配置。

注:目前有三种抑制策略
【第一种,内置的自动去重策略】:统一告警中心的告警都有一个告警事件 ID 字段,由告警源插件来设定这个字段的清洗规则,当一条告警成为有效告警后,在此条告警未关闭也未恢复的情况下,相同告警事件 ID 的告警自动被收敛。
【第二种,防抖抑制】:抑制抖动类指标偶发性产生的告警事件,如: CPU 使用率、内存使用率、磁盘 IO、网卡流量等
抑制规则: n 时间内出现 x 次则产生一条有效告警, 且告警关闭前不再产生新的告警。假设用户设定, 5min 内出现 4 次则产生一条有效告警;那么当告警中心接收到 1 条告警后,没有被自动去重,它会等待 5min,如果这 5 分钟内再次产生了 3 条及以上告警(除告警时间外,其他字段都相同),才会产生有效告警,5min 内产生的告警数量不足以达到数量要求,那这些告警全部被收敛,不会产生有效告警。
【第三种,关联聚合】:将关联字段相同的告警聚合,如: 7 分钟内“ 告警源+告警指标+告警对象+CMDB 业务+告警等级” 告警相同的告警聚合为 1 条有效告警。
聚合:第一条有效告警产生后,如果设定的时间窗口内产生关联字段相同的告警,那么这些告警被收敛。
执行顺序:如果一条告警被接收到后,之前没有相同告警事件 ID 的有效告警,则自动去重无法生效,执行告警抑制策略匹配,待产生有效告警后,后续接收的,相同告警事件 ID 的告警,会被自动去重;如果一条告警被接收到后,之前已有相同告警事件 ID 的有效告警,则优先执行自动去重,不会也不必再去执行抑制策略。
告警屏蔽
某些主机在执行一些日常任务的时候,例如定时备份任务,会导致CPU或是磁盘IO超过监控阈值。生成了”无效”告警,故可以采取该功能进行将特定条件下生成的告警事件进行屏蔽。
路径:管理-告警管理-告警处理-屏蔽策略
- 如下图所示,点击新增告警屏蔽策略规则。

- 如下图所示,按照如下指示输入匹配规则相关信息,随后点击提交即可完成配置。
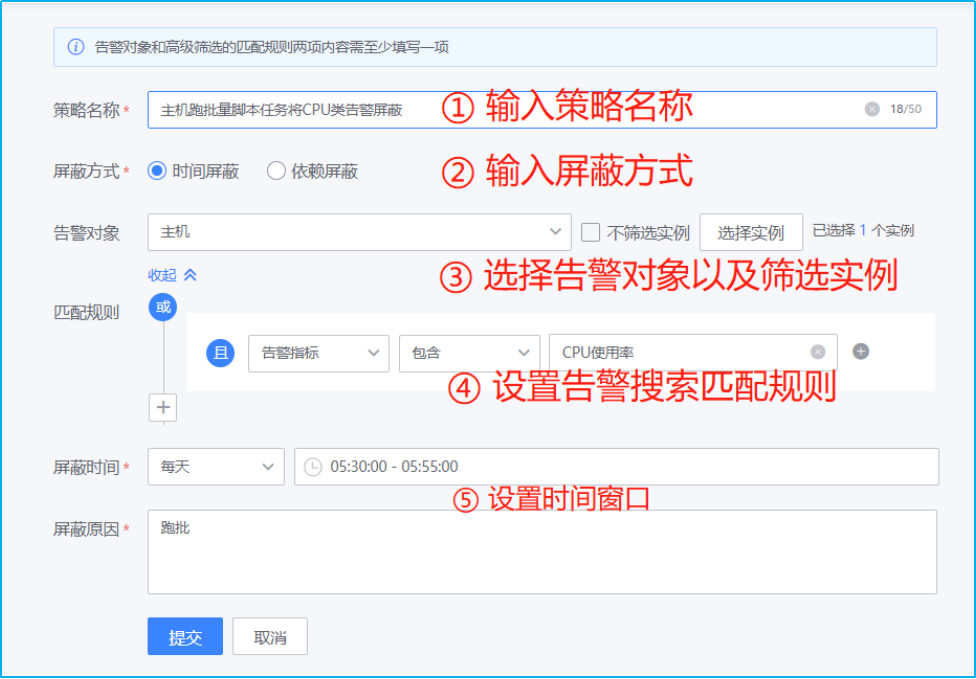
注:支持两种屏蔽方式:时间屏蔽(即维护期屏蔽,按时间段屏蔽符合筛选条件的告警)、依赖屏蔽(当符合 A 筛选条件的告警产生时,屏蔽之后 XX 时间段内的符合B 筛选条件的告警)。
告警自动处理
管理-告警管理-告警处理-自动处理
- 如下图所示,点击新增告警处理策略规则

- 如下图所示,新建页面,配置自动处理策略,让符合筛选条件的告警,根据策略优先级执行自动处理方案(包括自动转工单、自愈处理、自动关闭),可设置策略优先级、生效时间、分派人员、通知方式等
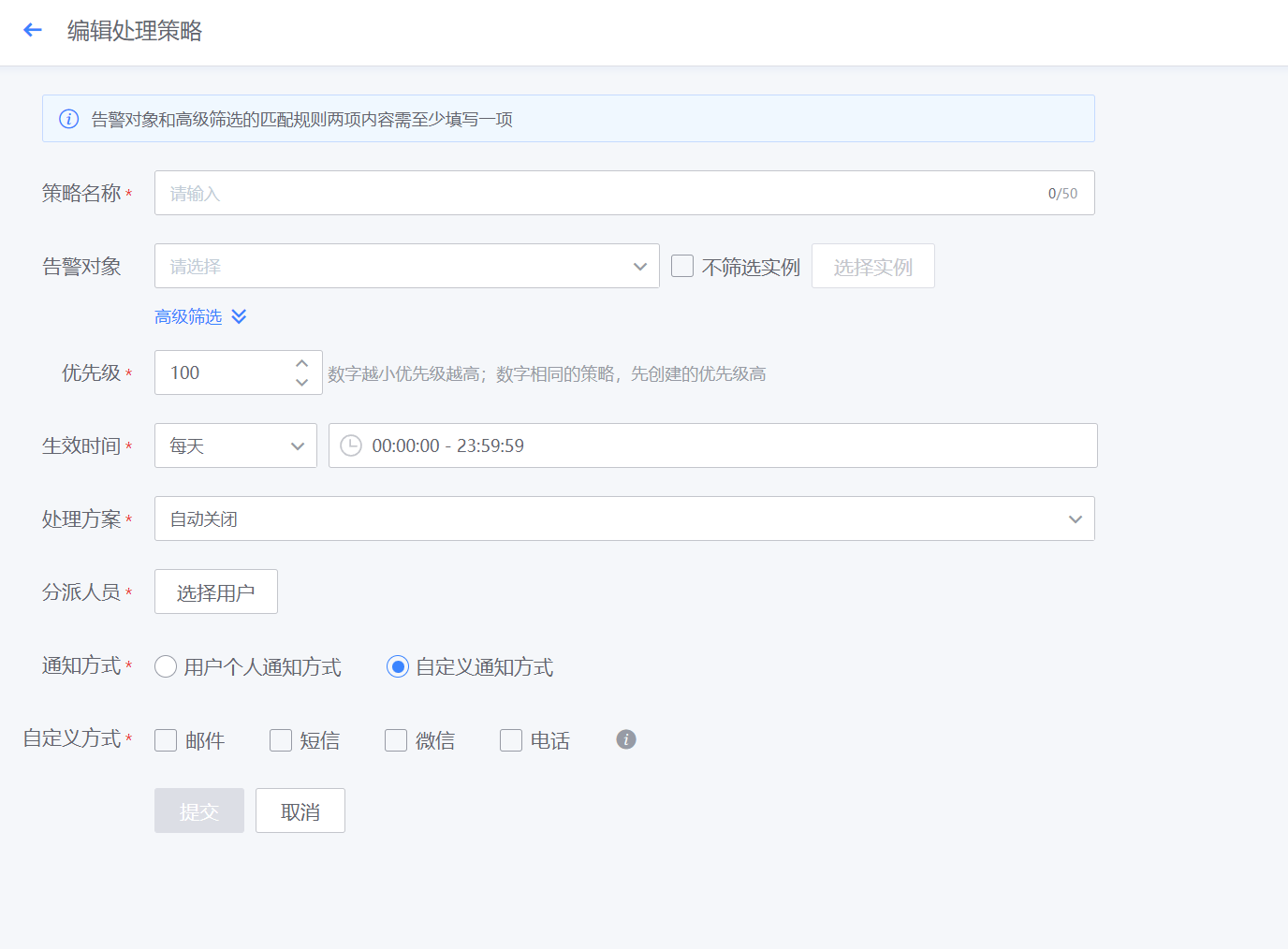
优先级: 1~100,数字越小执行该条策略的优先级越靠前,相同优先级数字的策略,创建时间早的的优先级更靠前。
分派人员:可根据组织目录的展开,选择用户;也可切换为全部用户,对用户名进行模糊搜索;还可以选择用户组(包括内置通知用户组和统一告警中心用户与组页面创建的用户组)。
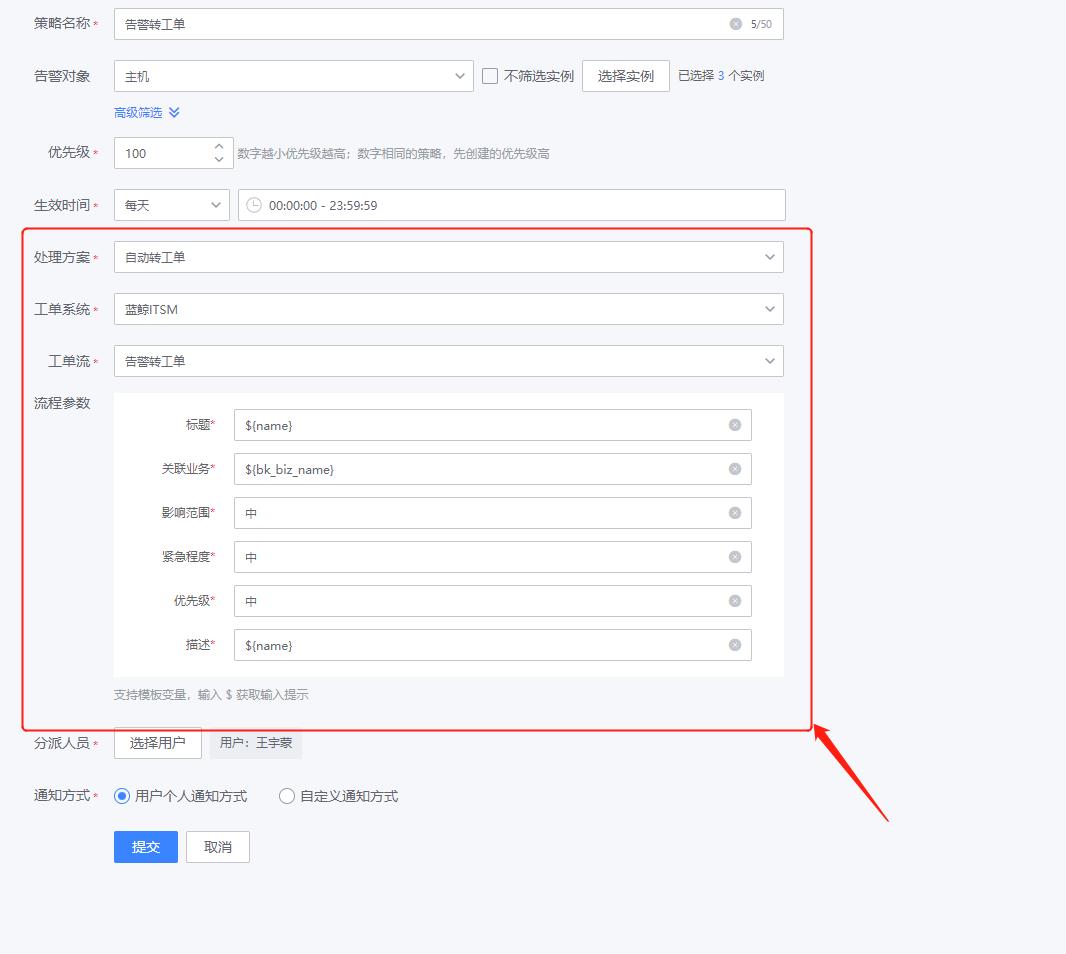
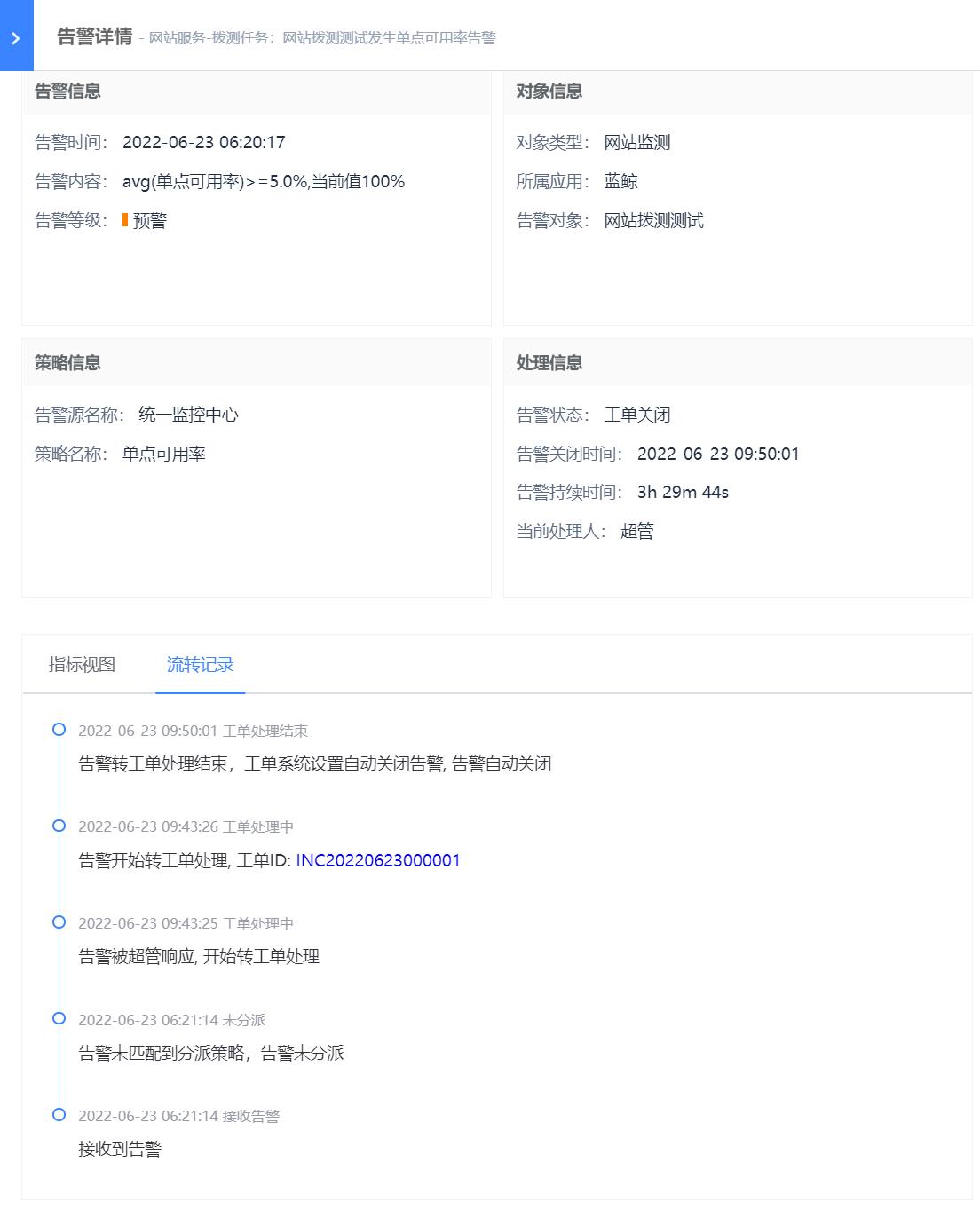
这里特殊说明下告警转工单,在“自动处理”中选择处理方案为“自动转工单”,按照工单模块内置的告警转工单流程进行相关字段的填写,设置完成后,符合该策略的告警将会转为工单处理,工单处理结束后,告警会自动关闭。
告警自动分派
配置告警自动分派策略,让符合筛选条件的告警,分派给指定人员或用户组,并可选添加附言、是否通知、通知方式等,这里以【短信】通知的形式来进行介绍
路径:管理-告警管理-告警处理-自动分派
- 如下图所示,进入到告警分派的界面,点击新增告警分派规则。
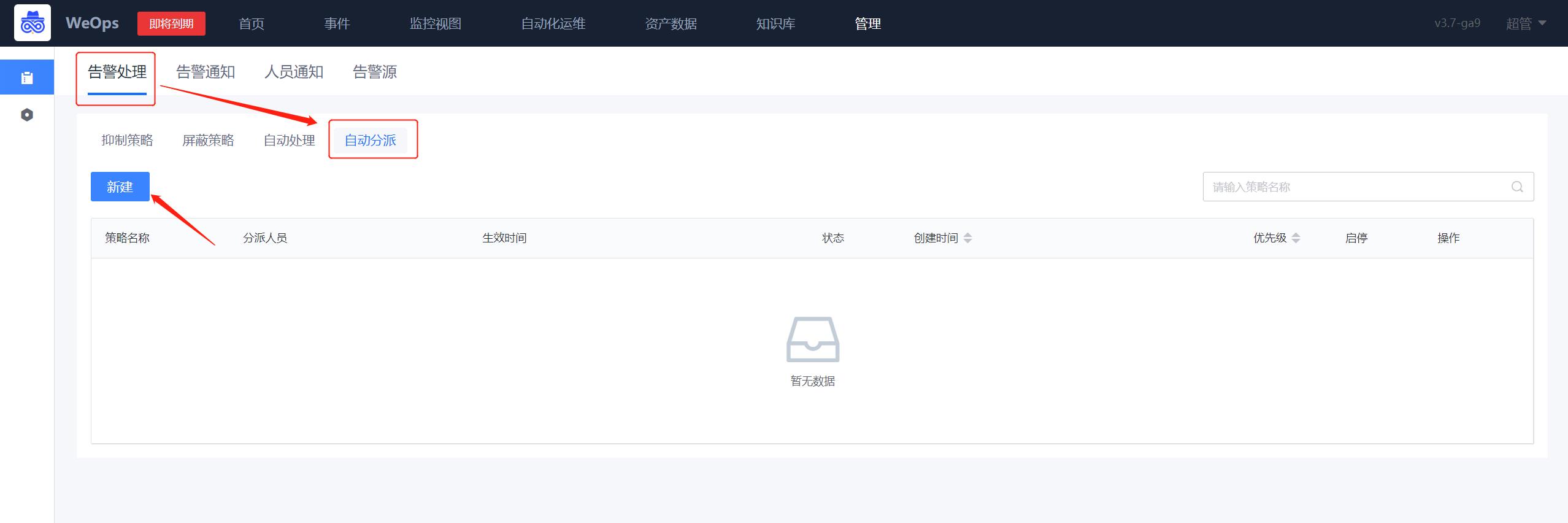
- 如下图所示,在第②步选择告警对象,若是不筛选实例则勾选【√不筛选实例】,若是需要筛选则按照第③步进行oracle主机的选择。随后按照第④步添加告警通知人员。在第⑤步选择“自定义通知方式-短信“。随后点击保存即可完成配置。

*分派策略优先级,同处理策略,优先级1~100,数字越小执行该条策略的优先级越靠前,相同优先级数字的策略,创建时间早的的优先级更靠前。
*优先执行告警处理策略,其后再执行告警分派策略。
*支持分派升级,当告警被分派,且分派用户在设定时间内未响应,可以升级分派给其他人,支持多级升级通知。还可设置分派通知规则,当告警未响应/未关闭时,重复通知给被分派用户。
*可设置通知频率,当告警未响应/未关闭时,重复发送通知。
人员通知
路径:管理-告警管理-人员通知
- 如下图,进入通知配置界面,选择对应的用户,点击“配置”按钮,可以进行通知方式的配置,可选“邮件、短信、微信、电话”等形式


2.3 动态分组配置
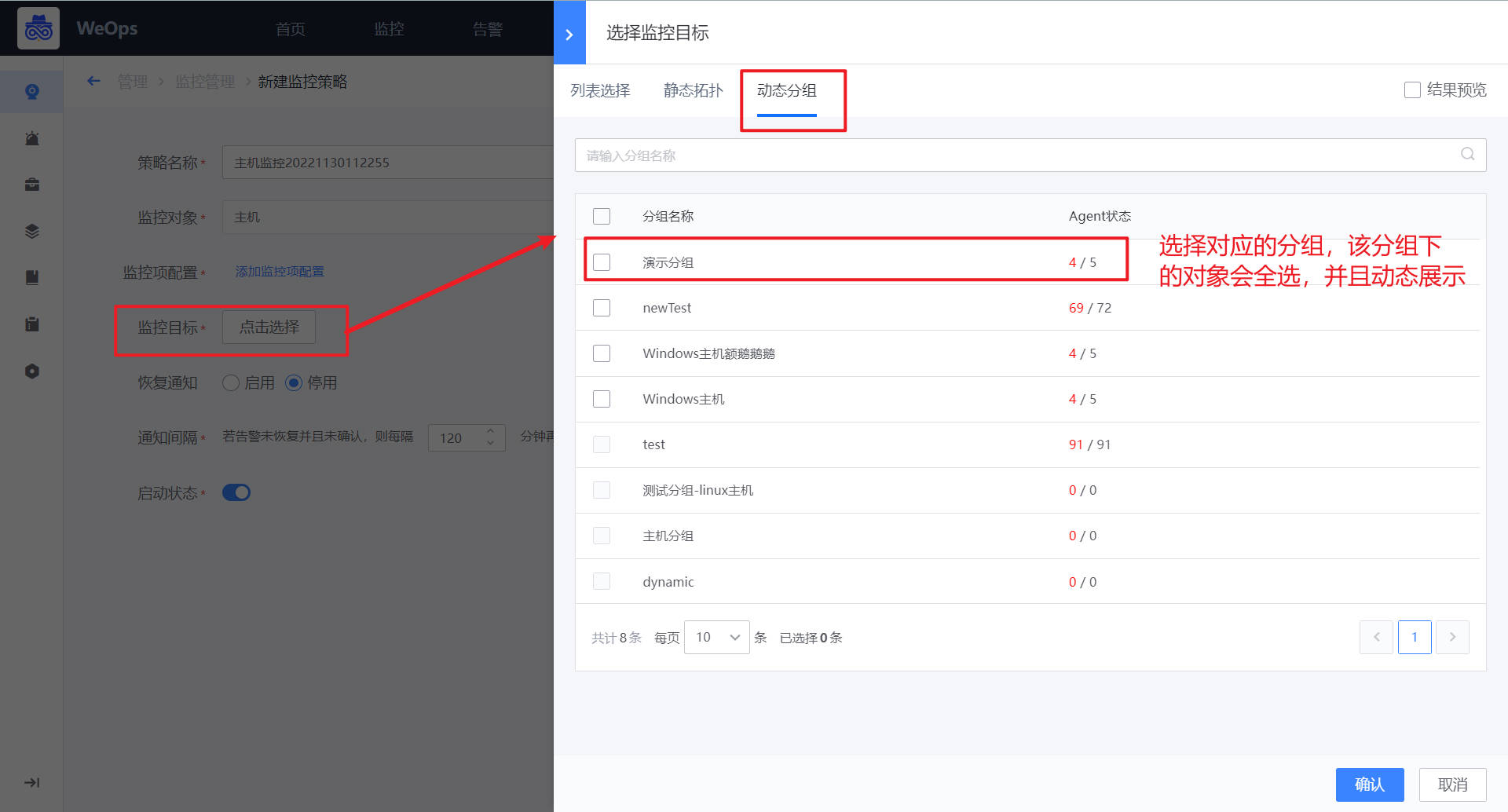
背景介绍:当监控策略的监控对象经常变动的时候,可以采用动态分组的方式,设置动态分组并设置监控策略。
分组设置
路径:管理-监控管理-动态分组
如下图,点击“新建“按钮,可以针对不同的对象,设置不同的分组条件。设置完成后,符合添加的对象会动态展示,一旦对象发生变化,该动态分组也会发生变化

分组效果
路径:管理-监控管理-监控策略
如下图,在监控策略中,选择监控目标的时候,可以选择该分组,当对象发生变化的时候,动态分组里面的对象也会对应变化,保证该监控策略始终监控的是符合条件的对象。
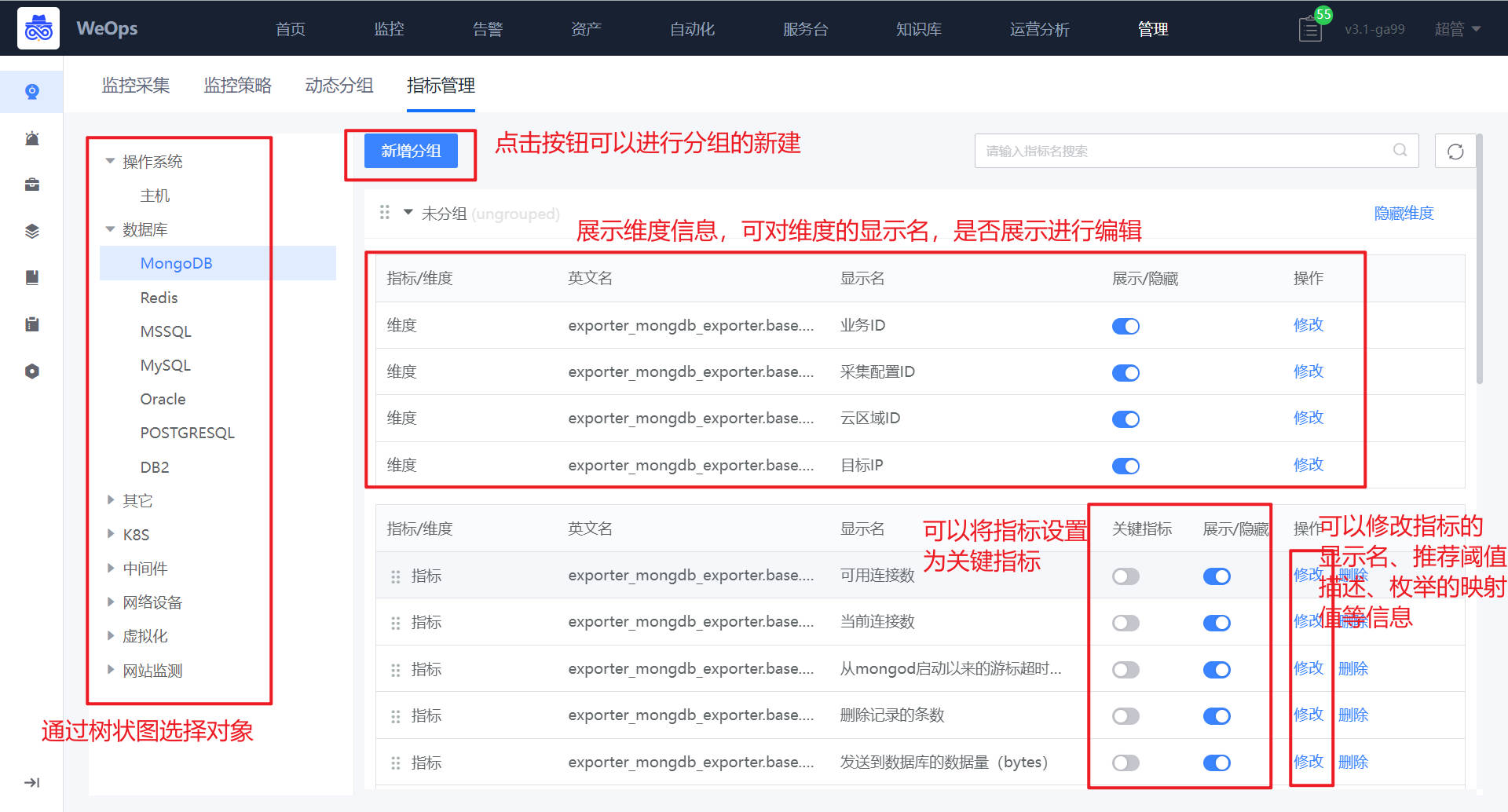
2.4 监控指标配置
背景介绍:监控对象已经纳管进来,并进行监控指标采集,需要对监控指标进行管理和分组,便于在监控视图中更方便的查看各个指标视图。
指标管理设置
路径:管理-监控管理-指标管理
如下图可以对指标的分组、设置关键指标、指标内容等方面的设置/编辑
指标分组:针对不同对象可以进行指标分组新建,分组创建完成后,可以通过拖拽的方式把指标拖拽至对应分组中。
设置关键指标:可以将指标设置为“关键指标”,设置成功后,在监控视图的顶端就可以看到“关键指标”的分组。
指标编辑:支持对指标的显示名、分组、推荐阈值和描述进行编辑,可以修改指标类型,对于枚举值的指标可以设置映射值,设置成功后可以在对应的监控视图看到设置的映射值。
指标维度:展示对应指标的维度,可以对维度的显示名,是否显示等进行编辑
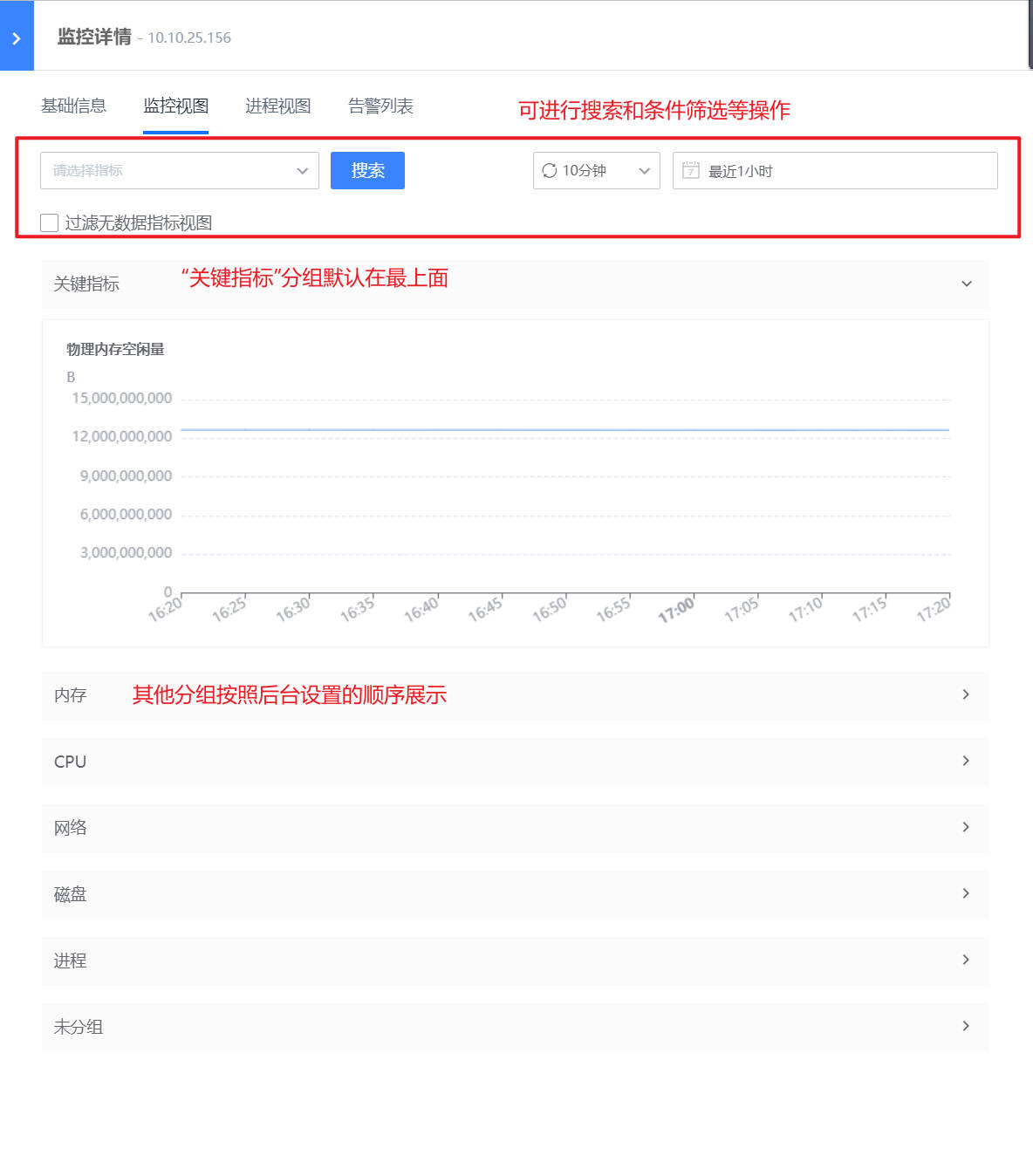
指标视图展示
路径:监控视图-应用/基础监控-主机/数据库/中间件等
如下图,指标管理配置完成后,在“监控视图-应用/基础监控”中的监控视图抽屉中,可以看到分组后的监控视图。
关键指标:标为关键指标的指标,在监控视图中的顶端可以看到“关键指标”的分组以及对应指标视图
指标分组:按照后台设置的分组情况进行展示,可进行搜索和条件筛选等操作
3、其他配置
3.1 工具管理
背景介绍:公司有经验的运维人员需要将自己沉淀的脚本转化为小工具,便于后续其他运维人员使用。
整体步骤:新建工具——工具使用
新建工具
路径:管理-管理中心-自动化运维-运维工具
WeOps-运维工具包括操作系统和网络设备两类
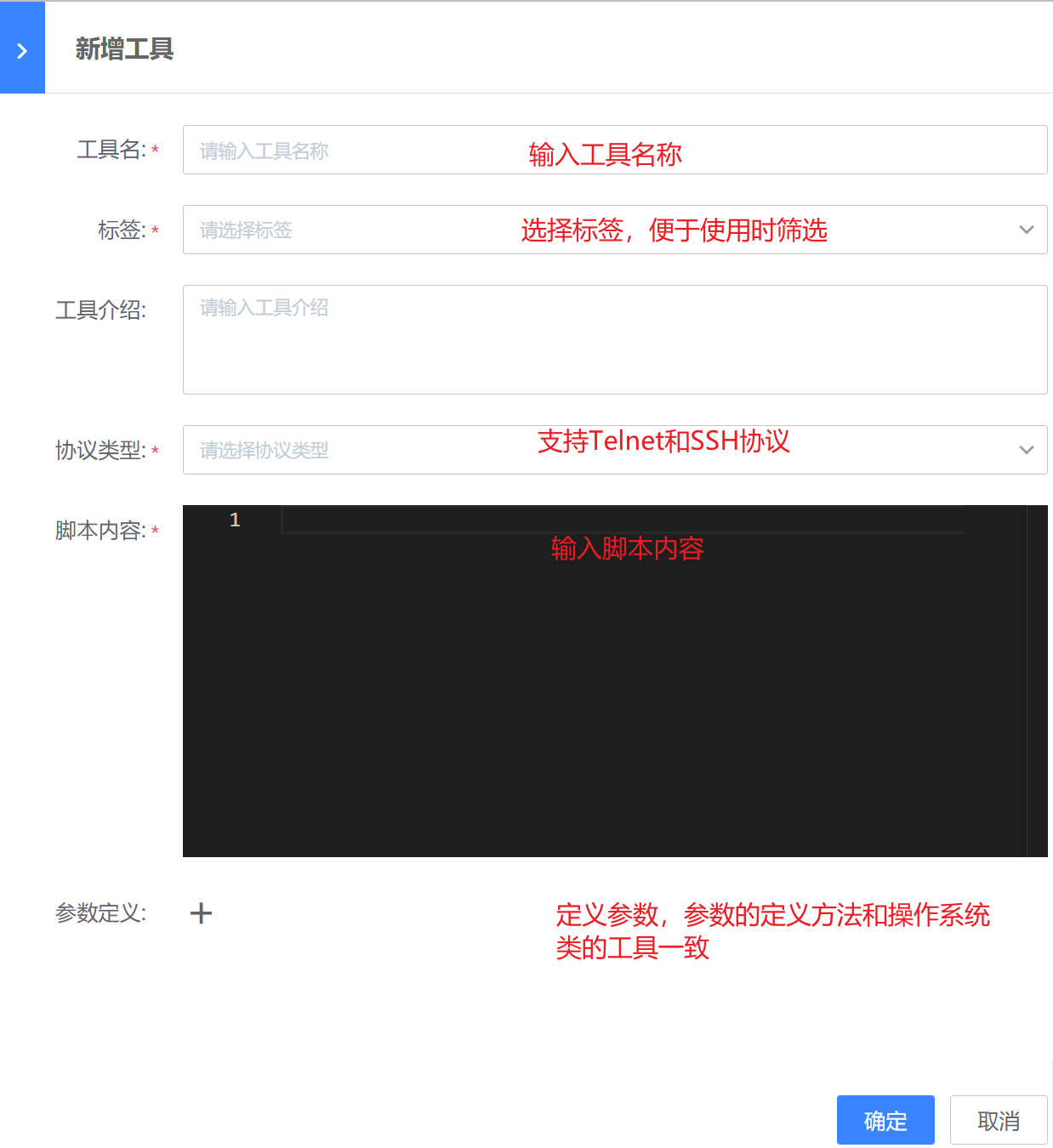
首先是操作系列类的工具新建:在工具管理界面,点击“新增工具”可进行工具的新增
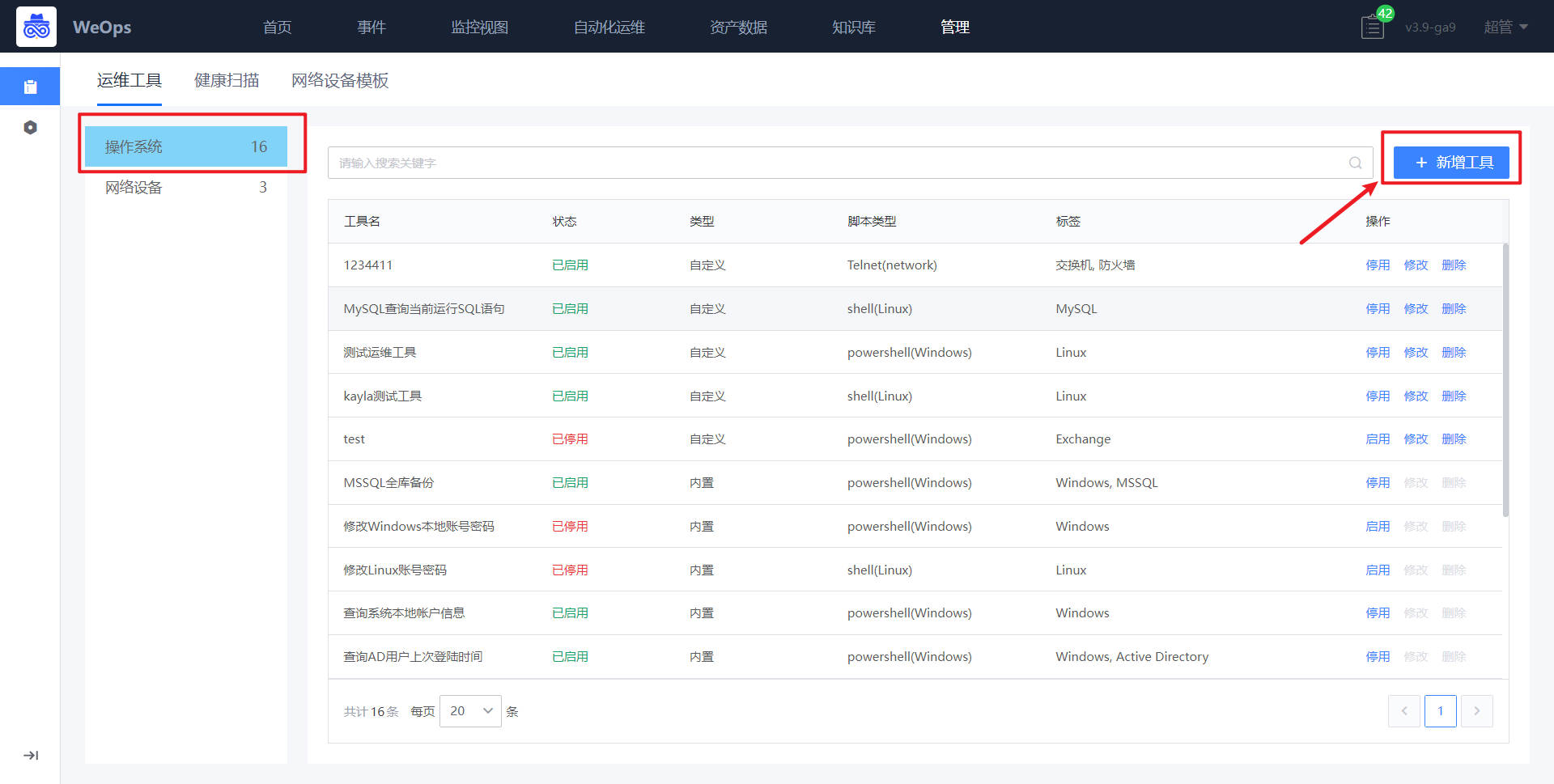
在工具新增界面,填写工具名称,选择对应标签和操作系统,Windows支持powershell和bat两类言语,linux支持shell和python两类语言。
特殊说明:与传统脚本使用不同,为了支持脚本工具在批量执行过程无需输入“参数信息”,在运维工具自定义的时候,将执行中用到的参数作为“位置参数“提前定义,并在脚本中对应的位置进行引用。这样,在工具执行前输入脚本执行需要的参数信息,即可一键批量执行,中途无需输入。
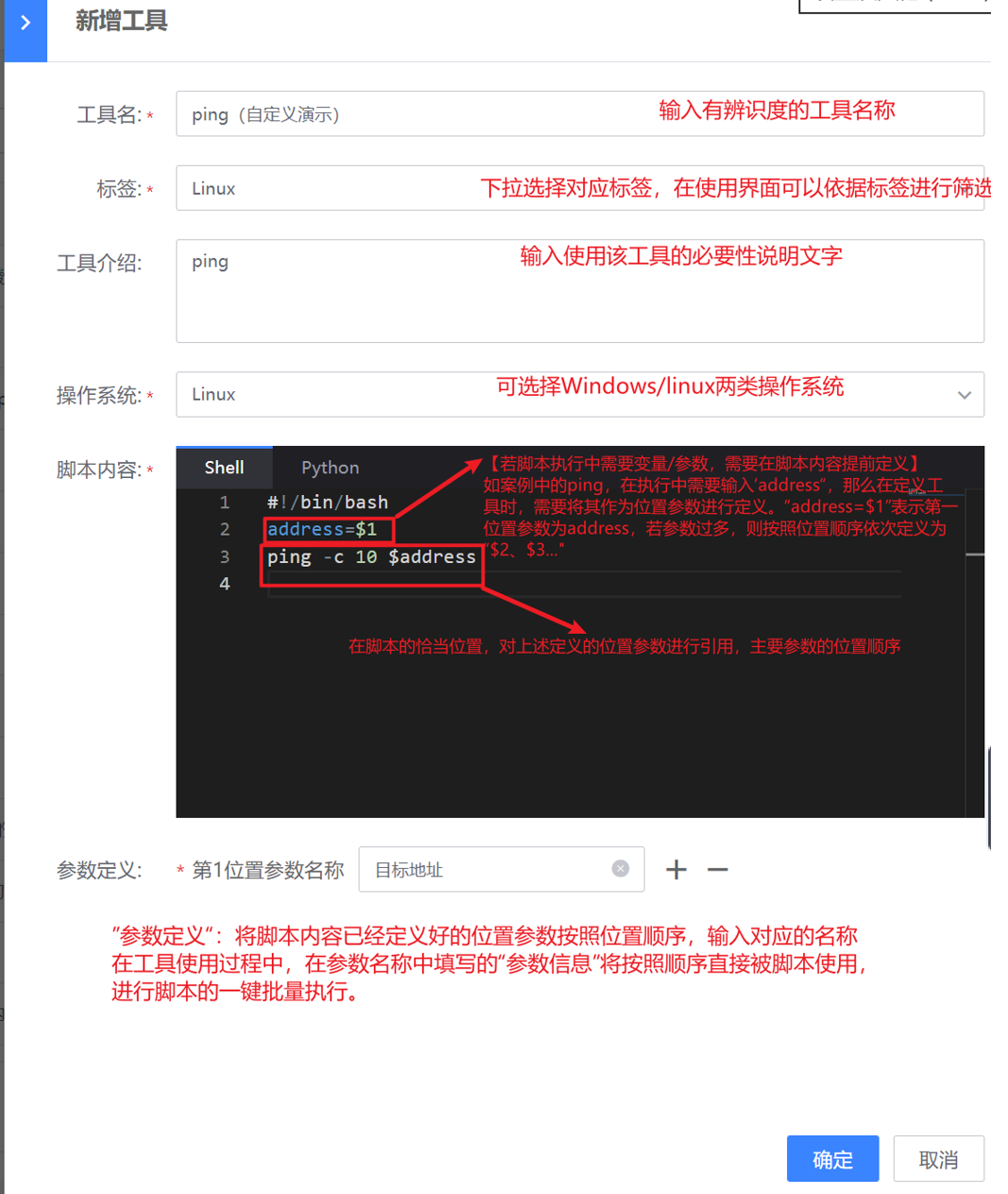
再者是网络设备类的工具新建:在自定义工具之前,需要对各类网络设备的脚本执行结束语进行设置,设置完成后方可在工具管理界面,进行工具的新建,这样工具在执行的时候就会按照设定的结束语结束脚本的执行
在“网络设备模板”中,点击“新建”按钮,创建某个品牌的某一类设备的结束语模板


点击模板的结束语,进行结束的创建
结束语定义完成以后,在选择“网络设备”,点击“新增工具”可进行工具的新增
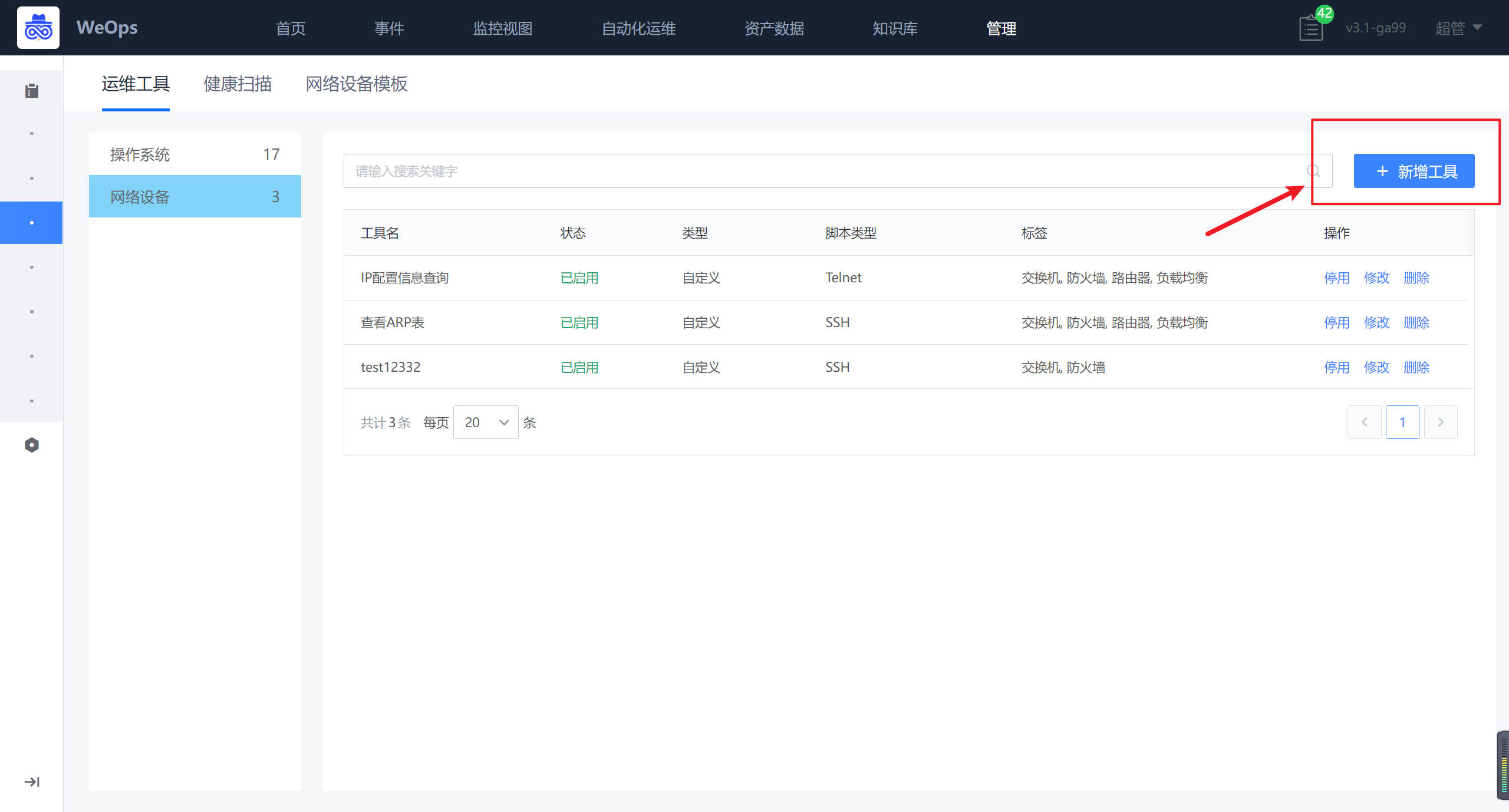
在工具新增界面,填写工具名称,选择对应标签,支持交换机/路由器/防火墙/负载均衡,支持Telnet和SSH两类协议。
工具使用
路径:自动化运维-运维工具-脚本工具
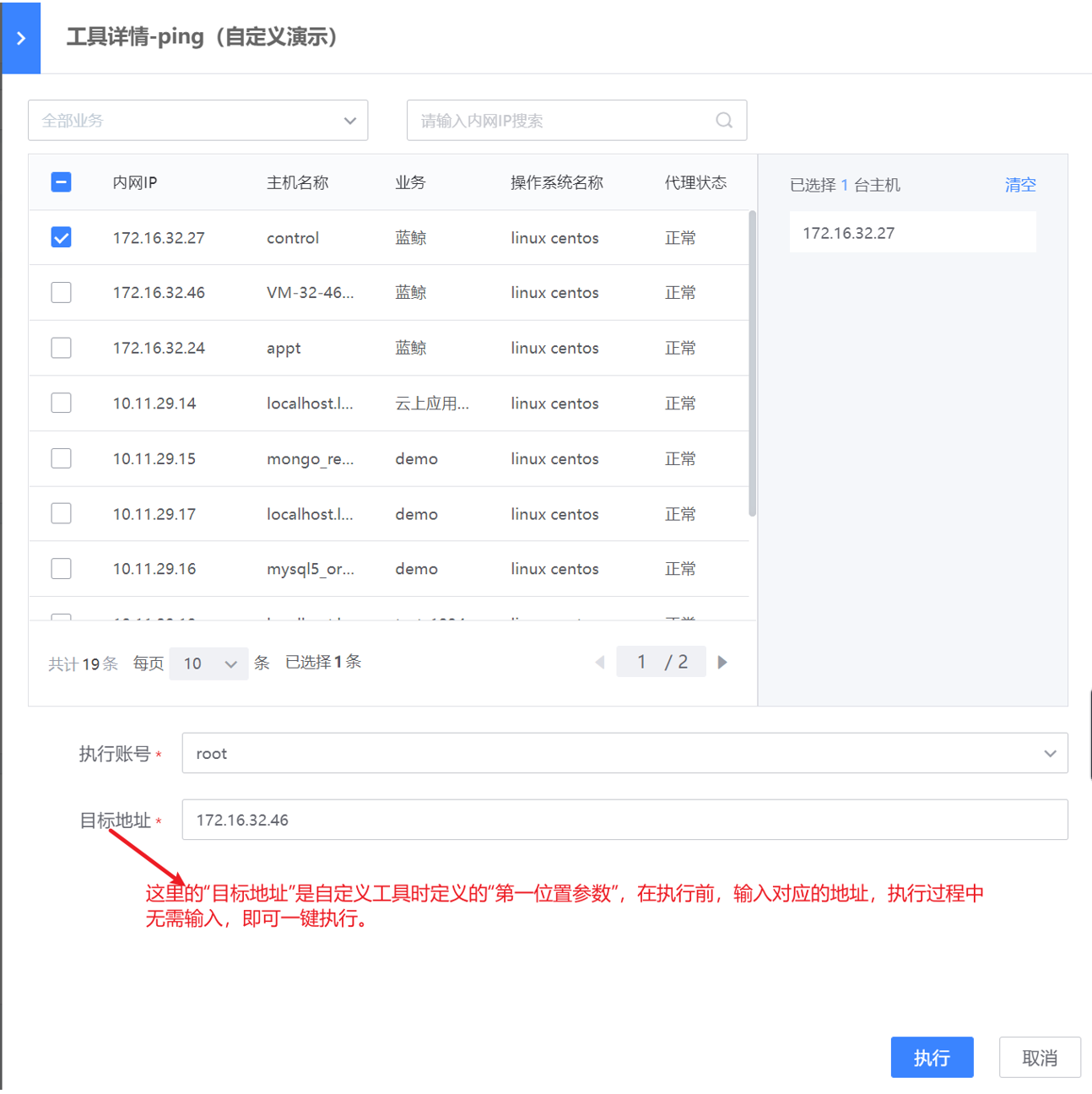
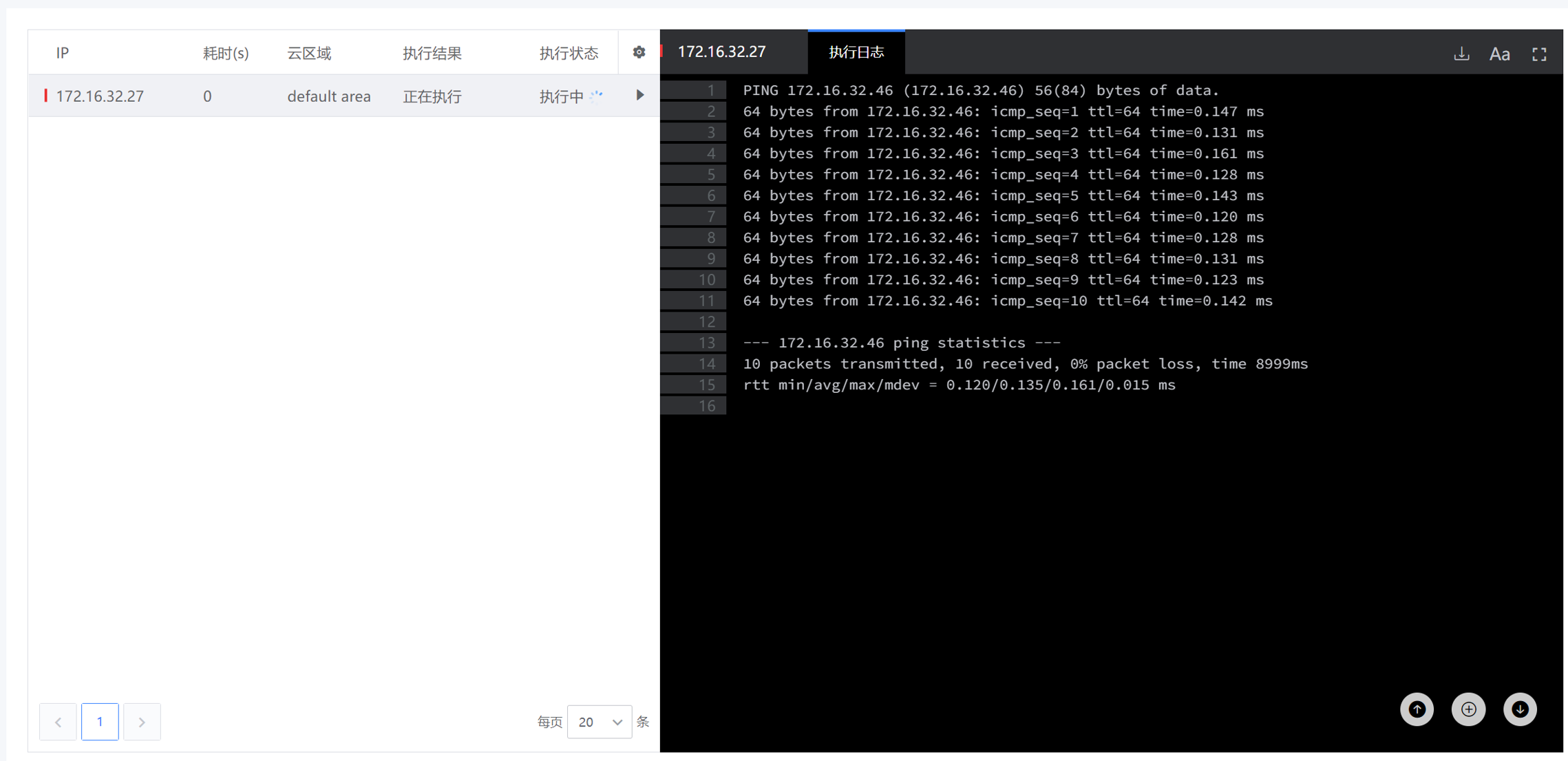
工具新建完成后,可在“运维工具-脚本工具”中查看到新建的工具,点击工具,选择对应的资产列表,输入定义好的参数信息,点击执行,即可查看执行结果。

3.2 扫描包管理
背景介绍:运维人员需要新增扫描包,或者对现在内置的扫描包的检查项和参数进行设置。
整体步骤:新建扫描包——扫描包设置
新建扫描包
路径:管理-管理中心-自动化运维-健康扫描
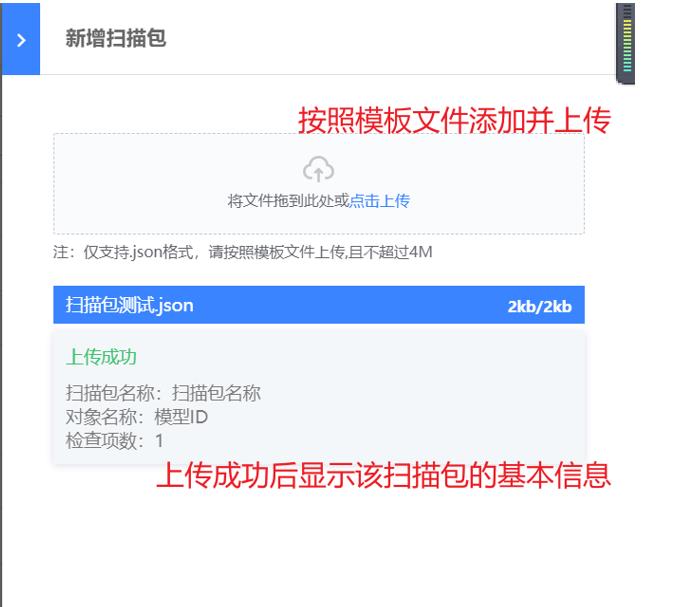
在“健康扫描”界面,点击“新增”按钮,可以进行扫描包的新建。
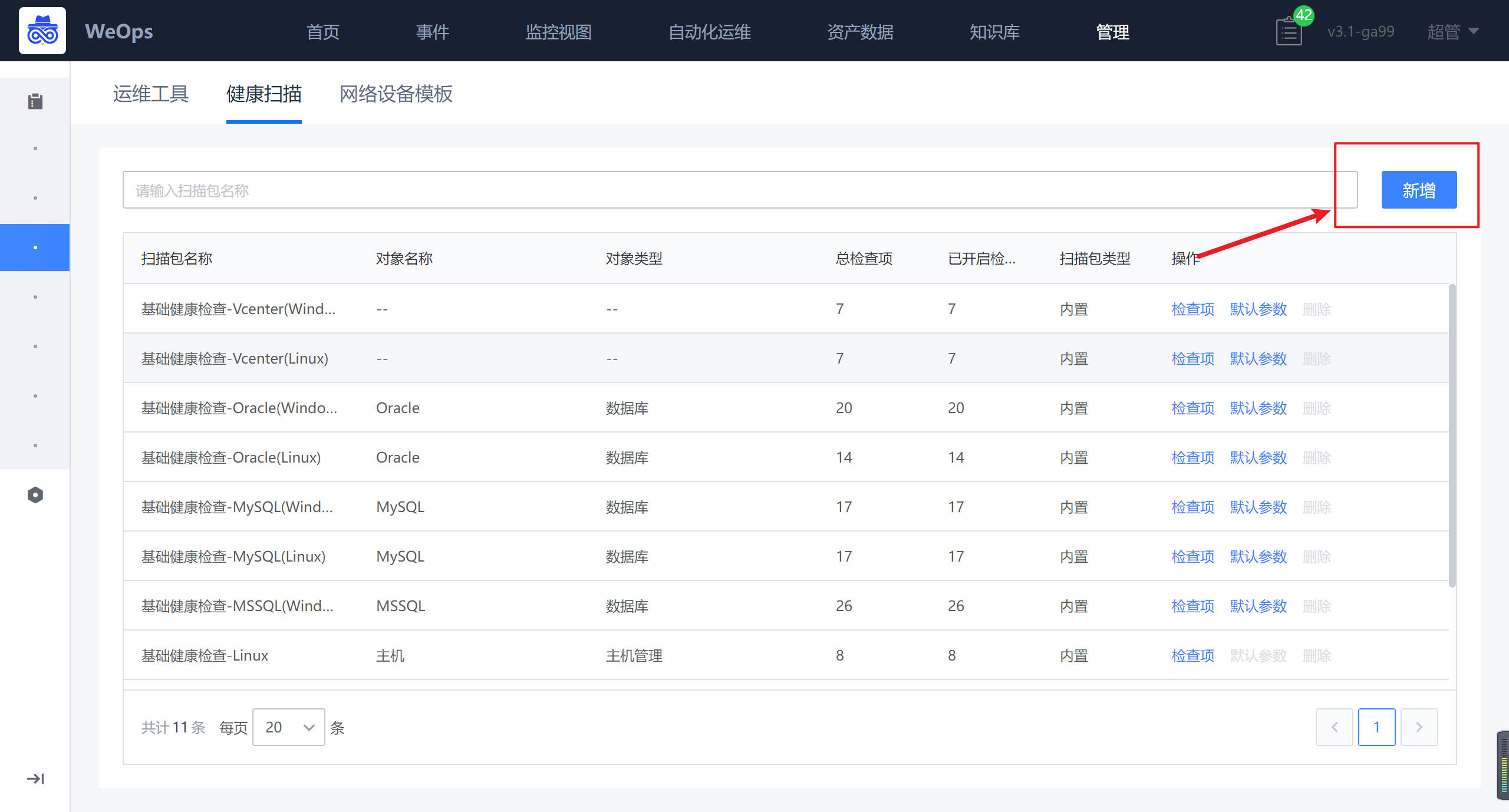
在扫描包新建页面,需要安装模板的.json文件进行导入,模板文件包括扫描包的基本信息(名称/对象类型/对象名称)、检查项采集脚本、检查项基本信息(名称、阈值、单位、解释说明、治愈建议等)。导入完成后,可以在“健康扫描”界面使用该扫描包进行资源的健康扫描。
进行扫描包设置
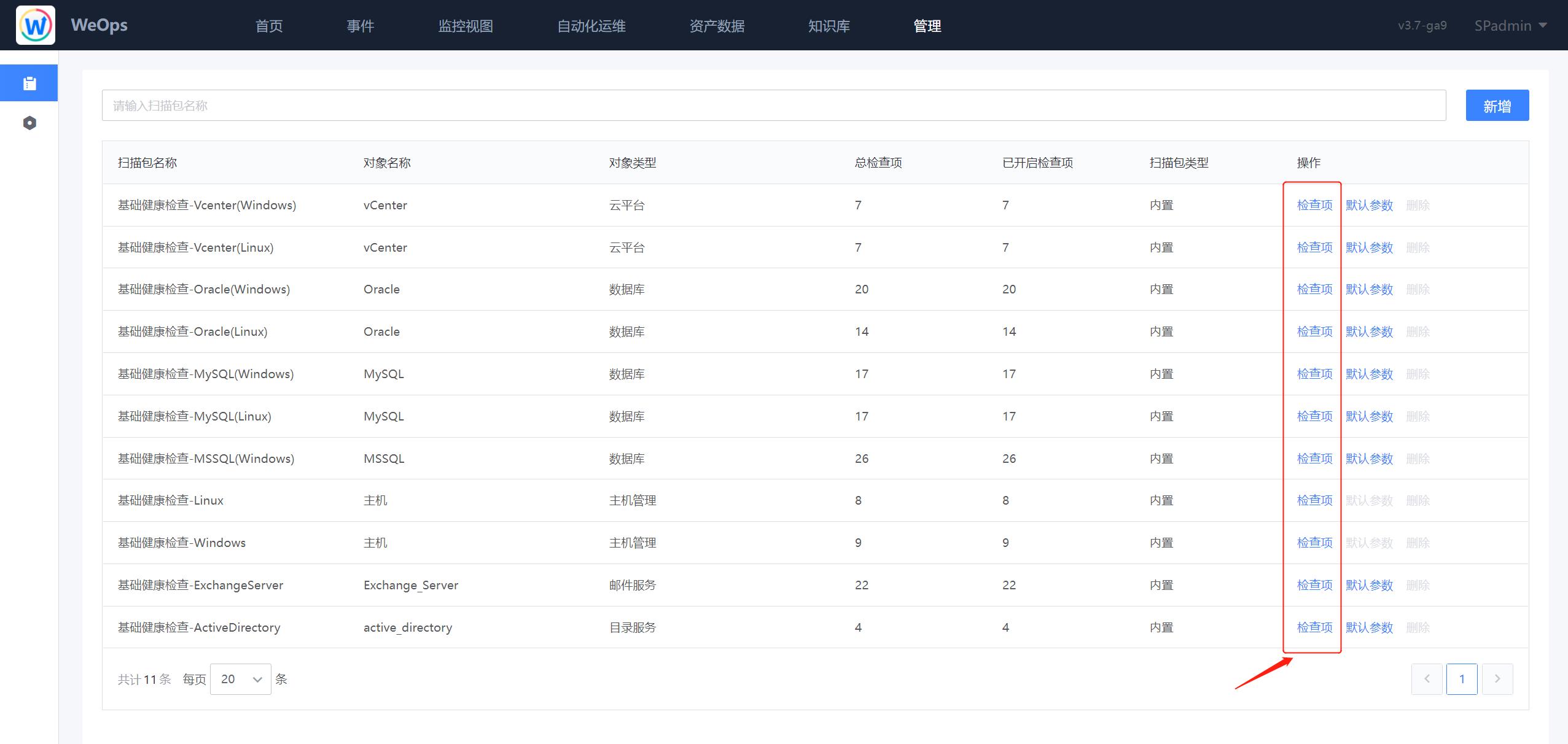
路径:管理-管理中心-扫描包管理
在“扫描包管理”界面,点击“检查项”按钮,可以进行检查项的设置。
在检查项的设置界面,可以进行检查项部分信息的重新编辑,包括阈值、指标介绍、治愈建议,也可以进行检查项的启停,对于不使用的检查项可以进行关闭。

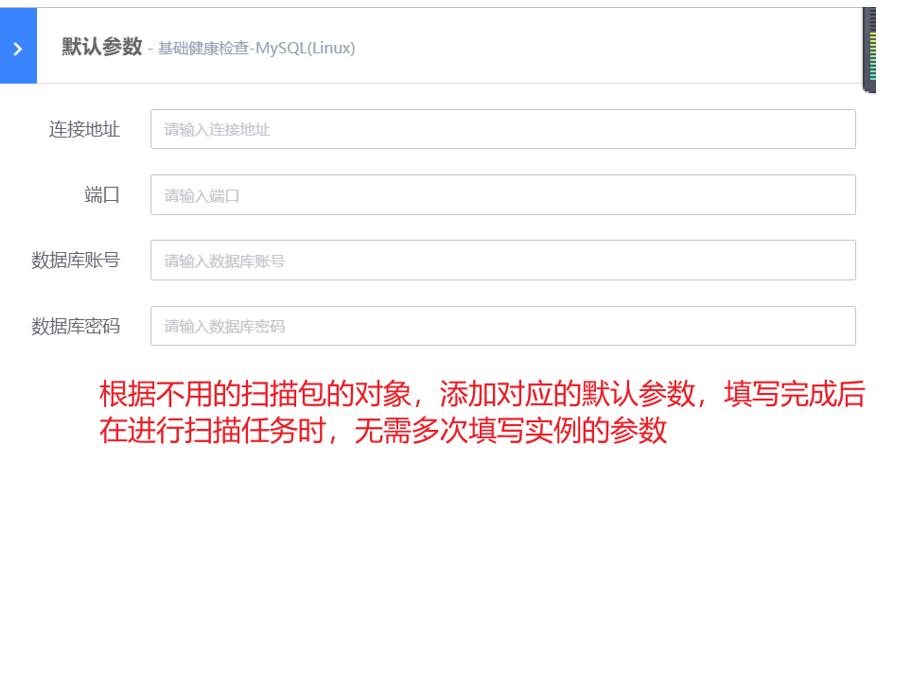
在“扫描包管理”界面,点击“默认参数”按钮,可以进行默认参数的设置,设置成功后,在使用该扫描包时,对应实例的参数凭据无需再次输入。
- 扫描包设置成功后,即可在自动化运维-健康扫描中使用
3.3 资源模型配置
背景介绍:内置的资源模型不满足公司对于资源纳管的需求,需要增加新的资源模型,并配置该资源模型与其他模型之间的关联关系。
整体步骤:新建模型分组——新建模型——设置模型字段和关联关系——模型使用
新建模型分组
路径:管理-管理中心-资产模型管理
- 点击在“资源模型管理”界面点击“新建分组”按钮,在新建抽屉中填写分组的中英文名称即可,内置分组不允许修改和删除,自创分组允许修改中文名称和删除


新建模型
路径:管理-管理中心-资产模型管理
- 点击在“资源模型管理”界面点击“新建模型”按钮,在新建界面选择模型图标、模型分组,填写模型的标识和名称。


- 模型新建完成后,将在“WeOps-资产记录/主机/数据库/其他”中展示新建的模型tab
填写模型属性字段和关联关系
路径:管理-管理中心-资产模型管理
模型新建完成后,点击该模型图标,可以进行“属性”和“关联”新建和管理。
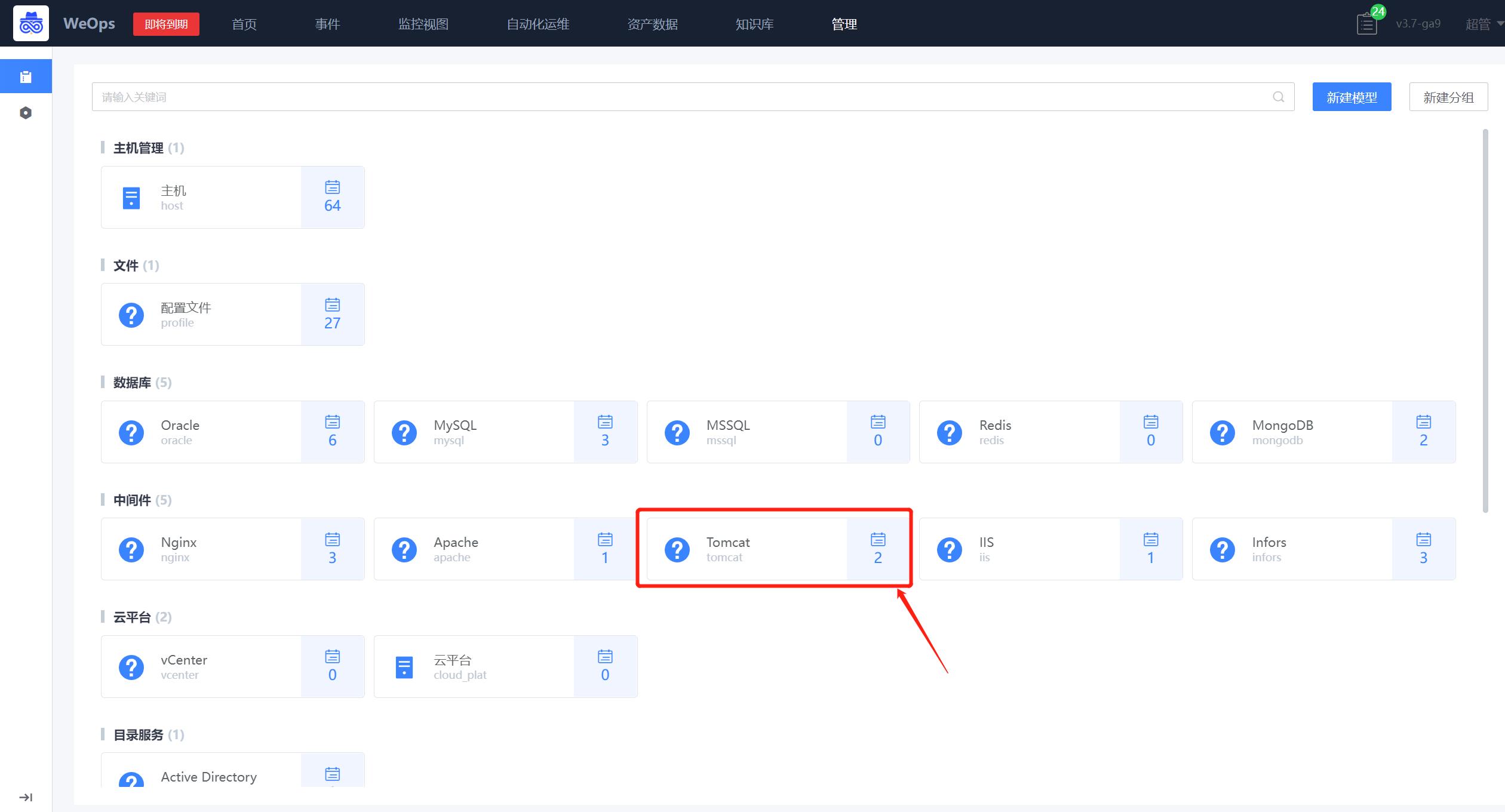
可以进行“属性”字段的新增和编辑,在后续为该模型增加实例时,这些属性字段将作为实例信息字段填写
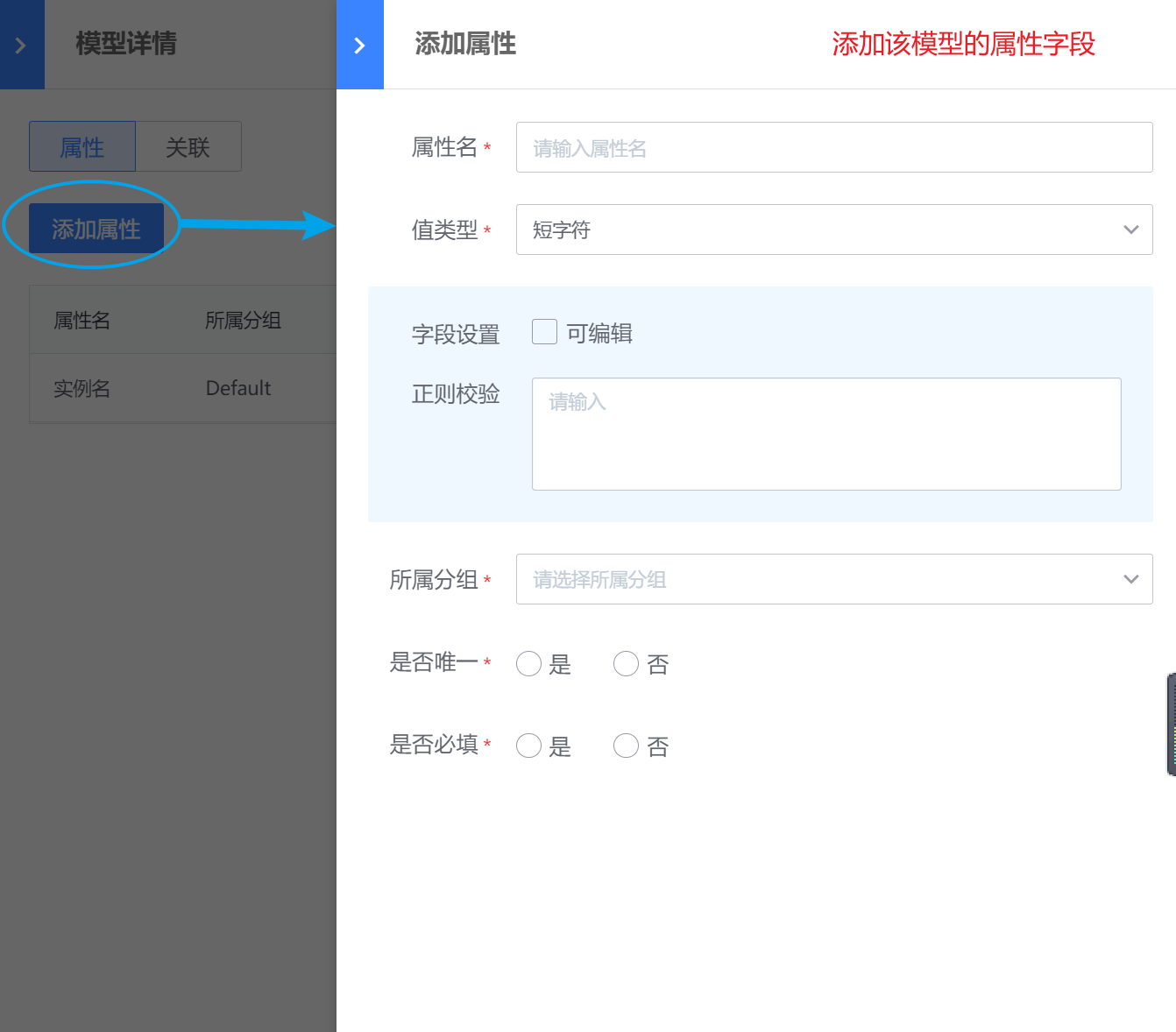
进行“模型关联”模型关联建立后,可以在新建实例后,进行实例的关联建立。

模型的使用
路径:资产数据-资产记录-对应模块
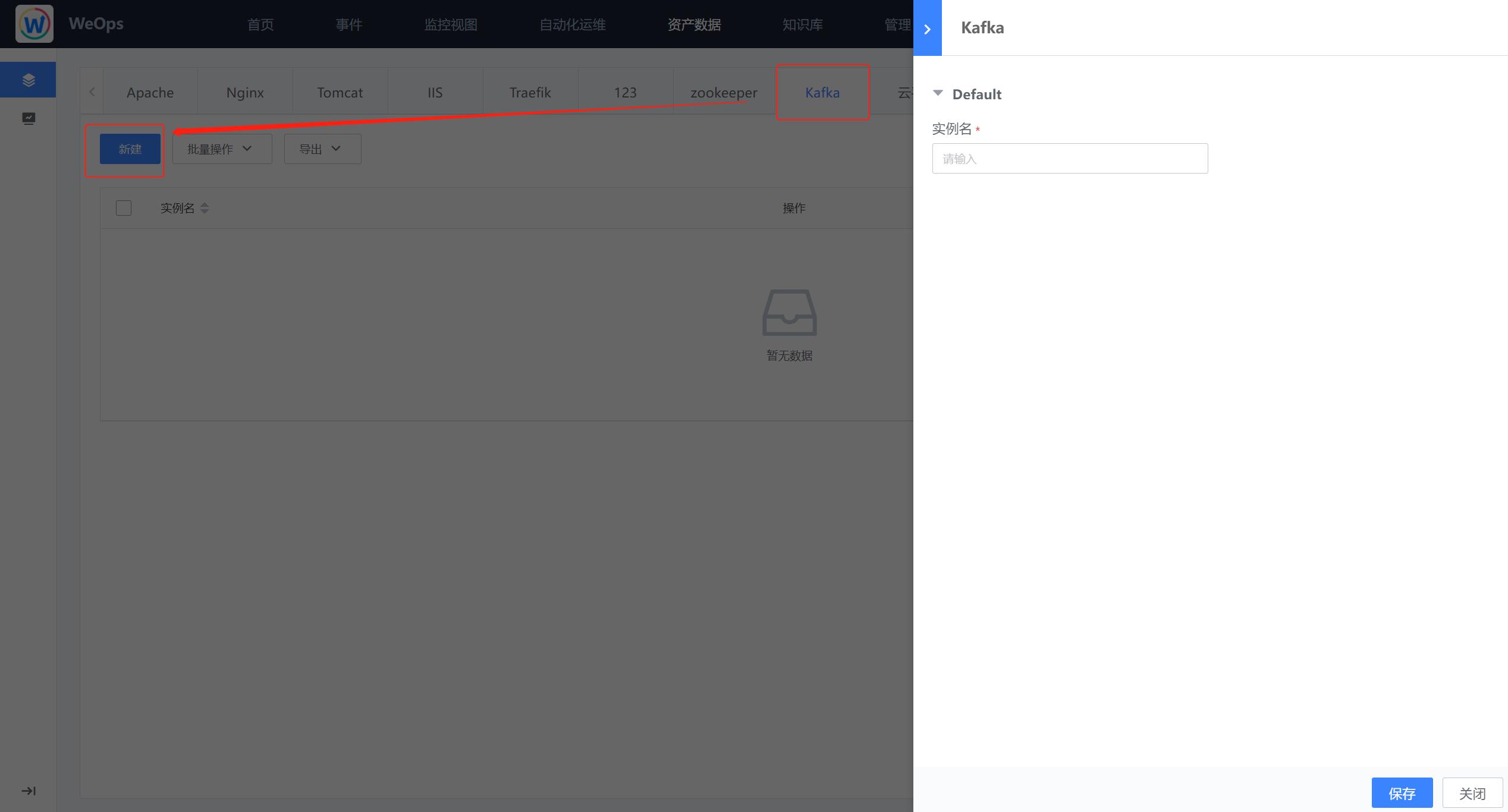
- 在资产记录中,找到新建的模型tab,点击“新建”按钮,可以进行实例的新增,这里需要填写的字段信息是在“资产模型管理-属性”中建立的属性字段。
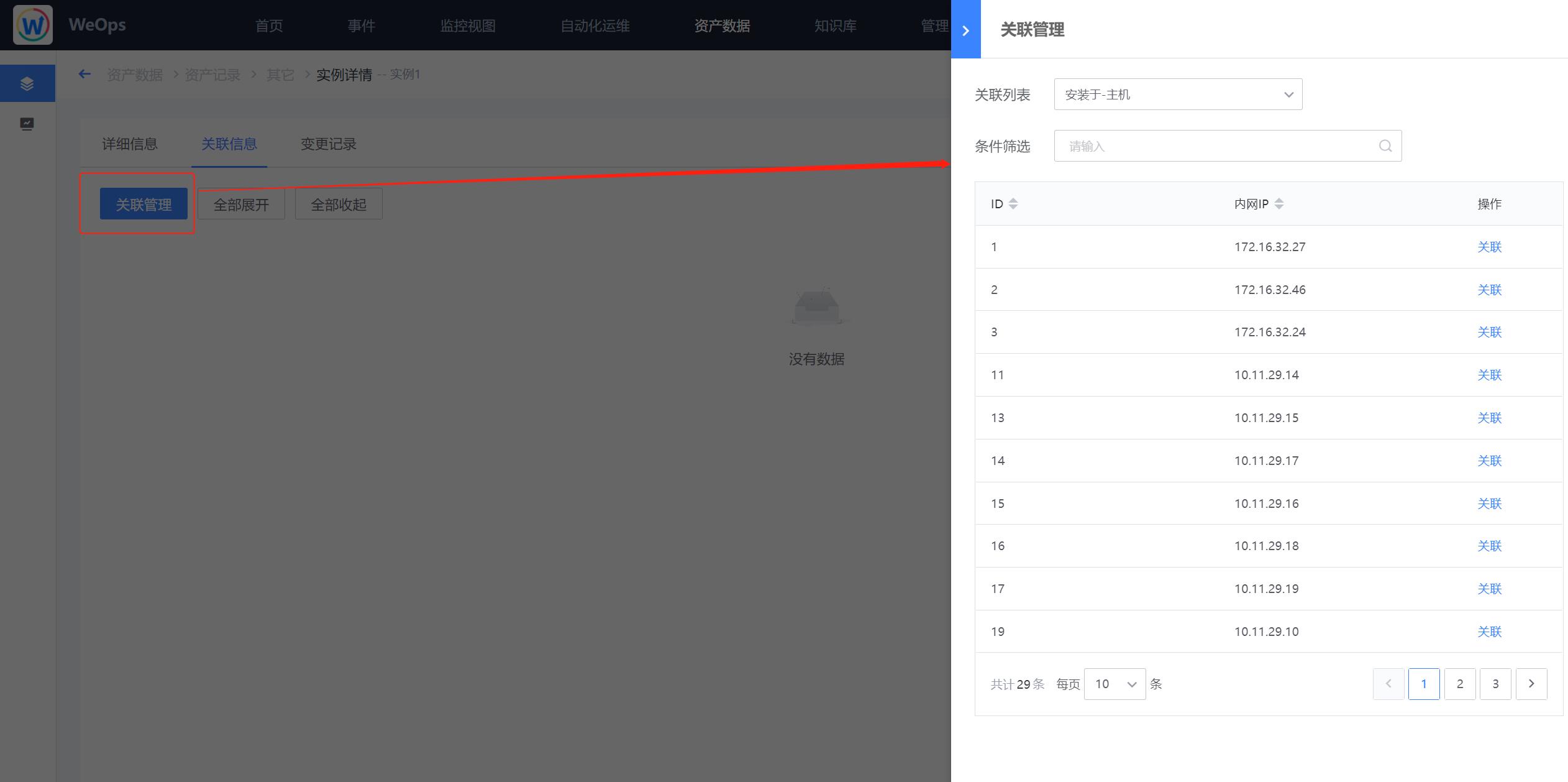
- 在实例新建完成后,点击“查看”按钮,进入到实例的详情页,在“关联管理”中可以进行该实例与其他模型实例的关联关系的新建,这里可选择实例其他模型实例的关联关系与“资产模型管理-关联”中模型之间的关联关系一致。
3.4 知识库配置
背景介绍:对知识库文章的标签进行管理,若需要重复撰写同类文章通过新建文章模型的形式实现。
整体步骤:管理标签——管理模板
管理标签
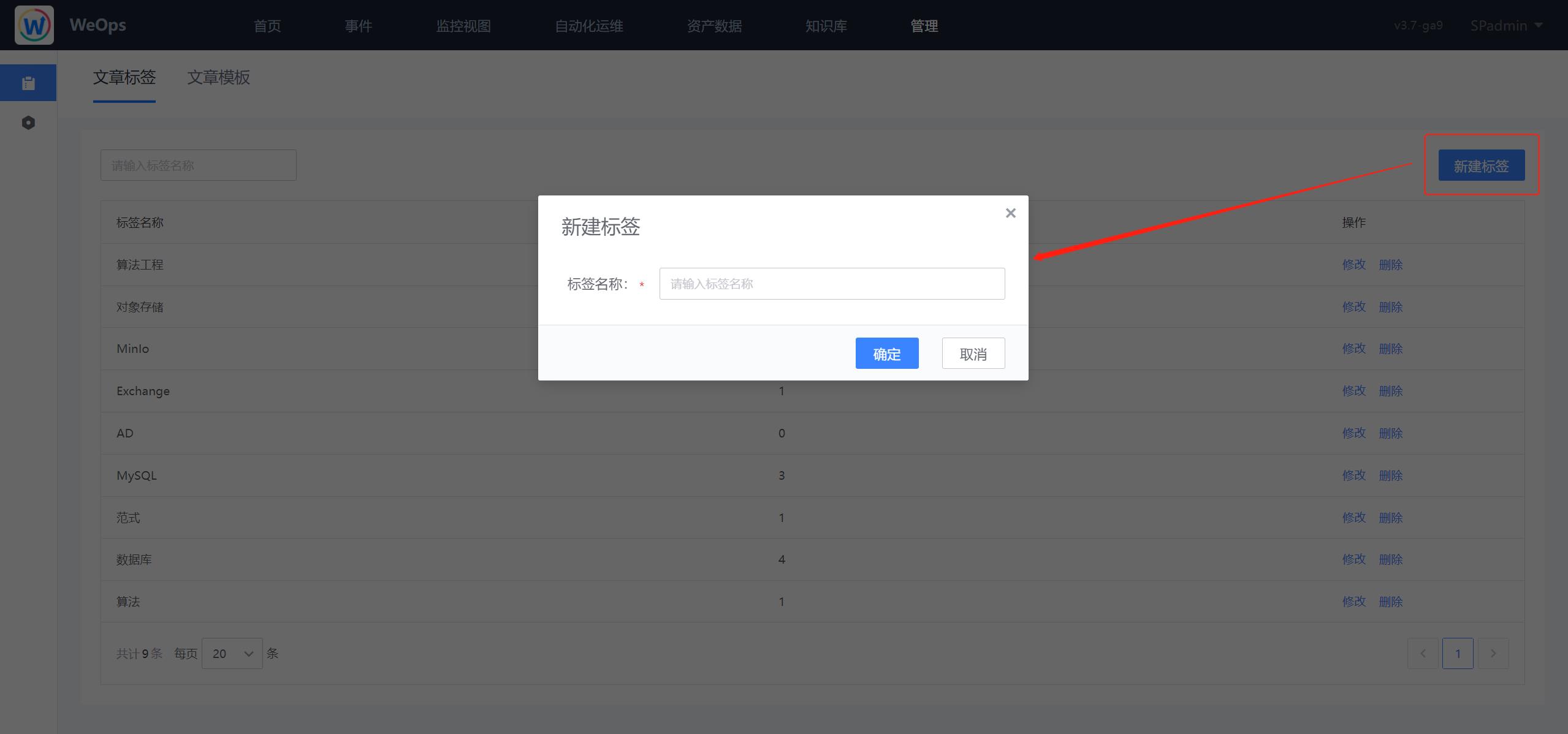
路径:管理-管理中心-知识库管理-文章标签
- 在“知识库管理”中可以对标签进行新增/编辑/修改,也可以查看各类标签的引用情况。知识库所有的标签可被文章撰写/模板撰写所引用。
管理模板
路径:管理-管理中心-知识库管理-文章模板
- 在“知识库管理”中可以对模板进行新增/编辑/修改,知识库所有新建的模板可以在“写文章”时被使用。
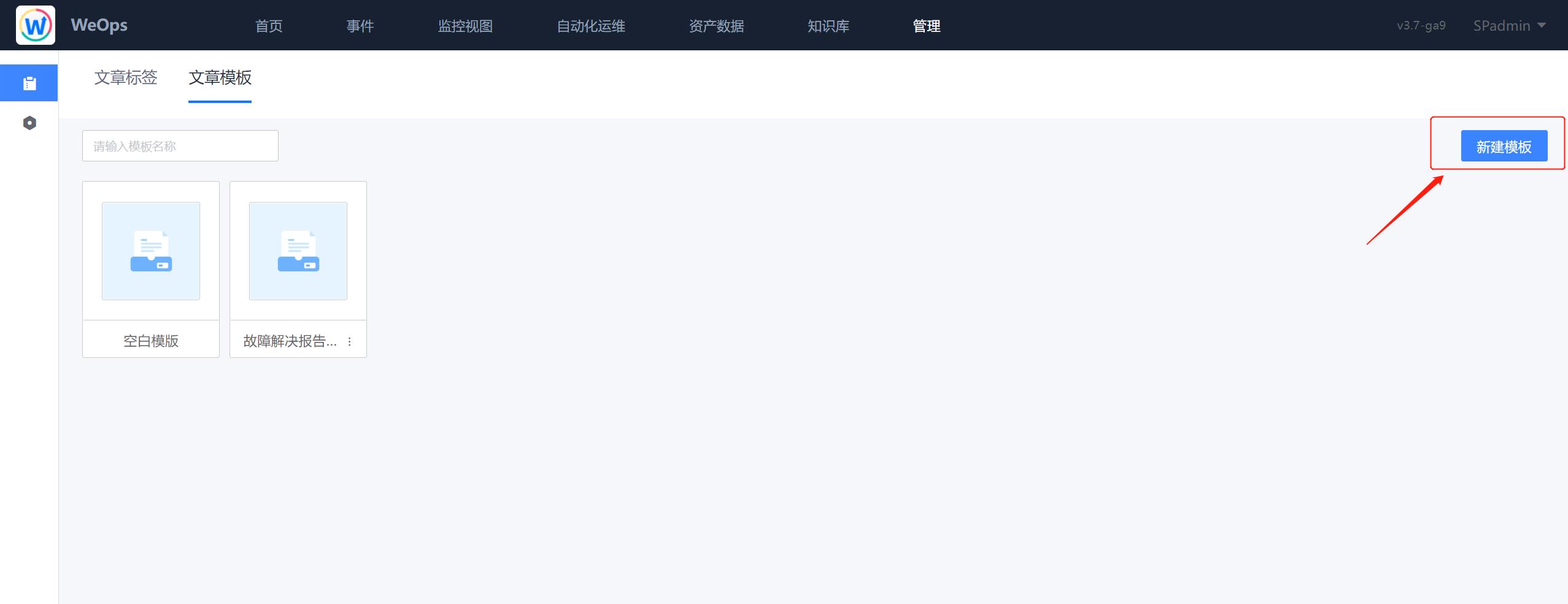
- 点击“新建模板”可以进行模板的创建,创建模板的时候可以上传图片作为模板封面。

3.5 服务台-服务流程配置
背景介绍:为了贴合客户使用场景,在IT服务台中增加常用流程,需要在后台进行服务流程的表单和流程节点的配置。
整体步骤:服务目录配置——流程配置(流程信息-配置流程-启用配置)——服务配置——SLA设置(服务模式-服务协议-服务使用)——服务台提单
服务目录配置
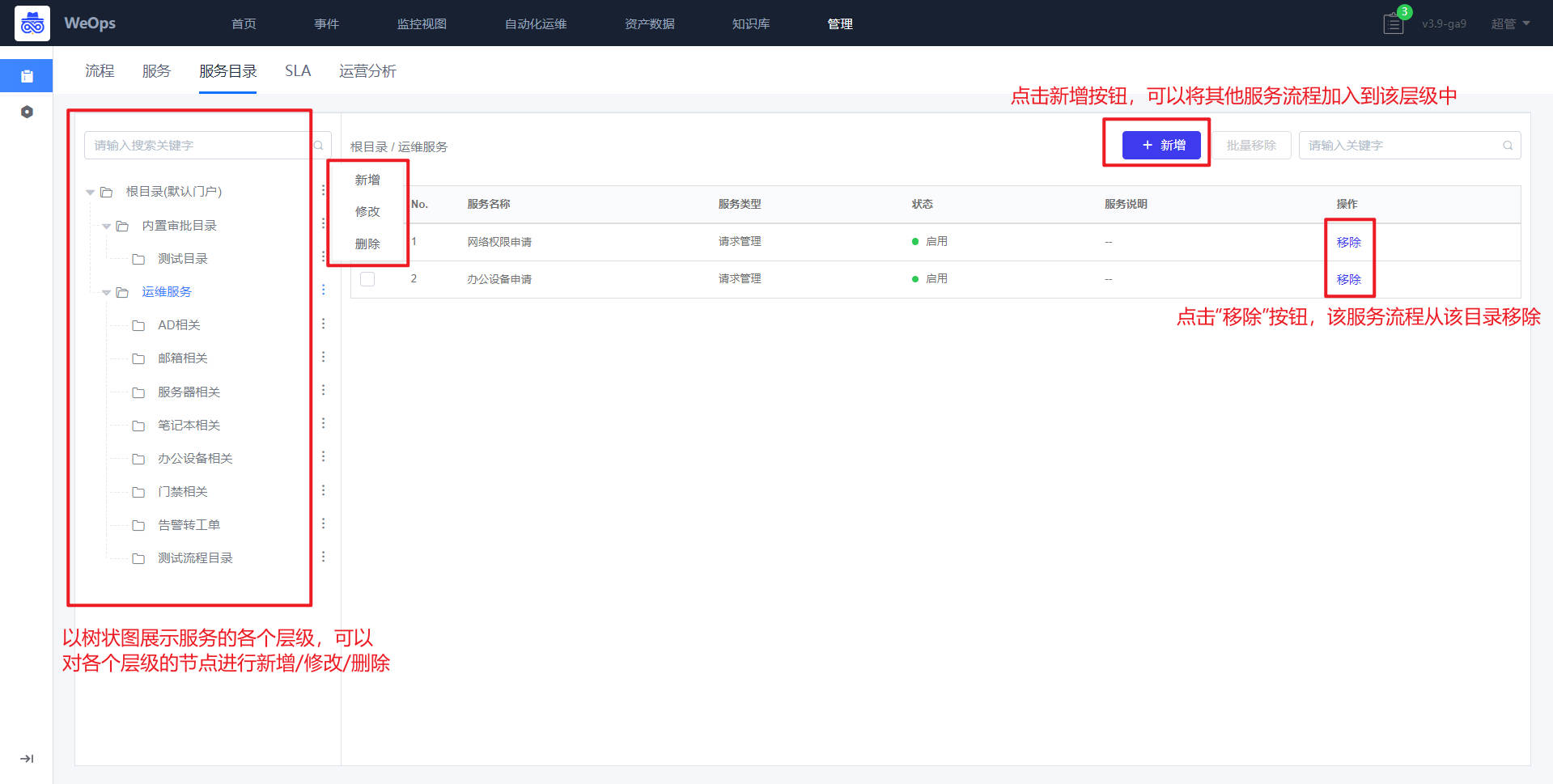
路径:管理-管理中心-服务台管理-服务目录
如下图,服务目录为整体服务内容的管理视图及入口。可对服务目录进行新增,编辑,删除,排序等操作。当服务目录下有子目录时,父级目录将无法删除。将子目录删除后方可删除。
在“服务台管理-服务目录中”可以新建各个层级的服务目录,在各个层级中可以新增服务流程,
在服务目录中可将现有服务流程移除,服务的移除仅代表从该服务目录移除,并不会删除服务。从该服务目录移除后,用户在IT服务台提单时,选择原服务目录后,将看不到被移除的服务。
流程配置
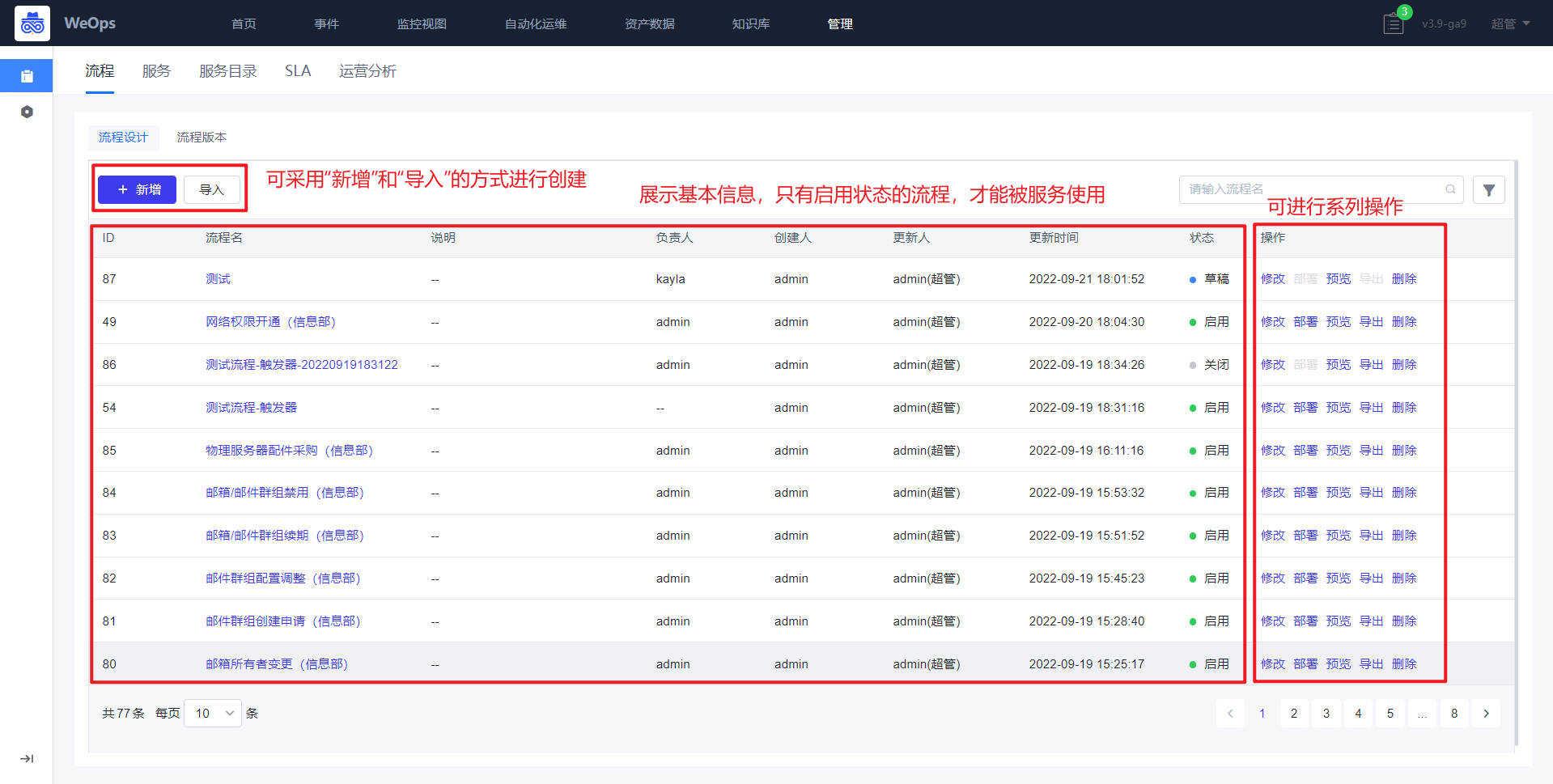
路径:管理-管理中心-服务台管理-流程
流程分为流程设计和流程版本,流程新建完成部署后会形成一个流程版本,以后每修改一次流程并部署都会形成一个版本
“流程设计”的列表页展示了所有服务流程的基本信息和状态,可进行新增和删除等操作。
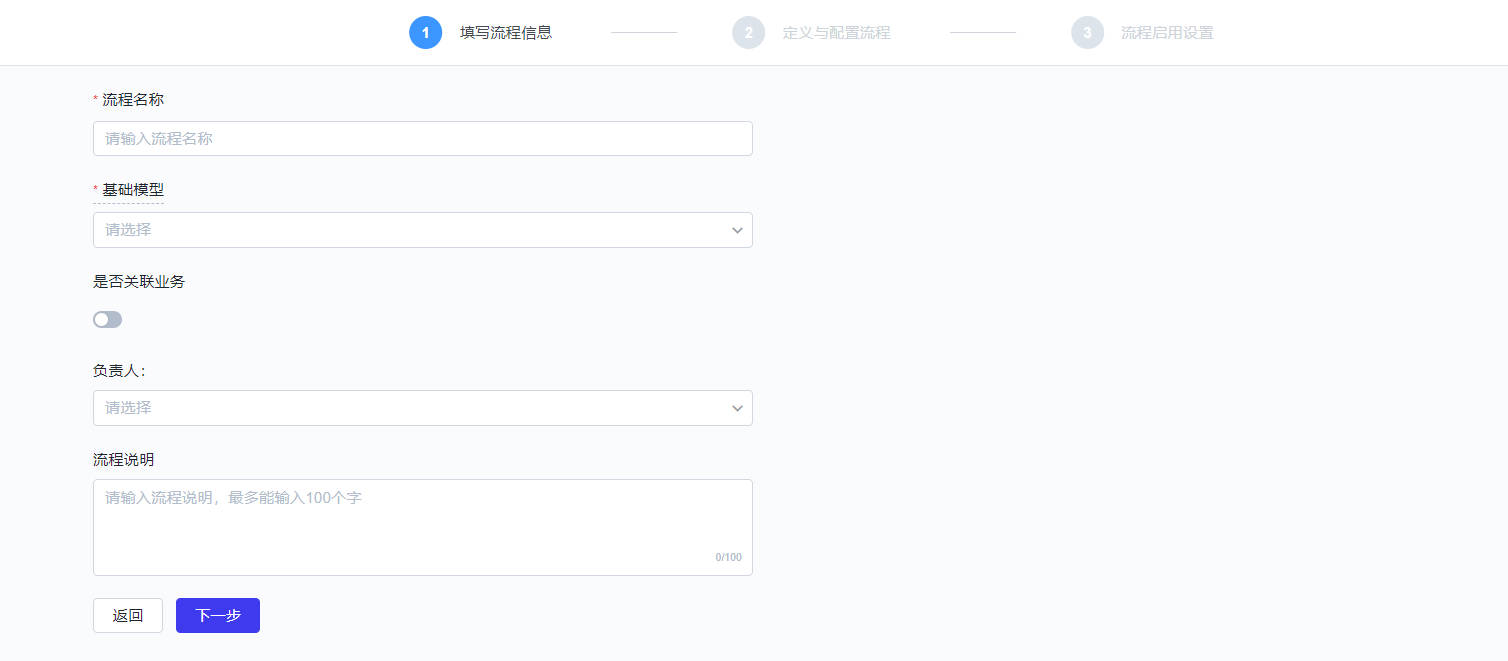
服务流程的配置步骤一般分为三步,分别为:填写流程信息、配置流程和启用配置。
步骤一:填写流程信息
填写流程的基础信息,包括:名称、基础模型(可使用内置的模型)、是否关联业务、负责人和流程说明等
- 步骤二:配置流程
当填写完成基本流程信息,会进入到流程节点的定义和配置步骤。该部分可以自行决定整体流程的长短,增删节点,节点类型,以及设置每个节点的字段信息。每个流程的默认起点环节为“提单”。
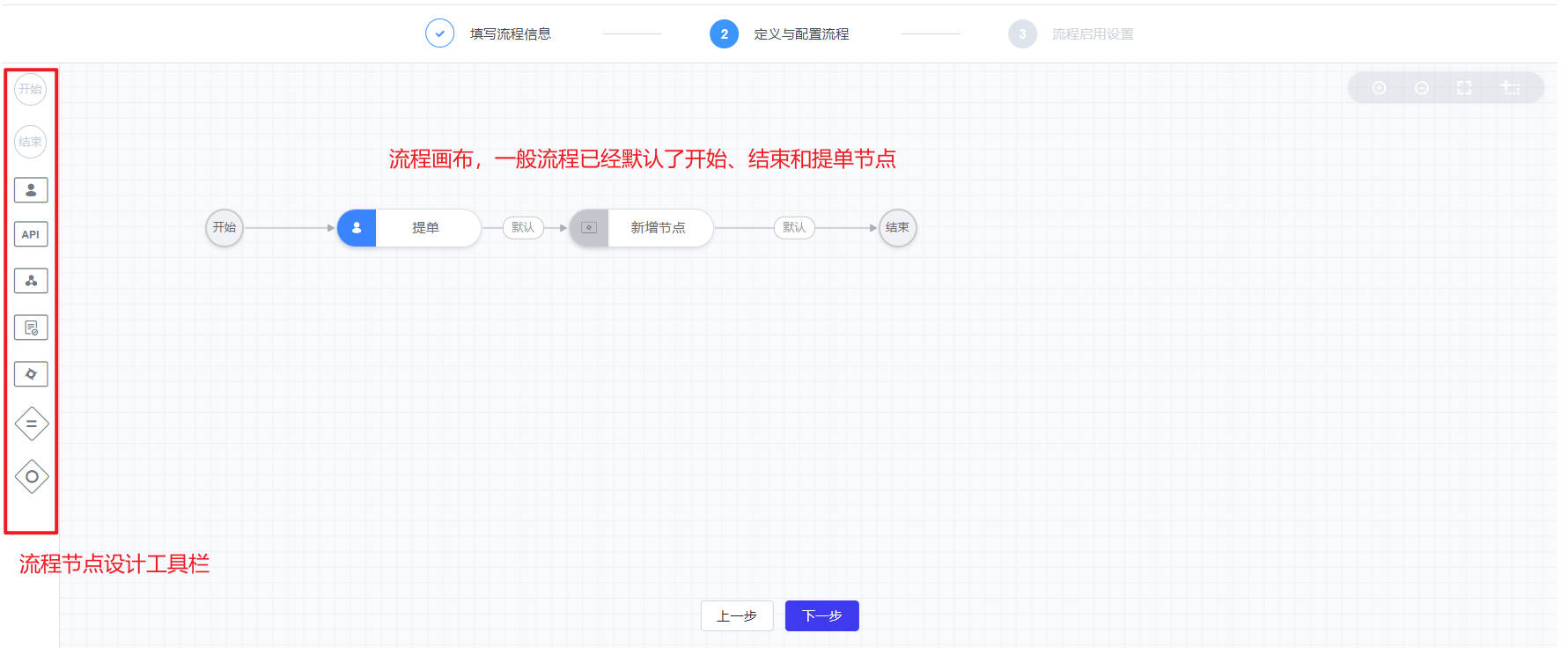
目前节点类型分为:手动节点,API 节点,会签节点,标准运维节点。
* 手动节点:该节点为人工手动进行处理反馈。
* API 节点:该节点为 API 自动处理节点。
* 会签节点:需要多人同时完成同一个处理环节。支持达到一定完成率后可以提前结束进行流转的设置。
* 审批节点:审批动作节点。内置审批内容和审批方式,可配置但无法修改。
* 标准运维节点:可调用蓝鲸平台中标准运维中的公共流程。
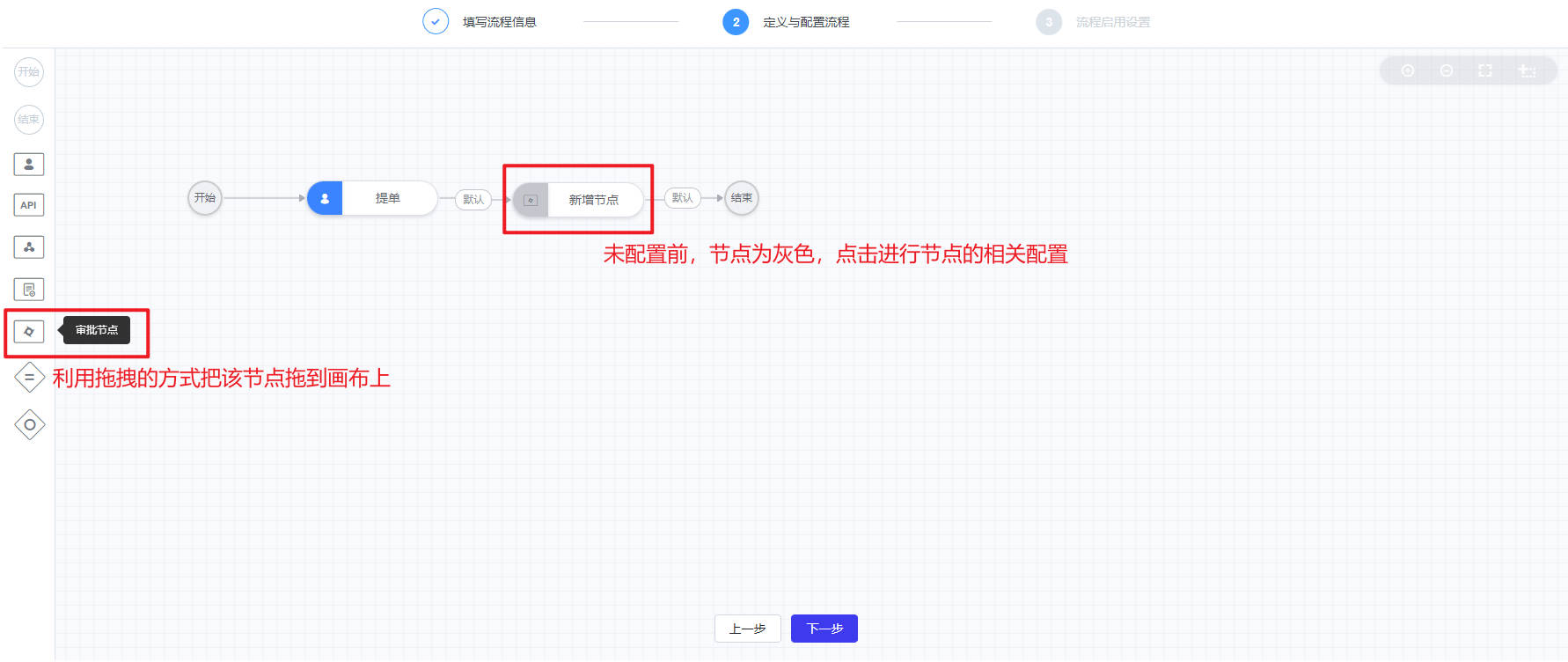
这里重点讲解“提单”(手动节点)和“审批节点”两类节点
首先是“提单”节点,每个流程默认都以“提单节点”开始,点击提单节点,进去到该节点的配置页面,各项选择和配置详见下图。
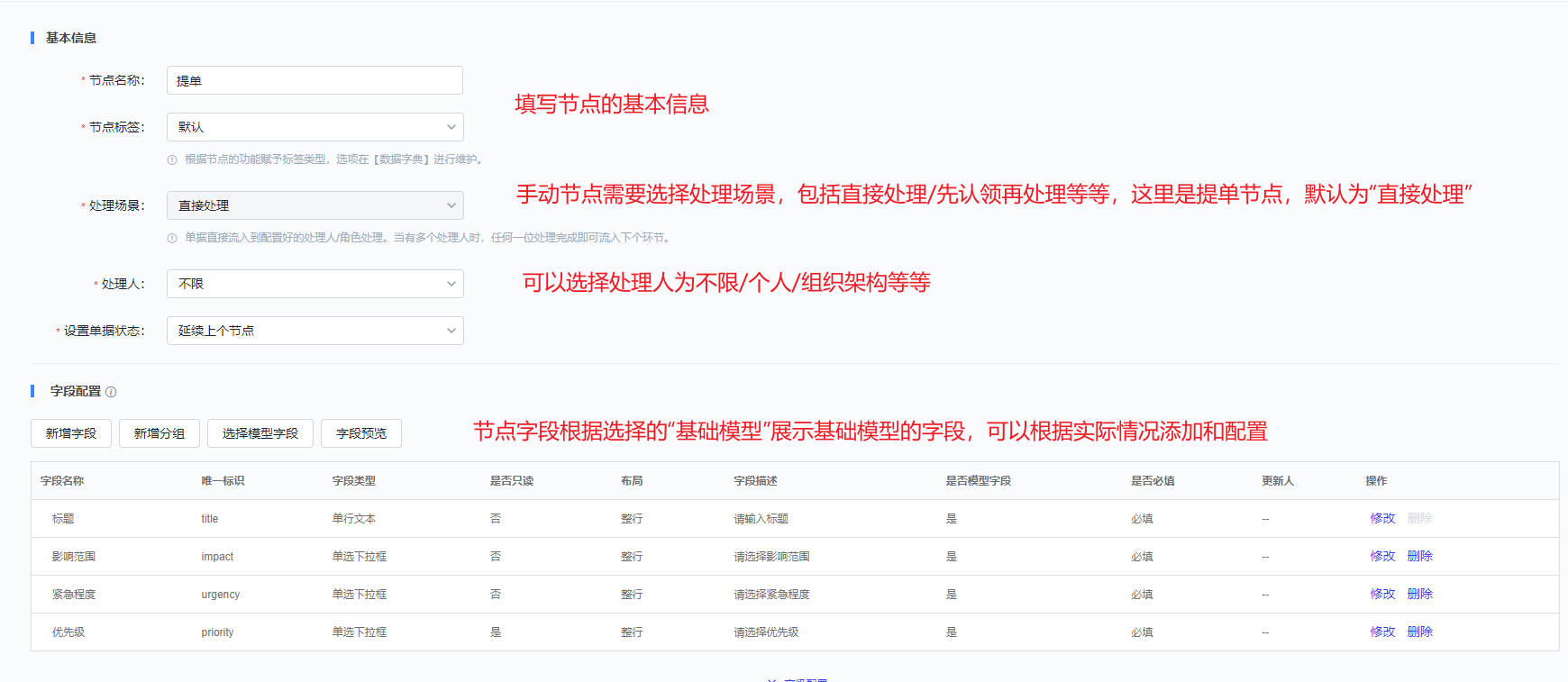
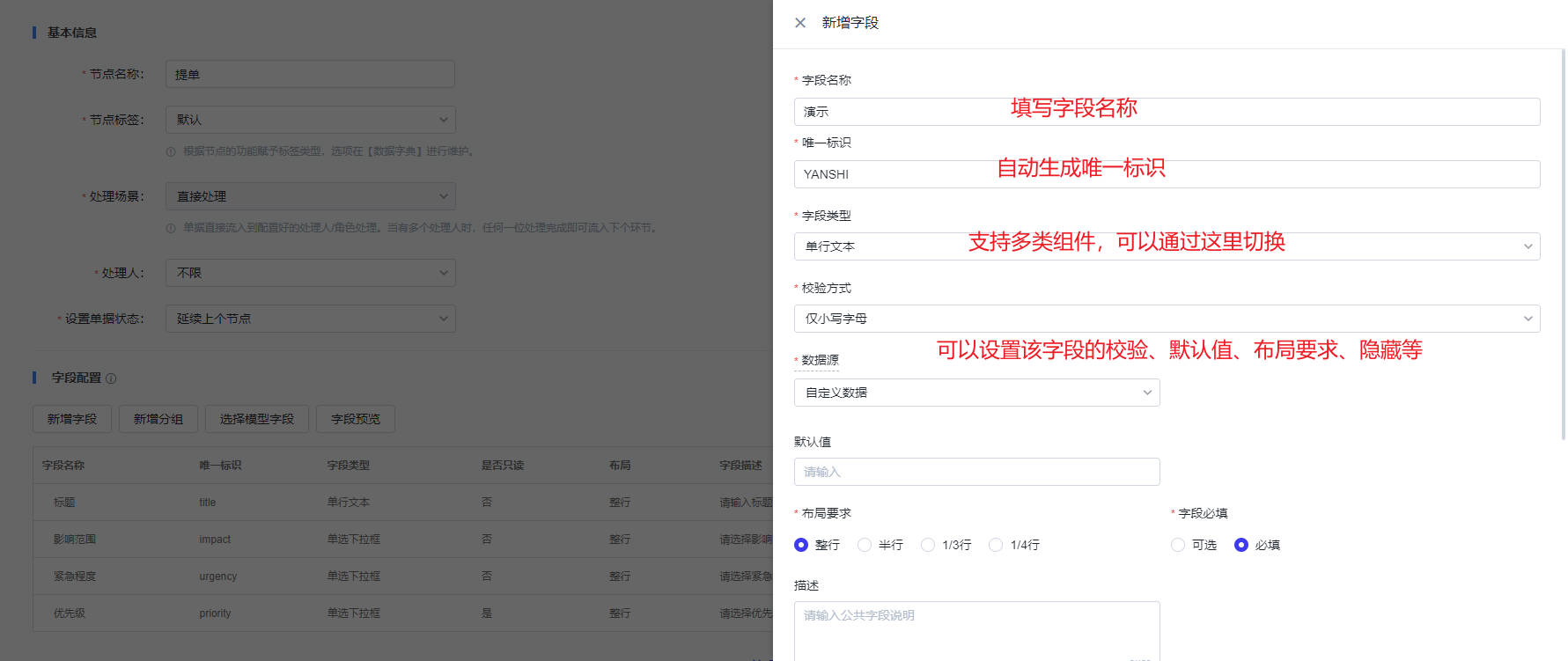
- 关于字段的配置,点击“新增字段”,填写字段名称,自动生成唯一标识,字段支持多类组件,可以通过“字段类型”切换,这里以“单行文本”为例,点击单行文本,可以对该字段进行字段名称、类型、校验、布局等方面的设置,设置成功后,增按照设置在表单的对应位置进行展示。
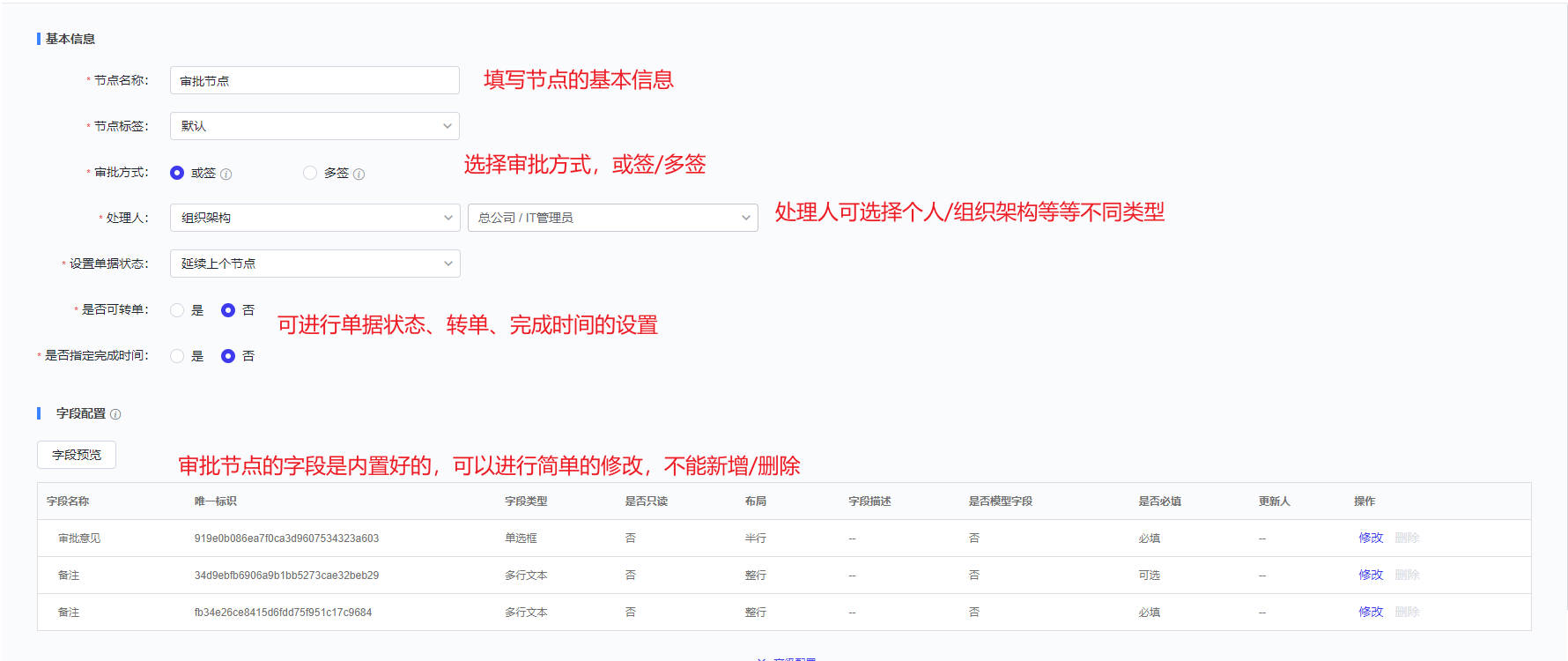
- 再者是“审批节点”,在节点工具栏中选择“审批节点”并拖至画布上,点击该节点,进行节点的配置。在“审批节点”的配置页面,可以进行该节点名称、标签、处理人、是否可以转单等方面的配置。
- 步骤三:高级配置
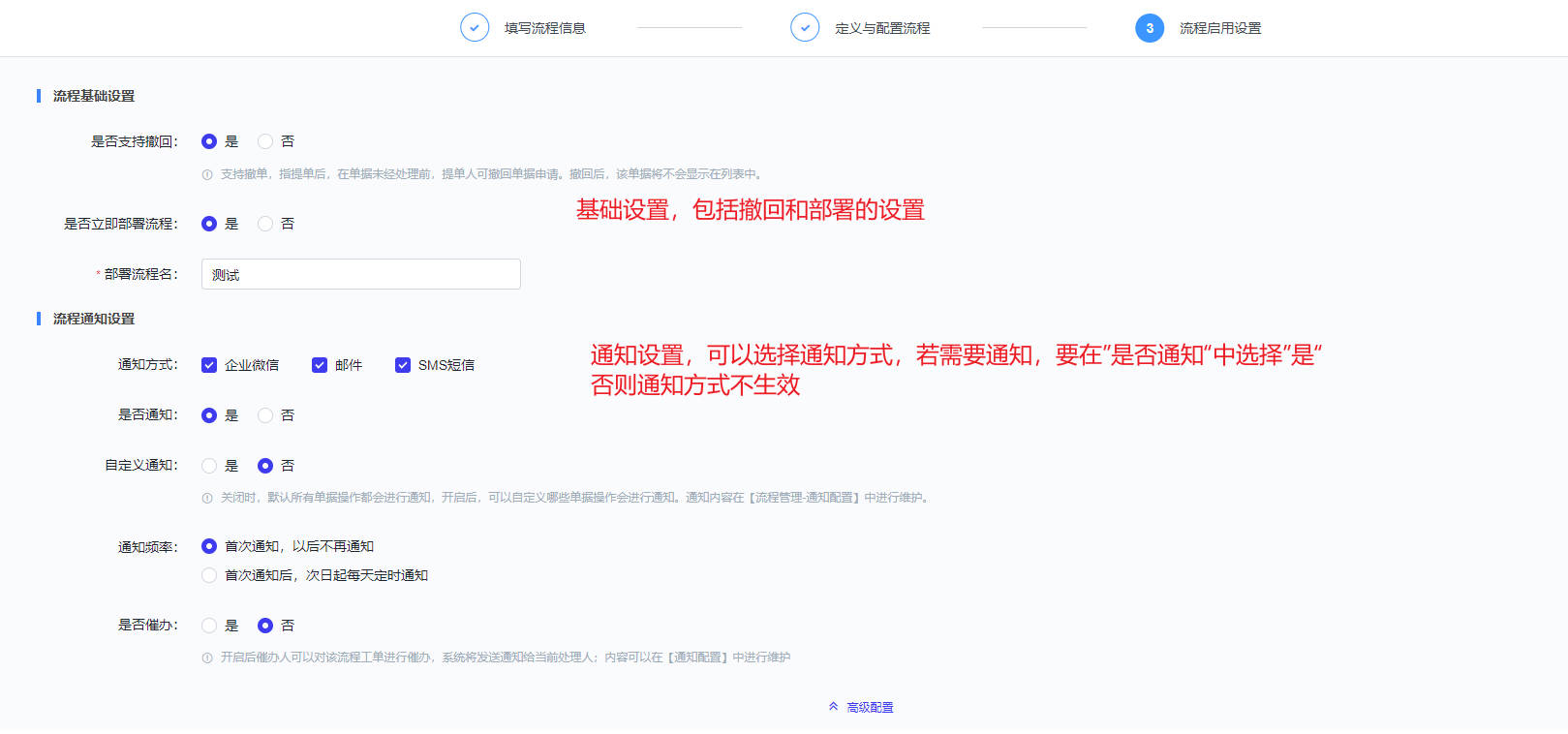
当服务表单和服务流程配置完成后,最后一步为高级高级配置,可设置基础设置、通知方式等。
服务配置
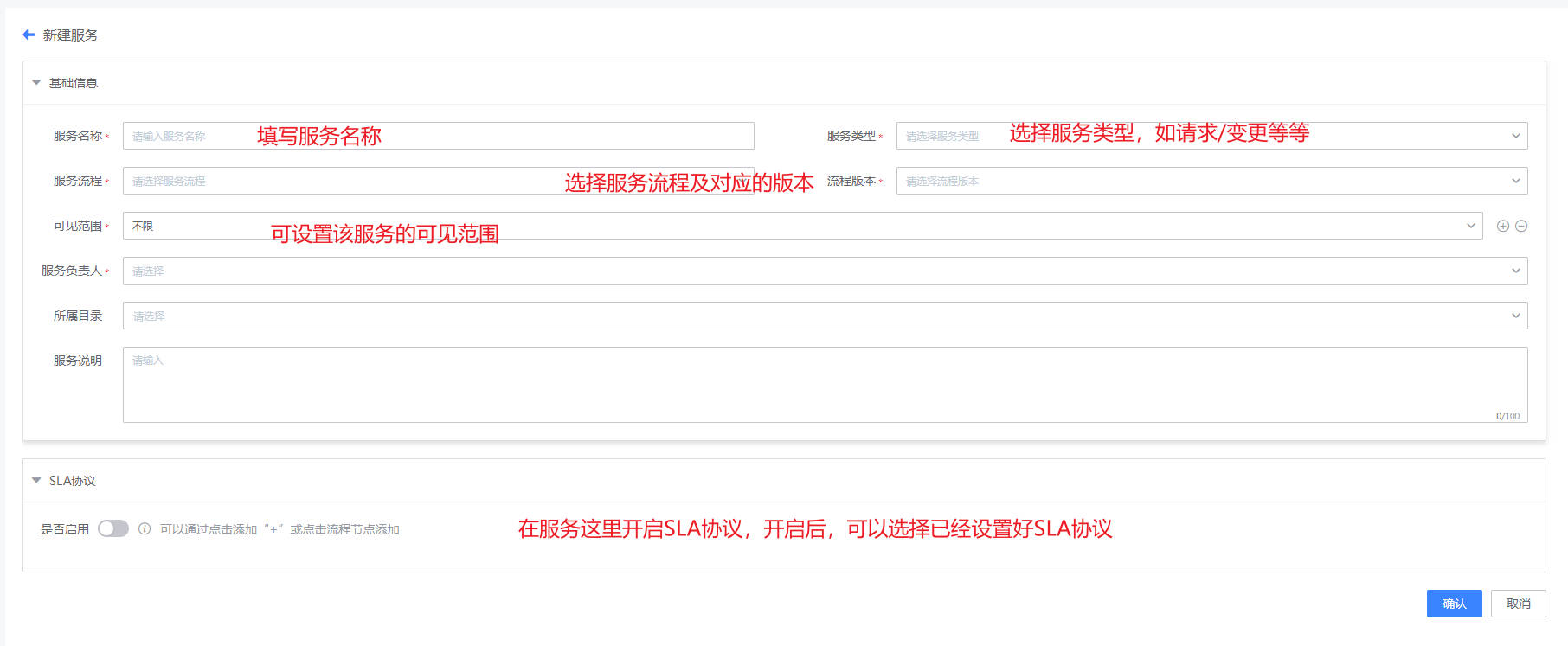
路径:管理-管理中心-服务台管理-服务
- 流程配置部署好后,需要新建服务并与之关联,才能够提单。如下图,在服务列表页,点击“新增”按钮,进入到新增页面。
SLA设置
路径:管理-管理中心-服务台管理-SLA
关于SLA设置和使用共分为三步:设置服务模式-设置服务协议-服务流程使用SLA协议
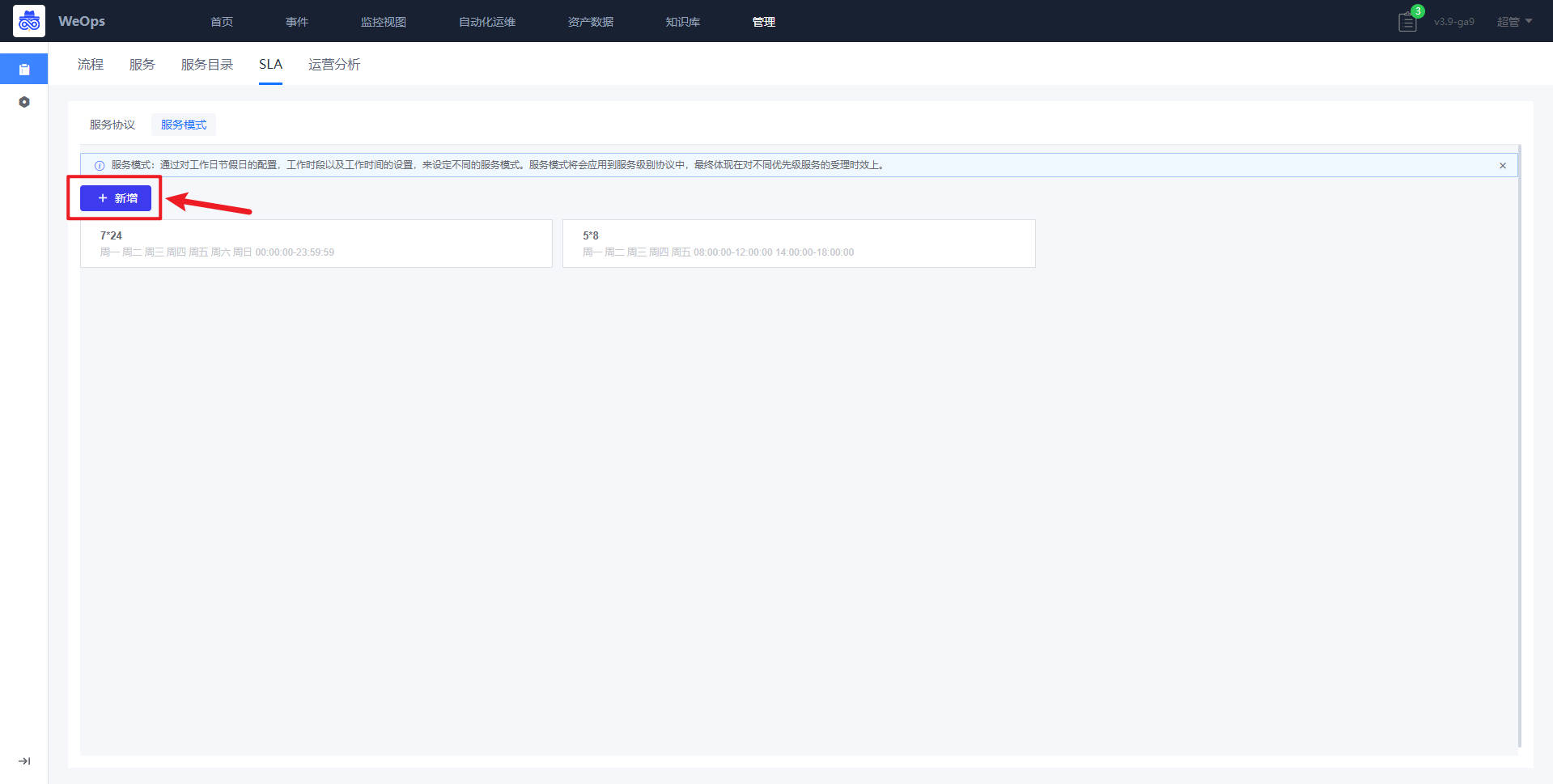
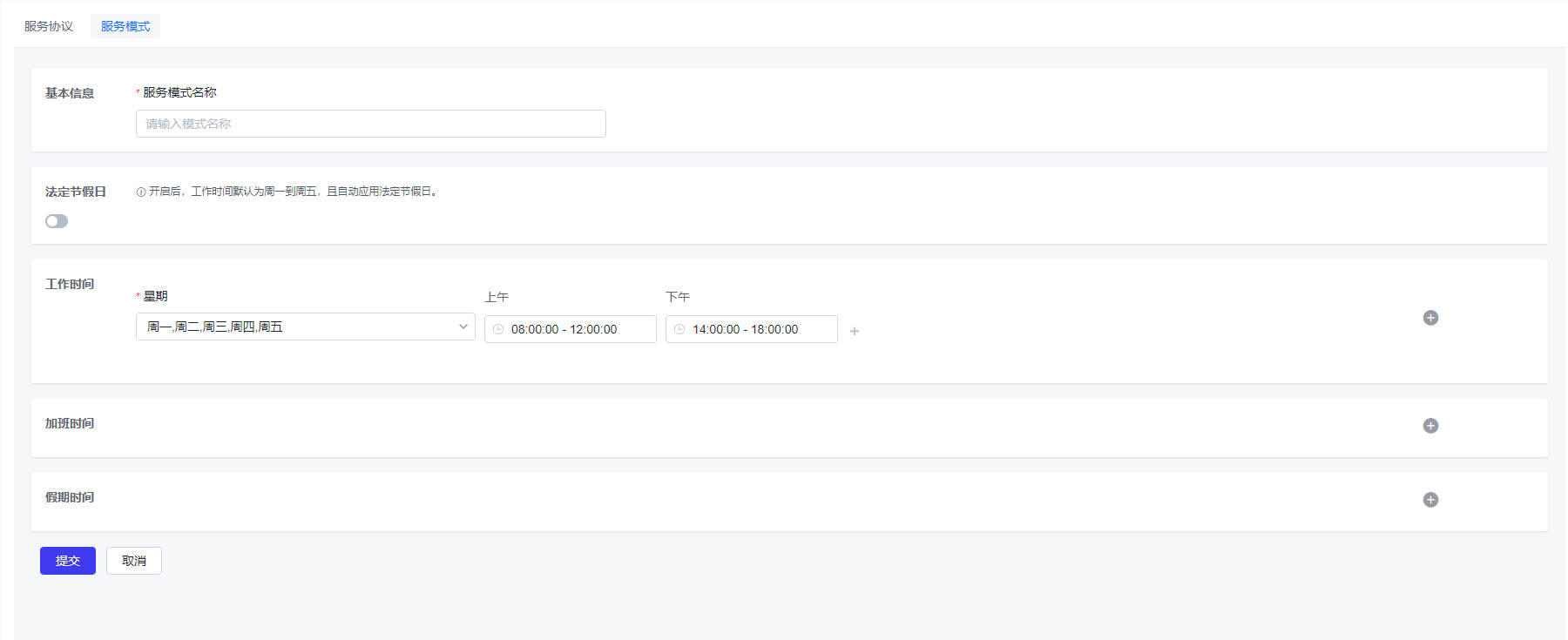
- 步骤一:设置服务模式
通过对工作日,节假日,工作时段的设置,可配置不同的服务时间模板。服务时间将会应用到服务级别协议中,最终体现在对不同服务的受理时效要求上。
- 步骤二:设置服务协议
服务协议是由服务优先级,服务时间,服务解决时长组合配置的的一套或多套服务标准内容,协议启用后,它将可应用到具体的每个服务中。

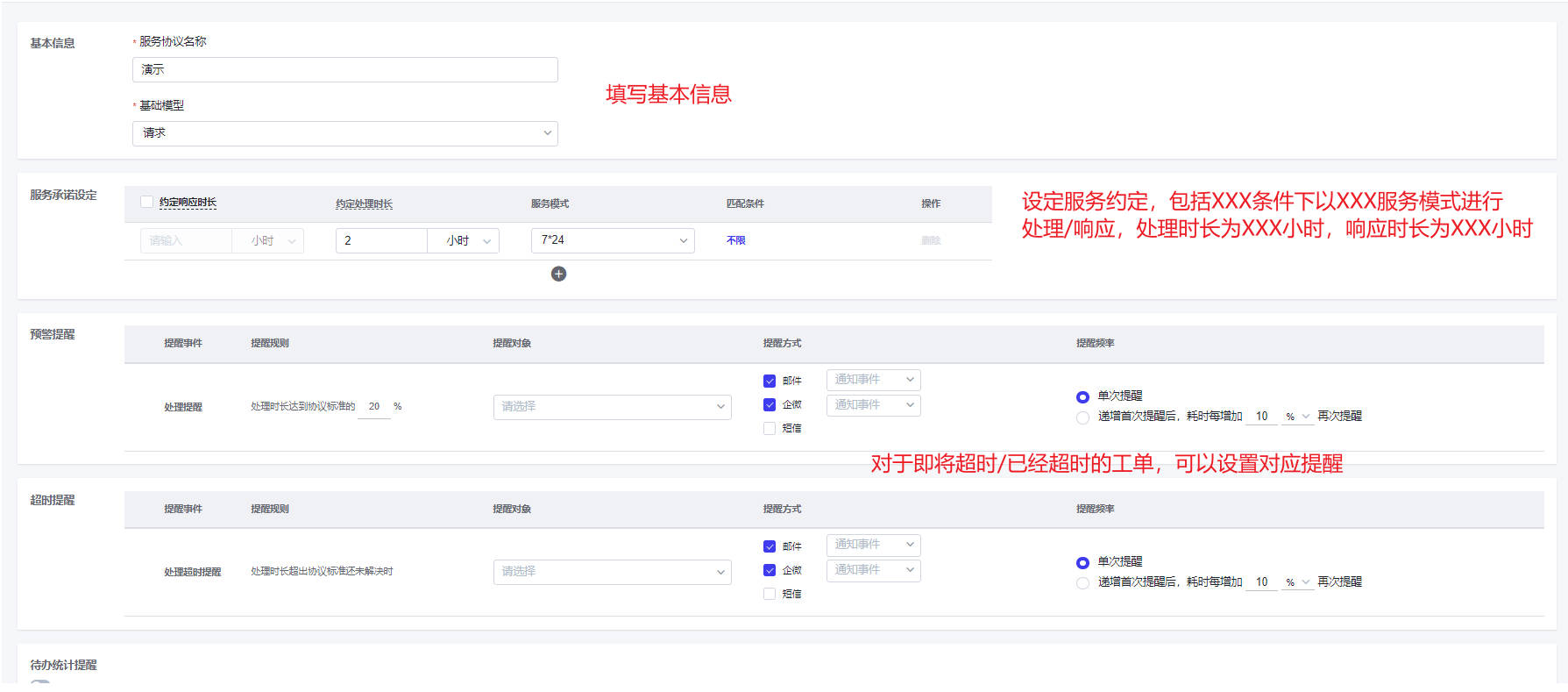
服务协议可设置如下内容:
基本信息:服务协议名称。
服务约定:管理不同优先级下的服务模式,以及解决时长。不同优先级可以设定不同的服务模式。
提醒机制设定:选择是否开启提醒机制以及对应的提醒规则。包括提醒对象,提醒方式,提醒内容(提醒内容可以自定义),提醒频率
是否启用该协议:协议启用开关。开启后,该协议会出现在服务管理中的服务协议下拉框中。
- 步骤三:服务流程使用SLA协议
当服务协议设置完成后,可以在对应服务中选择使用对应的SLA协议

提单
路径:IT服务台/WeOps-事件-工单
- 服务和服务目录创建完成后,可以在IT服务台看到对应的服务目录已经服务目录下的流程。普通用户根据自己的需求在IT服务台中选择对应服务目录下的流程进行提单。
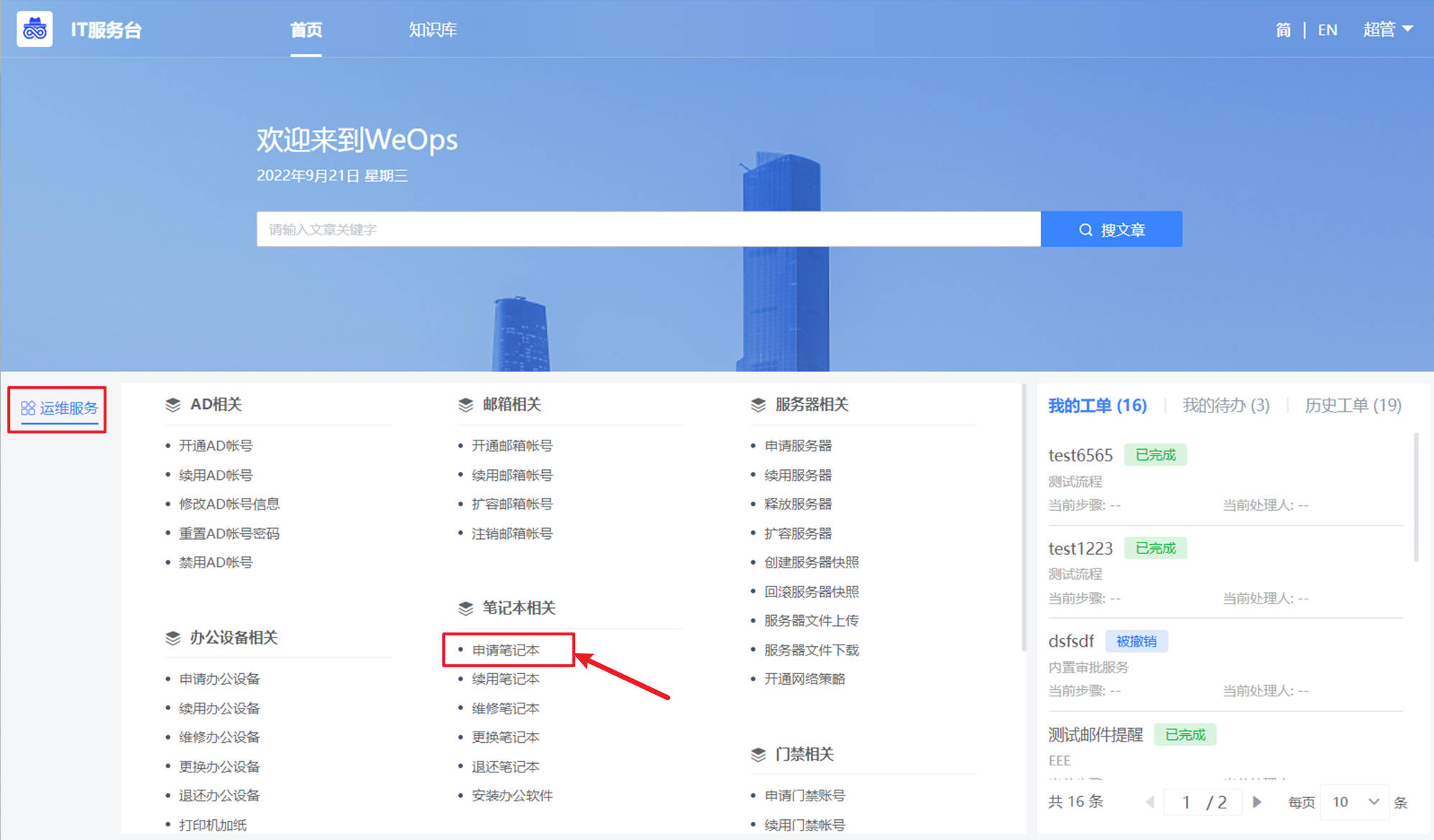
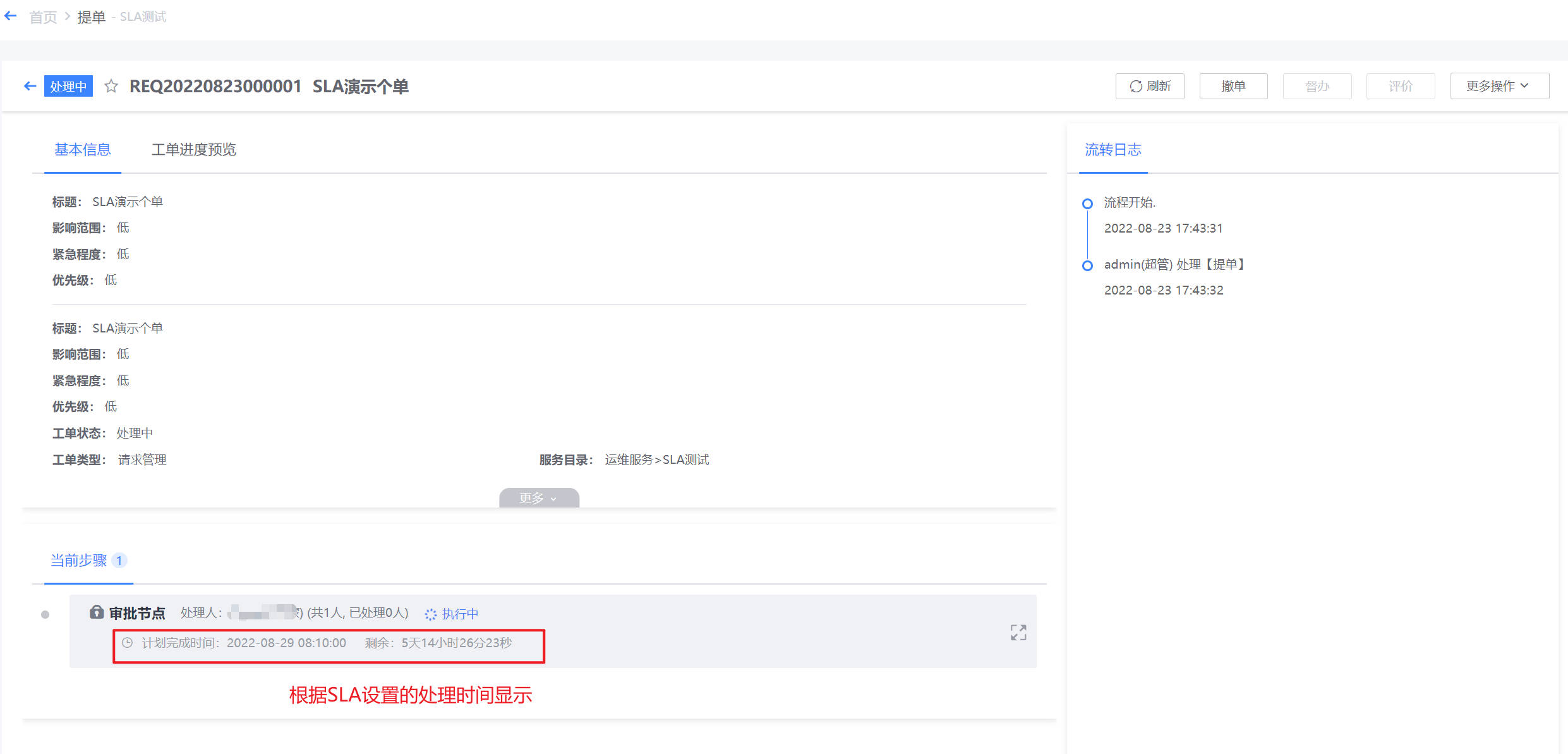
当服务应用某个服务协议之后,该服务下的所有工单将会开启相应的服务标准计时。在单据的详情中可以看到具体的服务时长信息。
3.6 服务台-值班管理配置
背景介绍:为了贴合客户使用场景,可以采用值班的形式,设置不同的值班组对外服务。
整体步骤:供应商管理——值班模式——值班组设置——排班——值班复核,个人可以在“我的值班”查看自己排班和值班的情况,服务流程在设置节点处理人的时候可以选择“值班组成员”
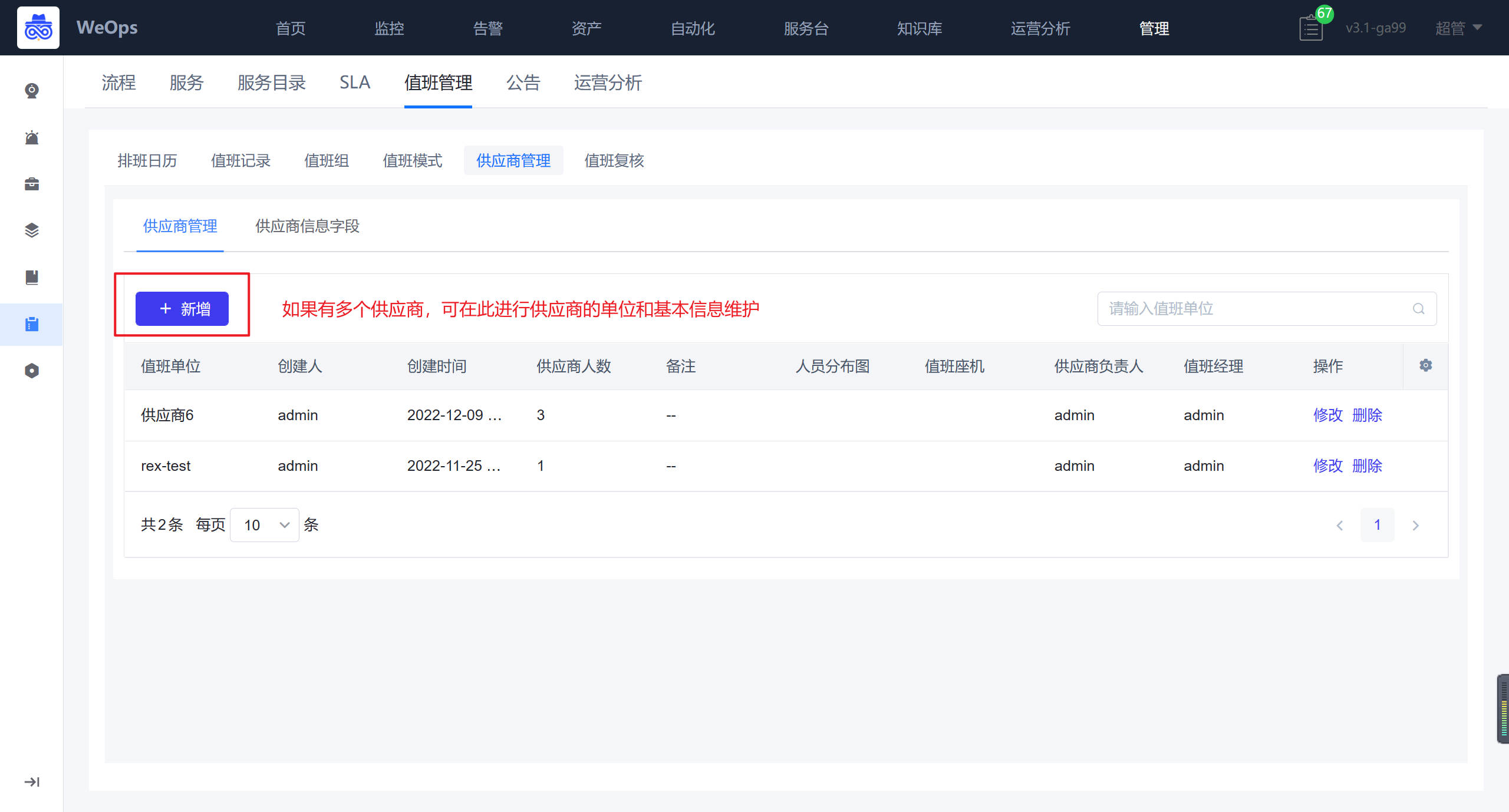
供应商管理
路径:管理-服务台管理-值班管理——供应商管理
在此处管理/维护值班单位的信息和成员,若无其他供应商可以在次维护自己企业的值班成员和信息。
供应商管理:可以维护不同的值班单位,并设置每个值班单位下面的人员以及根据添加的值班单位字段填写每个值班单位相关的信息。
供应商信息字段:若系统本身的值班单位字段不满足要求,可以在此处进行扩展,如:新增人员选择字段“运维负责人”,新增后,值班单位的列表将多一列改字段,所有值班单位均需维护“运维负责人”信息。

值班模式
路径:管理-服务台管理-值班管理——值班模式
相当于排班规则的模板,可设定上班时间、休假时间等。设置完后可在值班组的规则中引用值班模式。当已经绑定值班组的值班模式更新后,用户需要手动在值班组管理中进行更新。

值班组设置
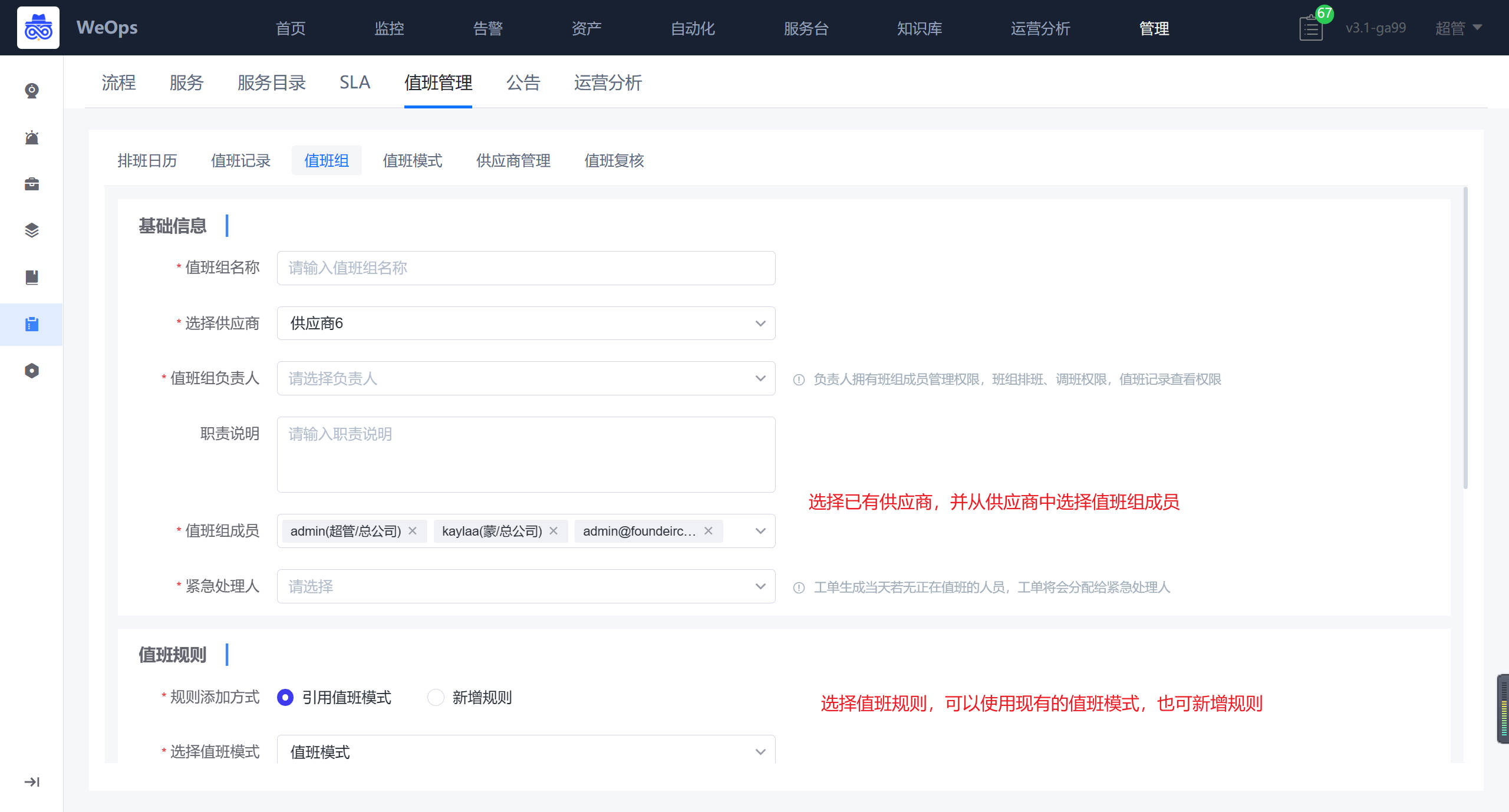
路径:管理-服务台管理-值班管理——值班组设置
点击新增可以配置值班组,值班组人员可以选择供应商中的人员。值班规则可以新增也可以引用值班模式或者新增值班模式。
排班设置
路径:管理-服务台管理-值班管理——排班设置
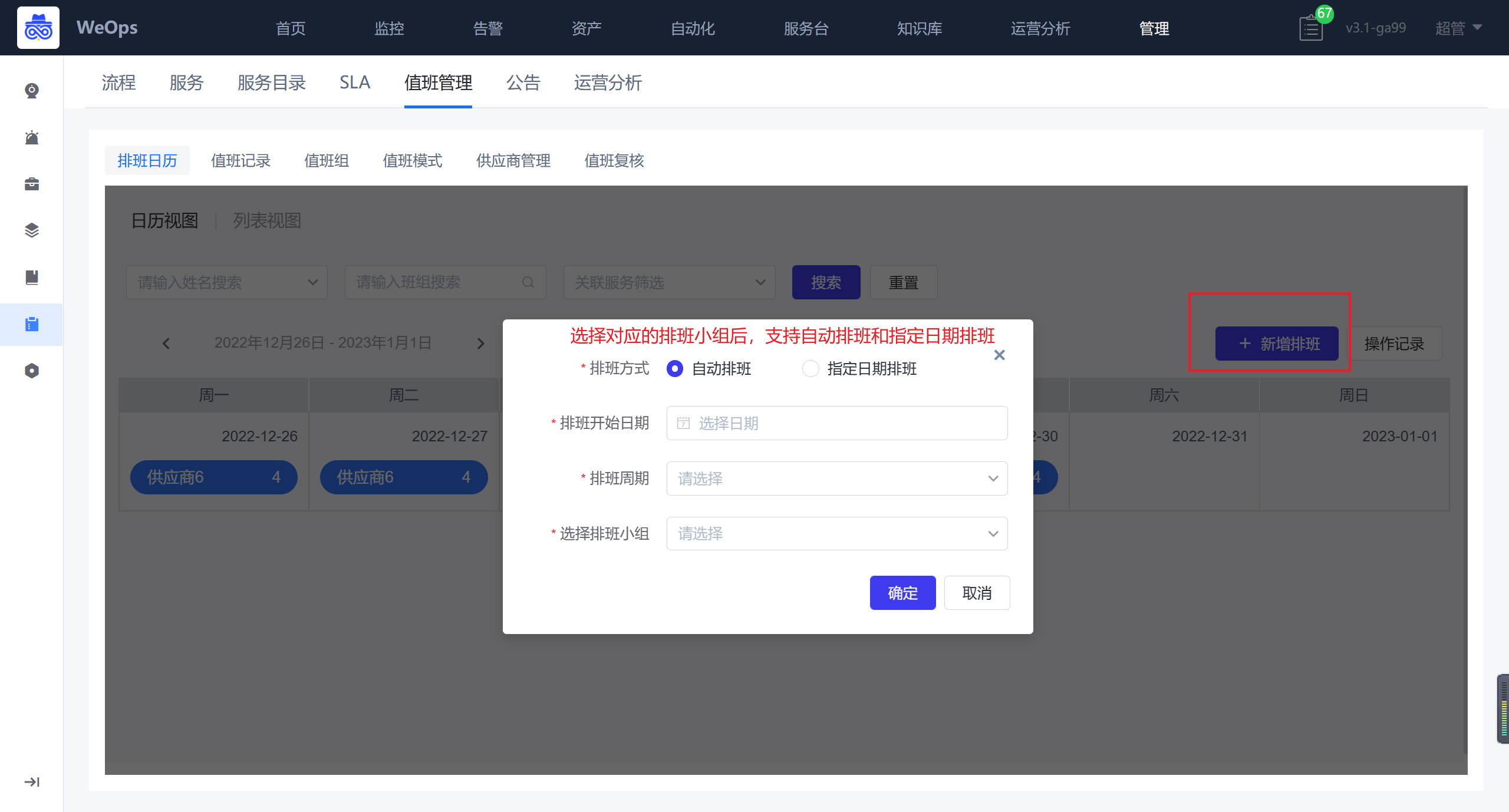
可以手动添加新增排班,支持某一时间段自动排班/指定时间排班,并选择值班组
点击未值班的人员可以进行调班(跟其他人员对调)、替班(由其他未值班人员顶替)。点击未来的日期可以进行插班(新增人员在当前日期值班)。

值班复核
路径:管理-服务台管理-值班管理——排班设置
当开启了值班复核(可在在ITSM-系统设置-基础配置中开启/关闭)后,排班的内容不会立刻生效,需经过超管及以上权限用户确认排班后,才会生效。
在复核时,可以调整值班成员(删除/新增);所有未经过复核的排班操作均会才此处展示;若排班已过期(到达了值班开始时间还未复核),相关内容将从此处移除。

我的值班
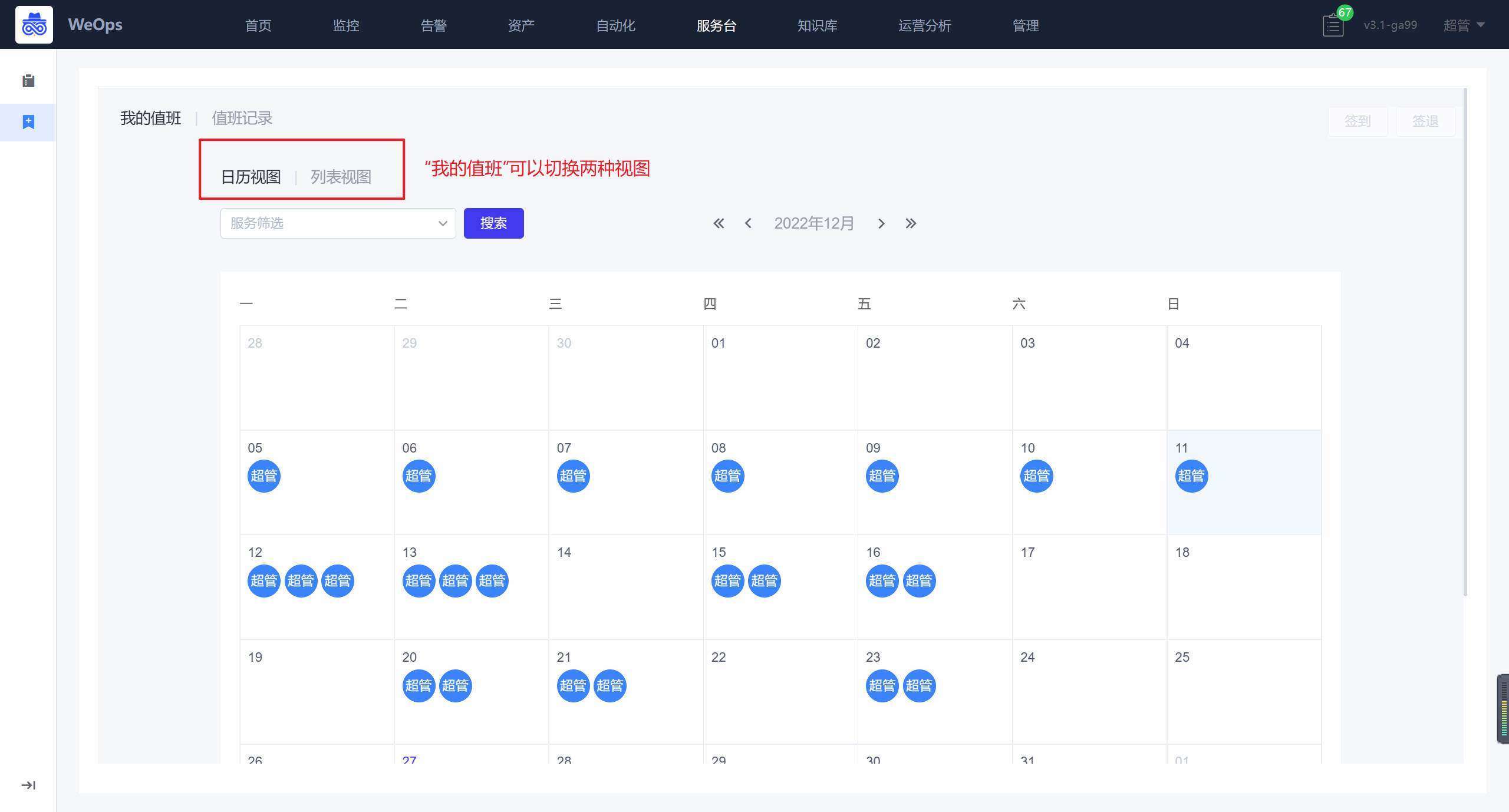
路径:服务台-我的值班
- 我的值班:支持切换“日历视图”和“列表视图”两种视图,根据排班情况展示我的值班情况,可进行签到、签退、工作交接。
- 值班记录:可查询以往值班记录/未来值班安排,可查看详细的值班和交接日志。
服务流程设置
路径:管理-服务台管理-流程
- 在流程配置过程中,审批节点可以选择对应值班组人员,当用户提单后,将按照值班组的值班情况分派给对应的人员来处理工单

3.7 服务台-公告配置
背景介绍:为了让用户及时获悉运维部门/其他部门对外公告,可在WeOps后台进行公告的配置,配置完成后,可根据有效期在IT服务台显示。
整体步骤:公告配置——IT服务台公告查看
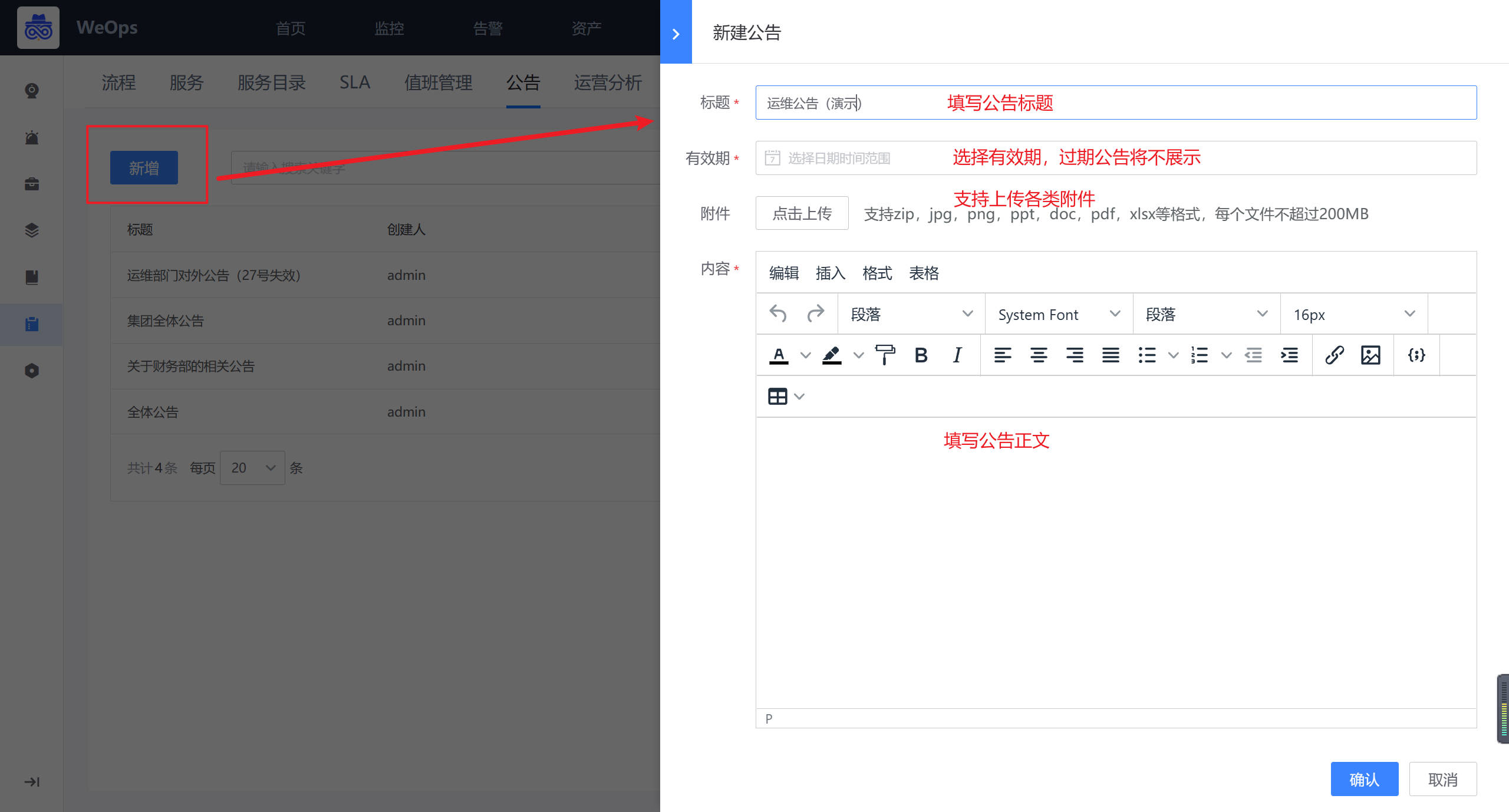
公告配置 路径:管理-服务台管理-公告
如下图,可以根据需求设置公告内容,设置公告有效期,支持上传附件、图片、链接、表格等各种格式。
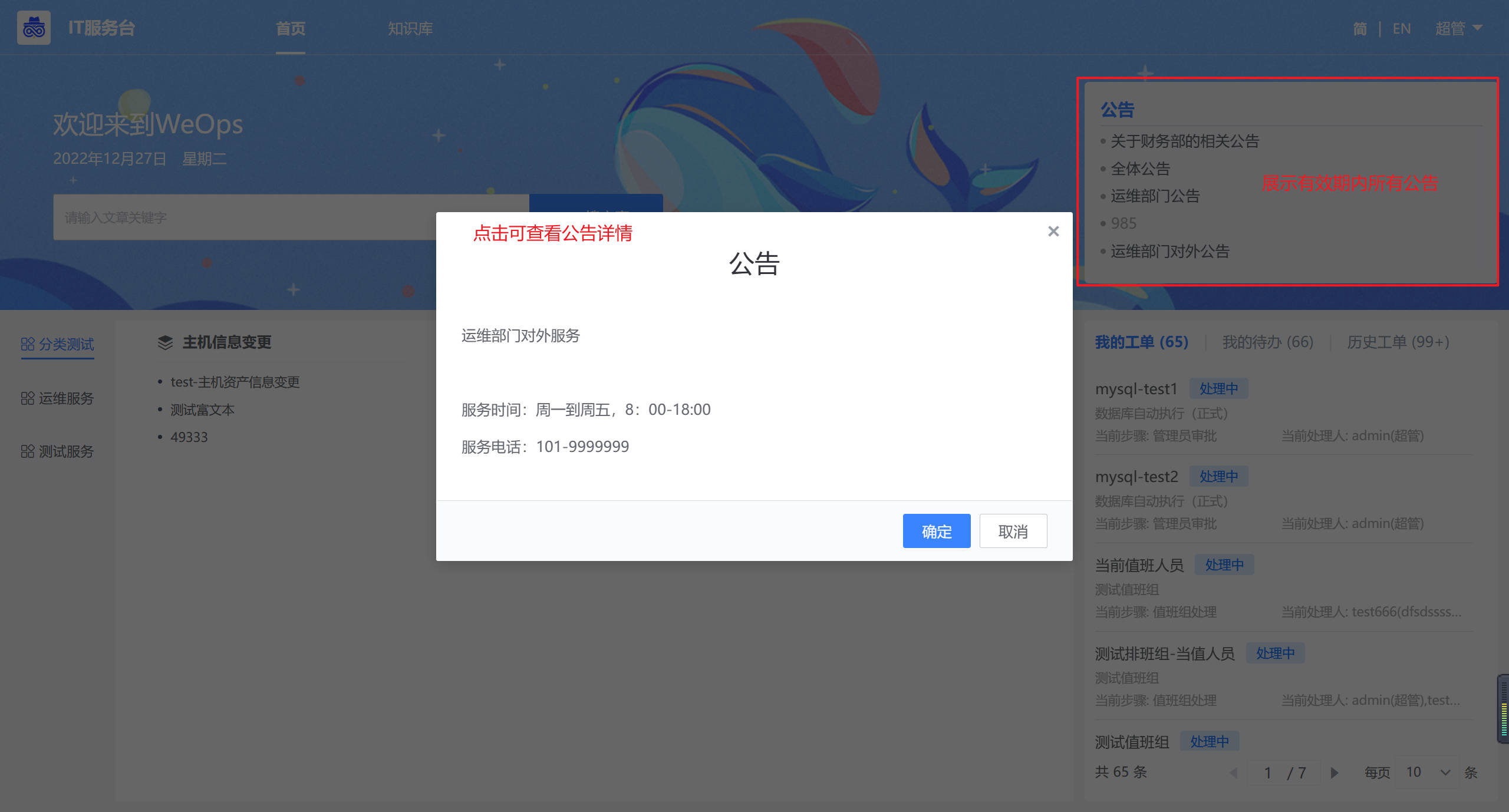
公告查看 路径:IT服务台
如下图,公告设置完成,可在IT服务台进行查看
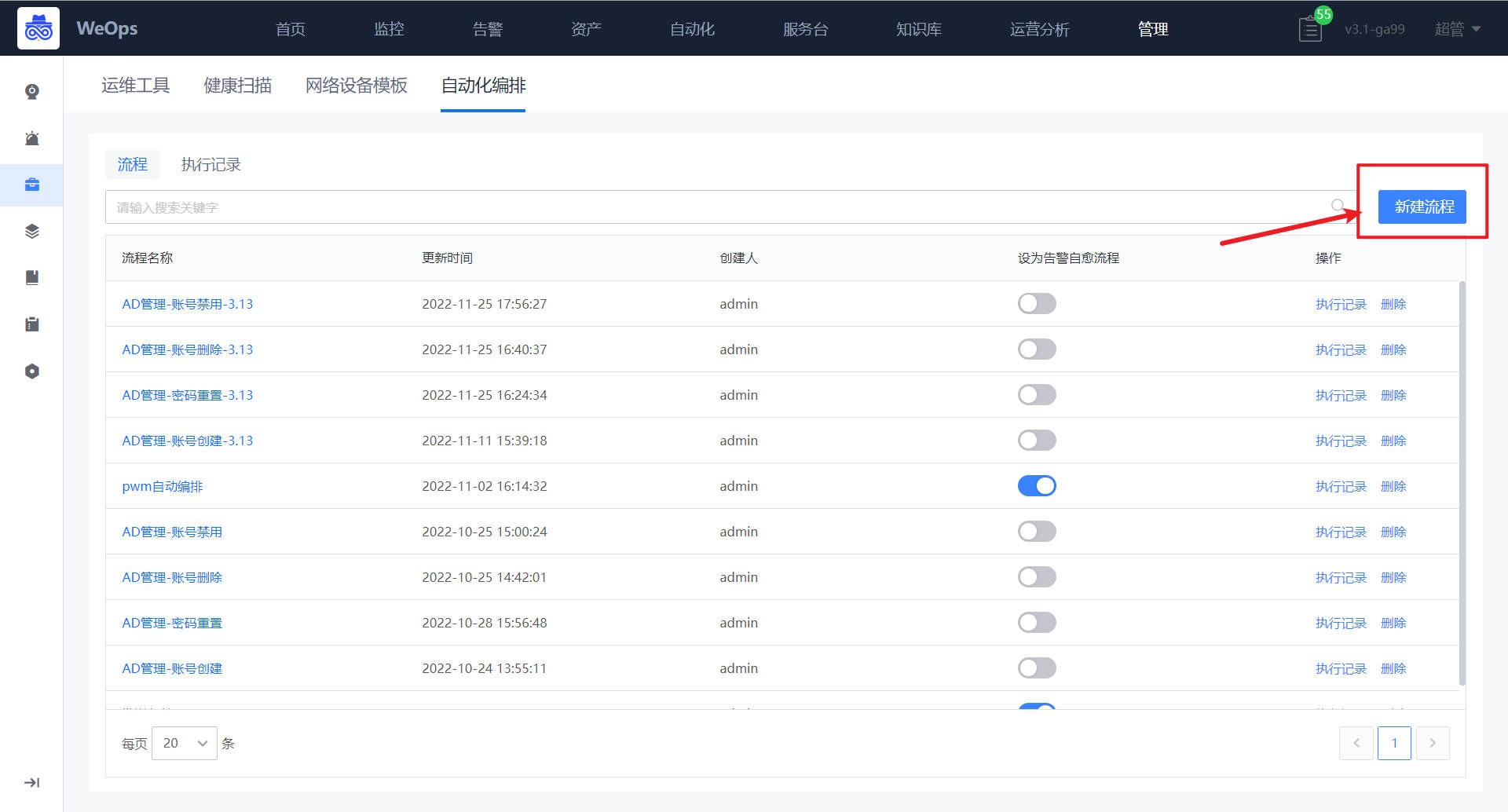
3.8 自动化编排
背景介绍:IT部门想在工单流程设置中引用自动化流程实现自动处理,或想在告警处理中引用自动化流程实现自愈处理。
整体步骤:新建流程(新建-配置节点-设置全局变量)——被服务台流程使用/被告警自愈使用
新建流程
路径:管理-自动化管理-自动化编排
- 用户可以通过对标准插件节点、子流程节点与网关节点的组合,变量的配置与引用,配置出一个业务自动化流程。流程的新建分为以下三步:新建流程,填写流程名称——配置流程节点——配置全局变量
第一步:新建流程,填写流程名称
如下图,点击流程中“新建”按钮,可进行流程的新建,流程名称是用户用来描述流程模板的,默认值是 “new+时间格式串”,用户可以自行修改。
第二步:配置流程节点
根据实际需求,进行流程节点和拖拽、配置和布局等方面的设置。
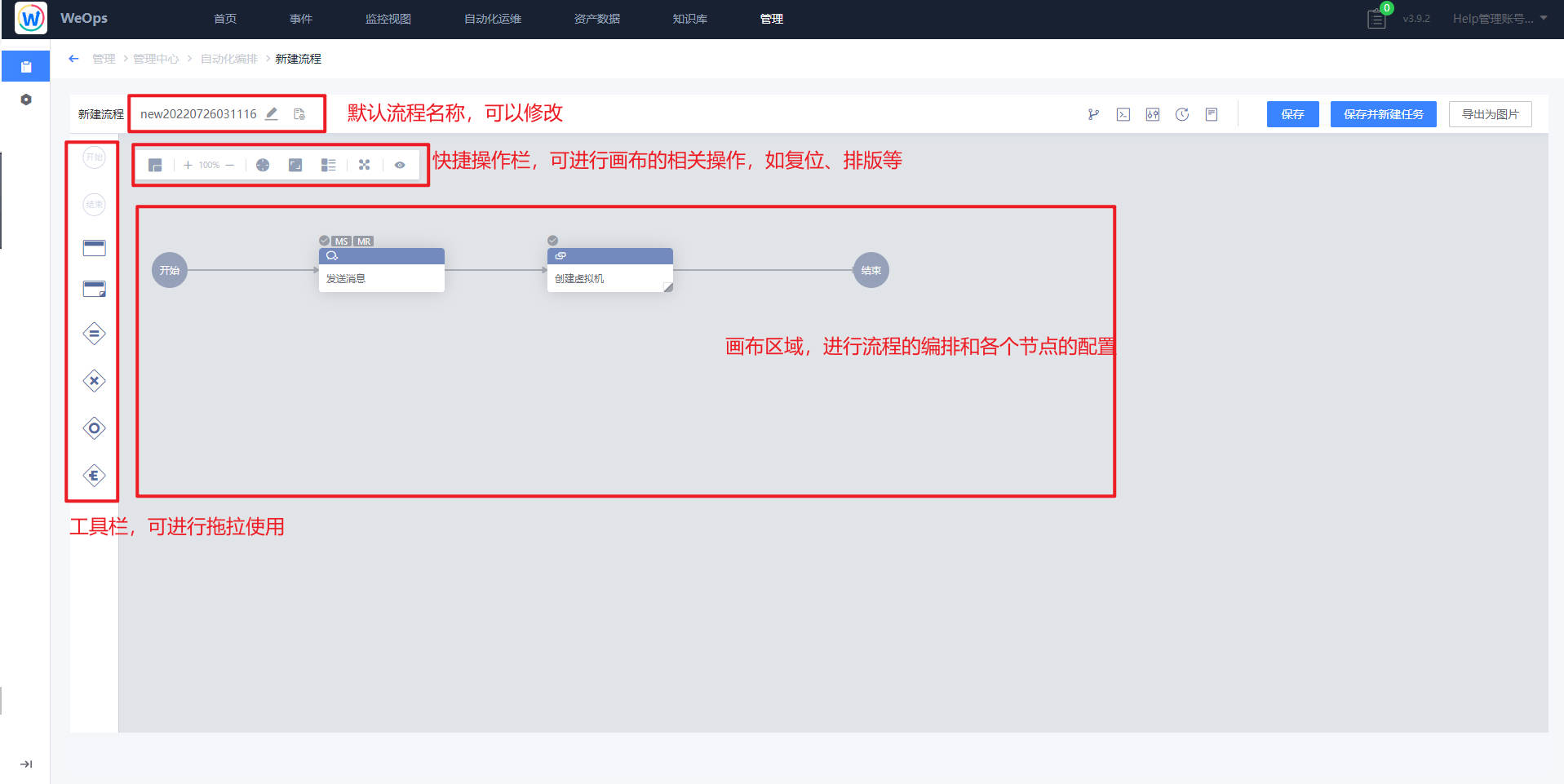
【工具栏说明】
开始节点——标识流程的开始(一般已经默认)
结束节点——标识流程的结束(一般已经默认)
并行网关——标识并行执行的开始
分支网关——标识分支执行的开始
汇聚网关——标识并行或分支的结束
标准插件节点——自动编排内置的最小执行单元,可直接使用内置的插件或使用第三方插件
子流程节点——可以选择用户已经创建的流程模板,在新的流程中引用并作为子流程执行标准插件节点:双击标准插件节点可以配置标准插件节点的参数。其中标准插件类型可以选择已经接入的标准插件
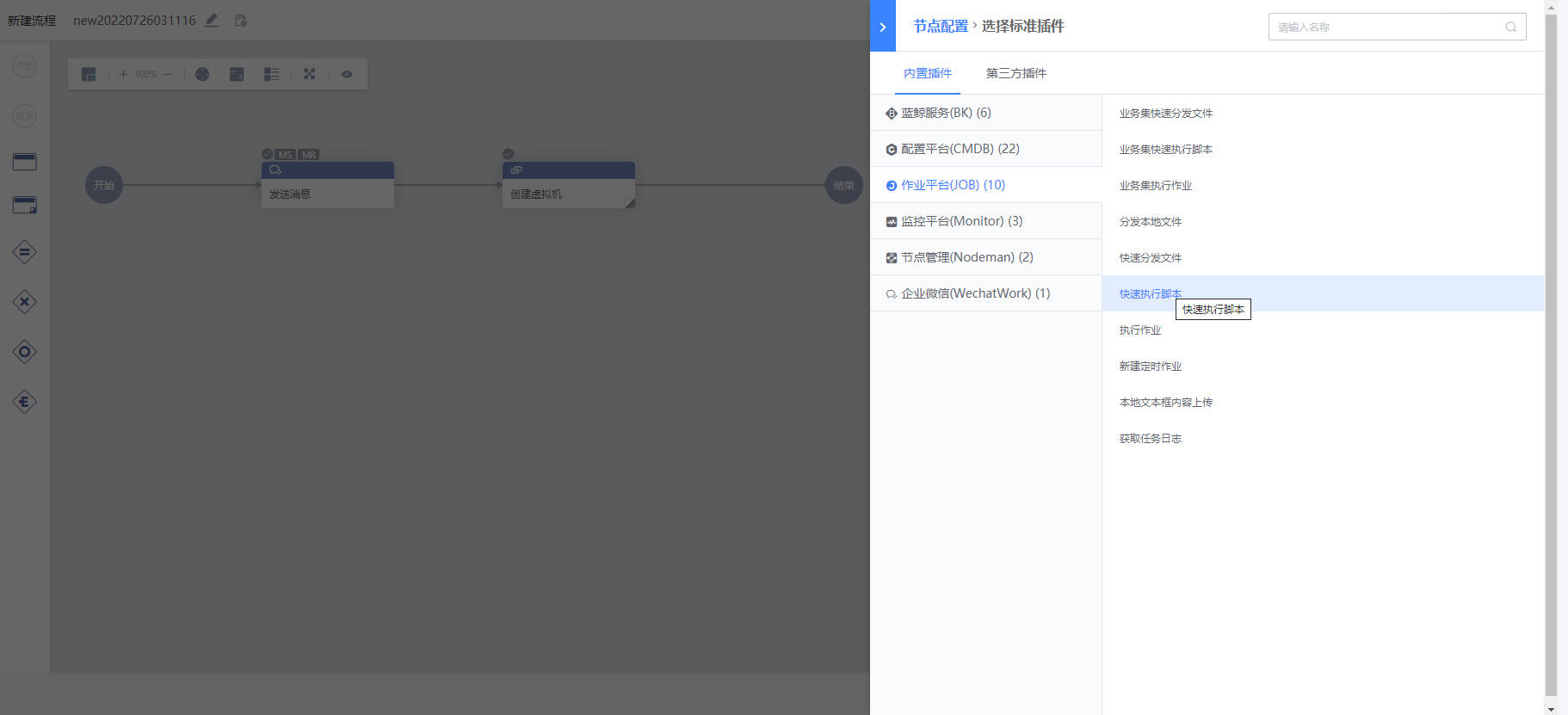
每个标准插件的参数一般不同,如“作业平台(JOB)-快速执行脚本”是对应作业平台的快速执行脚本 API,需要填写脚本类型、脚本内容、脚本参数等输入参数,在执行时,会利用填写参数调用 API,然后根据结果把 JOB 任务 ID、JOB 任务链接、执行结果(成功或失败)作为输出参数展示在执行详情中,后续的流程节点也可以引用前面节点的输出参数。

子流程节点:子流程节点可以选择用户已经创建的流程模板,在新的流程中引用并作为子流程执行。子流程节点的输入参数是子流程模板单独创建任务时需要填写的任务参数。输出变量是选择的流程模板中勾选了输出属性的全局变量。

第三步:配置全局变量
全局变量是一个流程模板的公共参数,用户可以在任务节点的输入参数和分支网关表达式中引用
全局变量来源有三种:通过任务节点的输入参数勾选生成、通过任务节点的输出参数勾选生成、在全局变量区点击 “新增变量” 生成


被服务台流程使用
路径:管理-管理中心-服务台管理
在服务流程创建的过程中,通过使用“标准运维节点”从而可以直接把已经创建好的自动化流程引用到工单流程中。
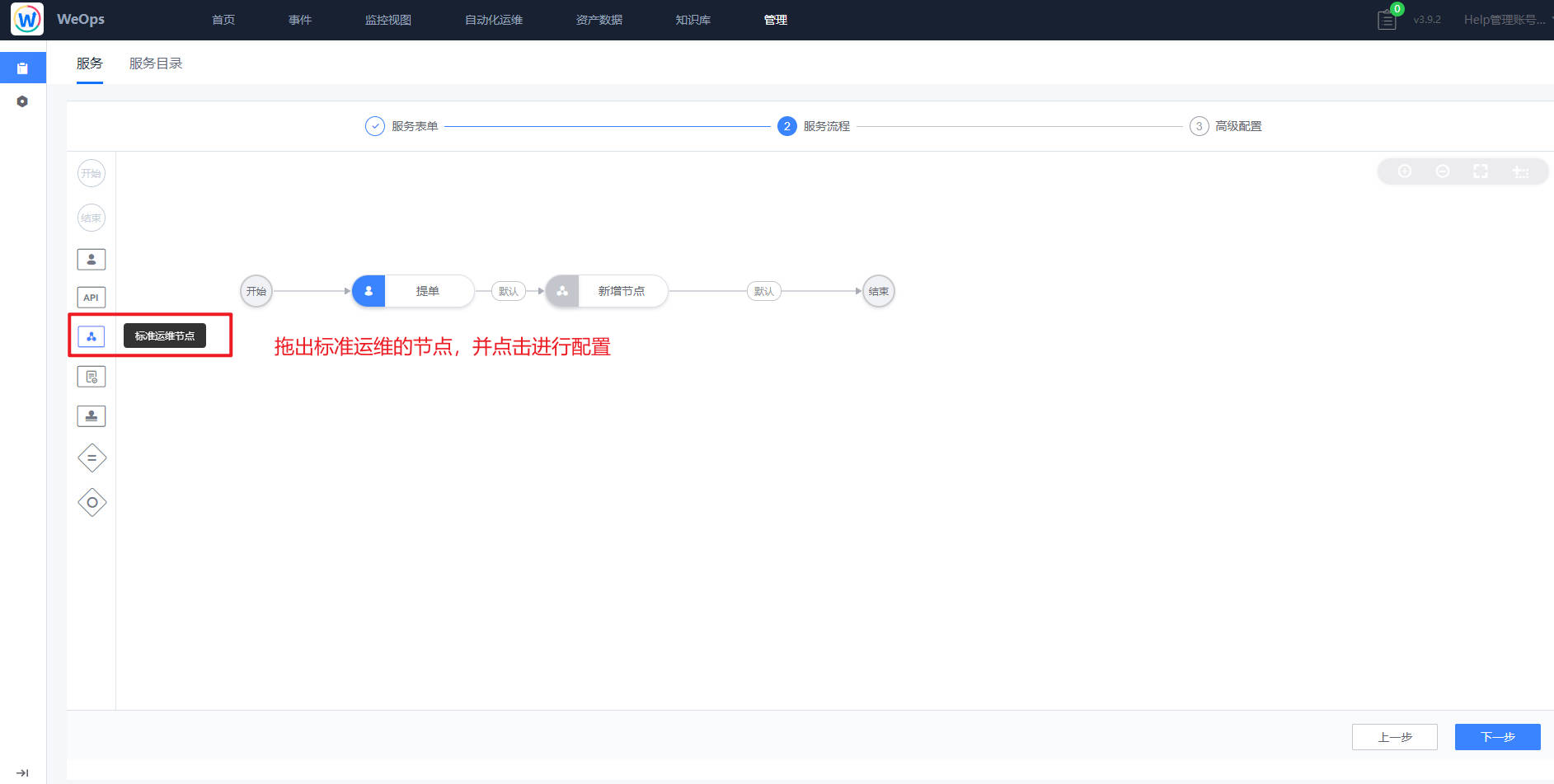
在“标准运维节点”的配置中,填写该节点基本信息,选择需要使用的自动流程,若该流程需要填写输入参数则需要填写。
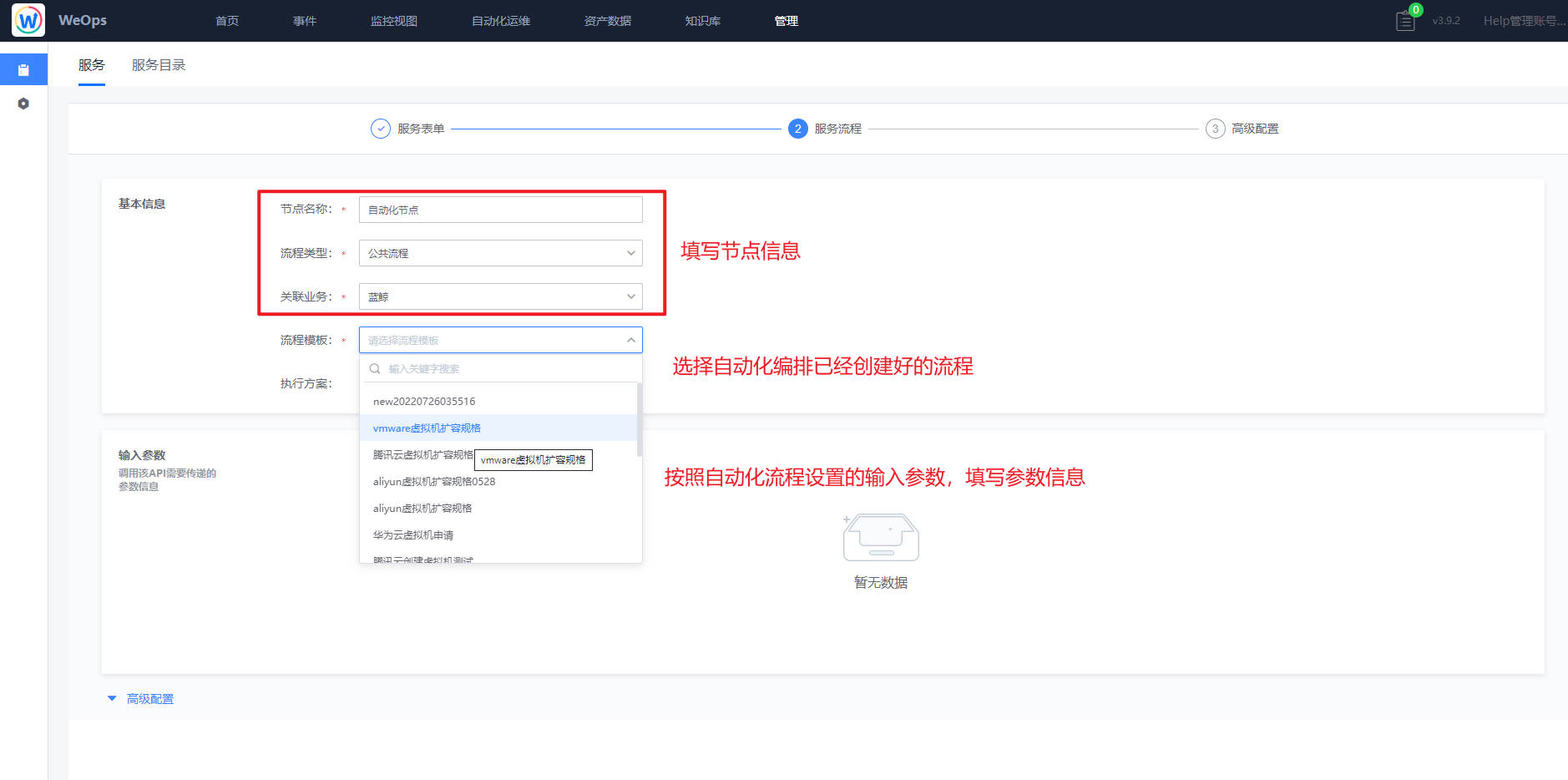
工单流程引用自动化流程后,当工单流转至该节点时,会自动调用自动化流程。
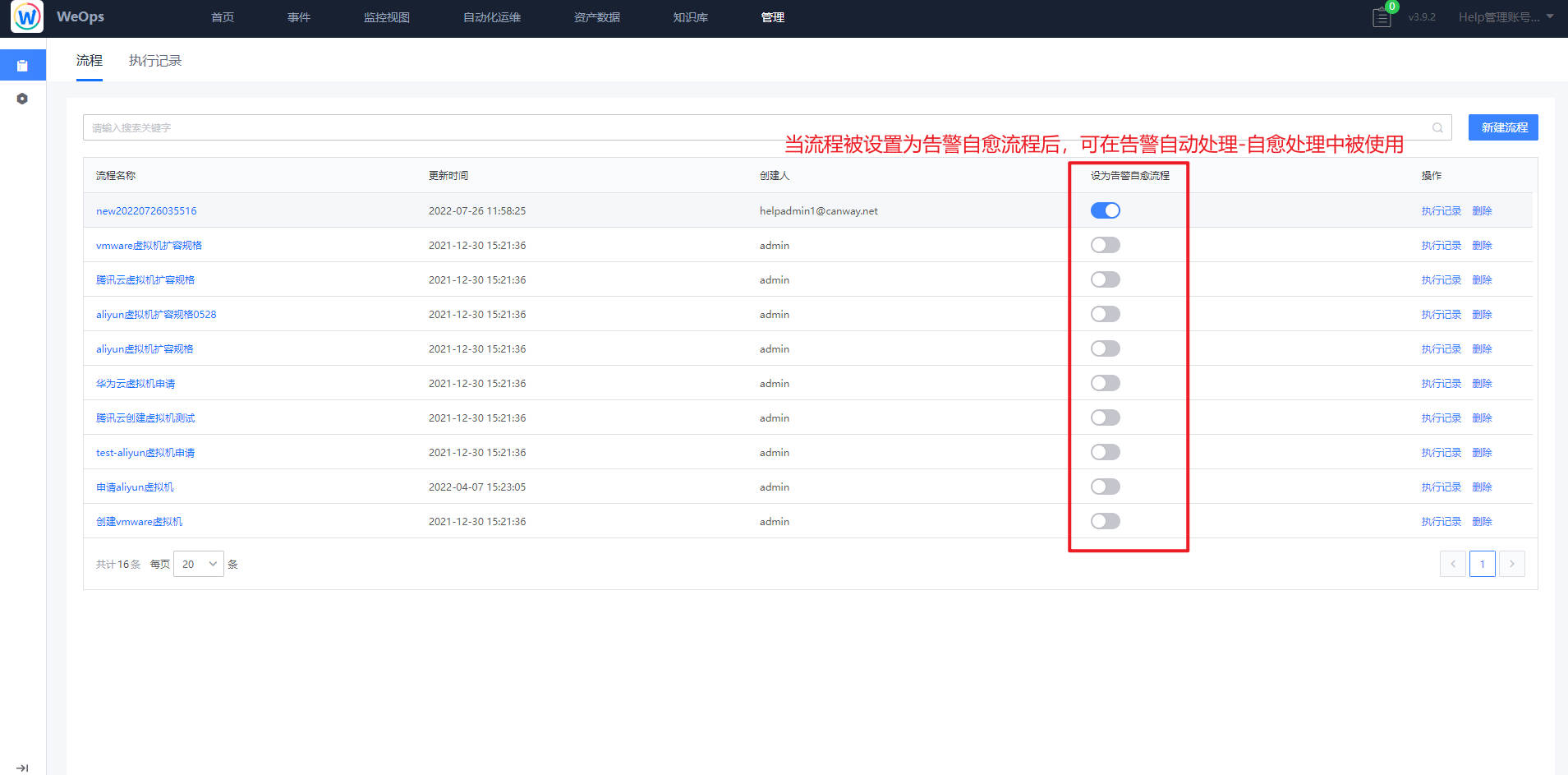
告警自愈使用
路径:管理-管理中心-告警管理-告警处理(自动处理)
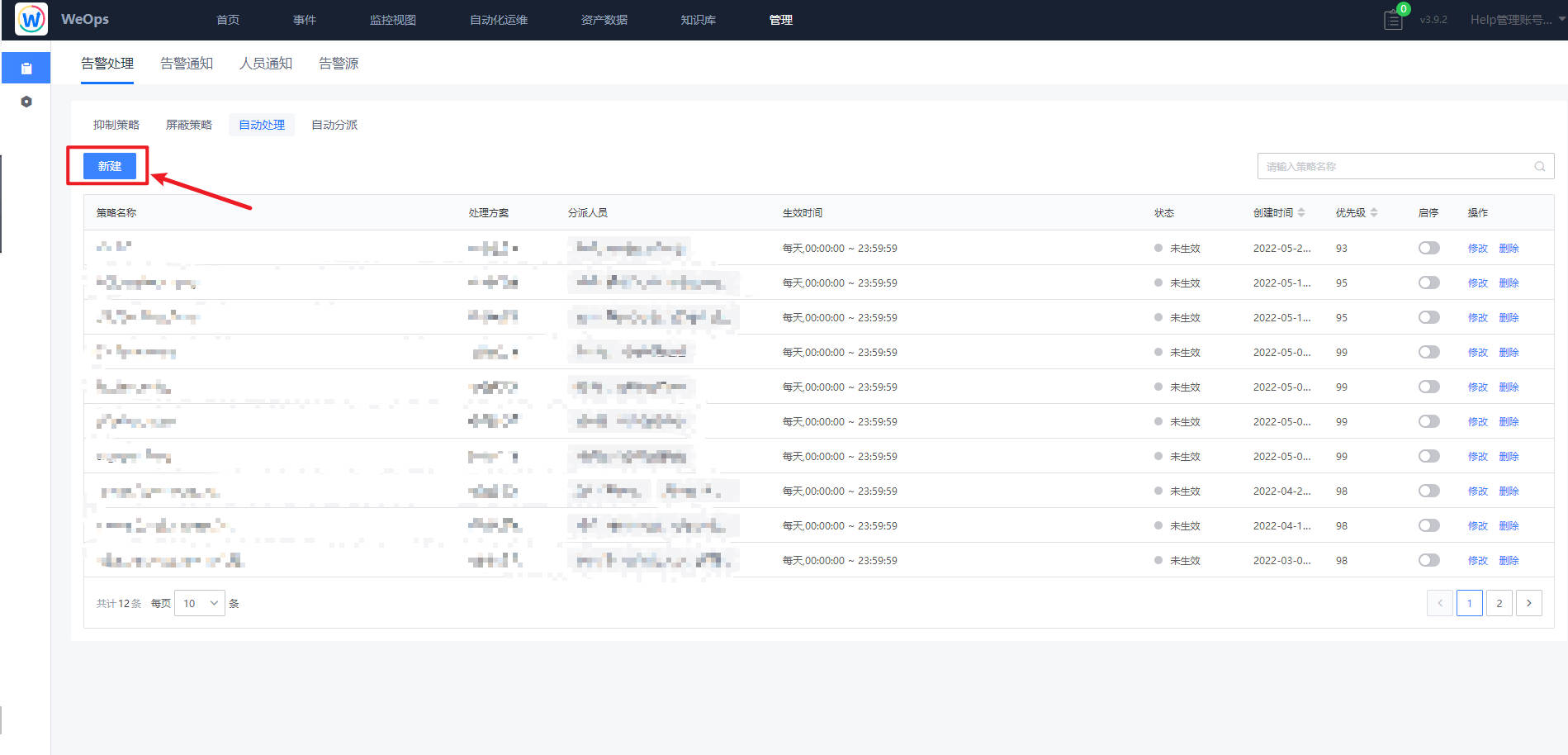
在“管理中心-自动化编排”中把对应流程勾选上“设为告警自愈流程”
在“管理中心-告警管理-告警处理(自动化处理)”中,点击新建按钮,在新建的自动化处理策略中,填写基本信息、选择告警对象和规则、选择“自愈处理”并选择对应的自愈流程。

3.9 凭据的配置和使用
背景介绍:运维管理员统一管理资产的凭据,并且在使用时可以快捷的选择已经保存的凭据,目前支持主机/AD两类凭据的管理和使用。
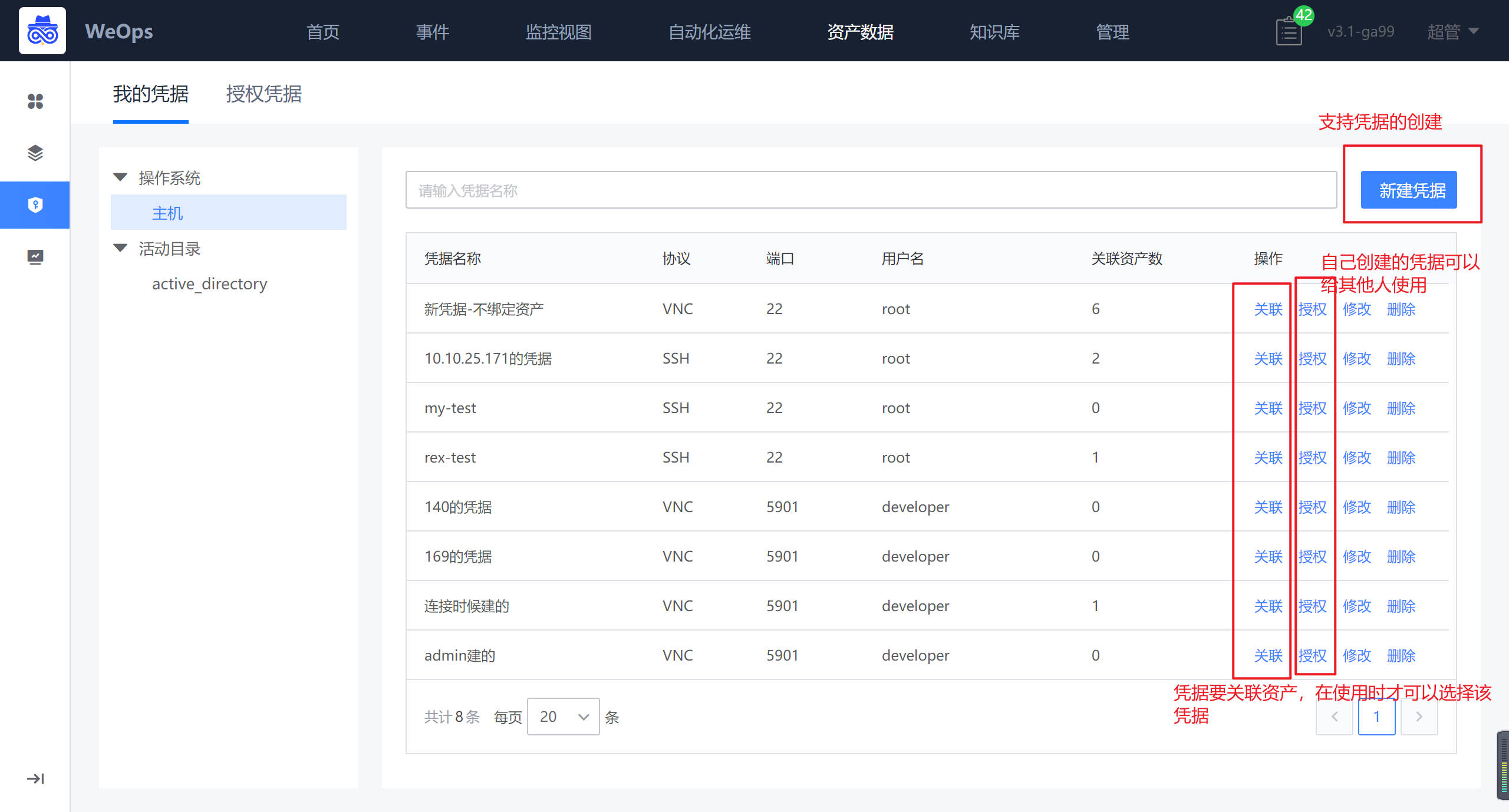
创建凭据
路径:资产数据-凭据管理-我的凭据
支持主机/AD/网络设备的凭据新建,主机支持SSH/RDP/VNC协议、AD支持LDAP/LDAPS协议,创建的凭据需要关联资产,对应的资产才可以使用这条凭据。(注:网络设备不需要关联资产)

授权凭据
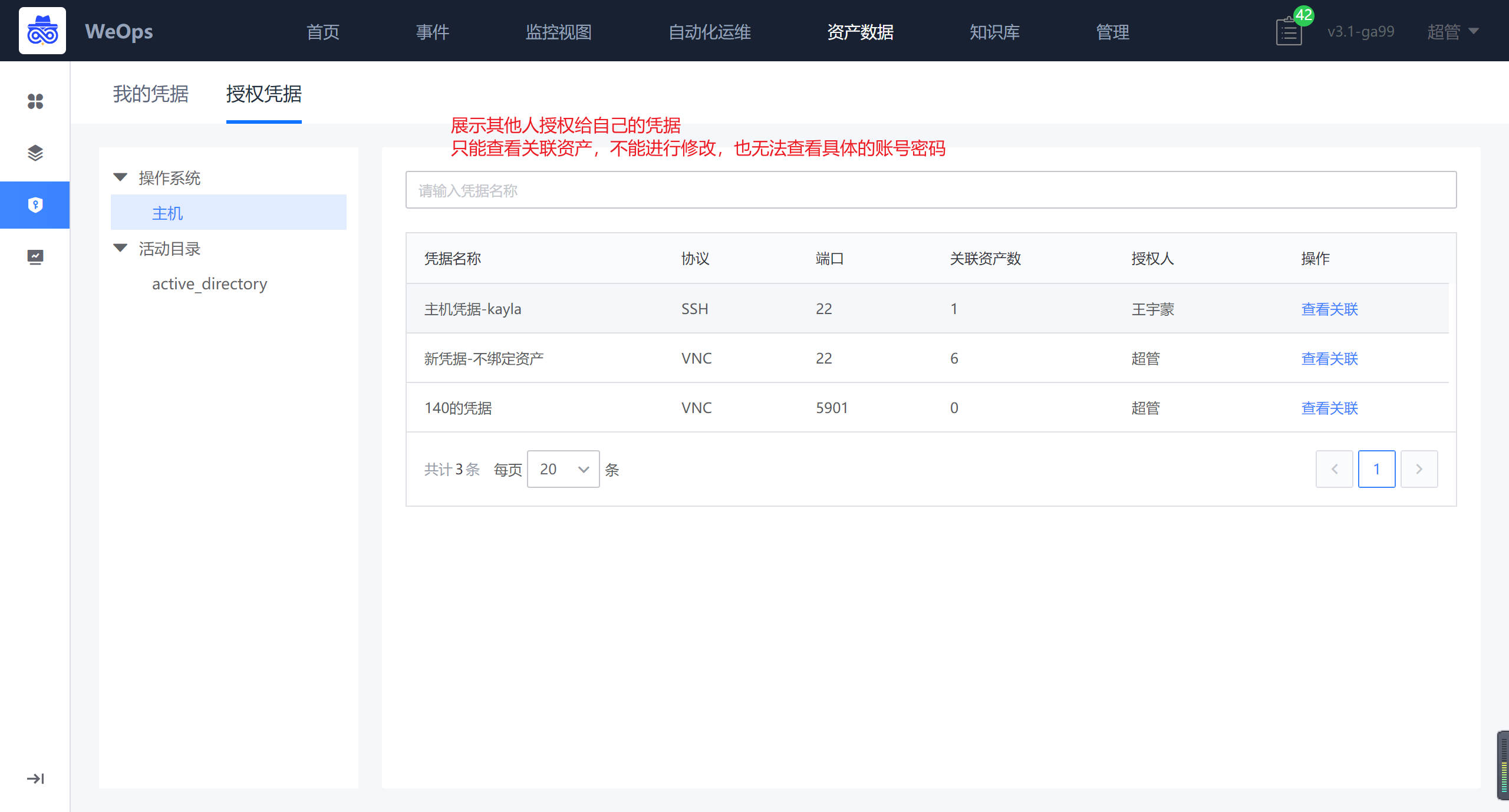
路径:资产数据-凭据管理-授权凭据
展示其他人授权给自己的凭据。
凭据使用
用户可以在某个资产使用的凭据场景包括两类:一类是自己创建的凭据,并且这个资产已经绑定凭据;另一类是别人把创建的凭据授权给自己,且这个凭据绑定了这个资产。
主机凭据使用有如下两个途径:在资产列表-主机中,可以点击“远程连接”快捷选择已有的凭据进行远程连接;在告警——告警详情中,若是主机产生了告警,可以快捷使用已经的凭据进行远程连接
AD的凭据使用:AD目前使用在weops-内置的自动化工单流程中,作为AD账号创建/修改/禁用/删除的前置条件,具体的自动化工单流程可详见“内容说明——7、内置的工单流程”
网络设备的凭据使用:设置自动发现网络设备的时候可以使用已有的网络设备凭据,设置网络设备监控采集的时候可以使用已有的网络设备凭据。
云平台的凭据使用:设置自动发现网络设备的时候可以使用已有的网络设备凭据,设置网络设备监控采集的时候可以使用已有的网络设备凭据。
3.10 通知渠道配置
路径:管理-系统管理-通知渠道
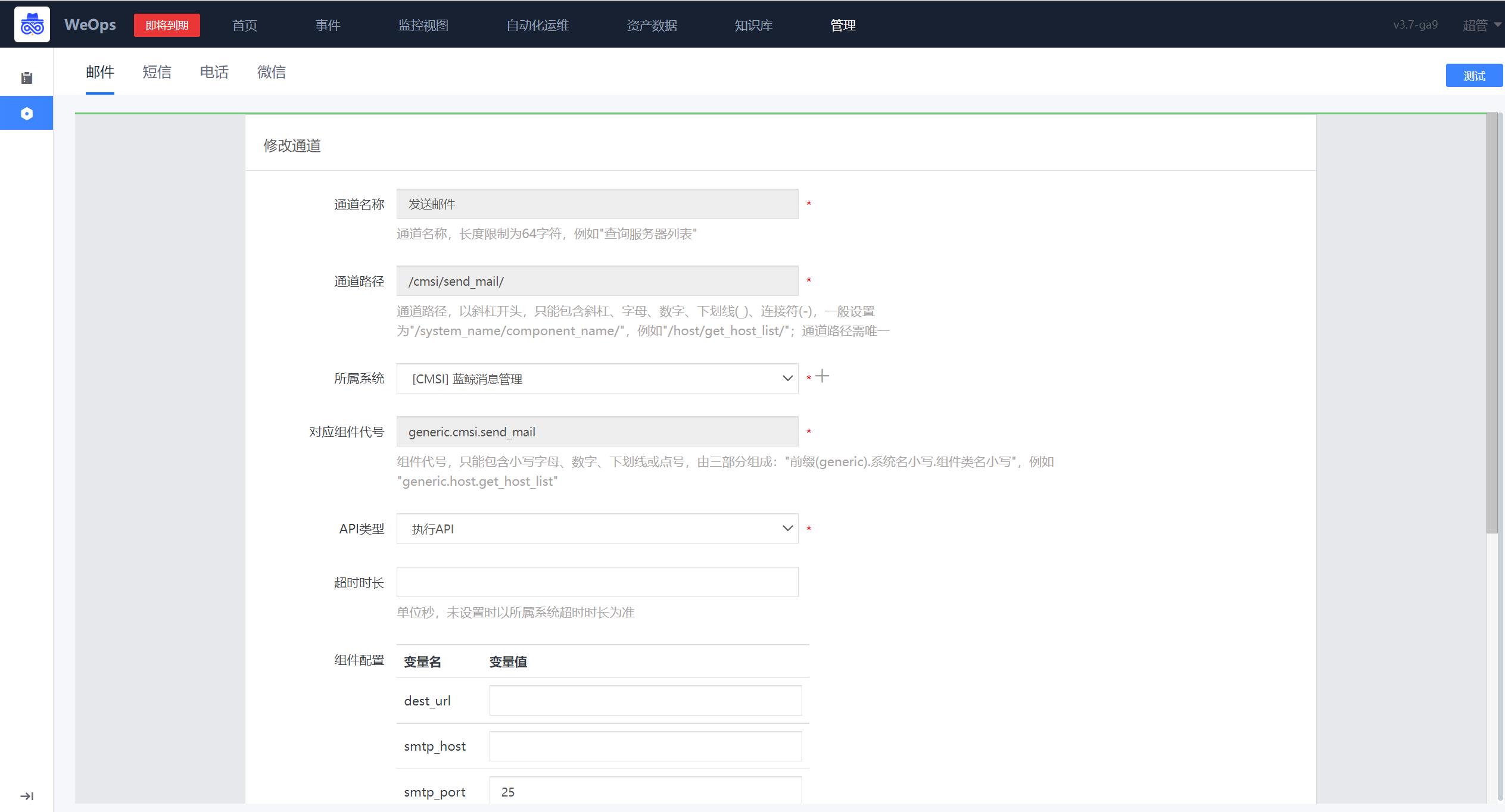
邮件
邮件是相对较为常见的通知方式,对接配置比较简便,需提供一个发件箱,并允许蓝鲸对SMTP服务器的访问权限。参数说明如下:
dest_url: 若用户不擅长用 Python,可以提供一个其他语言的接口,填到dest_url,ESB 仅作请求转发即可打通邮件配置
smtp_host: SMTP 服务器地址 (注意区分企业邮箱还是个人邮箱)
smtp_port: SMTP 服务器端口 (注意区分企业邮箱还是个人邮箱)
smtp_user: SMTP 服务器帐号
smtp_pwd: SMTP 服务器帐号密码 (一般为授权码)
smtp_usessl: 默认为 False
smtp_usetls: 默认为 False
mail_sender: 默认的邮件发送者 (smtp_user 相同)
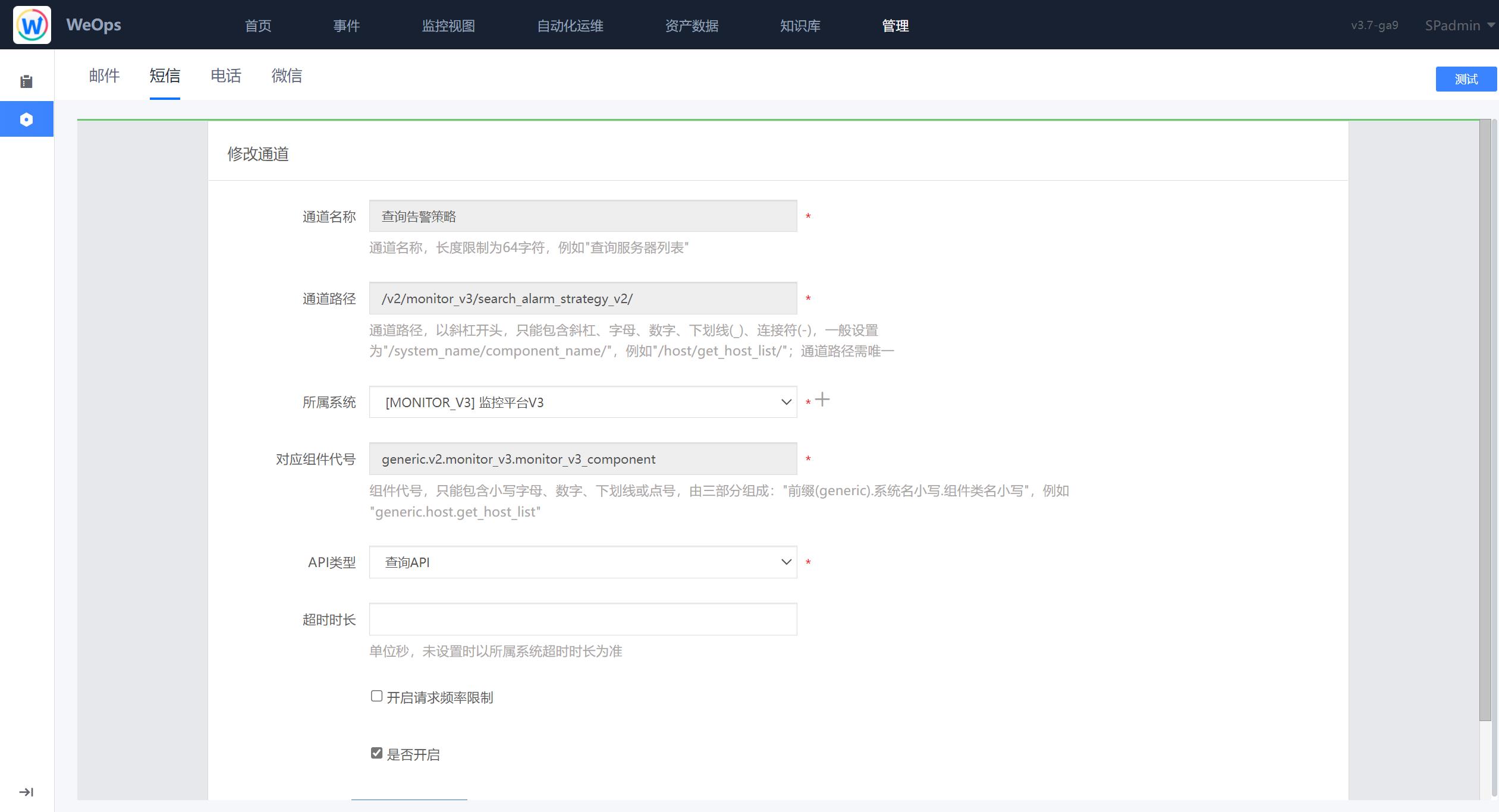
短信
企业采用的短信服务厂商不尽相同,目前蓝鲸仅支持腾讯云sms服务开箱即用,其他厂商对接需企业提供短信服务接口文档,并在蓝鲸侧做定制适配,以下以腾讯云sms为例列举参数说明:
dest_url: 若用户不擅长用 Python,可以提供一个其他语言的接口,填到 dest_url,ESB 仅作请求转发即可打通短信配置
qcloud_app_id: SDK AppID
qcloud_app_key: App Key
qcloud_sms_sign: 在腾讯云 SMS 申请的签名,比如:腾讯科技
微信公众号
1)微信公众号对接需要满足以下先决条件:
a)企业需提供一个微信公众号;
b)蓝鲸平台发布在公网。
2)创建微信公众号:打开微信公众平台(https://mp.weixin.qq.com/)自行注册微信公众号服务号,所在行业选择IT科技/IT软件与服务(和后面的模板消息有关联);
3)添加模板消息
4)统一告警中心配置公众号相关信息:
APPID,AppSecret:在服务号管理后台-开发-基本配置中可获取到
Token:自行设置 (必须是英文或数字, 长度3-32字符)
template_id:在服务号管理后台-功能-模板消息中可获取到
5)然后,在微信服务号管理后台-开发-基本配置,须填写以下参数:
IP白名单:填写统一告警中心服务器出口IP
服务器地址:填写内容为{{alarmcenter_url}}/alarm/mobile/wechat/event/,{{alarmcenter_url}}为统一告警中心地址
令牌(token):上一步中填写的token
消息加解密密钥:不需要设定
消息加解密方式:选择 “明文模式”
6)在服务号管理后台-设置-公众号设置-功能设置,设置网页授权域名处需下载授权文件提供给实施工程师进行蓝鲸服务器Nginx配置,然后填写网页授权域名为paas域名, 即可通过验证。

企业微信 1)企业微信对接需要满足以下先决条件:
a)统一告警中心SaaS(这里指SaaS所在蓝鲸appo服务器)能够访问外网(统一告警中心的告警会先把消息推送到企业微信服务器,然后企业微信再转发推送到客户的企业微信上,所以蓝鲸服务器需要能够访问公网);
b)蓝鲸平台的域名需要发布在公网;
c)外部访问蓝鲸公网域名+端口和在客户内网环境访问蓝鲸域名+端口需要一致,这是由告警中心这个SaaS的底层代码和企信的回调域设置决定的。事实上,告警中心移动端的配置是通过企信扫二维码实现的,这个二维码由SaaS生成,其实质是一个url,这个url只能从内网的蓝鲸服务器获取。因此,企信去访问这个url时,要先访问发布在公网的蓝鲸域名。强烈推荐蓝鲸平台采用https方式部署。
2)逻辑架构参考下图:
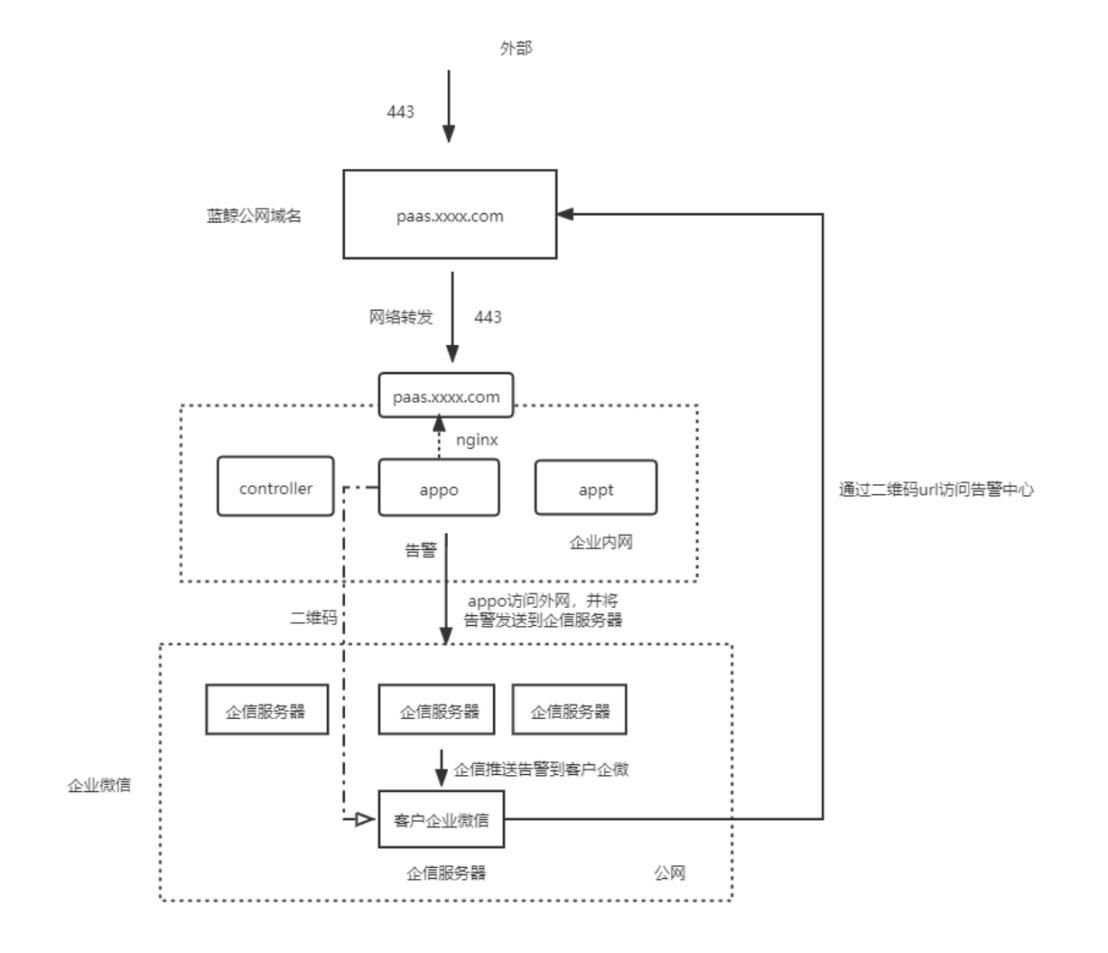
3)企业微信对接需在统一告警中心填写以下参数:
企业ID:在企业微信后台“我的企业”中可以获取到;
AgentID,Secret:在应用的基础信息中可以获取到

3.11 许可管理配置
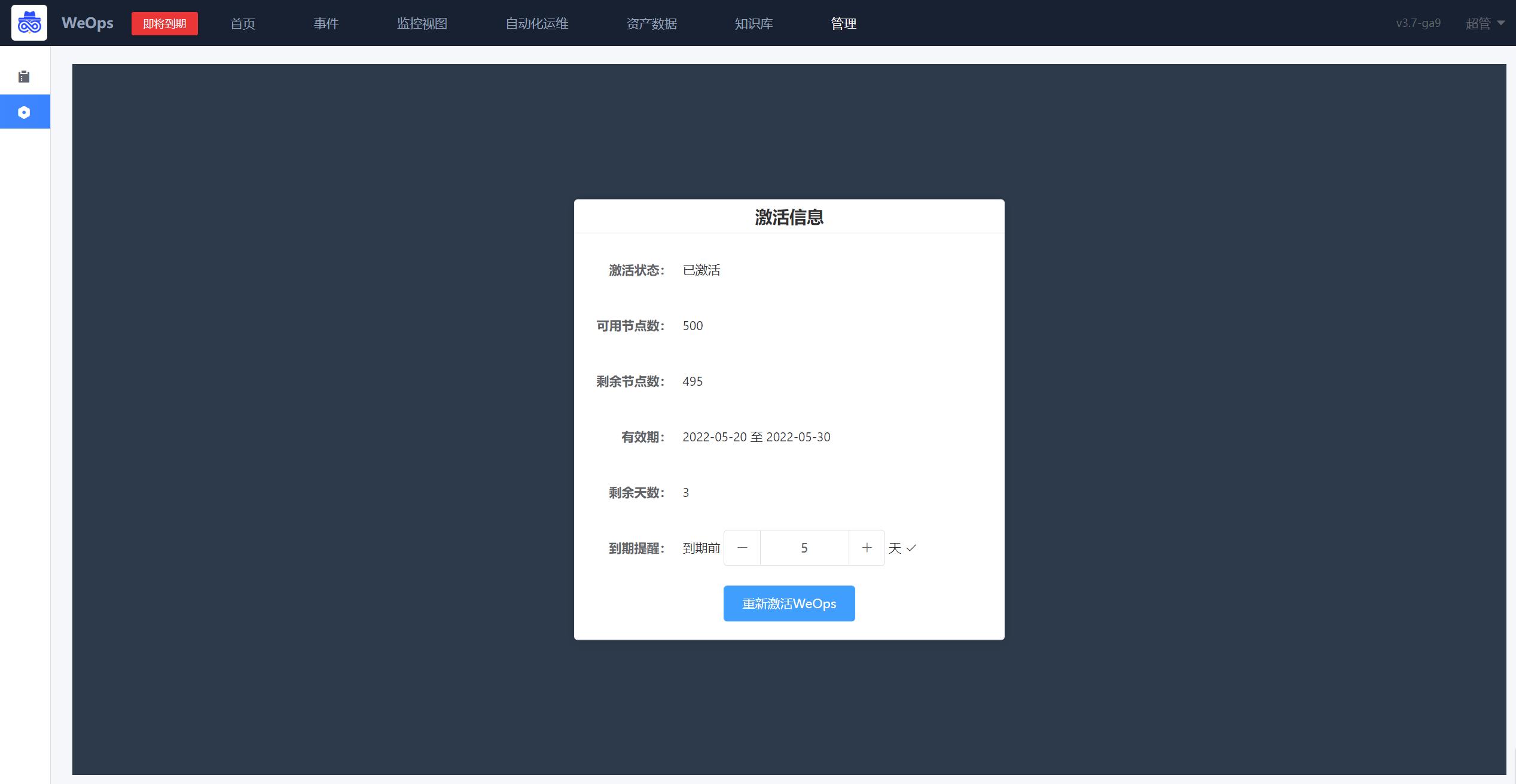
背景介绍:企业客户想了解该系统的可用节点信息和许可有效期,并设置到期提醒。
路径:管理-系统管理-许可管理
可以查看激活状态,可用节点数量、有效期等信息,可设置到期提醒,设置成功后,可在菜单的左上角收到到期提醒提示。
3.12 用户和角色配置
背景介绍:需要配置新角色,并对新角色授权对应权限,把对应用户赋予新角色。
整体步骤:新建角色——角色授权——赋予人员角色
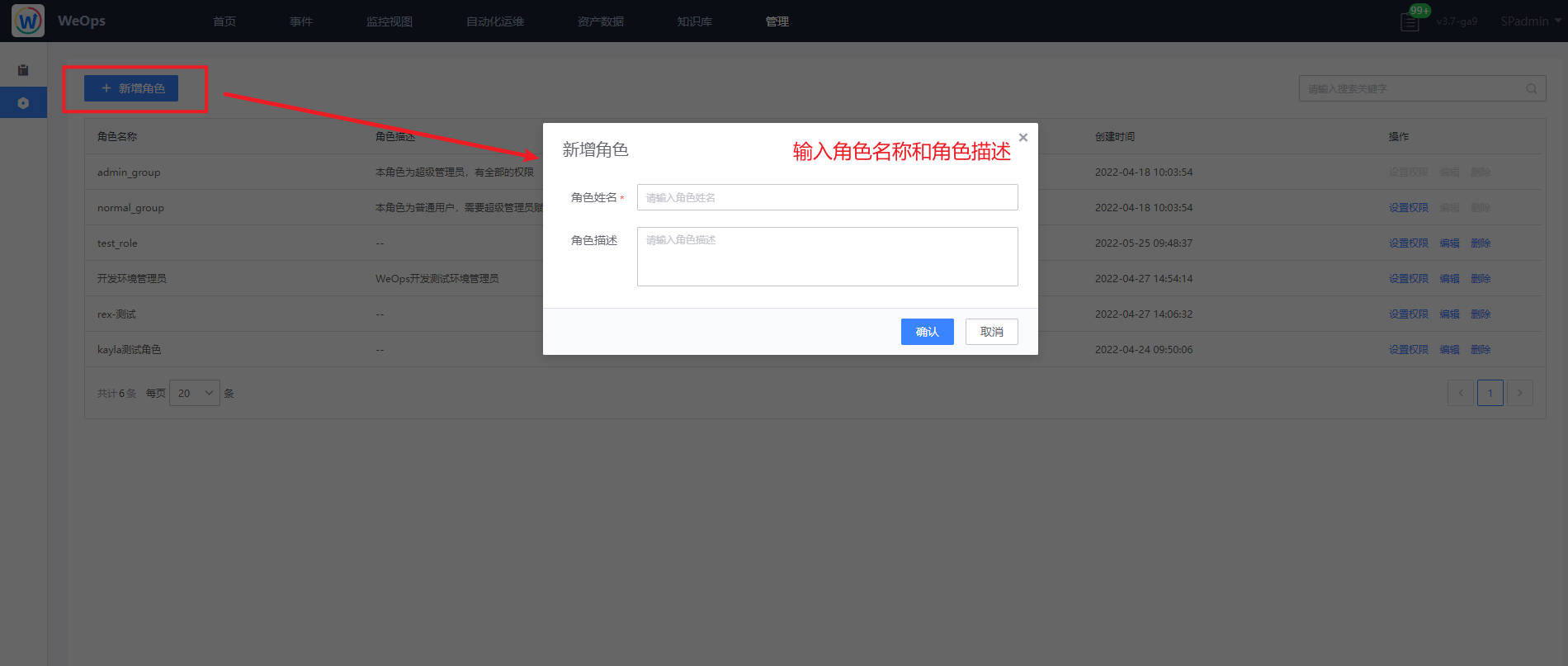
新建角色
路径:管理-系统管理-角色管理
- 如下图,点击“新建”按钮,填写角色名称和描述
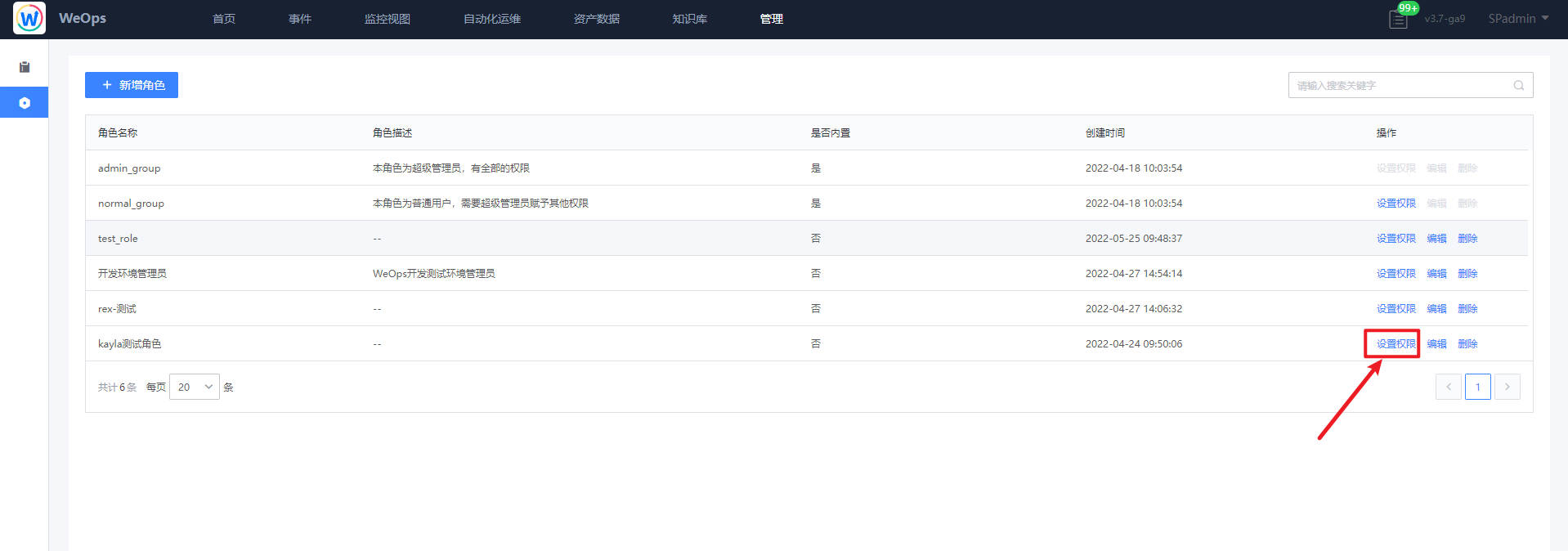
角色授权
路径:管理-系统管理-角色管理
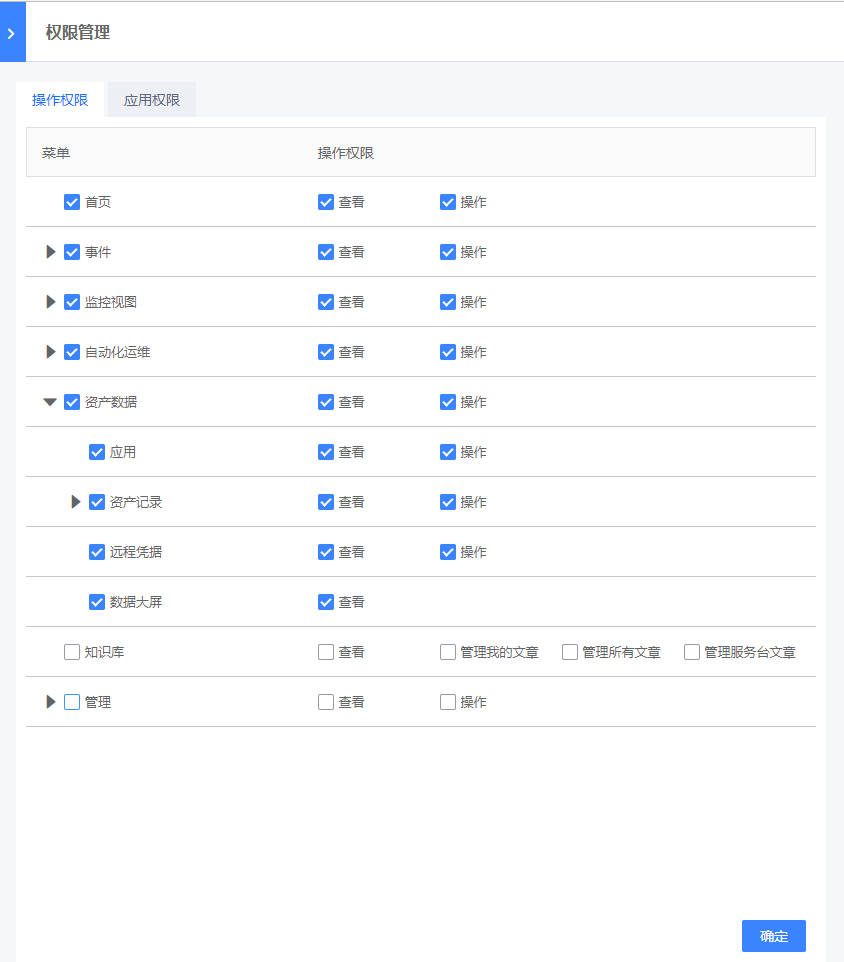
- 点击角色后的“设置权限”,对该角色进行授权,包括操作权限和应用权限。操作权限包括菜单权限和操作权限,用于限制该角色是否可以看到该菜单、以及对该菜单下的页面是否有查看/操作权限;应用权限用于限制该角色是否可以看到该应用数据已经该应用下的资产数据。
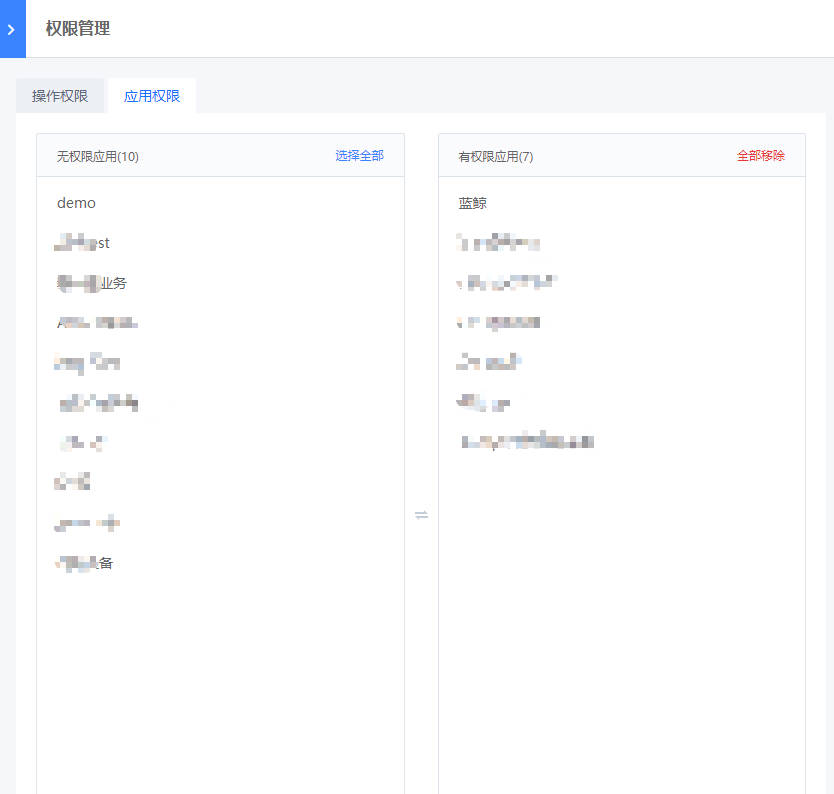
赋予人员角色
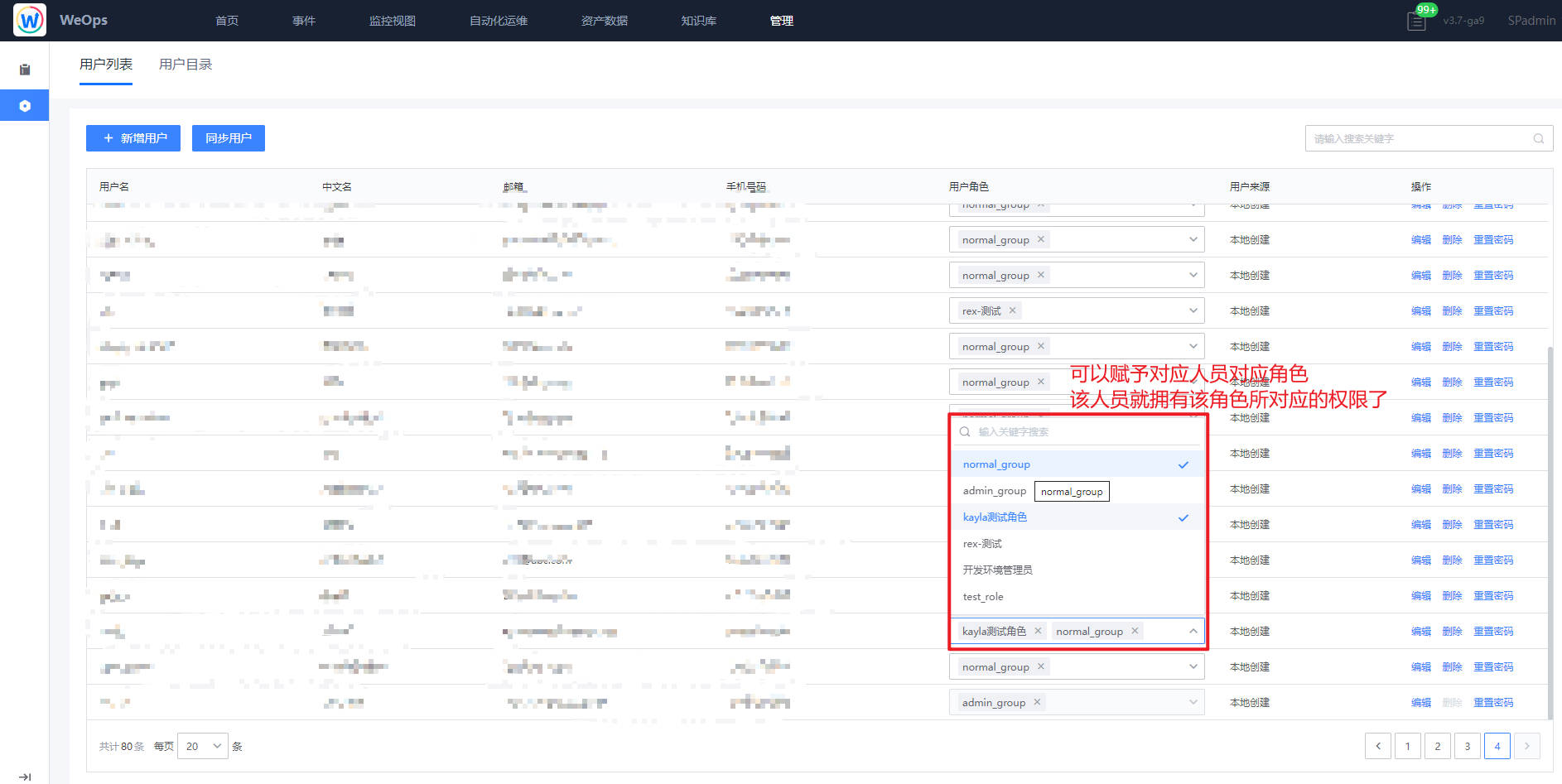
路径:管理-系统管理-人员管理
- 如下图,在“人员管理”中,选择需要设置的人员,在用户角色中选择对应角色,即可把该角色的权限赋予对应人员。若某人员赋予多个角色,则他将会拥有这多个角色的所有权限。
4、常用使用场景
场景一 如何进行主机监控告警配置和处理
场景介绍
某公司,现已存在Zabbix、动环、网络监控及阿里云监控系统,存在以下问题:告警信息查看系统过多,信息不同步,告警分析难度大,通知方式单一等问题。使用“WeOps-监控告警”可以对多类对象进行监控,提供多种方式的告警,全面展示该告警的相关信息,以便进行处理。
场景实现
Step1:监控采集-安装Agent
如下图所示,选择“操作系统-主机”,进入主机Agent安装界面,点击“安装Agent”

在安装的界面,选择该主机归属的业务、云区域以及接入点。随后在安装信息输入该纳管主机的IP地址,登录账号和密码等核心配置。输入完成之后点击[安装]按钮即可将agent部署至该主机。
Step2:监控策略配置
进入WeOps的管理中心的监控管理,找到监控策略。

- 如下图所示,进入新建监控模板配置界面
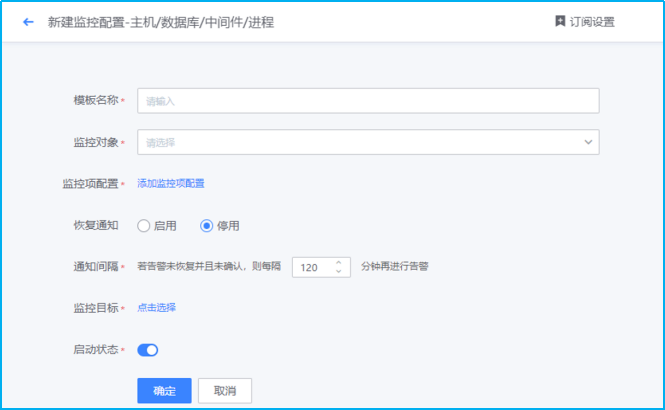
- 如下图所示,填写监控“模板名称”、“监控对象”。

- 如下图所示,点击蓝色字体【添加监控项配置】即会弹出对应界面。主机监控项分为“指标”和“事件”两类。指标主要为常见的CPU、内存、磁盘、进程等监控指标。而事件则是指Agent心跳、Ping可达、主机重启等。
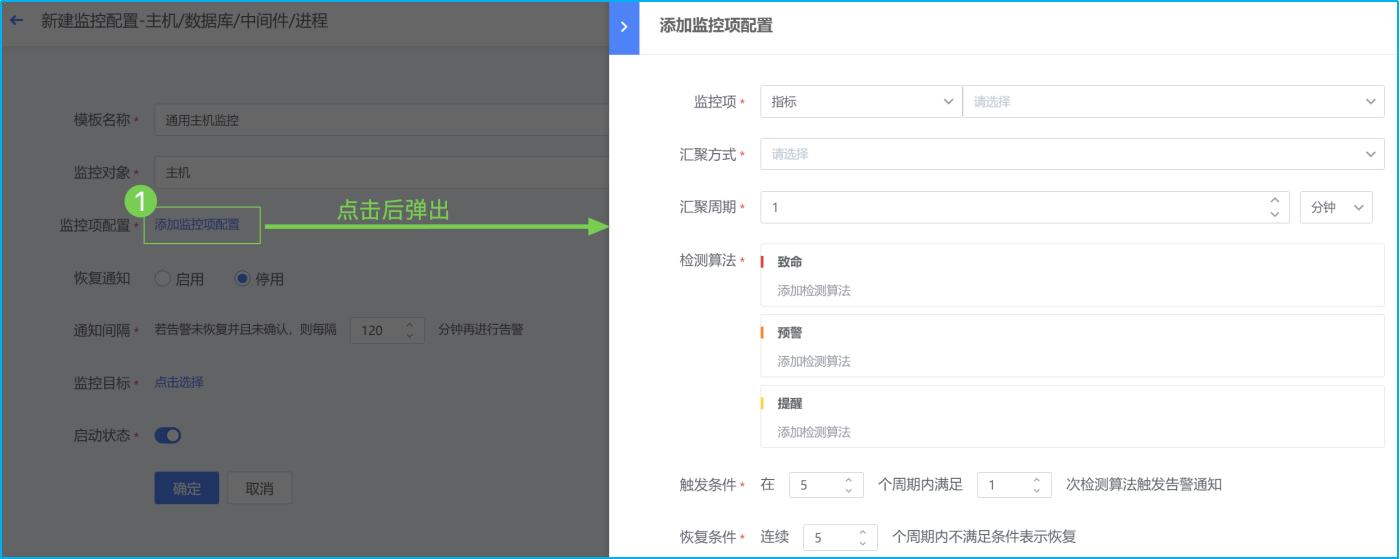
- 若下图所示,选择监控项为指标类,搜索监控项

- 选择汇聚方式为平均数,即AVG方式。SUM代表总数,AVG代表平均数,MAX代表最大值,MIN代表最小值,COUNT代表计数/总数。
- 选择汇聚周期,汇聚周期即采集数据的周期。(注:汇聚1min即是服务端每分钟向Agent采集1次数据。若是汇聚周期设置为5min则表示服务端向Agent每5分钟采集1次数据,此刻的Agent已经采集到了5次数据。之后,并根据汇聚方式将这5个数据进行计算(AVG/MAX/MIN等),计算得出的数值再于检测算法设置的阈值进行比较。)
- 如下图所示,点击蓝色字体添加检测算法,进行不同监控等级阈值的设置。以下示例采用检测静态阈值触发告警。此外还有高级的阈值检测方式可选择:各种同比/环比策略。
- 如下图所示,进行“触发条件”、“恢复条件”、“无数据告警”、“监控纬度”以及“监控条件”的设置。
- 如下图所示,对监控项进行一一添加后再进行其他配置即可完成通用监控项模板。
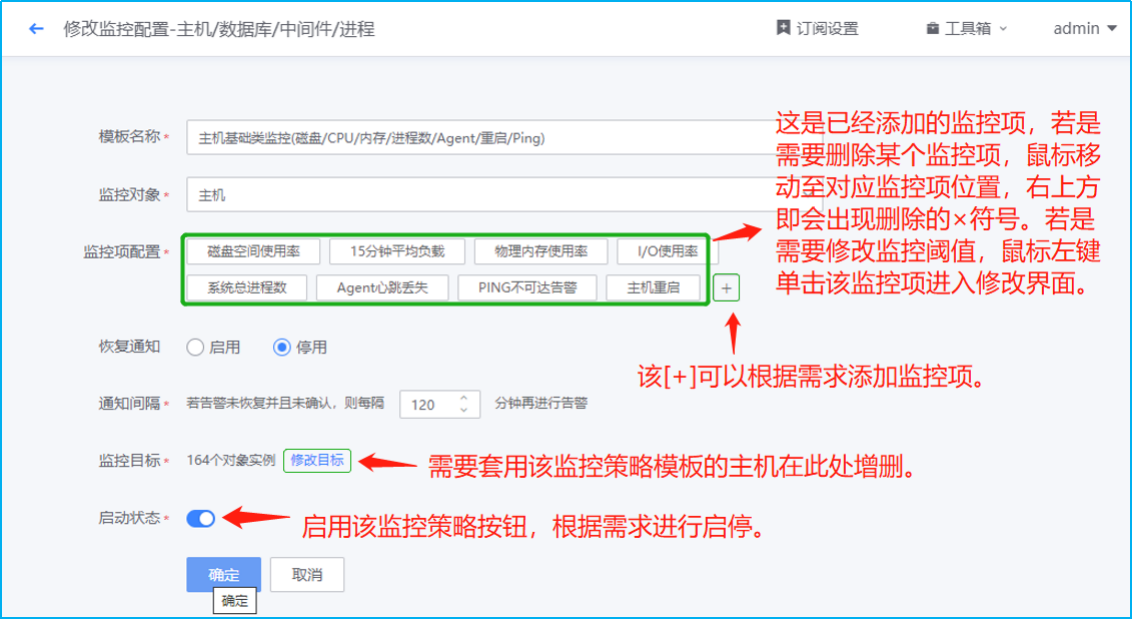
Step3:告警人员通知配置
- 如下图,进入通知配置界面,选择对应的用户,点击“配置”按钮,可以进行通知方式的配置,可选“邮件、短信、微信、电话”等形式
Step4:接收告警信息(以邮件为例)
路径:个人邮箱
- 发生告警时,邮箱接受到告警信息,如下图,包括告警的内容、对象、时间、业务等信息,便于快速感知告警。

Step5:告警详情查看
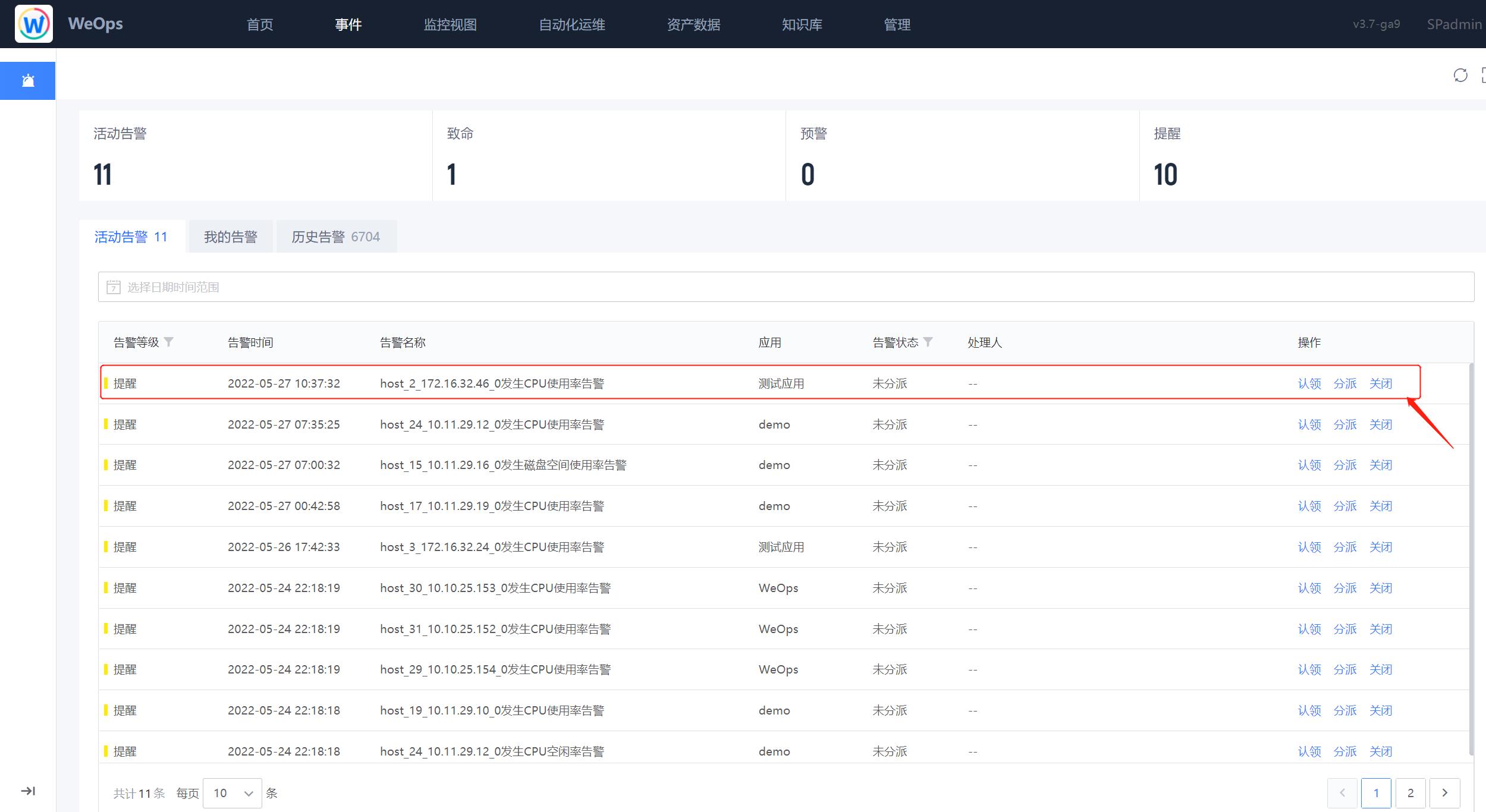
路径:事件-告警-活动告警
- 如下图,前往告警的活动告警中,可以找到该条关于CPU内存的告警信息。
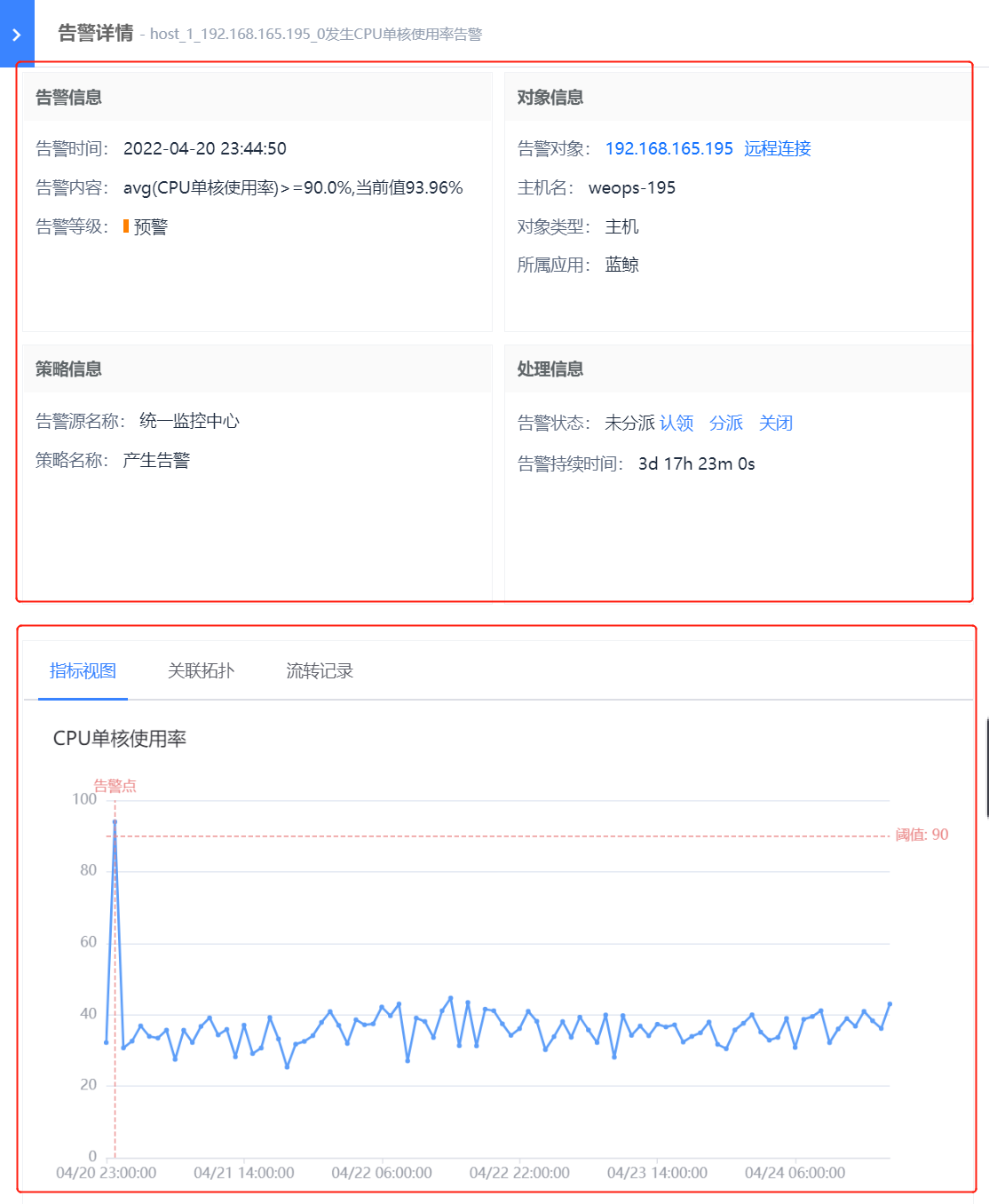
如下图,点击告警,可以进入告警的详情页,进行告警信息的查看,通过基础信息、指标视图等信息,可以断定告警发生的对象、时间、影响等,比如该条告警,是蓝鲸应用下一台主机的cpu单核使用率过高,设定的告警值为90%,目前该主机的CPU单核使用率已经达到了94%。
可以通过指标视图和关联拓扑,可以分析告警的影响范围和产生的原因。

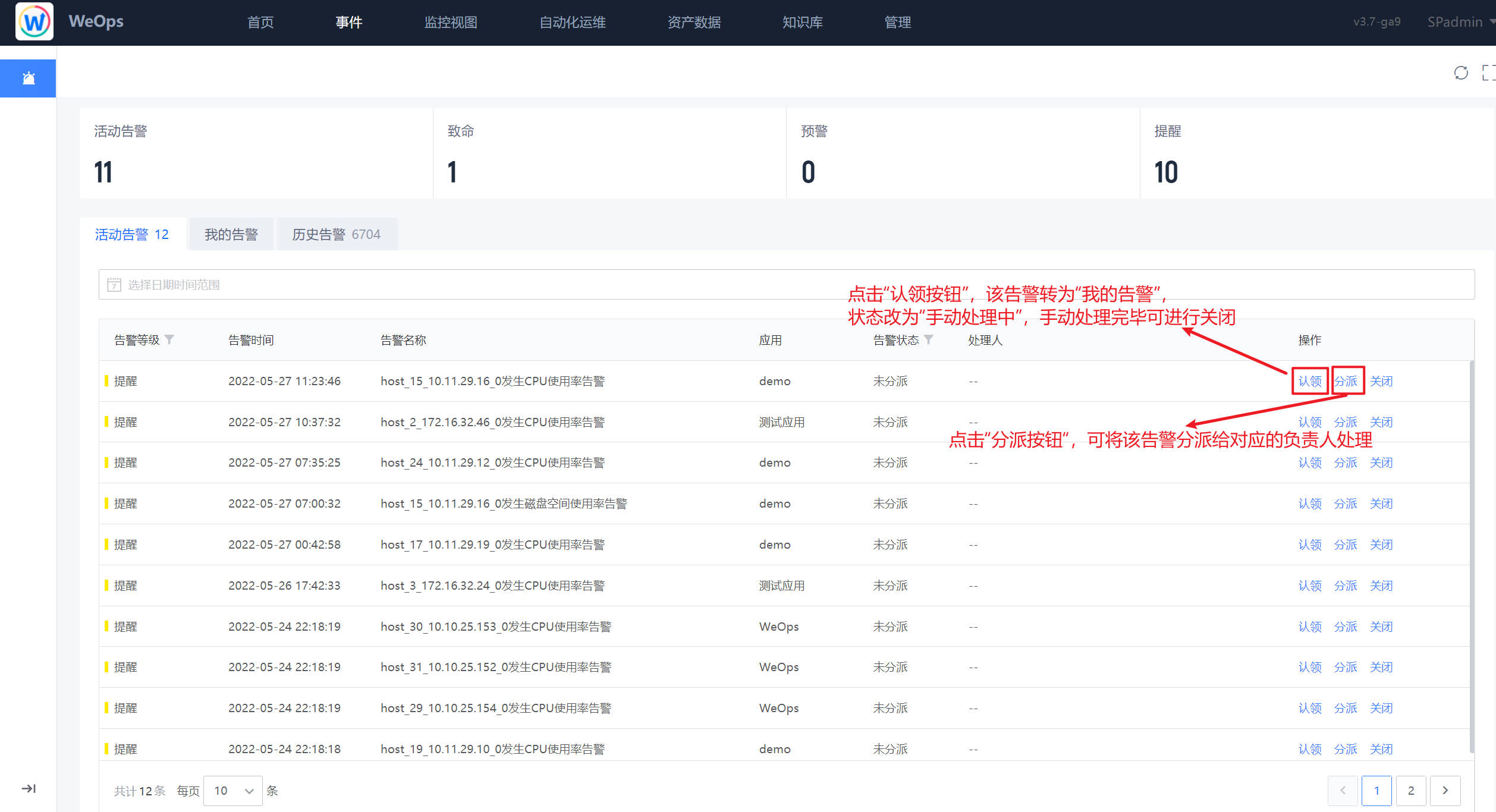
Step6:告警分派/认领
路径:事件-告警-活动告警
- 对于告警的处理,可以进行认领和分派,点击认领按钮,可以对告警进行自行认领,认领的告警项会进入到“我的告警”,状态改变为“手动处理中”待处理完成后,可关闭告警; 点击分派按钮,可以对告警进行指定用户的分派。
- 这里我们选择自行认领该告警,告警进行手动处理阶段,在故障处理完成后可以自动/手动关闭。
Step7:故障处理
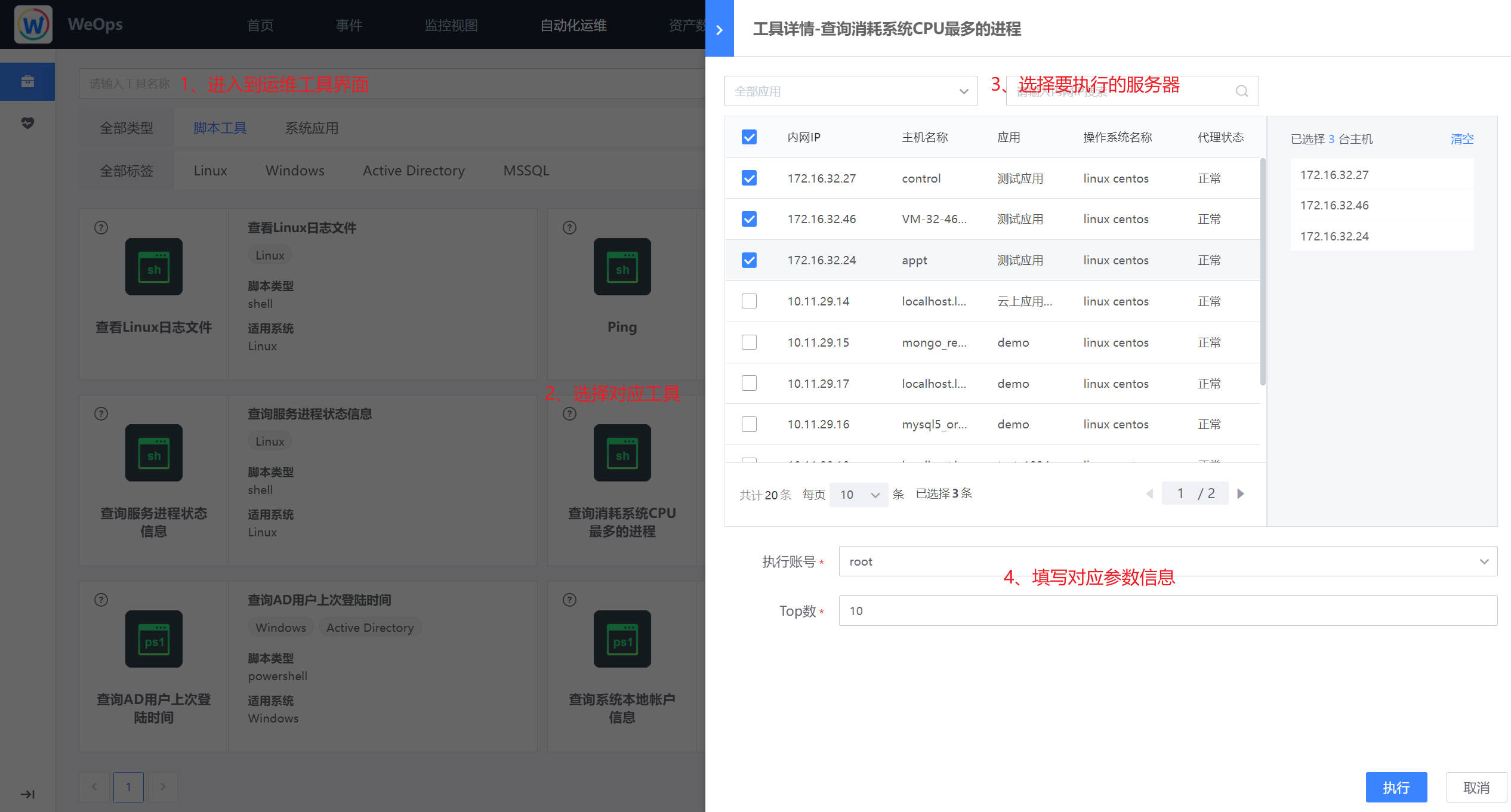
路径:运维工具-脚本工具-查询消耗系统CPU最多的进程
- 针对上述告警关于CPU单核使用率过高的故障,需要进行故障处理,需要查看该台主机的CPU使用情况,可利用“运维工具-脚本工具-查询消耗系统CPU最多的进程”进行。
- 点击进入脚本工具的执行页面,选择有故障的主机,填写展示top20的进程
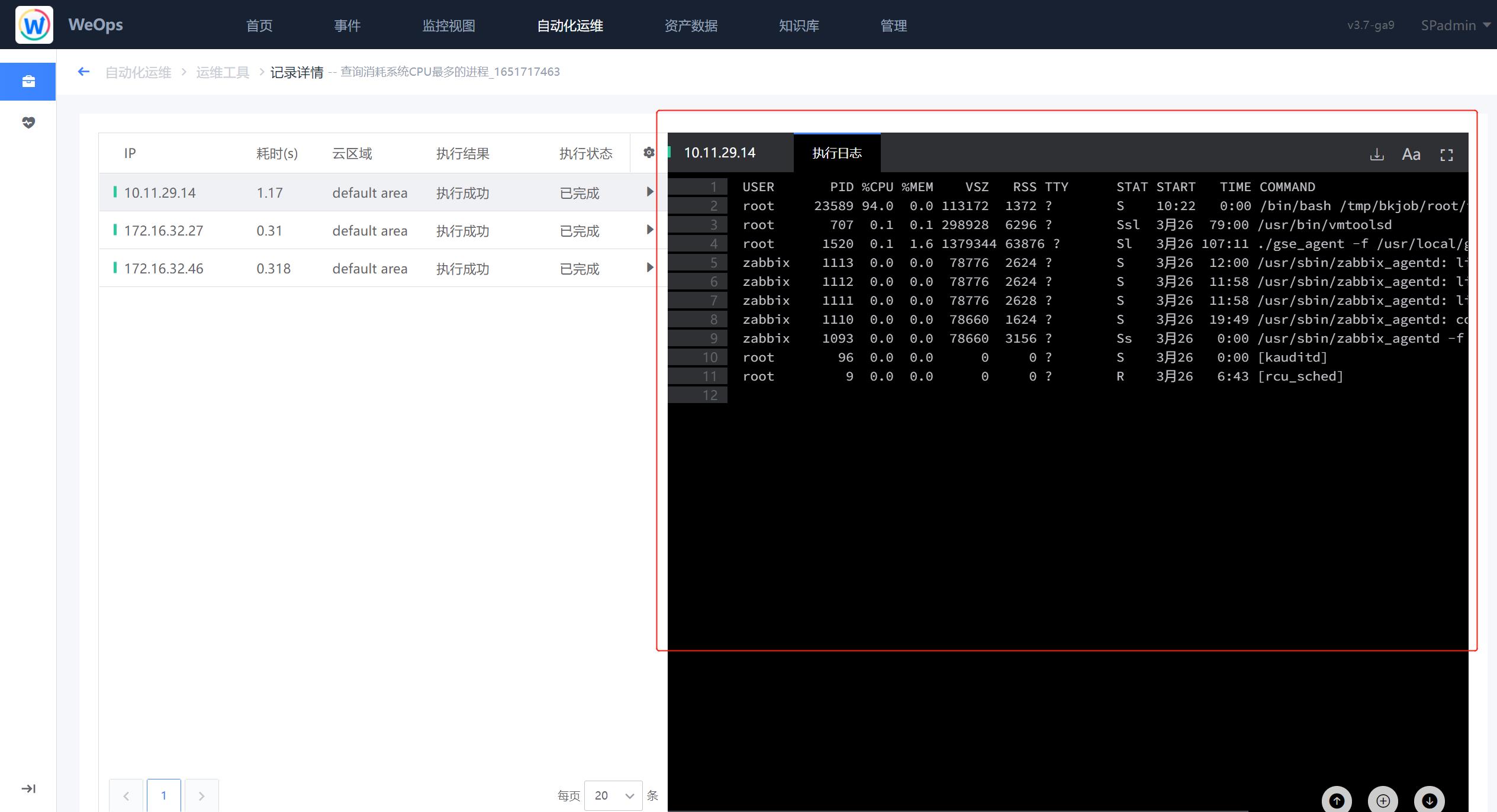
- 执行完成后,可以在结果界面,查看消耗cpu最多的top20的进行,可进行判断进行处理。
Step8:告警关闭
故障消除后,该条告警将会自动关闭,也可进行手动关闭。
场景二 如何进行应用故障的处理
场景介绍
某公司IT部门内部明文规定,作为业务管理员在收到相关业务的报障后,需要尽快进行问题的排查和处理,保证各应用的正常运行。
场景实现
路径:WeOps-应用
Step1:接收报障
- 应用管理员接收到同事的报障:今天上午9点左右,蓝鲸环境访问速度过慢,需要紧急修复。
Step2:查看网站视图
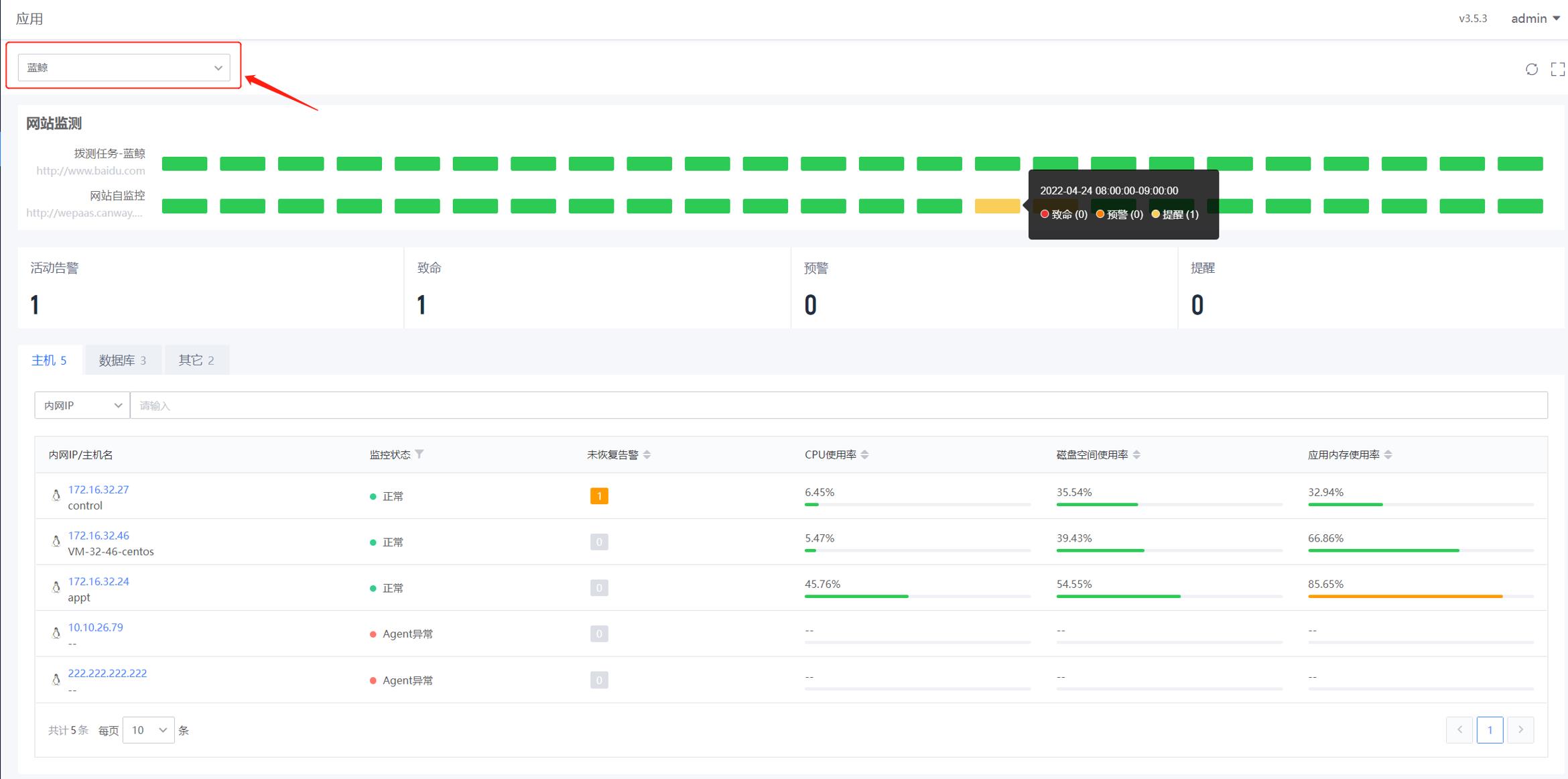
登录WeOps,进入应用界面,切换至“蓝鲸”应用。在页面上方的网站监测部分,可以看出在8::0-10:00直接该网站的发生了告警事件,点击可查看该段时间的网站的使用率和响应时长视图,通过视图可以看出,该时间段响应时长过长。

Step3:分析故障产生原因
协助分析1:在应用界面的中部展示与该应用所有相关的告警信息,可点击查看告警列表,查询与该故障前后发生的告警协助分析。

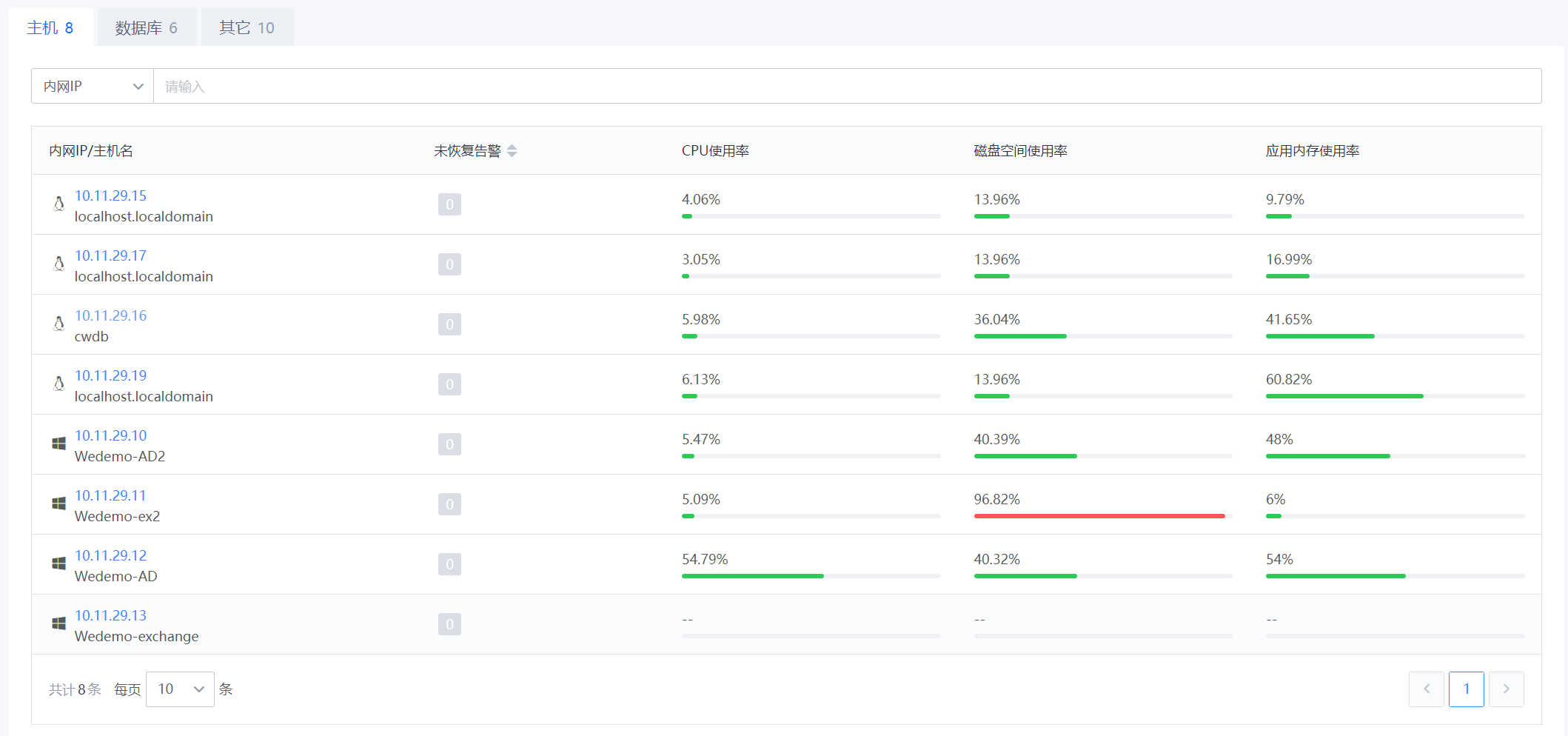
协助分析2:在应用界面的下方展示了该应用下的主机、数据库、其他资源的基本信息,CPU磁盘使用率、磁盘空间使用率、应用内存使用率等信息,可以帮助排查故障出现的原因。
Step4:进行故障处理
根据上述步骤,已经排查出故障出现的原因,同“场景一”可以使用运维工具进行故障的处理。
场景三 如何进行资源的日常检查
场景介绍
某公司IT部门内部明文规定,为了保证业务系统的正常运行,运维每天早上上班后需要对负责的IT运维对象进行整体情况的熟悉,对于出现的问题可以提前预判,避免故障发生。
场景实现
Step1:查看告警情况
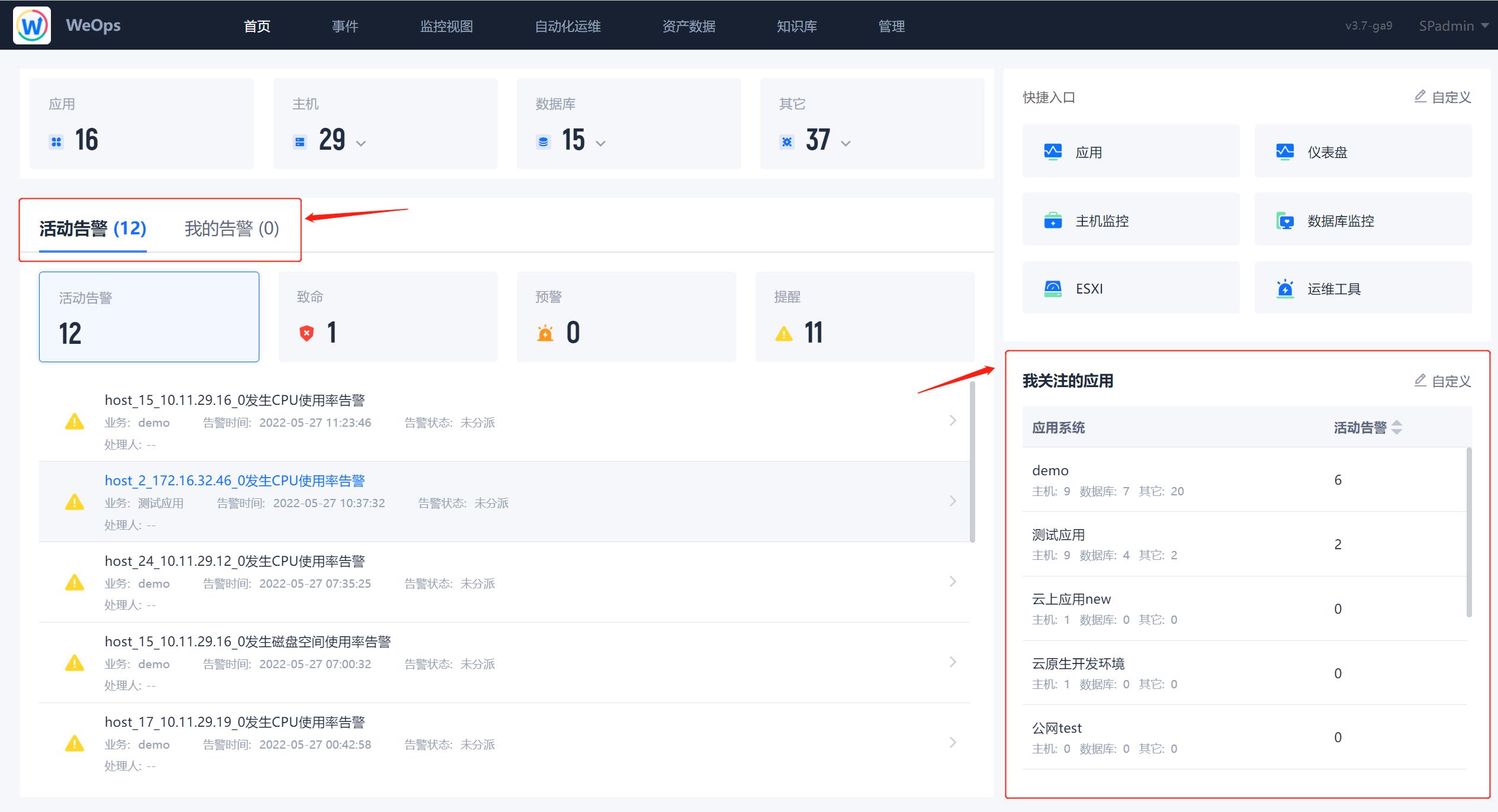
路径:WeOps-首页
- 登录WeOps,进入首页,在首页中可以查看目前出现暂未处理的告警列表,也可以查看自己关注的应用的告警汇总数量,从整体上感知系统的整体状态。
Step2:查看监控状态
路径:监控视图-应用/基础监控/网站监测
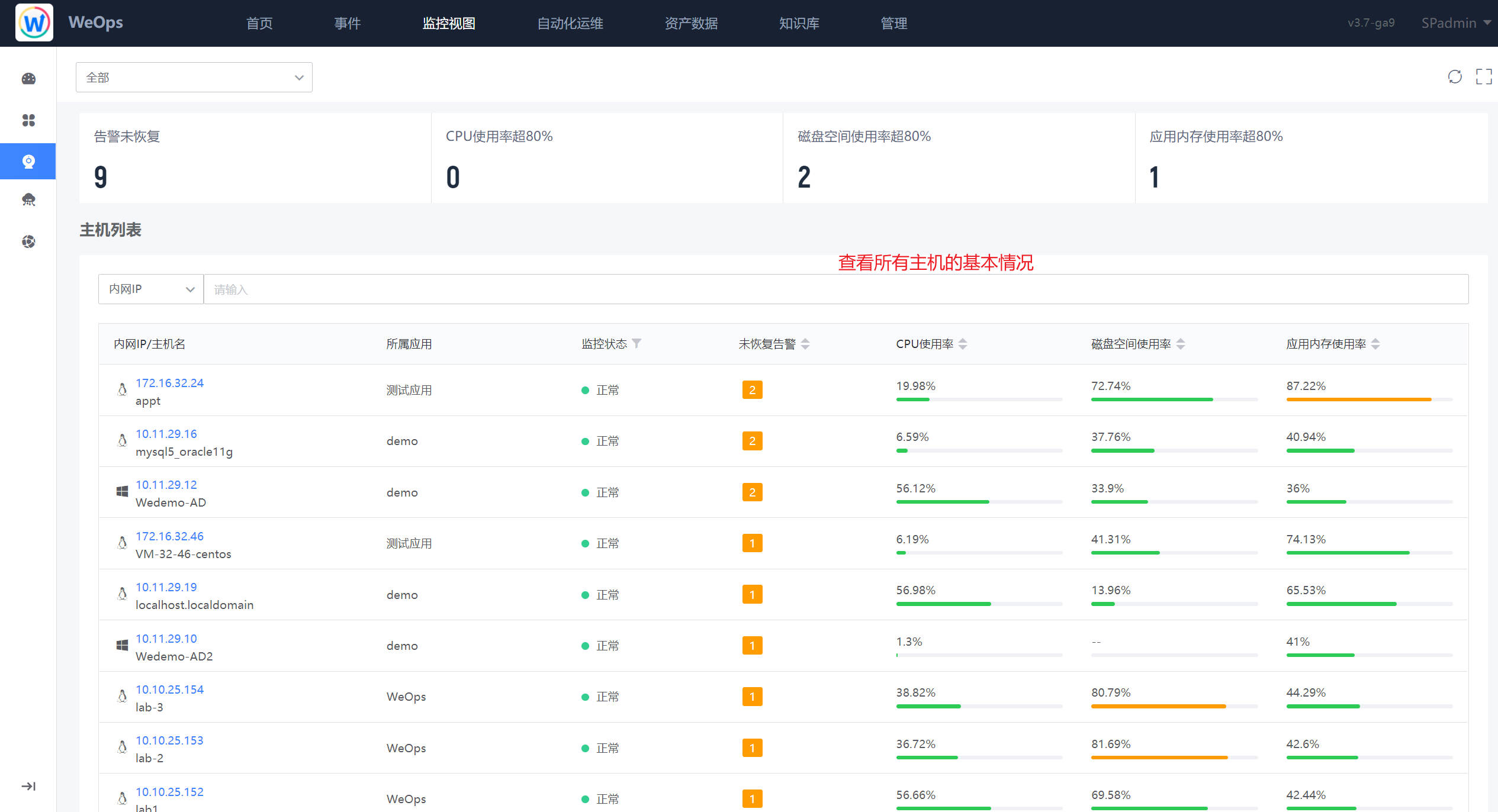
- 进入“应用”界面,从该应用的网站监测、告警情况、实例状态等方面,进行该应用的检查。

- 进入“基础监控”界面,将IT对象分为主机、数据库、中间件等分类进行不同实例的告警状态、监控状态的检查。
- 进入“网站监测”界面,对已经加入拨测的网站进行可用率、响应时间等方面的整体检查。

Step3:进行健康扫描
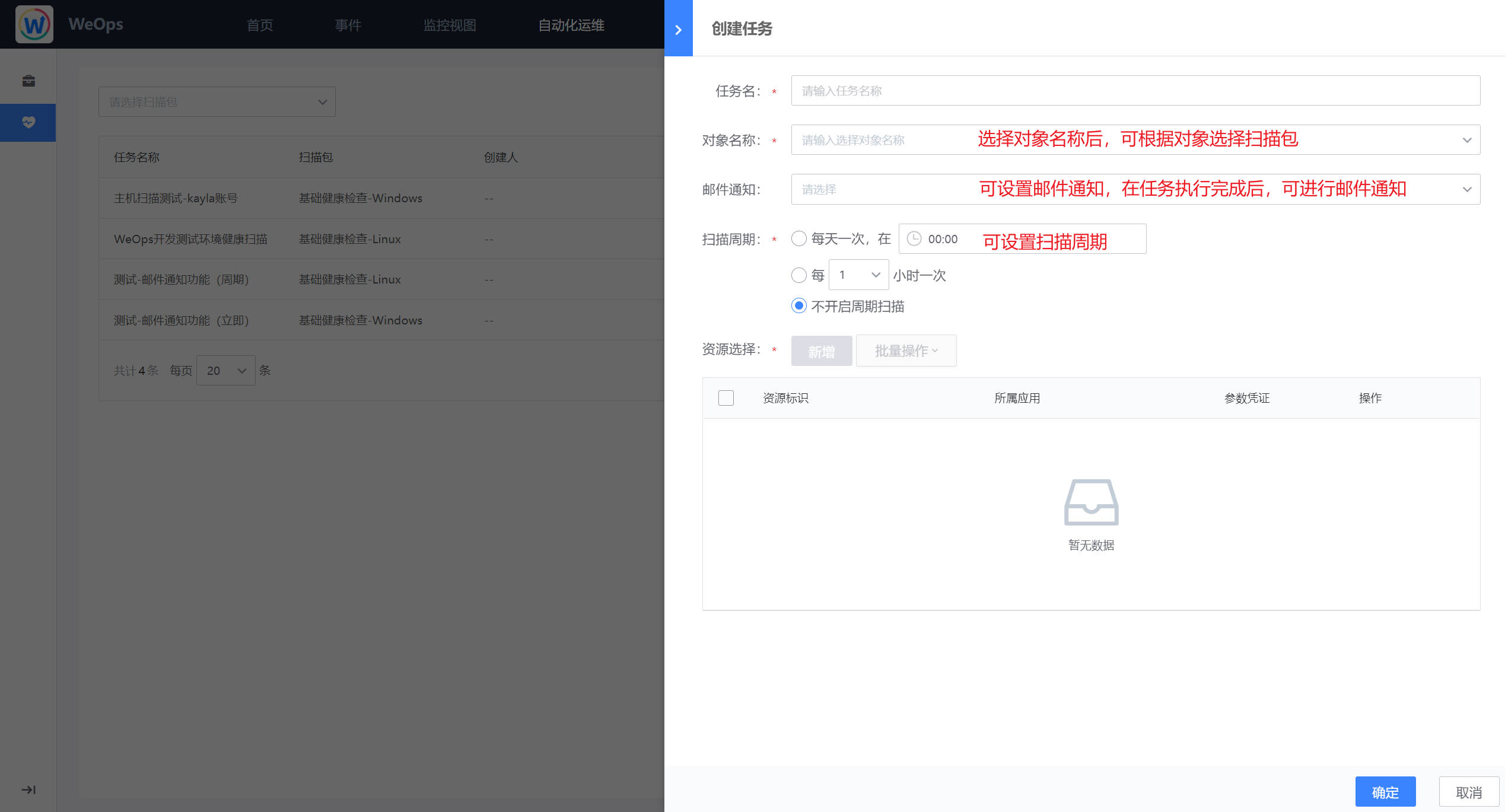
路径:健康扫描-扫描列表
- 如下图,在健康扫描中,新建扫描任务,填写基础信息、选择内置的扫描包和对应的资料。
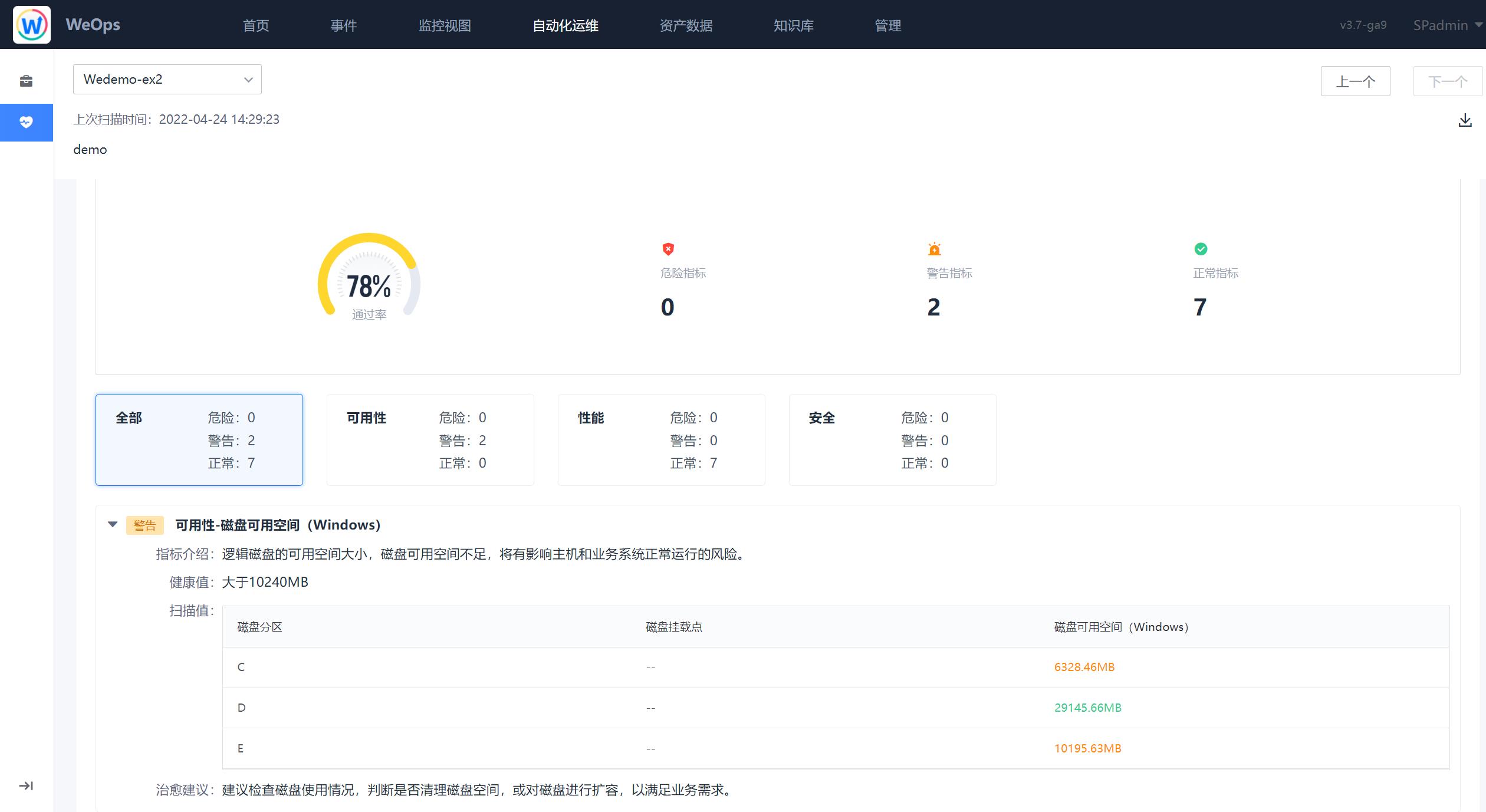
- 任务创建完成后,可执行“立即扫描”,扫描结束后如下图,在该任务下点击“详情按钮”,可以查看各个实例的扫描情况

- 点击“实例列表”后面的“详情”,可进入到该实例的详情业务,该实例的详情页面展示了实例的健康详情,具体见下图,对于警告/危险的指标予以关注,并进行处理,避免发生故障,影响系统的正常运行。
场景四 如何进行自动化运维(以Windows月度补丁安装为例)
场景介绍
某公司的安全部门要求,Windows服务器必须每个月按照要求进行对应的补丁安装,补丁来源于微软每月发布的月度补丁。
场景实现
Step1:下载/准备补丁文件
前往微软官网,下载对应月度的补丁。
Step2:创建补丁安装任务
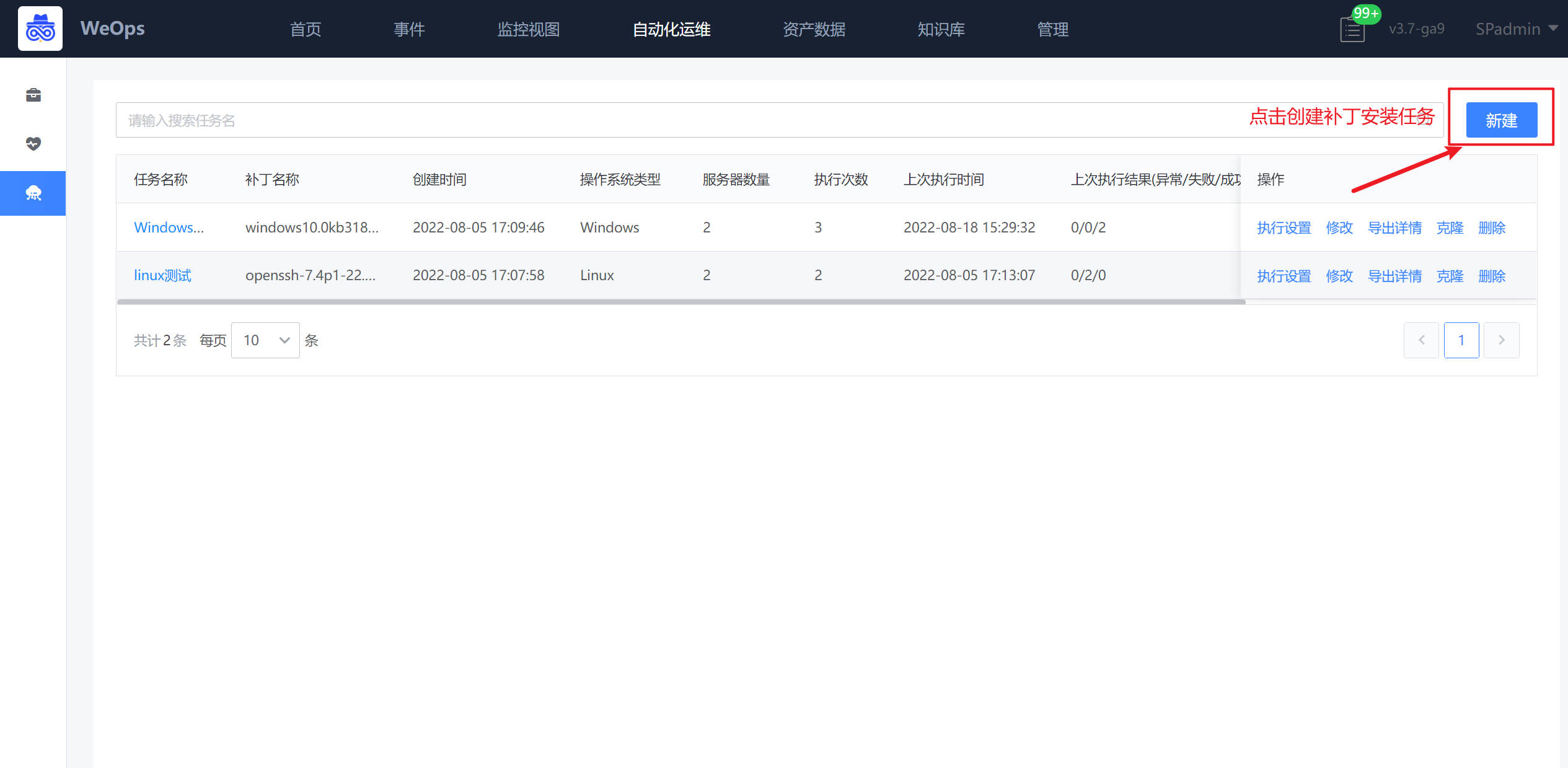
路径:自动化运维-补丁安装
点击WeOps自动化运维中的“补丁安装”进行补丁安装操作,点击“创建任务”进行补丁任务的新建。
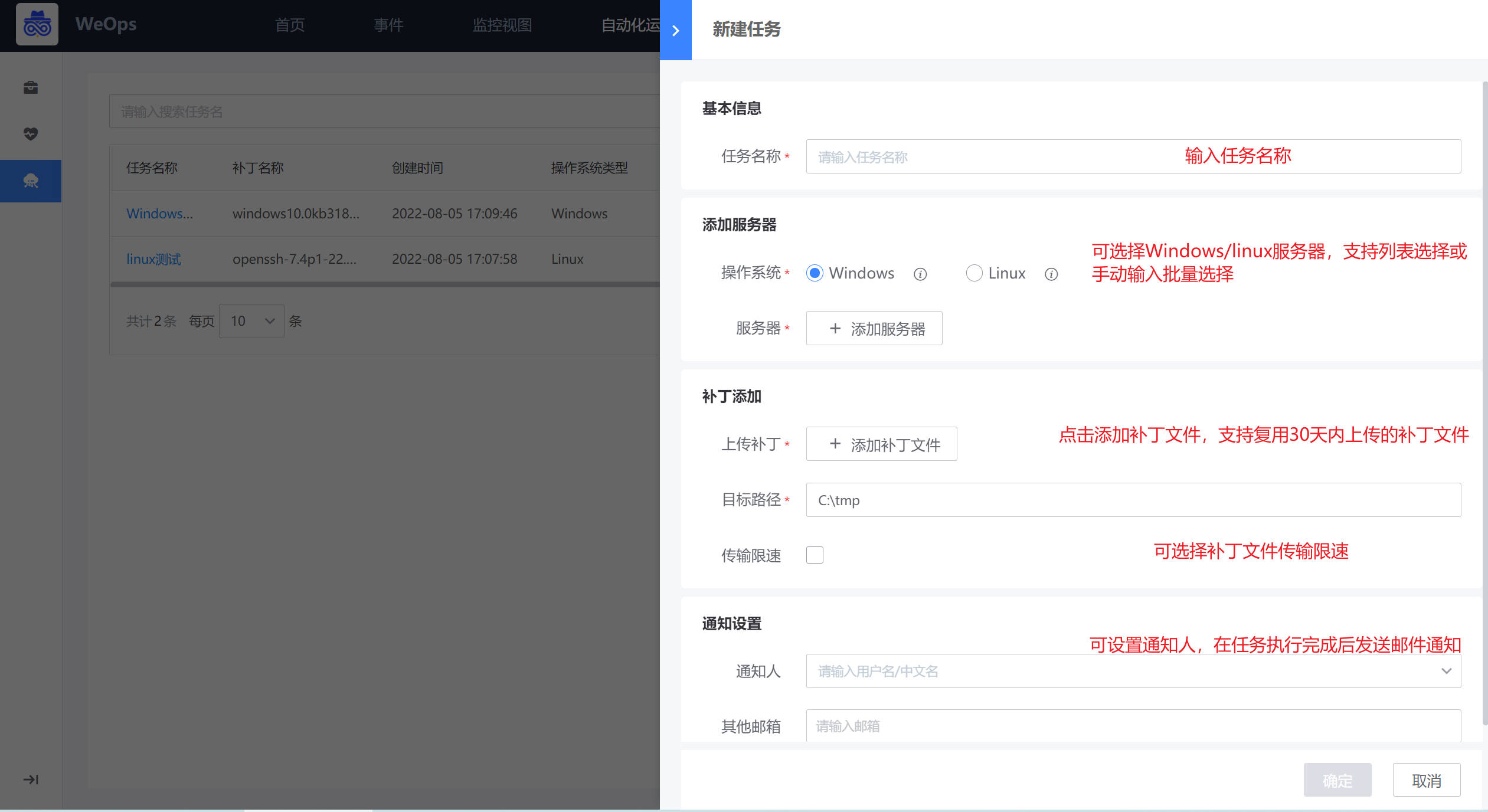
在任务新建界面,可选择Windows/linux两类操作系统,服务器支持跨业务多选,补丁文件支持本地上传/30天内上传的补丁文件复用,支持选择邮件通知人。
Step3:执行补丁安装
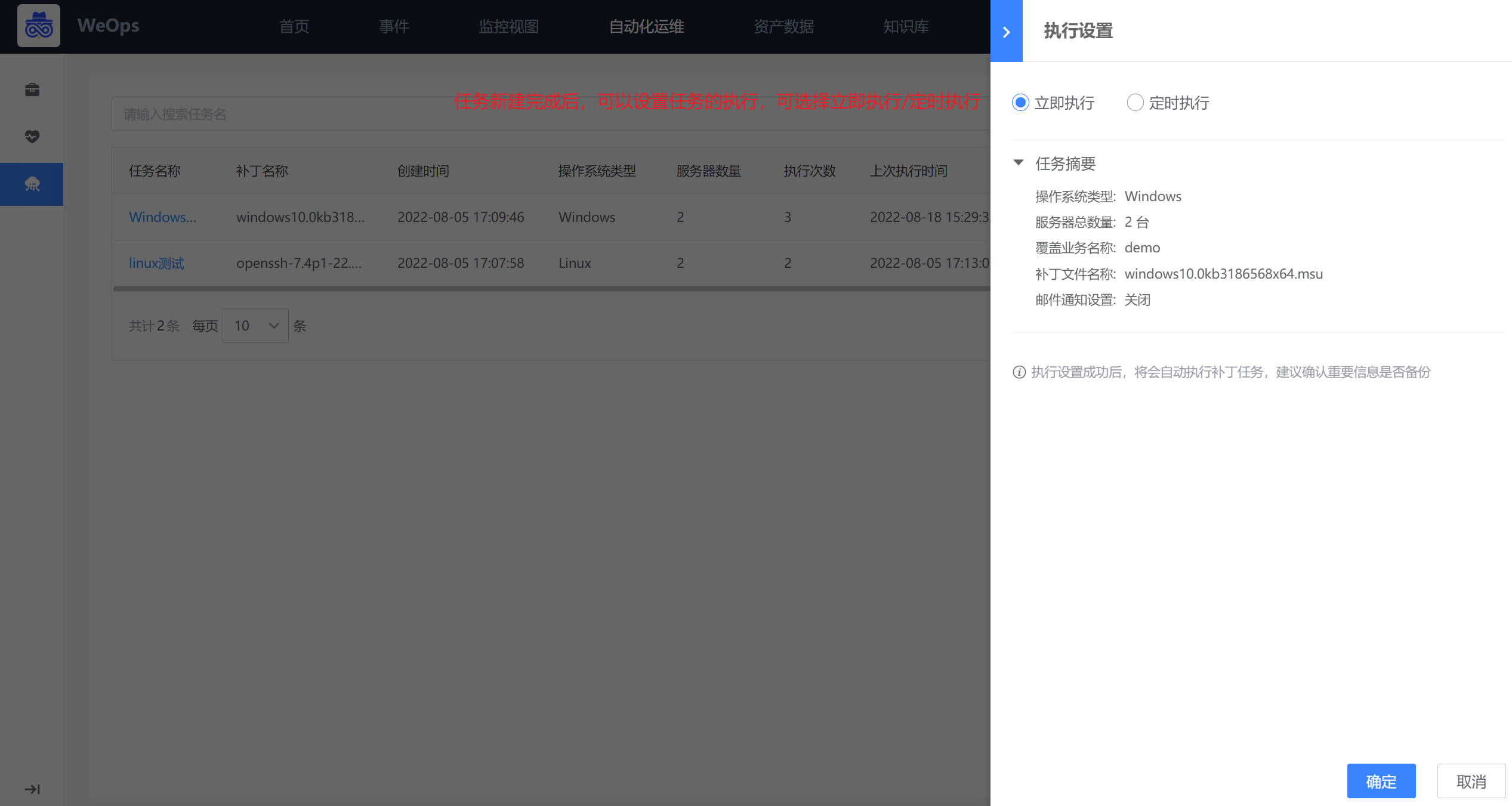
任务创建完成后,可以点击进行“立即执行”/“定时执行”
执行完成后,可以查看执行结果
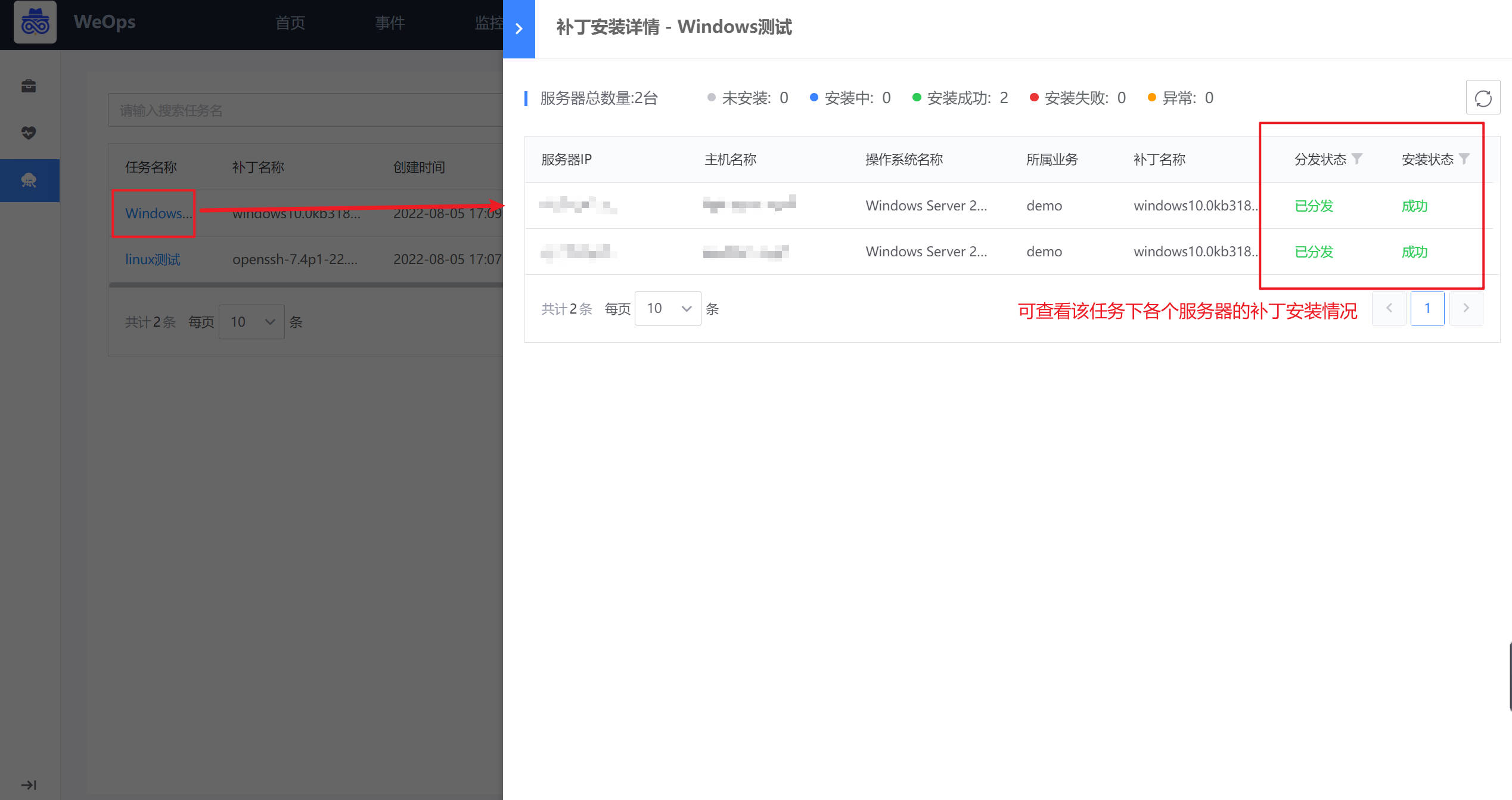
Step4:服务器重启
路径:运维工具-系统应用-作业平台
补丁安装任务执行完成后,针对需要重启的Windows服务器,可以通过作业平台进行批量服务器重启。
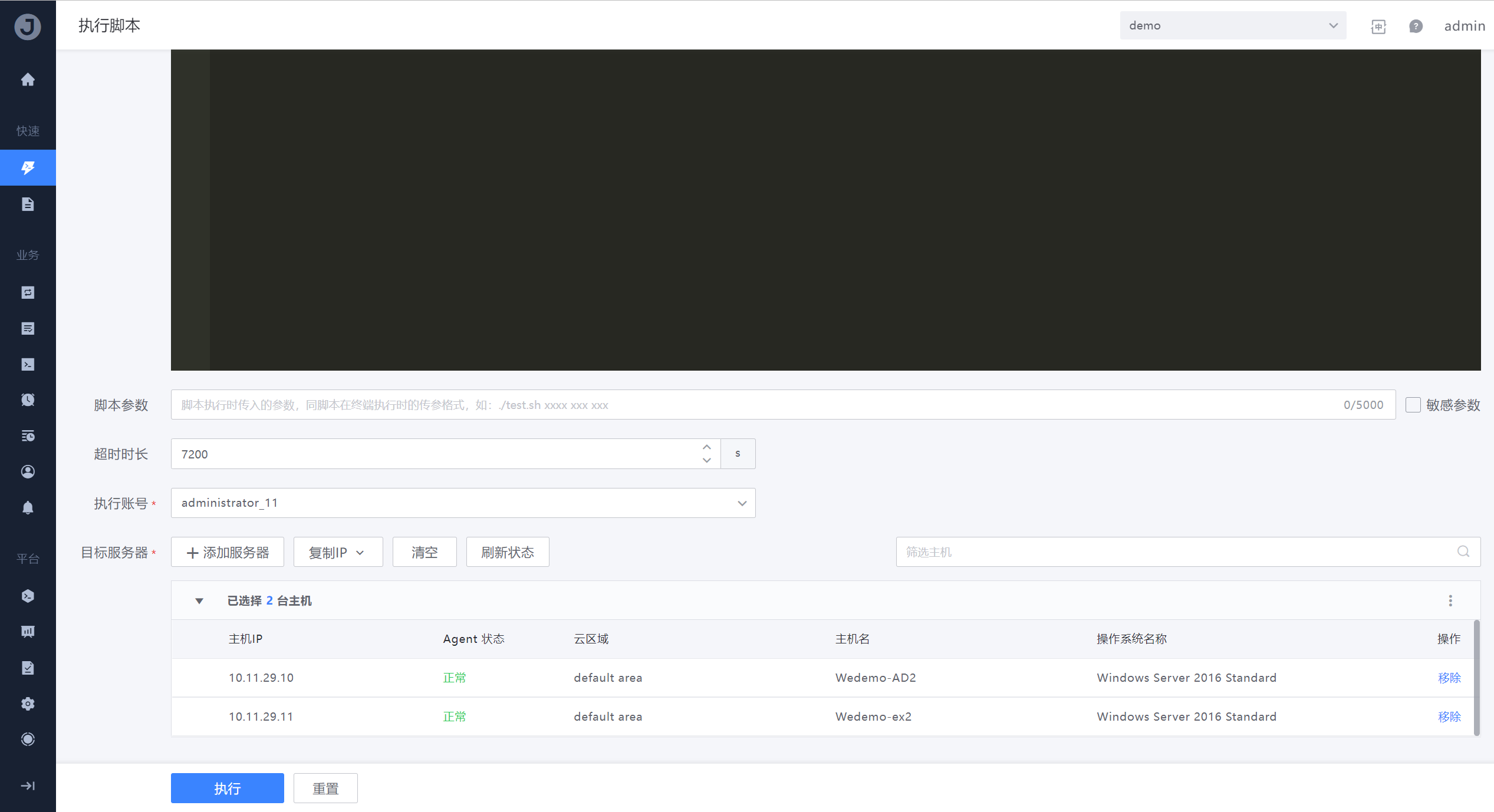
服务器重启完成后,补丁安装完毕。
场景五 如何进行IT资产的管理和维护
场景介绍
某公司原来对于IT资产信息的管理仍使用传统的表格进行人工手动维护,会造成资产记录完整性和及时性无法保证,资产盘点工作繁琐的问题。使用“WeOps-资源记录”模块可以实现资产信息管理自动化,拓扑展示可视化,资产盘点工作高效。
场景实现
Step1:资源纳管
对于应用、主机、数据库、中间件的纳管,可参见“1、资源纳管”的部分
Step2:应用资源信息查看
路径:管理-管理中心-应用列表
- 如下图,应用列表展示了所有的应用信息,点击“查看”按钮,可以进行该应用的详细信息查看,点击“查看拓扑”可进入到该应用的拓扑界面,进行拓扑的查看。
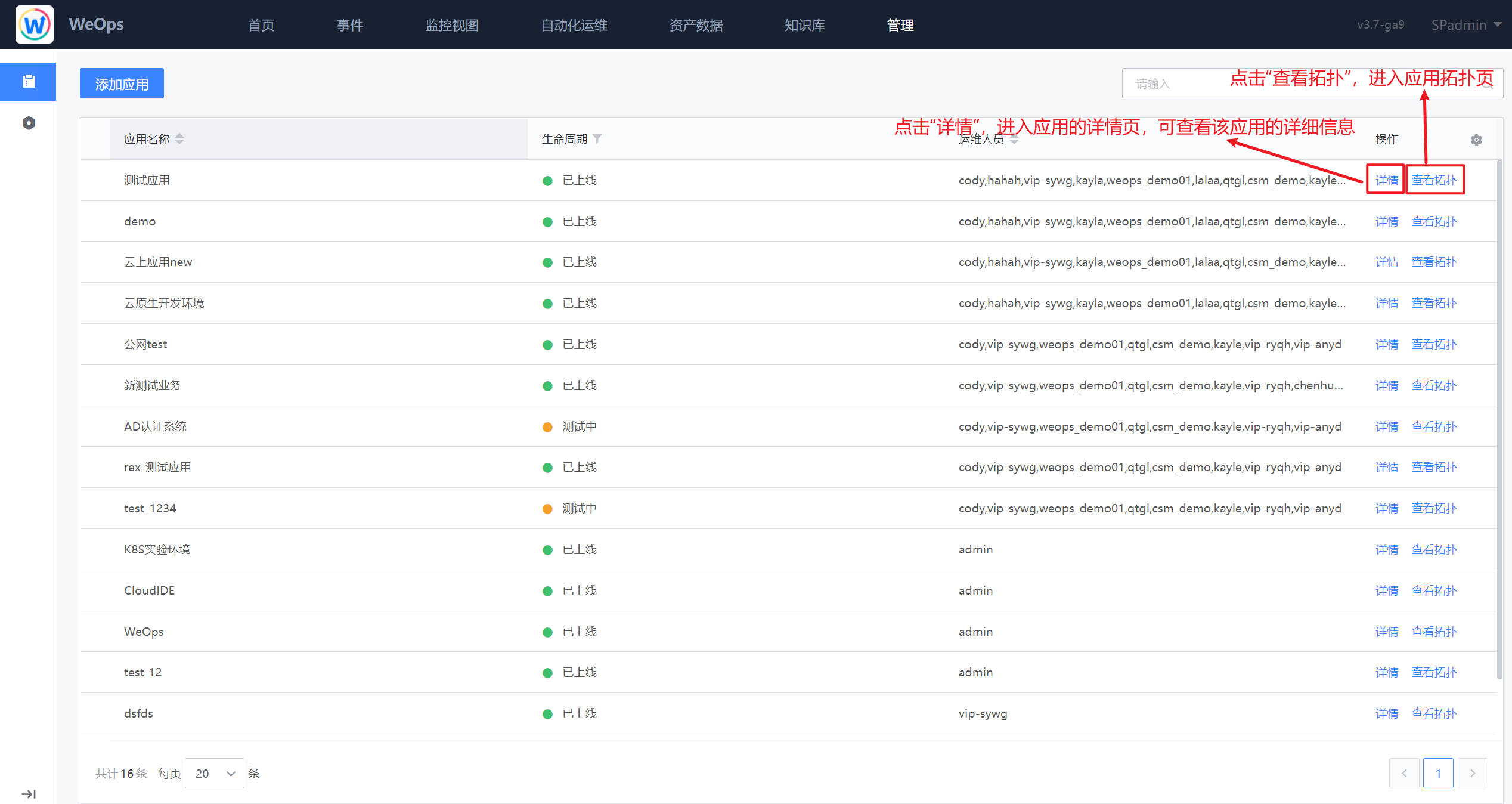
- 在应用列表页点击“查看”后,可进入该应用的详情页面,可以查看该应用的拓扑结构、变更记录、主机列表、节点信息。

- 在应用列表页点击“查看拓扑”后,可进入该应用的拓扑页面,可以查看该应用的拓扑图、以及拓扑图中的各个节点/实例的信息,具体详见下图

Step3:资源信息查看(以主机为例)
路径:资产数据-资源记录-主机
如下图,在资源列表中,可以查看所有主机的列表和信息,关联的数据库实例,可以进行主机资源的导出。
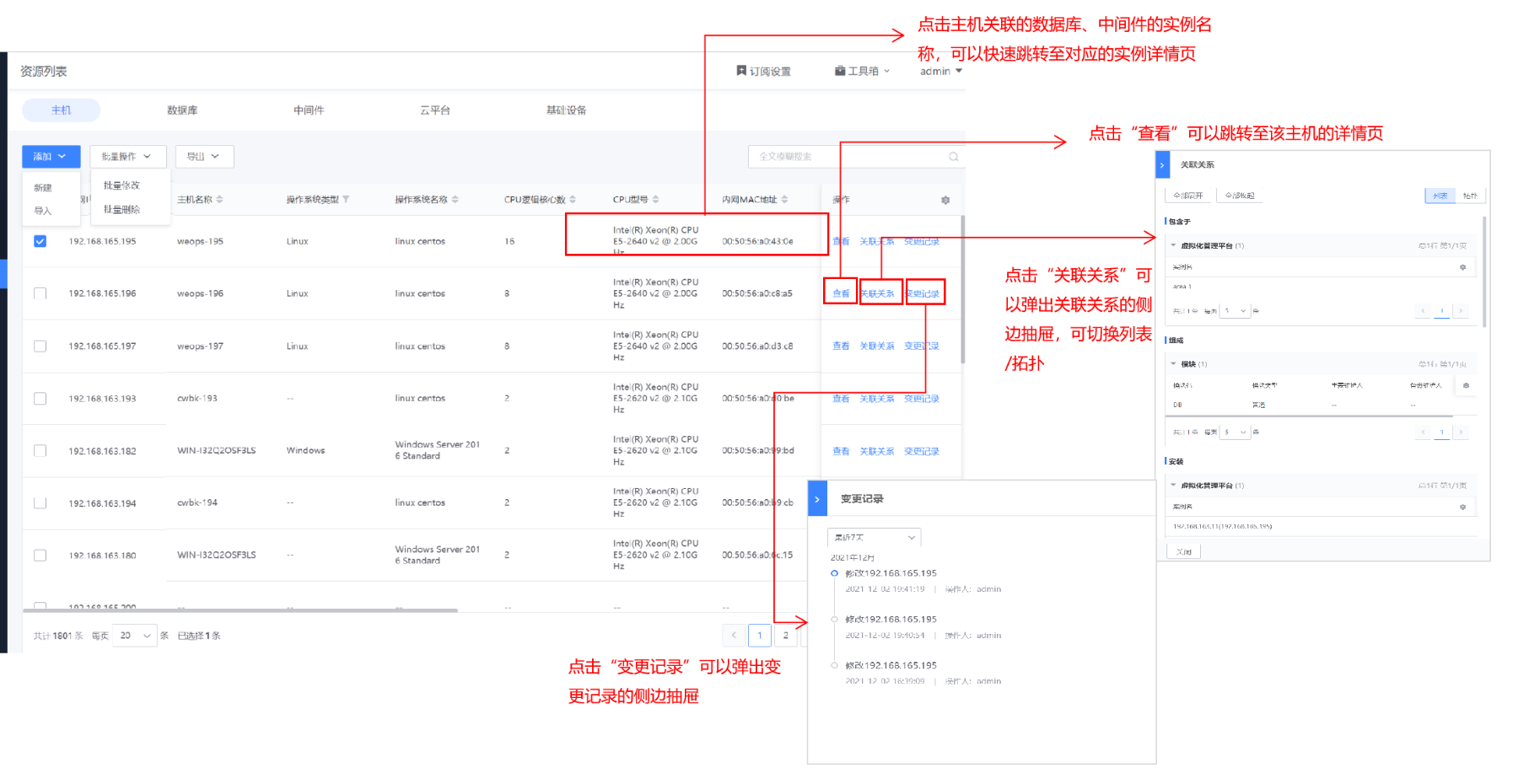
在资源列表中,点击“查看”按钮,跳转到该主机的详情页,详情页展示了主机的详细信息,以列表和拓扑的形式展示了主机的关联信息,以时间轴的形式展示了主机的变更记录。可以通过上述的形式获取主机的相关信息。

场景六 如何利用工单进行AD账号的自动创建
场景介绍
某公司之前AD账号创建需要运维人员接受到需求后,前往AD里面一个个手动创建账号,并把对应的账号密码信息反馈给申请人,可以使用WeOps的IT服务台进行AD账号创建的工单提交并且实行自动化创建。
场景实现
Step1:前提条件介绍
1、WeOps和AD的前期准备
- WeOps的APPT机器能通AD服务器的636端口,并且装了AD的根证书
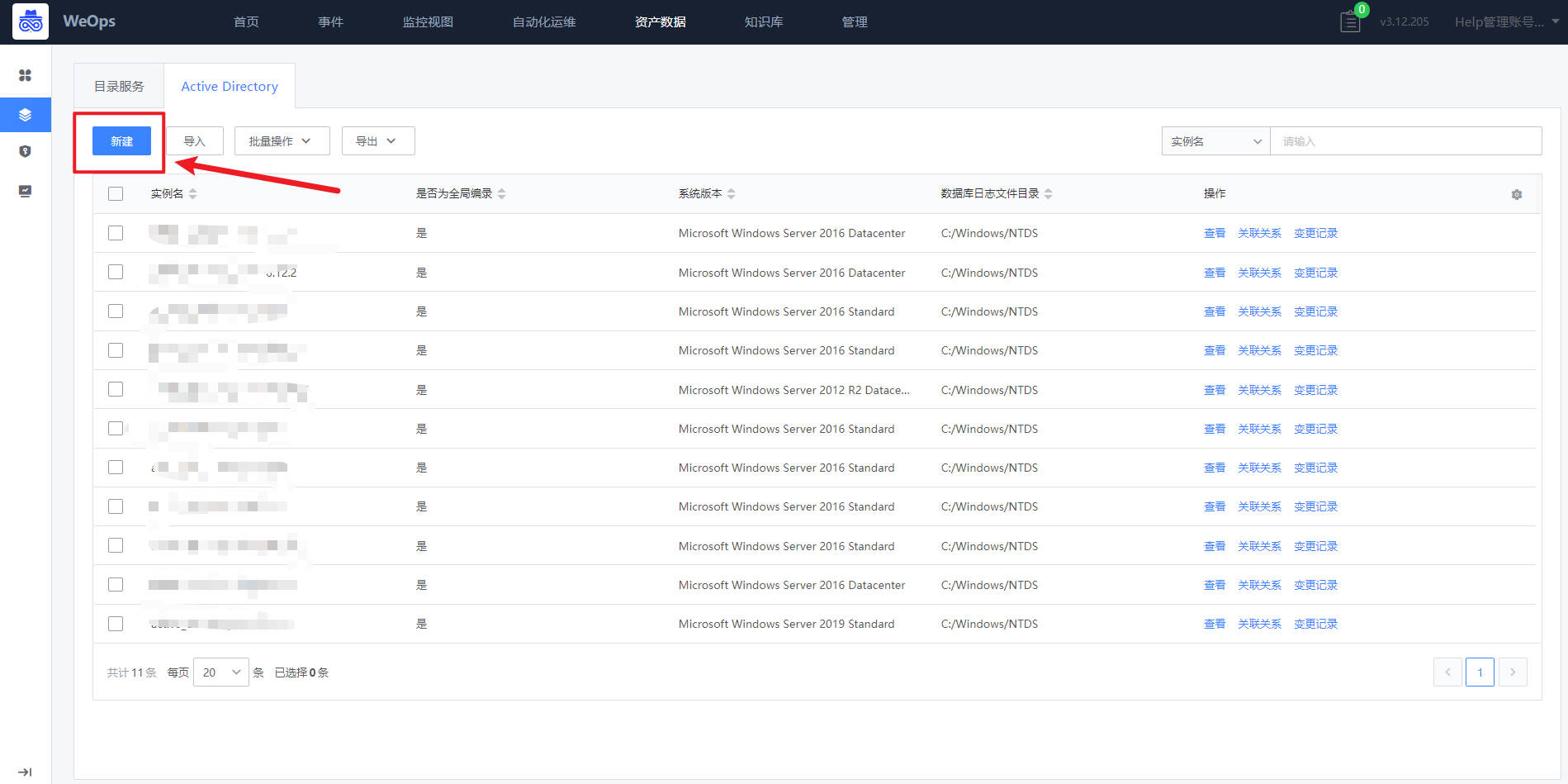
- WeOps中已经纳管所需要的AD服务器,如下图,在WeOps-资产数据-资产记录-AD中,对所需要的AD服务器进行纳管
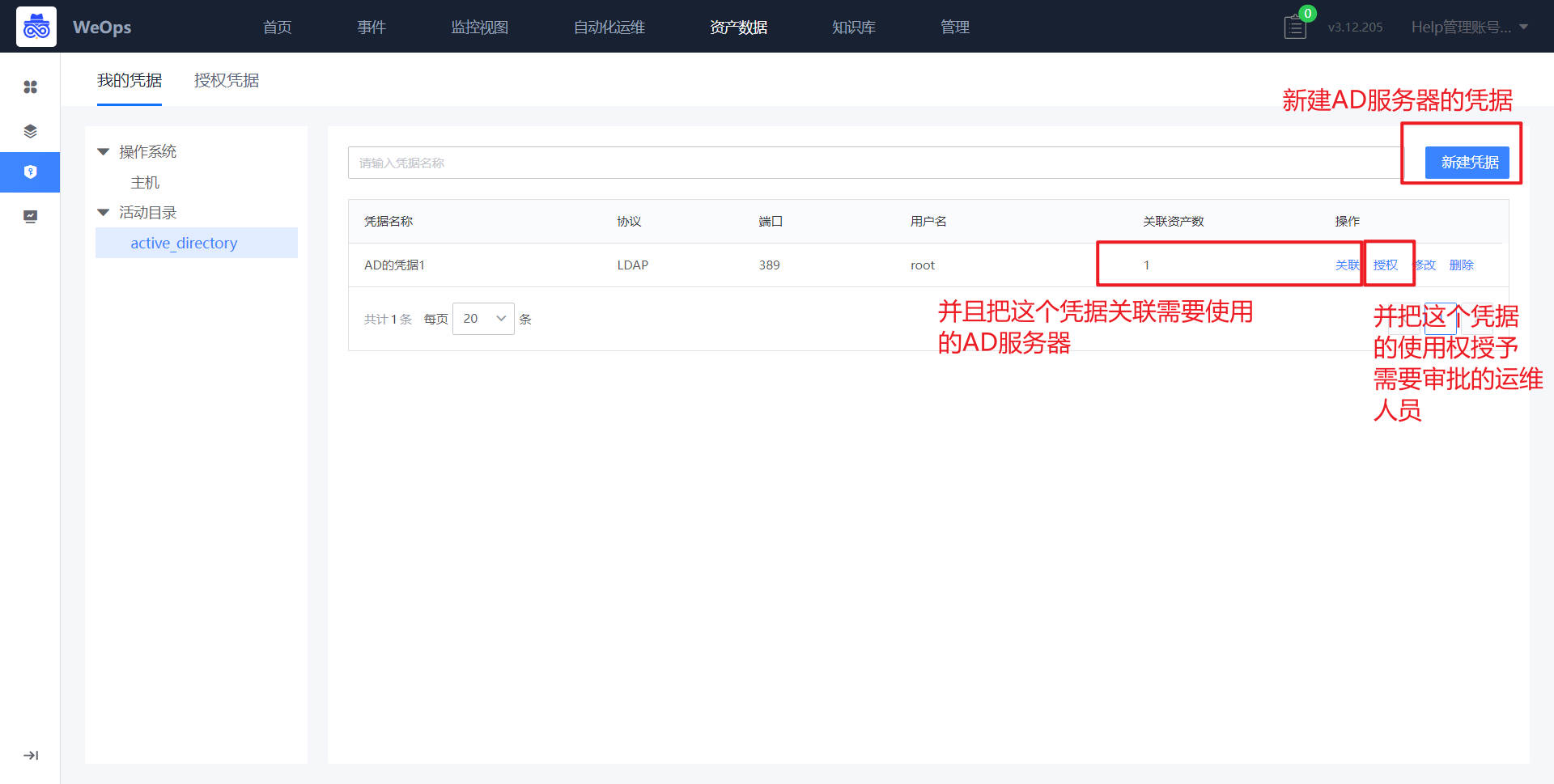
- AD服务器的凭据信息已经录入WeOps-凭据管理中,并且关联该AD服务器,并授权给对应需要审核的运维管理员
2、工单流程和自动化流程前期准备
- 在WeOps-管理-服务台管理导入工单流程
在WeOps后台管理-流程API配置中导入需要的API接口
在自动化流程中导入需要的自动化流程
Step2:对导入的流程进行重新配置
前期准备完成后,需要对流程进行重新配置,具体操作步骤可查看视频查看AD账号创建自动化流程的配置。
提单节点:用内置的不用调整
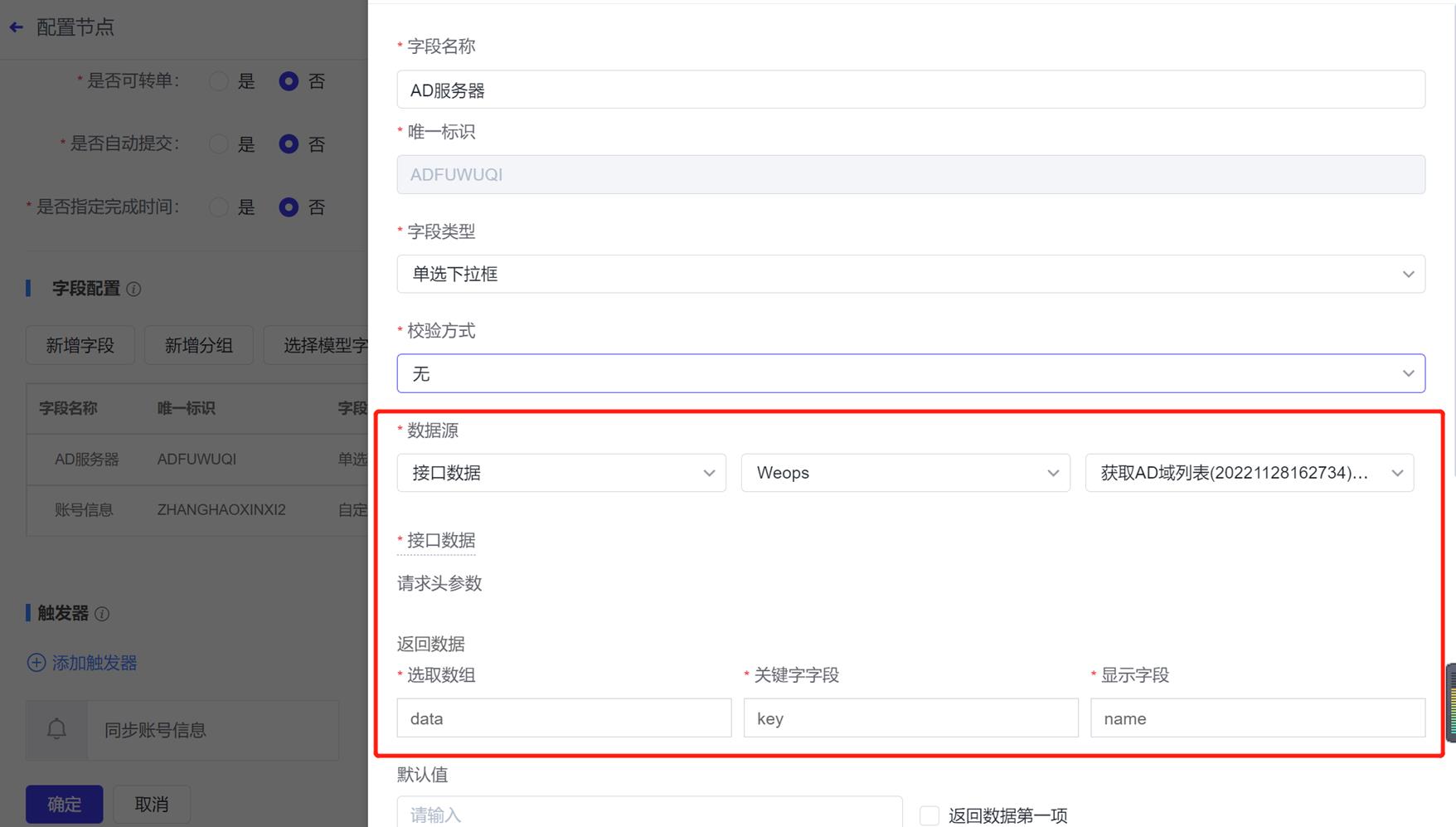
审批节点:AD服务器和AD组这两个字段需要重新选择接口
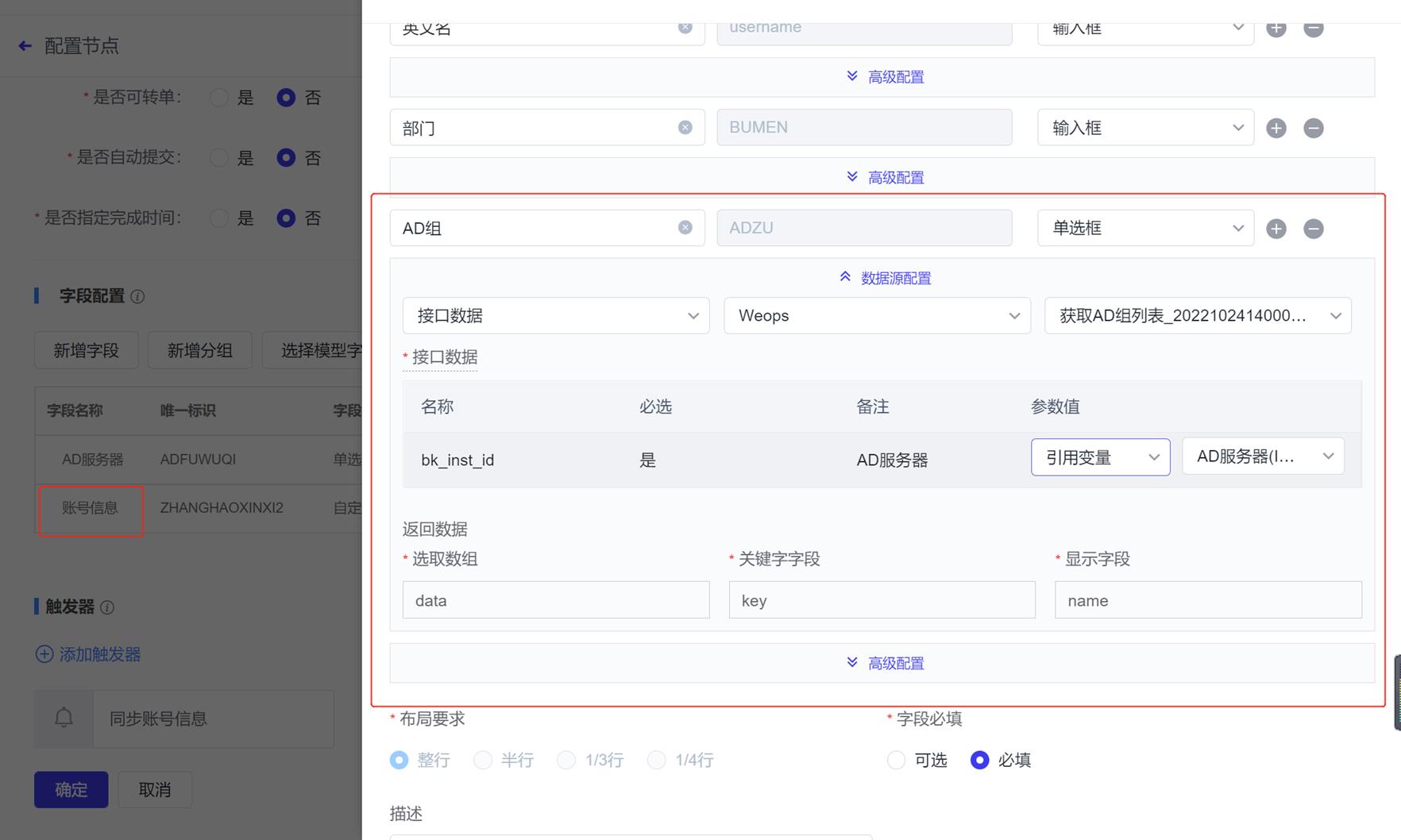
获取API详情节点:选择对应接口,下面的参数会自动勾选的
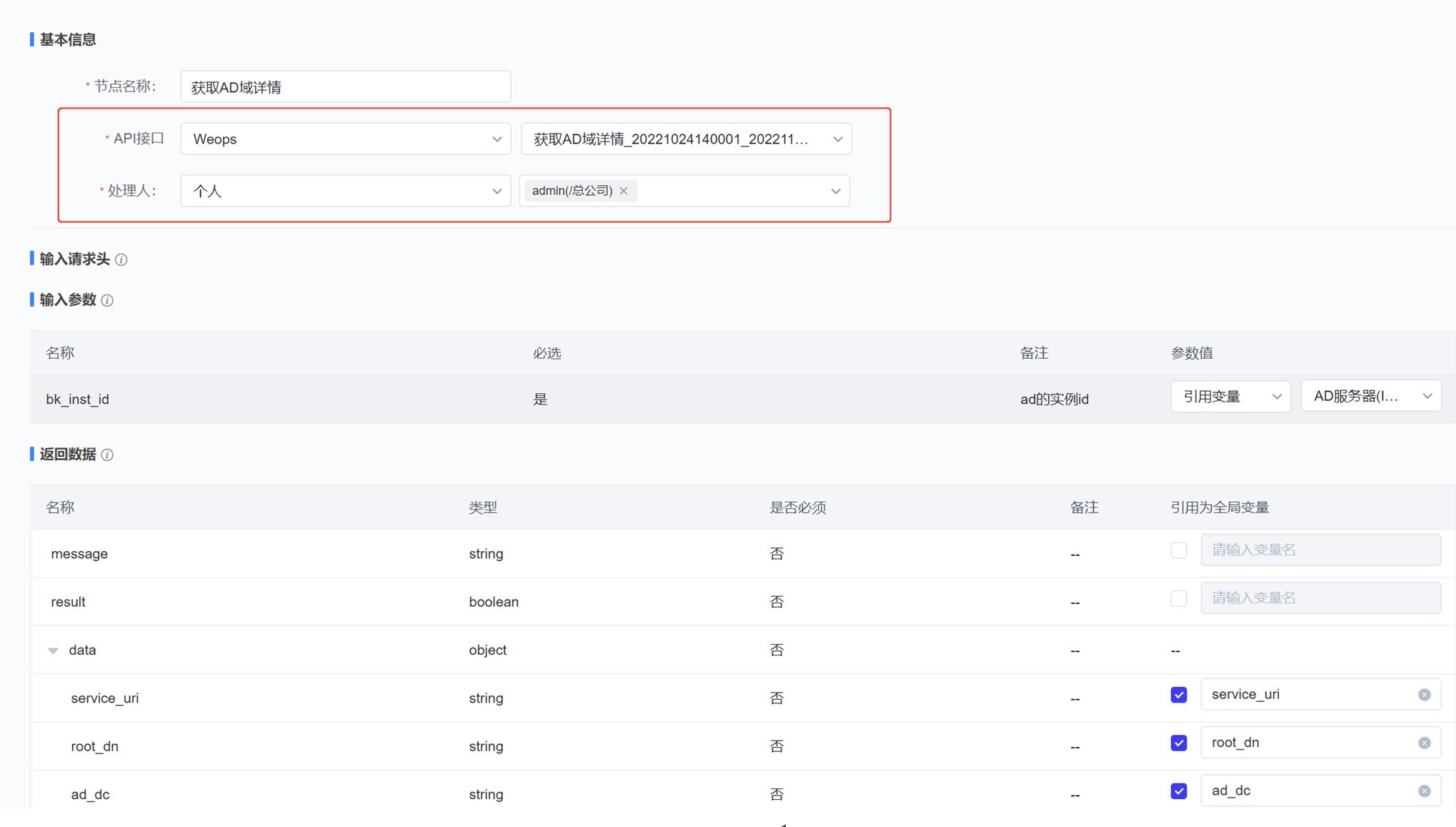
自动账号创建节点:选择需要的自动流程,填写参数
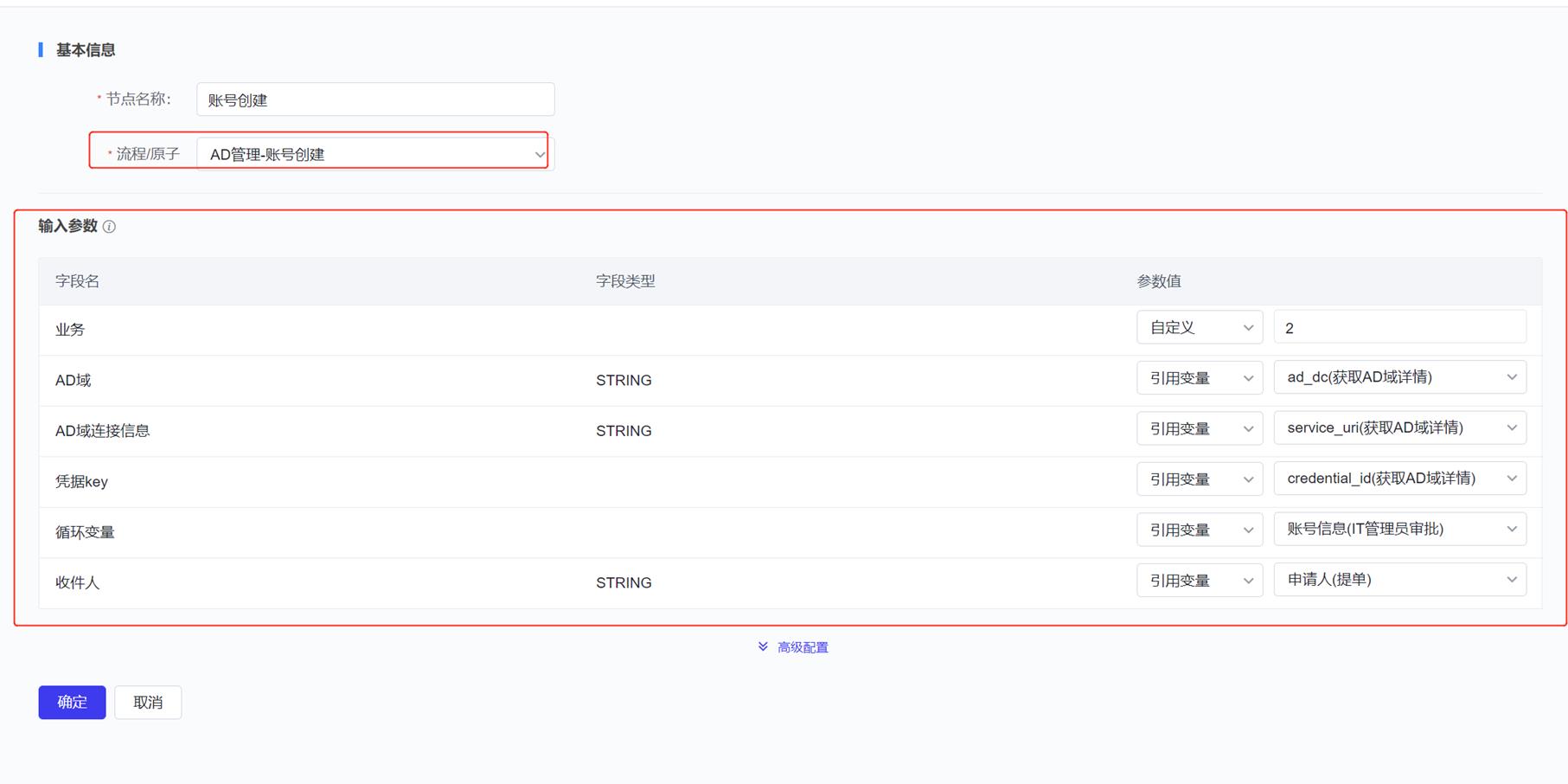
Step3:使用工单流程提单,进行自动化创建
当流程配置好以后,可以进行提单操作,具体步骤可以查看视频查看AD账号创建自动化流程的使用。
场景七 如何利用工单进行数据库SQL的自动执行
场景介绍
某公司之前的数据库SQL执行语句需要运维人员接受到需求后,手动执行前,现在可以使用WeOps的IT服务台进行自动化执行。
场景实现
Step1:前提条件介绍
1、WeOps的前期准备
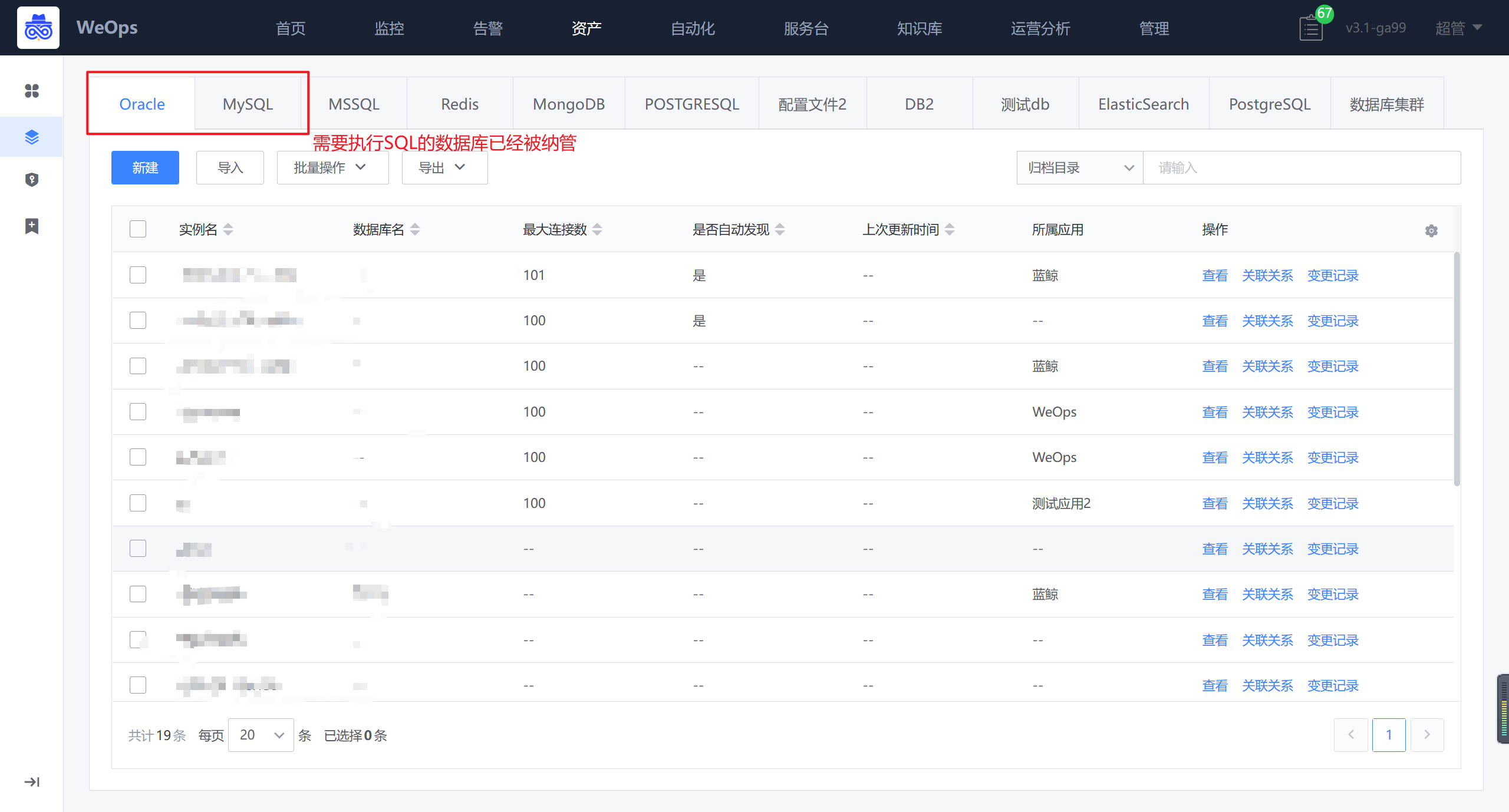
- WeOps中已经纳管所需要的数据库,如下图,在WeOps-资产数据-资产记录-数据库中,对所需要的数据库进行纳管(目前可支持MySQL和Oracle的执行)
- 数据库的凭据信息已经录入WeOps-凭据管理中,并且关联该数据库,并授权给对应需要审核的运维管理员

2、工单流程和自动化流程前期准备
- 在WeOps-管理-服务台管理导入工单流程

在WeOps-后台管理-流程API配置中导入需要的API接口
需要导入的API如下:WeOps组导入获取业务某模型下的资源列表、获取实例凭据列表、获取实例详情、获取用户业务这4个API接口
在后台自动化流程中导入需要的自动化流程
Step2:对导入的流程进行重新配置
前期准备完成后,需要对流程进行重新配置
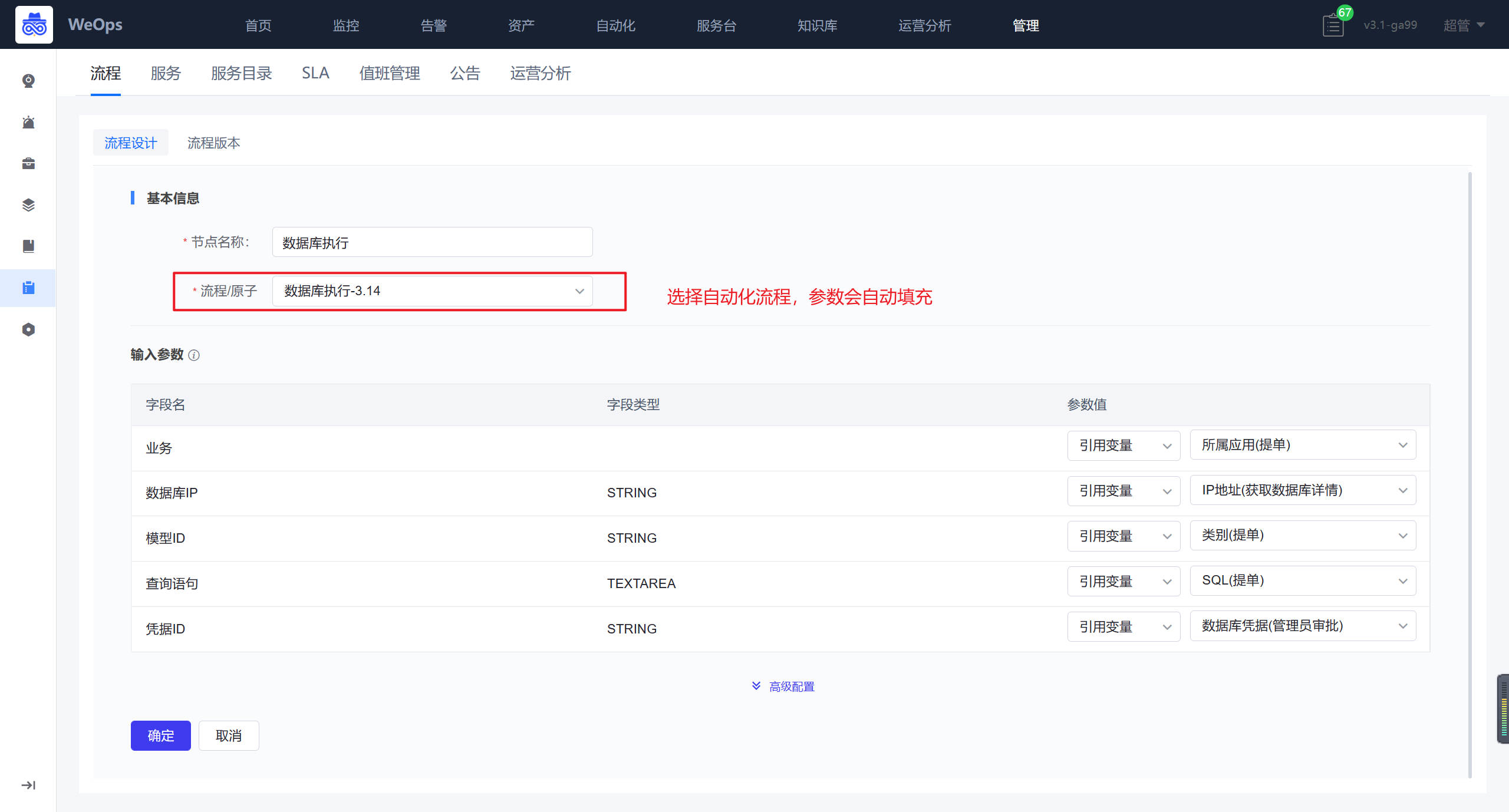
- 提单节点:所属应用、数据库这三个字段需要对应配置API接口,作用如下:所属应用展示提单人有权限的应用,类别展示该应用下的资产模型列表,数据库展示选择的数据库类型具体实例列表。具体选择和配置如下图所示

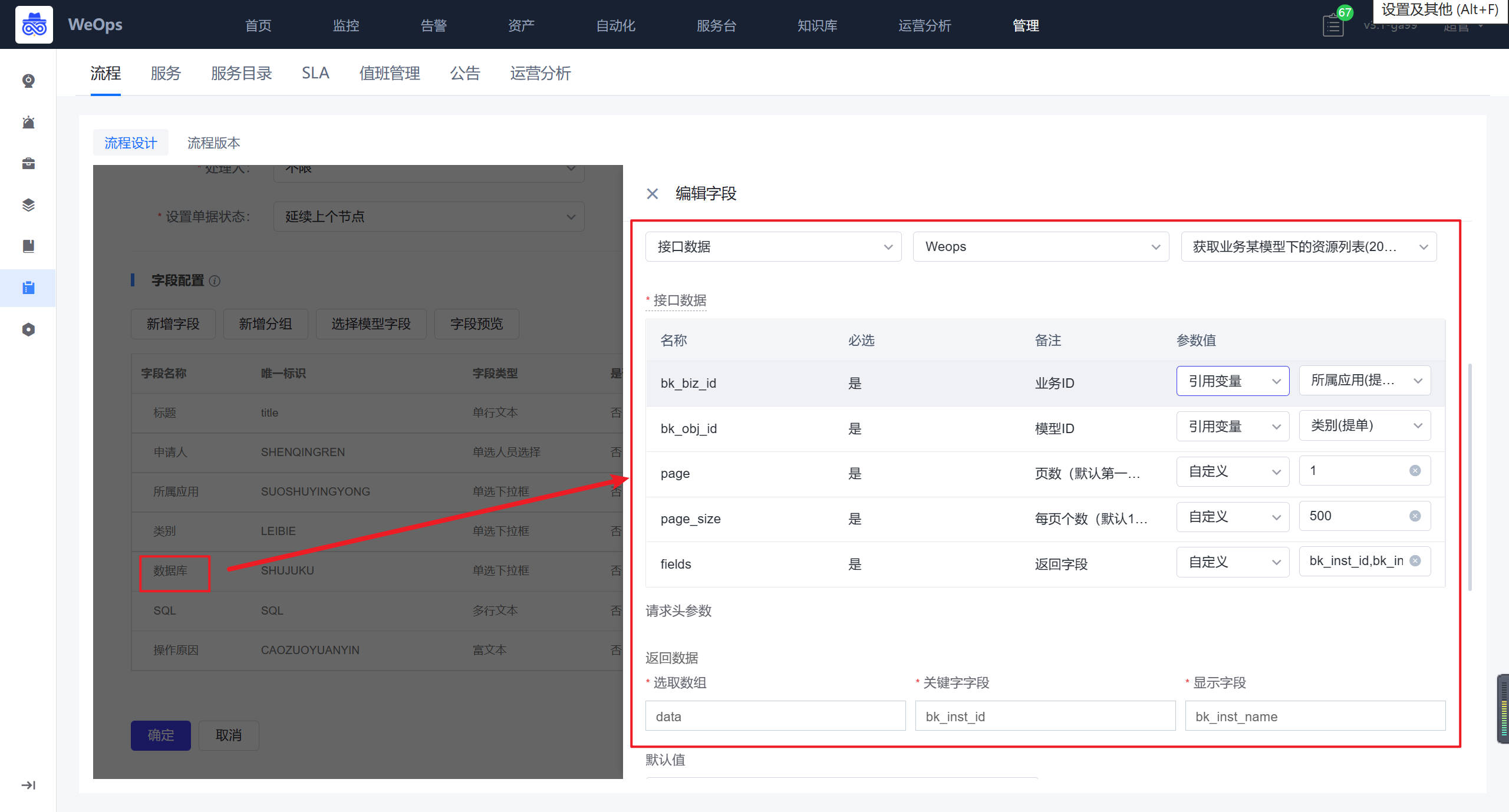
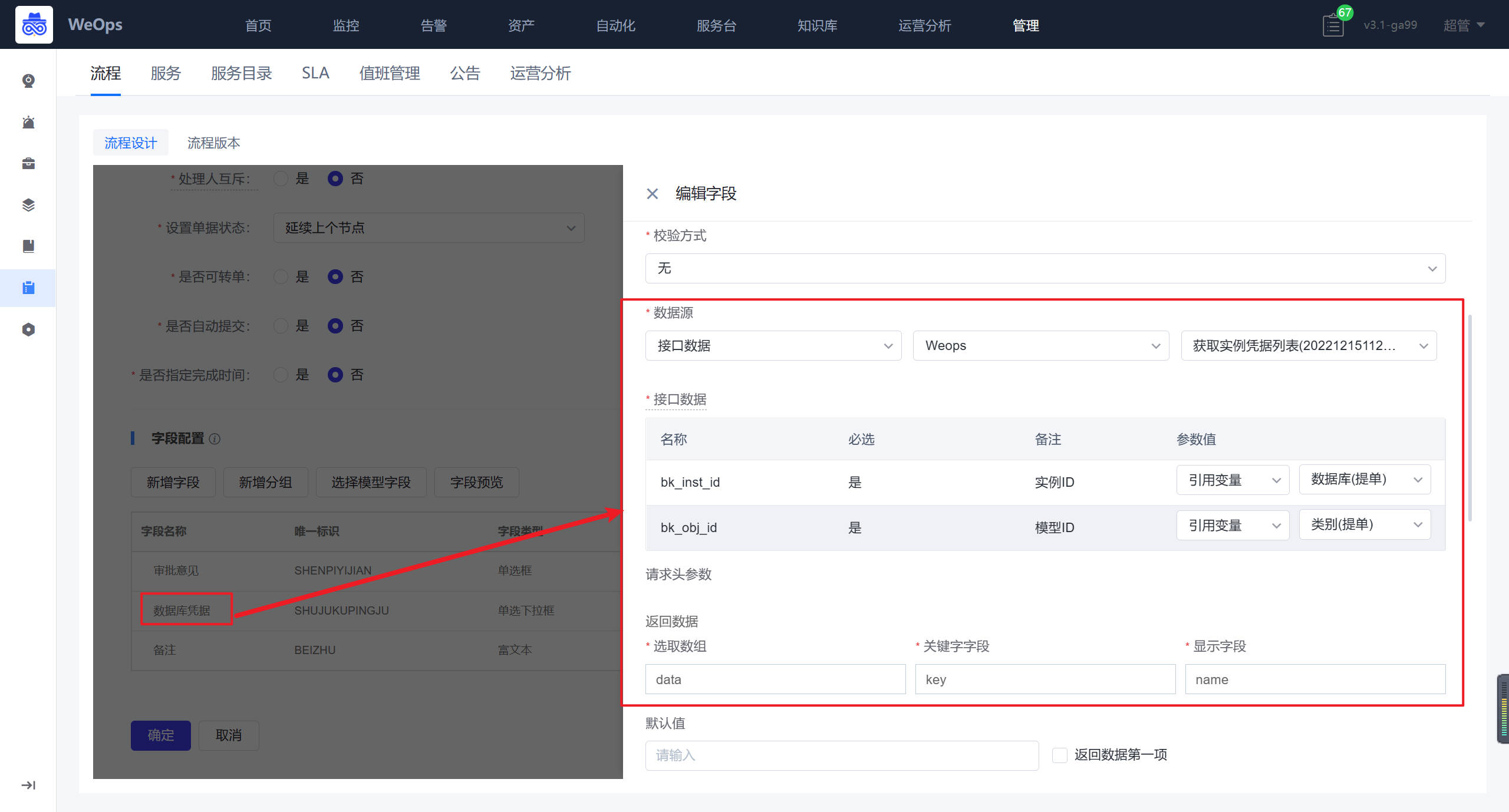
审批节点:数据库凭据需要重新选择接口,作用如下:管理员对提单人提交的SQL语句,数据库信息等进行审核,审核无误后选择该数据库的凭据,便于下一步自动执行。
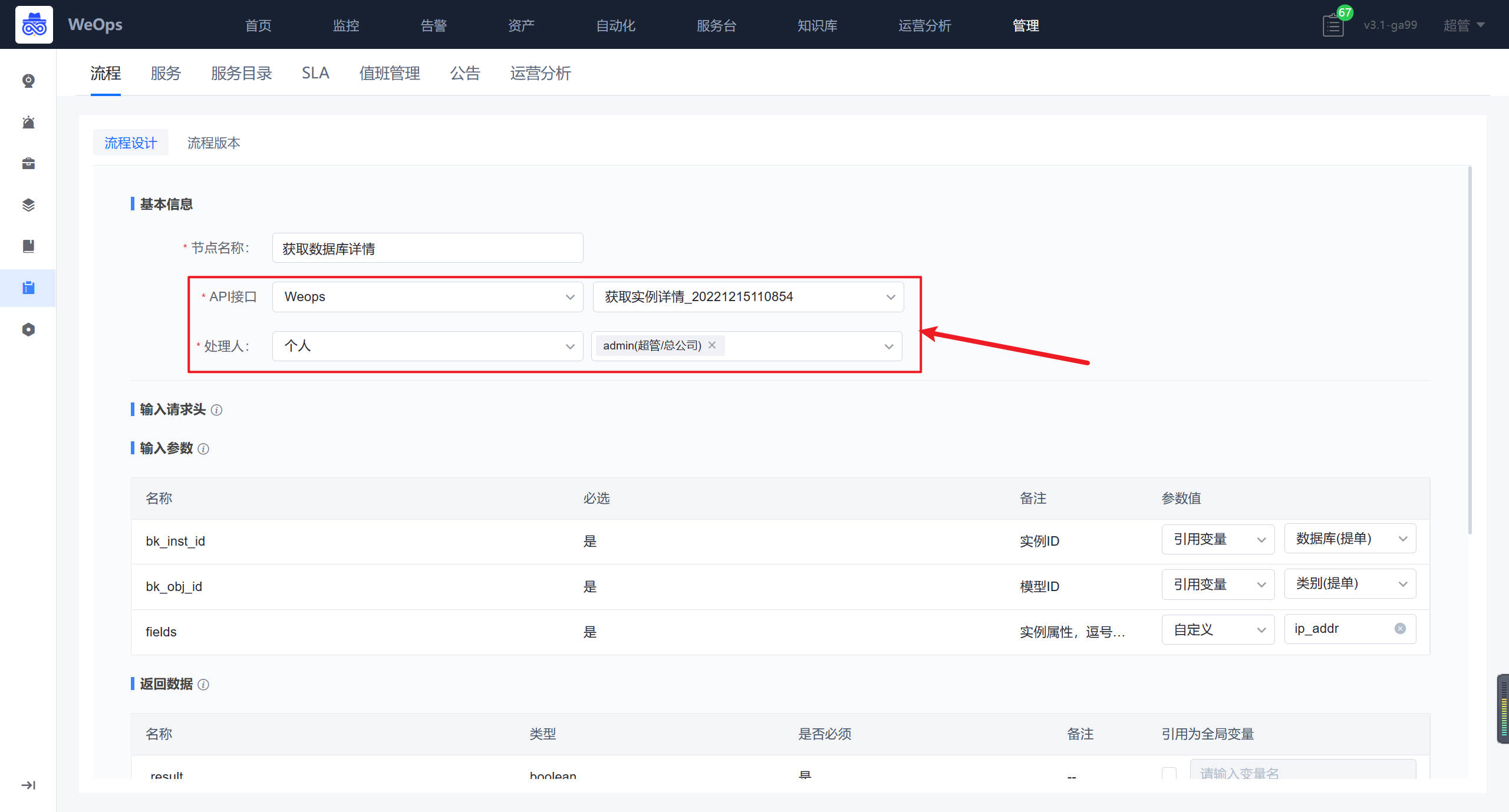
获取API详情节点:选择对应接口,下面的参数会自动勾选的
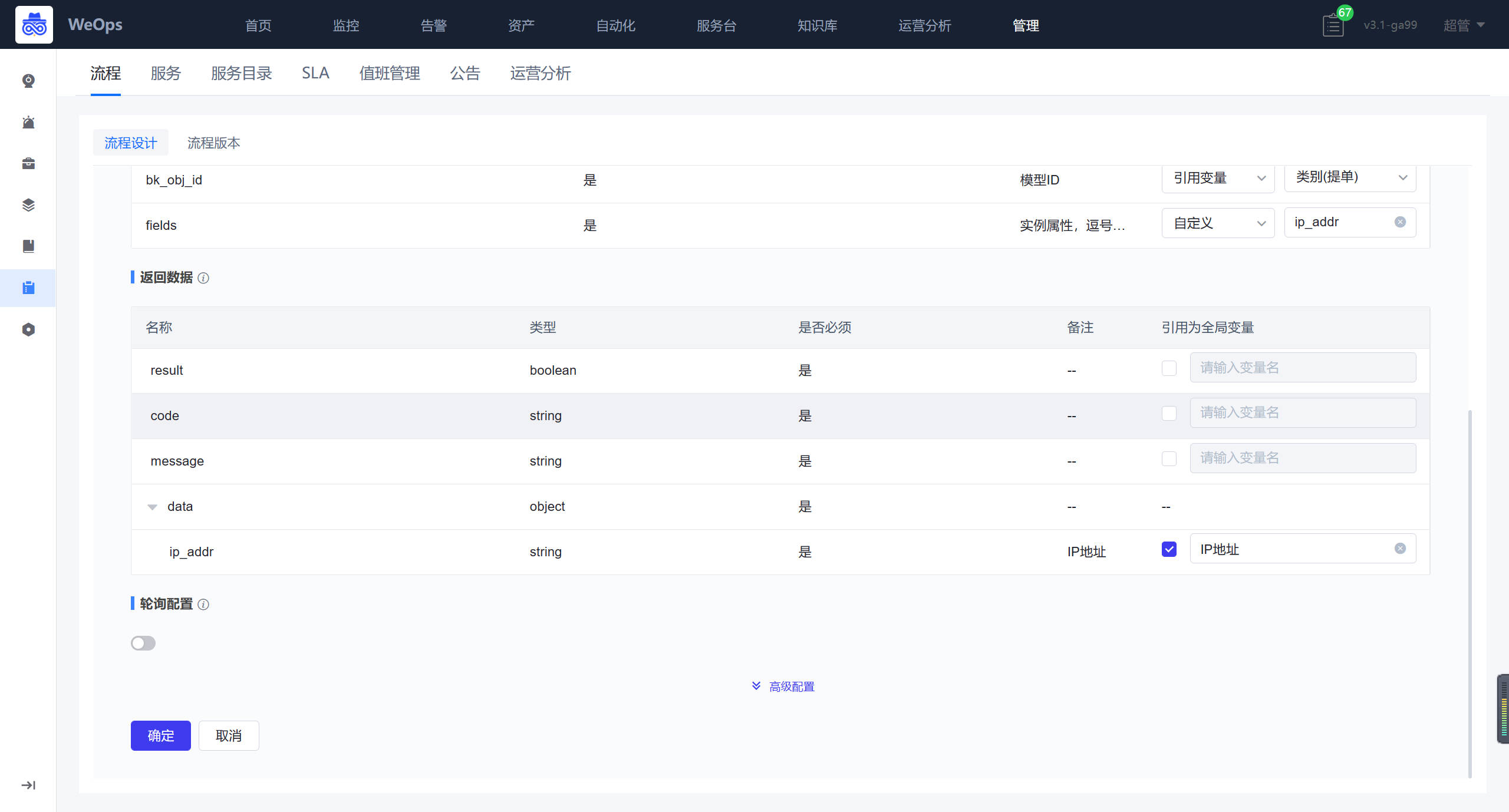
自动执行节点:选择需要的自动流程,填写参数
Step3:使用工单流程提单,进行自动化创建
当流程配置好以后,可以进行提单操作
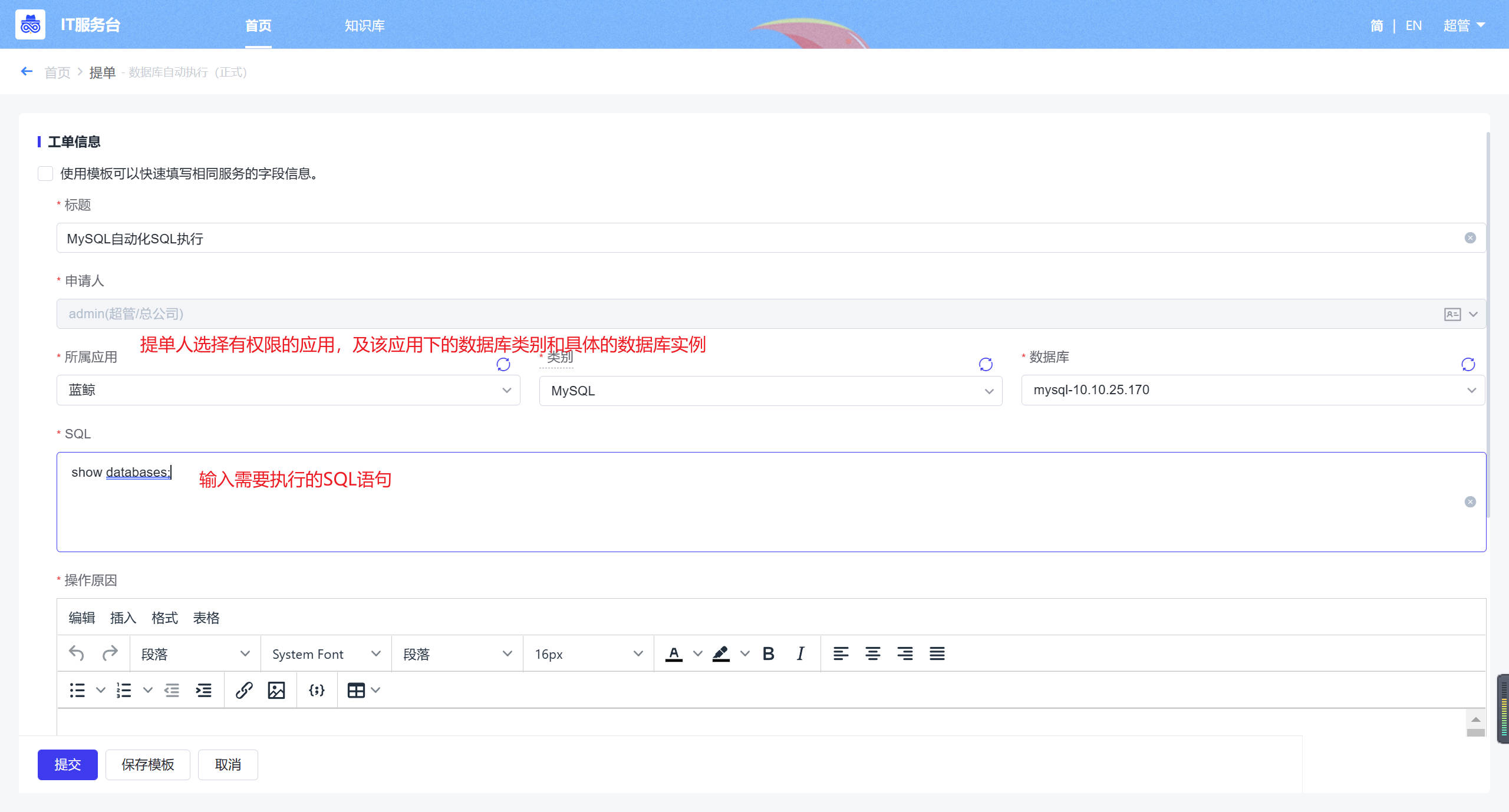
- 提单:用户提单时需要选择需要执行的数据库实例,并填写SQL语句和申请原因
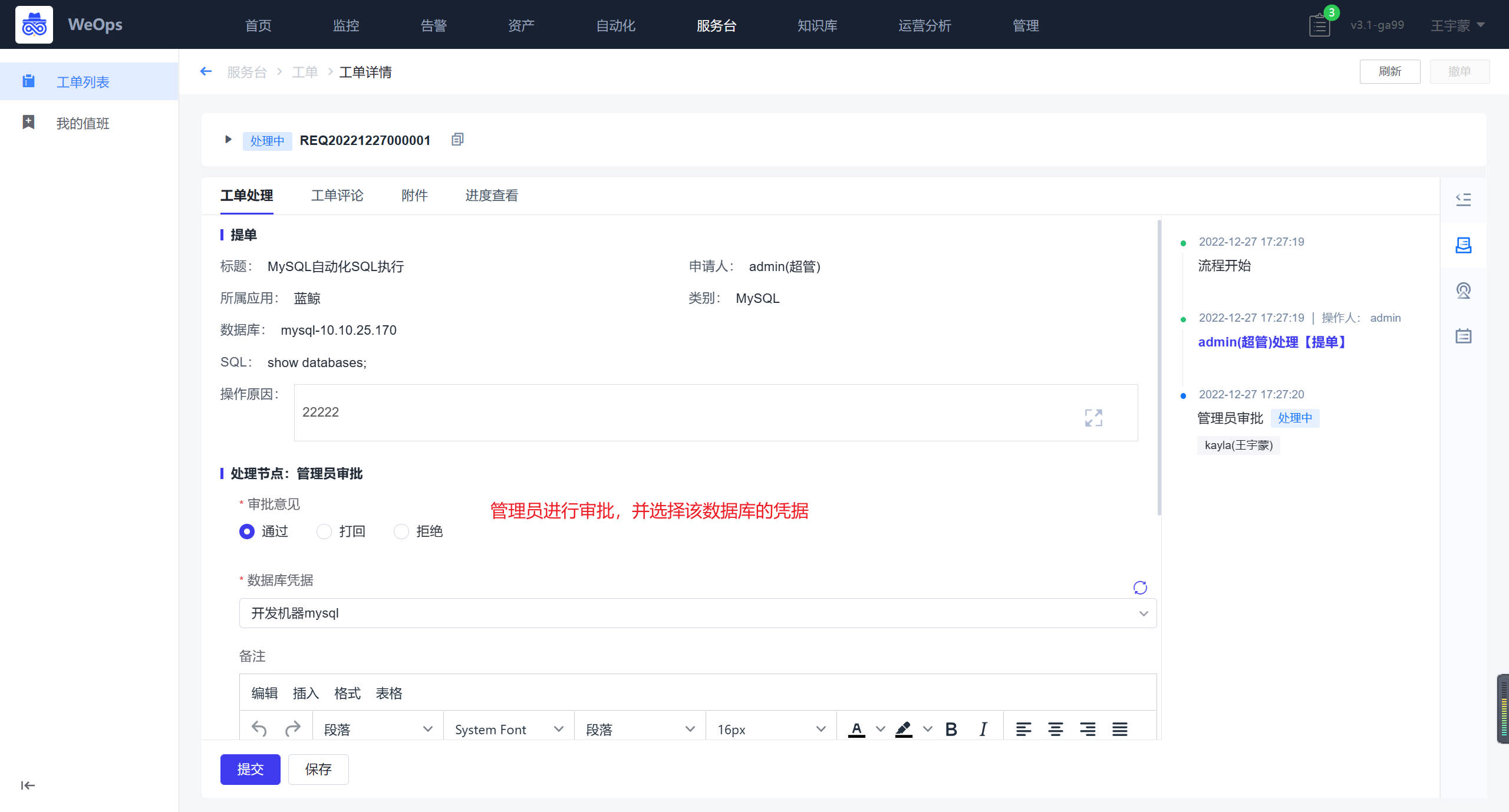
- 审批:管理员对提单人的申请信息进行审批,无误后选择执行的数据库凭据
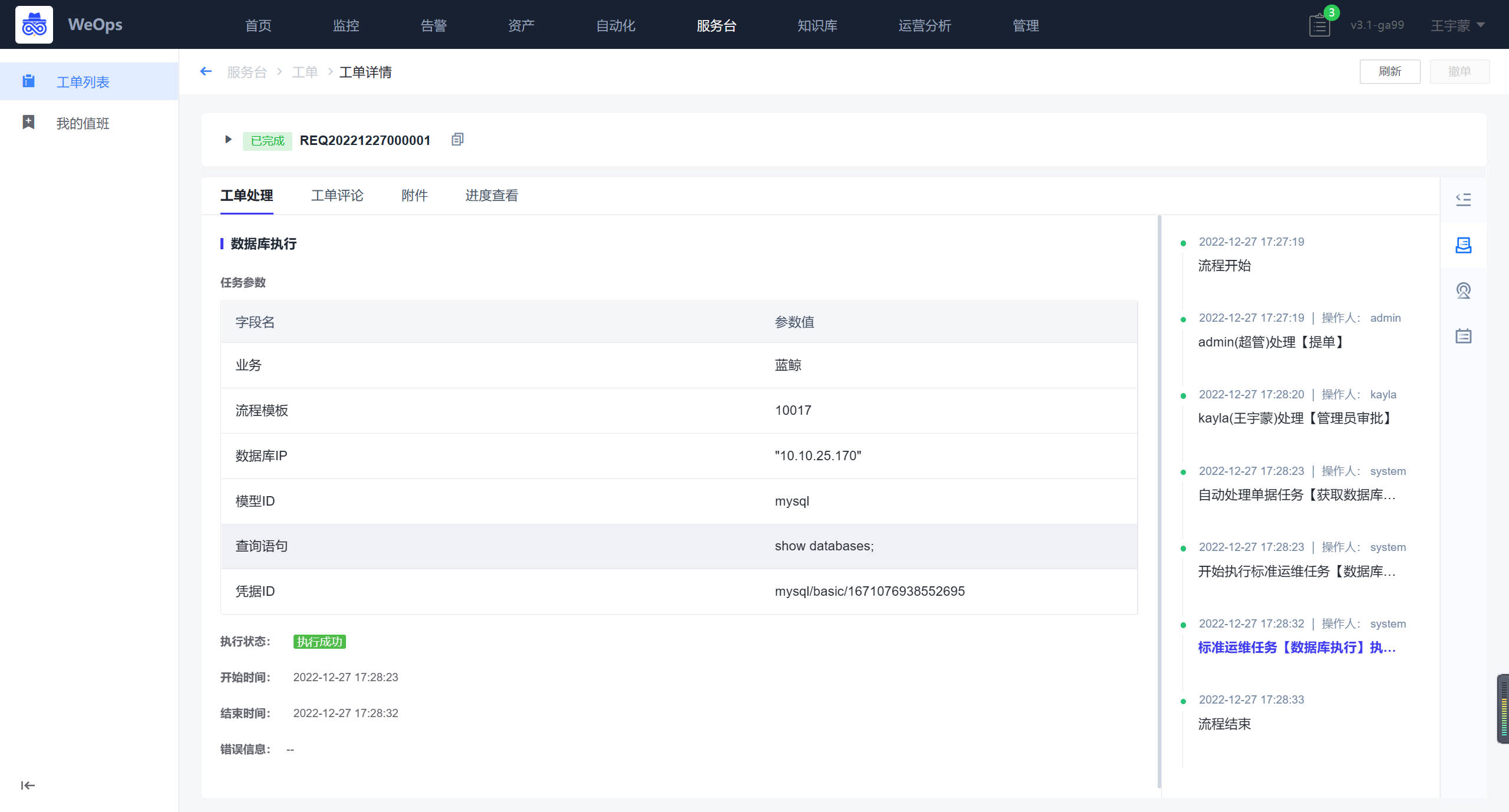
- 自动执行:提单人的SQL语句将会自动的在对应的数据中进行执行,并返回执行结果成功/失败
场景八 如何利用工单进行vmware虚拟机的自动创建/快照创建/快照回滚
场景介绍
某公司之前的虚拟机创建需要运维人员接受到需求后,手动进行创建,耗时耗力,准确率低,容易出错。采用工单自动化,可以实现申请人自行提单,管理员经过审批就可以创建。
场景实现
Step1:前提条件介绍
1、WeOps的前期准备
- WeOps中已经纳管所需要的Vcenter,如下图,在WeOps-资产数据-资产记录-Vcenter中,对所需要的Vcenter进行纳管
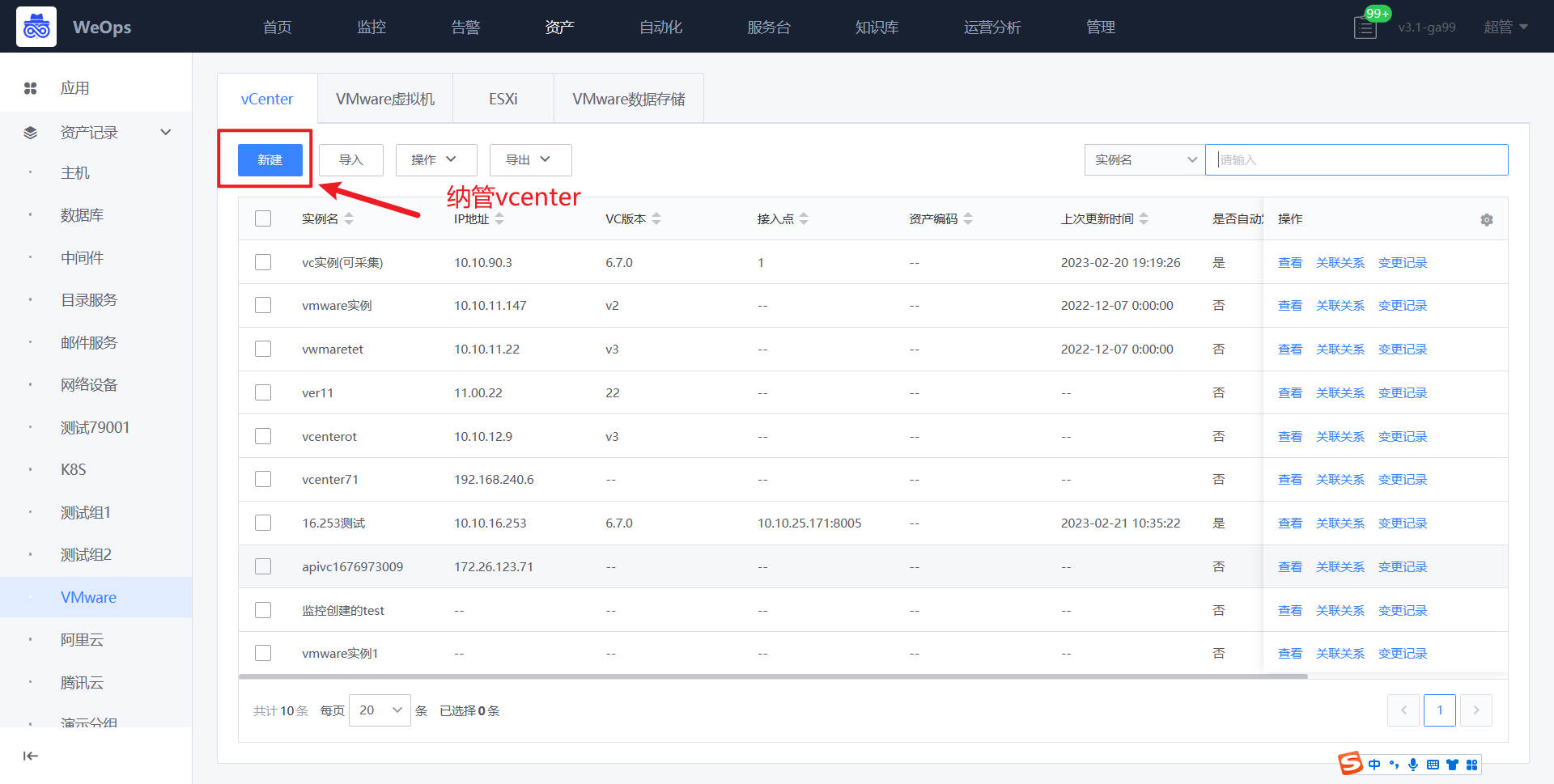
- Vcenter的凭据信息已经录入WeOps-凭据管理中,并且关联该Vcenter,并授权给对应需要审核的运维管理员,这样运维管理员在审批工单的时候,就可以选择到这个Vcenter并选择使用对应的凭据,以便后续直接进行自动化的创建。 (用户自动化流程的凭据,建议使用拥有全局权限的管理员角色)
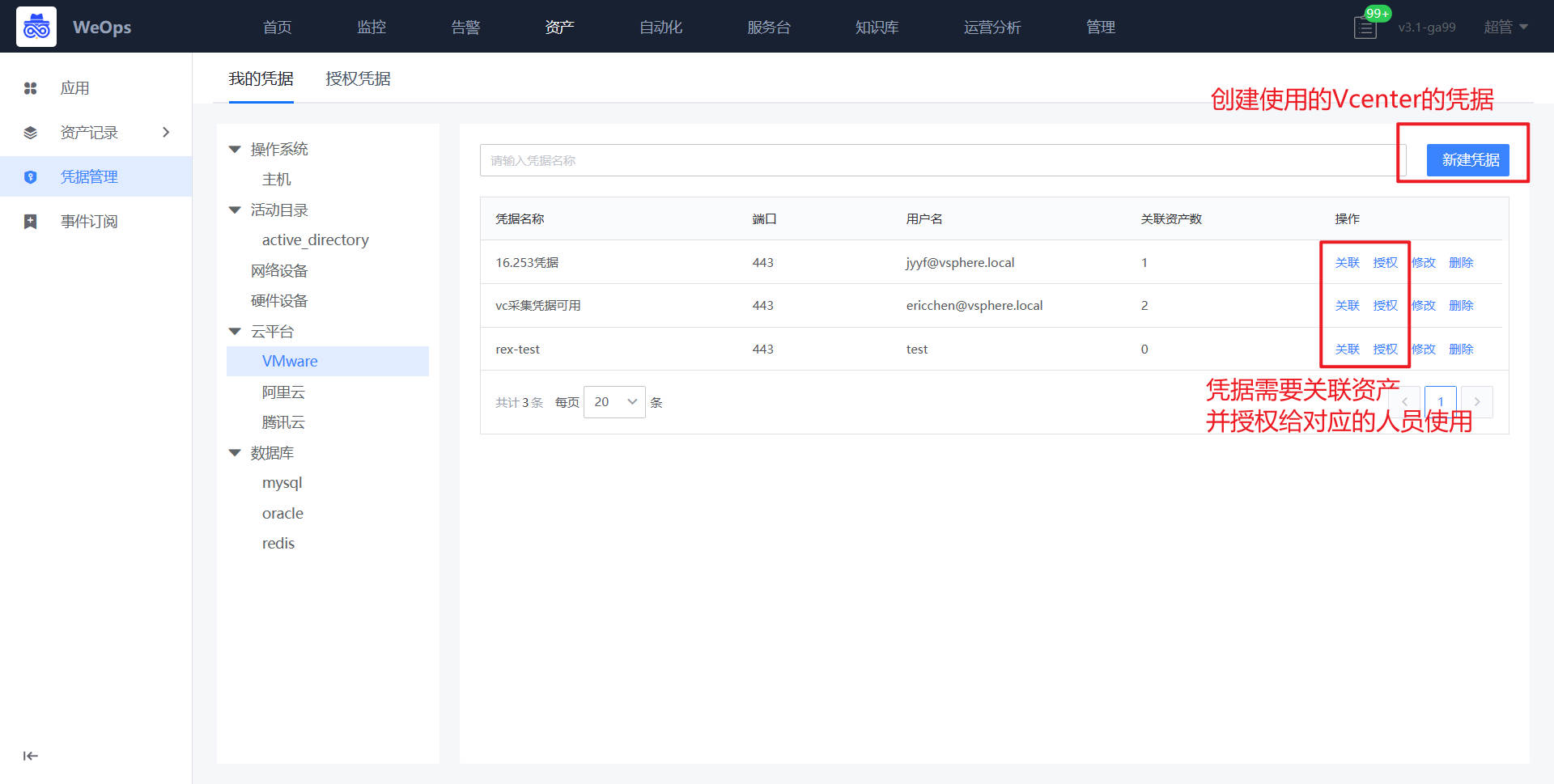
- 该Vcenter在WeOps-管理-资产管理中,已经设置了定时自动发现,可以自动发现该Vcenter下面的虚拟机、ESXI和数据存储。设置了自动发现后,自动创建的虚拟机可以定时被WeOps自动纳管,以便后续使用(比如自动创建快照,快照回滚)
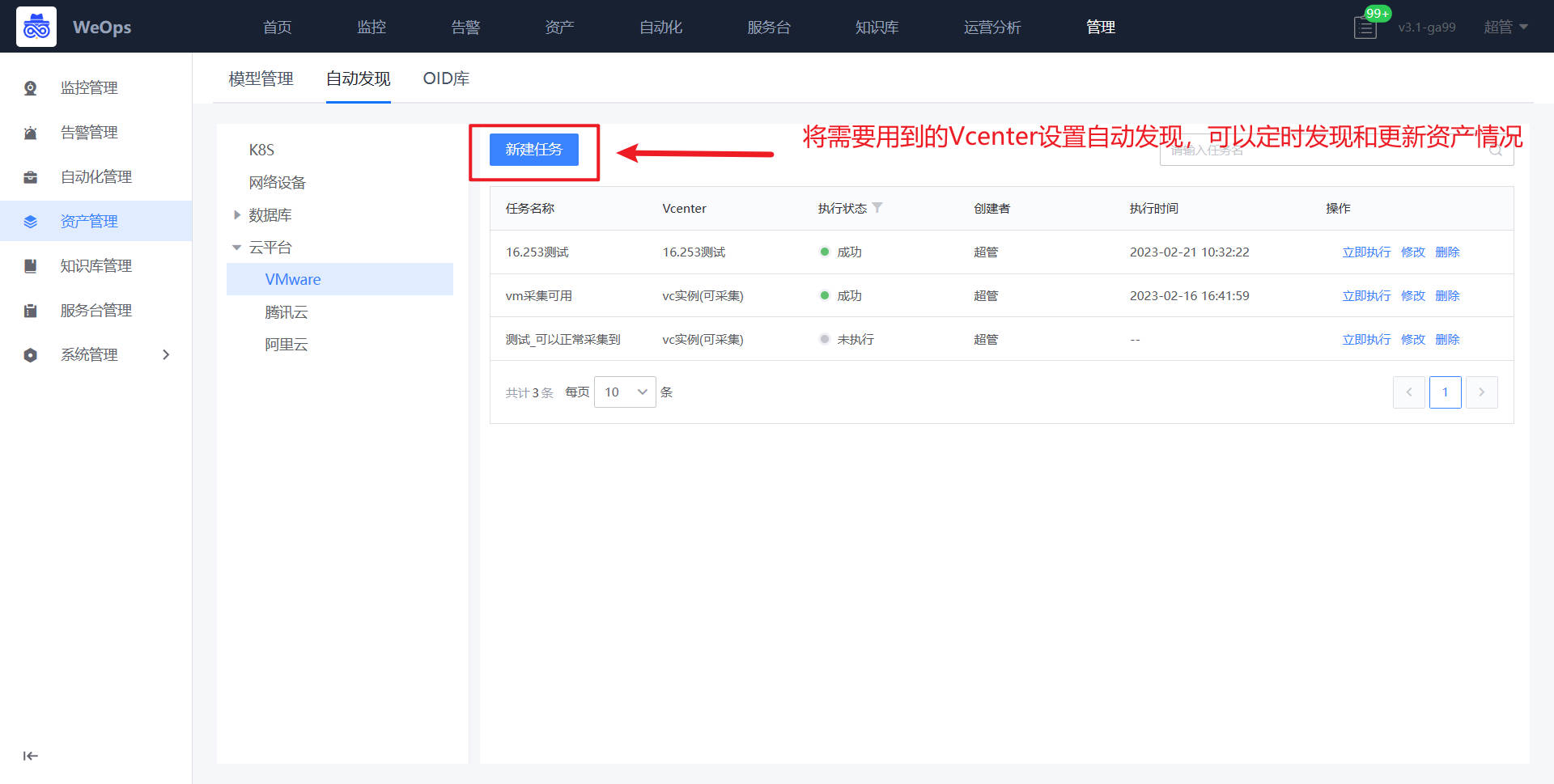
2、工单流程和自动化流程前期准备
- 在WeOps-管理-服务台管理导入工单流程
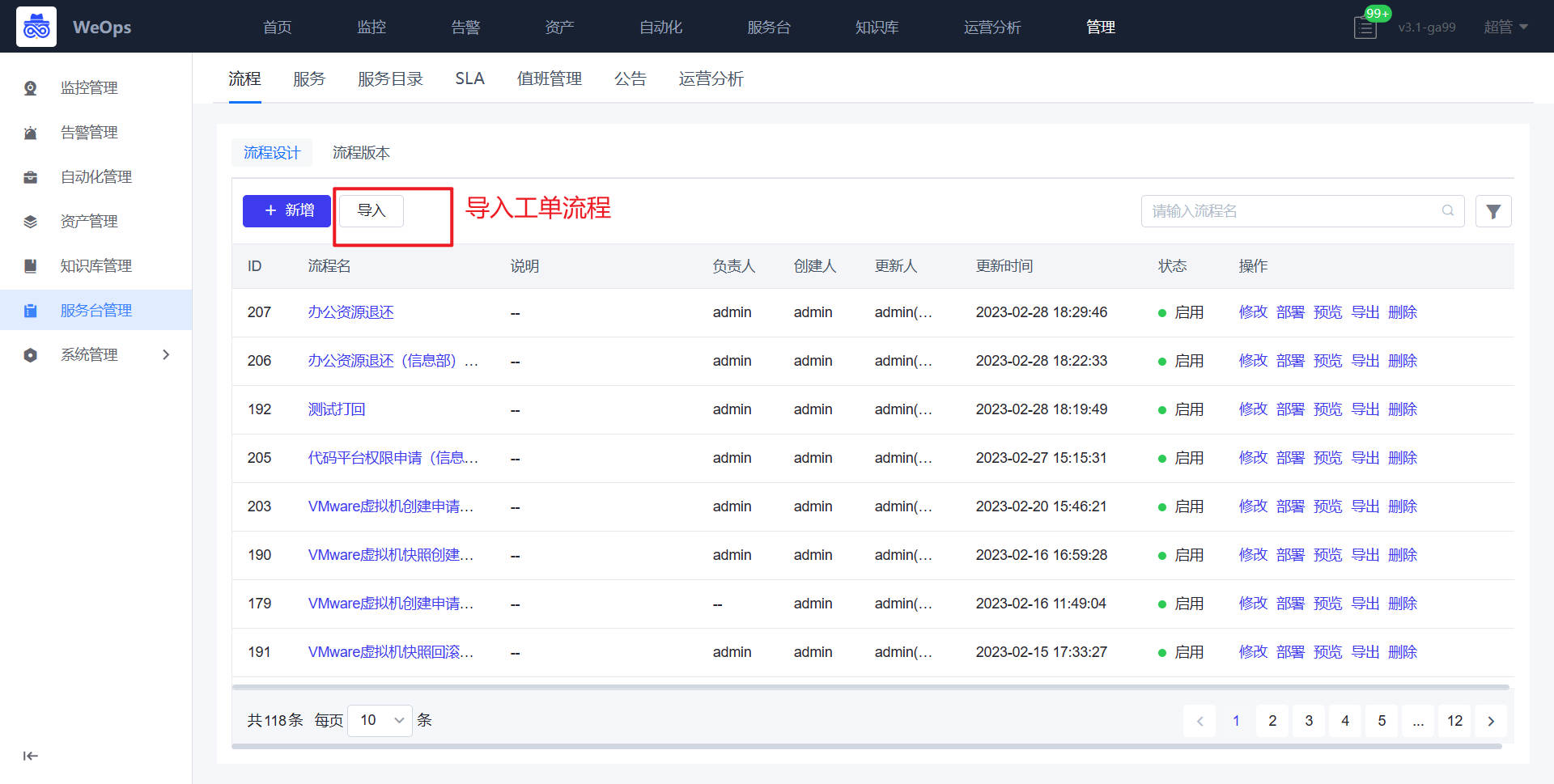
- 在WeOps-后台管理-流程API配置中导入需要的API接口
- 需要导入的API共有13个,主要用于虚拟机创建、虚拟机快照创建、虚拟机快照回滚,具体如下

- 在自动化流程导入需要的自动化流程
Step2:对导入的流程进行重新配置
前期准备完成后,需要对流程进行重新配置
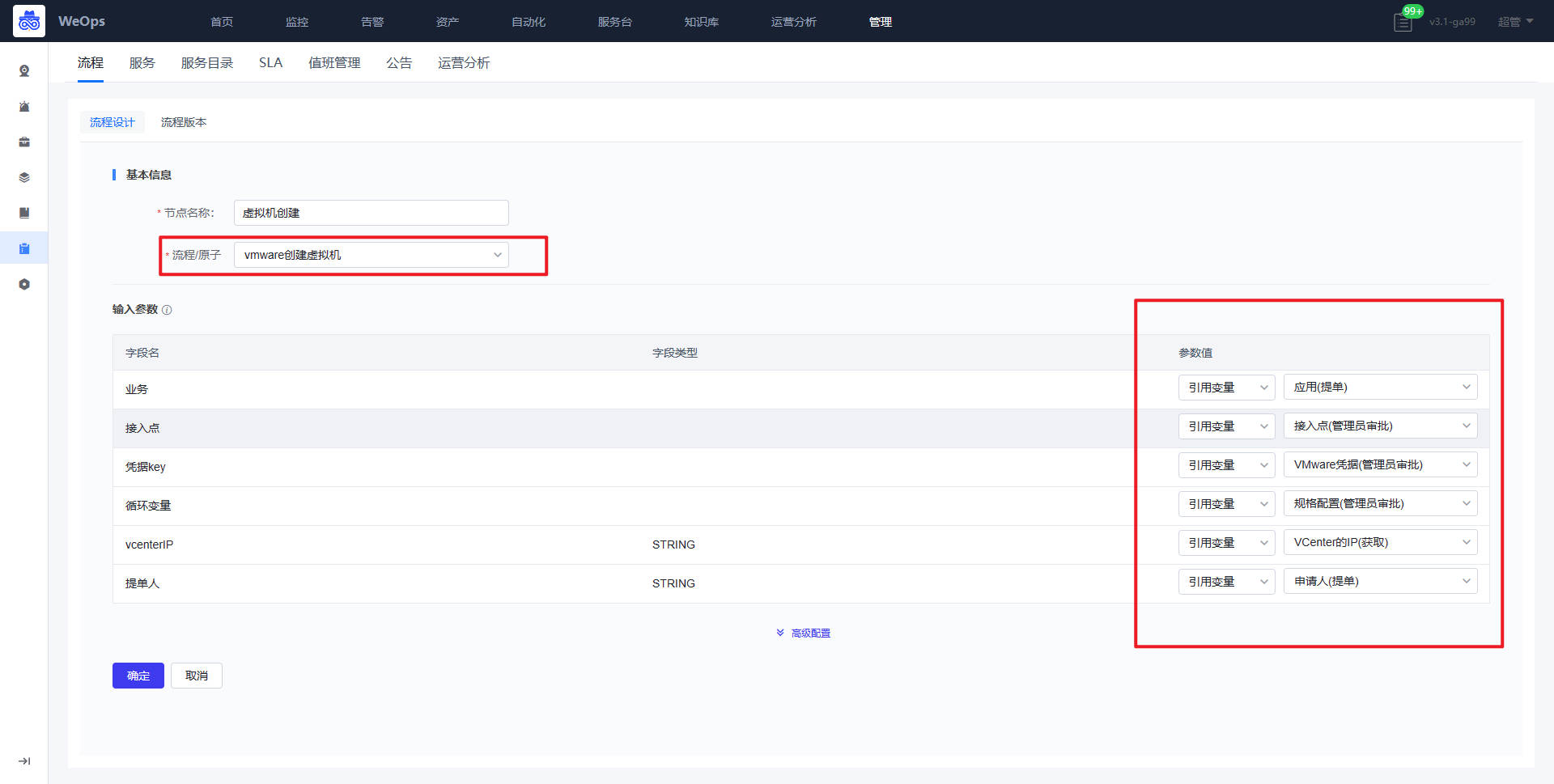
虚拟机创建
工单流程的重新配置重点在第二步“定义与配置流程”,接下来重点介绍下每个节点的流程应该如何配置。
- 提单节点:所属应用需要对应配置API接口,作用如下:所属应用展示提单人有权限的应用,提单人选择应用后,创建的该虚拟机就归属这个应用。规格配置的字段:CPU规格、内存规格、系统容量、数据盘容量和操作系统,字段保持不变,下拉选项可以配置,以便后续把相关数据传入自动化流程。
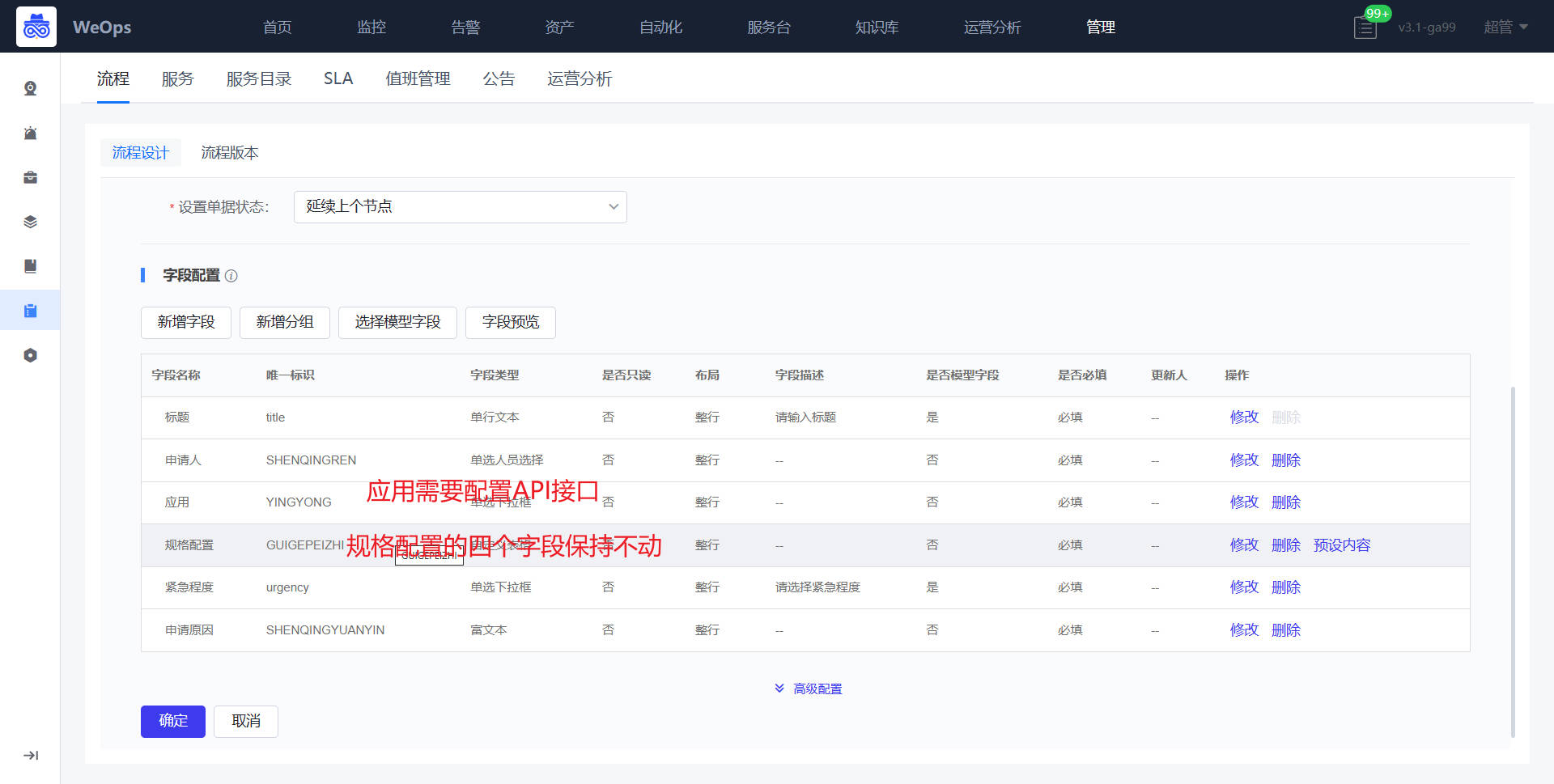
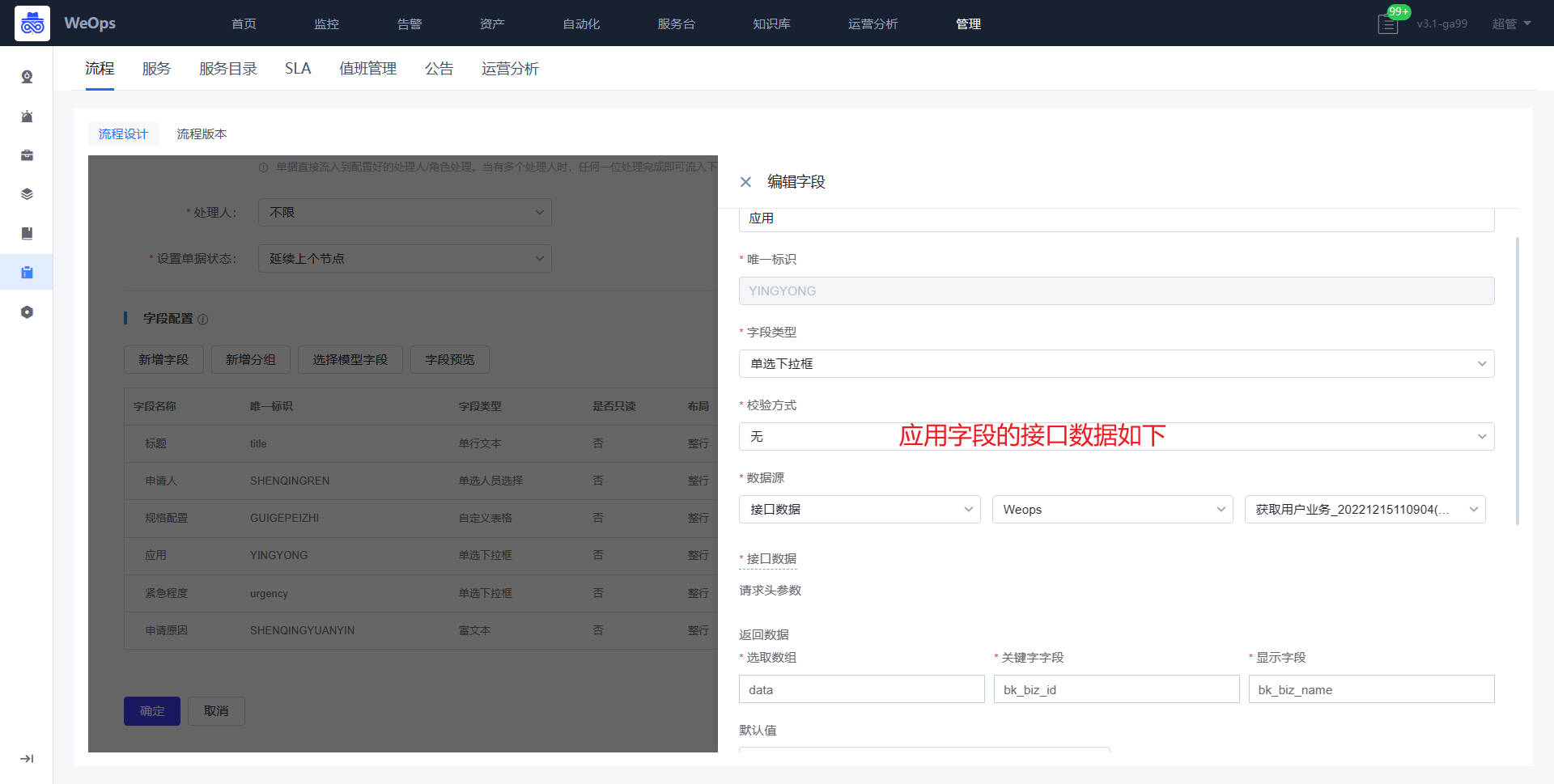
- 审批节点:接入点、Vcenter、VMware凭据三个字段需要配置API接口,作用如下:管理员对提单人提交申请,选择对应接入点,创建虚拟机的Vcenter以及其凭据,便于确定这个虚拟机创建的位置。
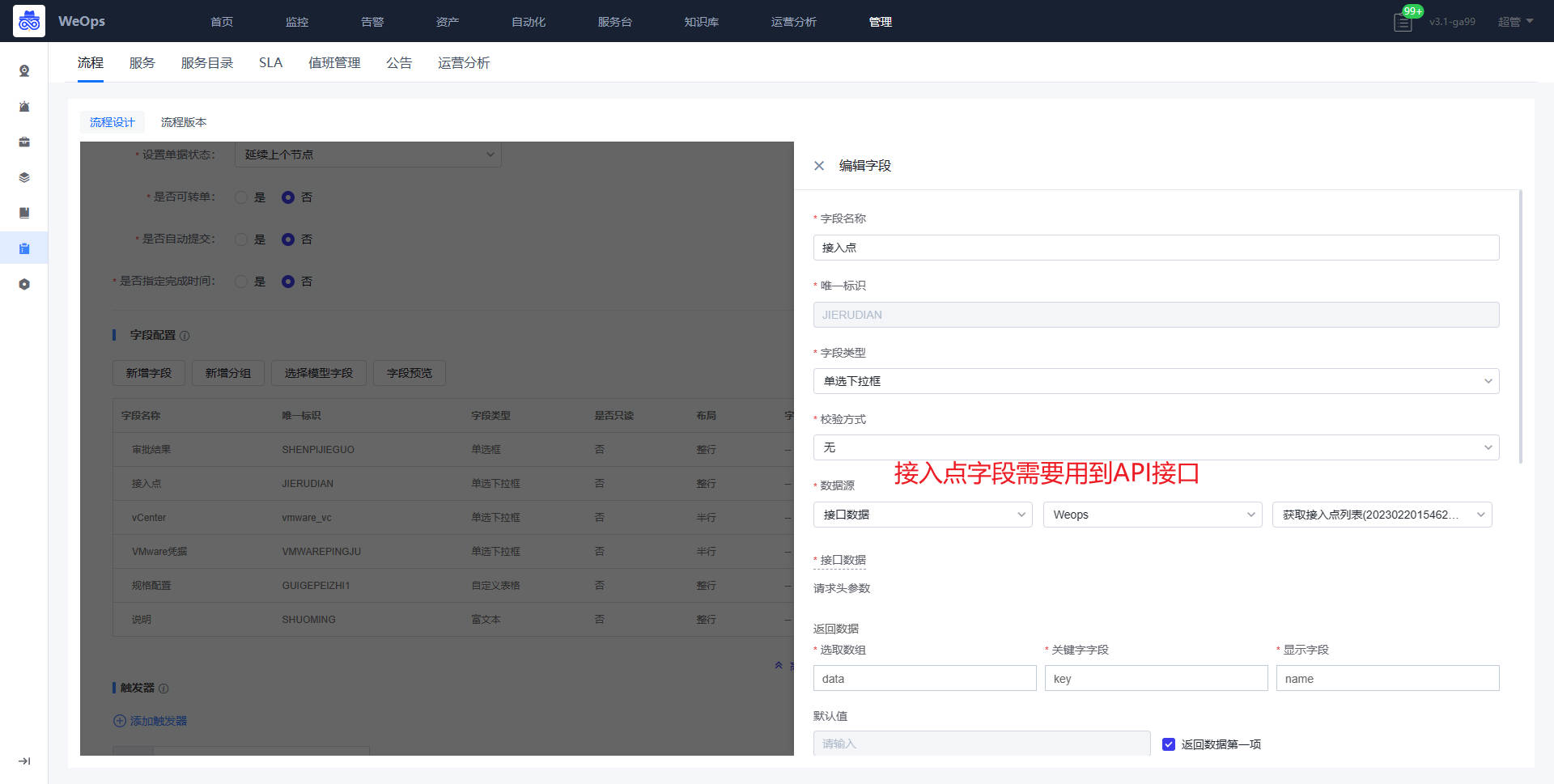

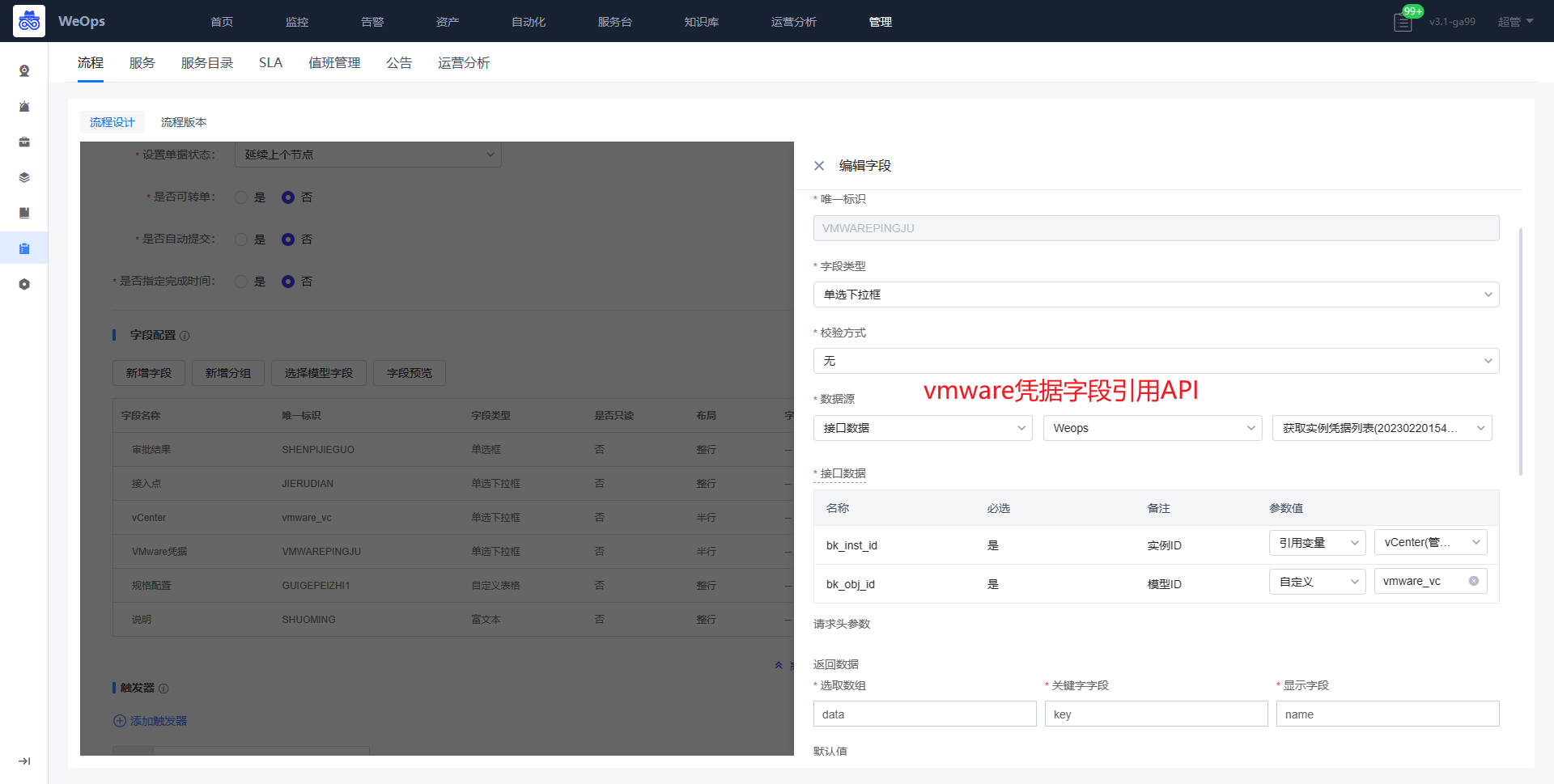
*审批节点:规格配置的字段说明如下:CPU规格、内存规格、系统容量和数据盘容量、操作系统的字段是提单节点自动获取的,无需改变;虚拟机模板、网络适配器、ESXI、文件夹的字段需要配置API获取对应信息;子网掩码、网关、DNS、虚拟机名称、IP地址的字段为手段填写;IP是否存在字段是为了验证填写的IP地址是否被使用,需要配置API信息。
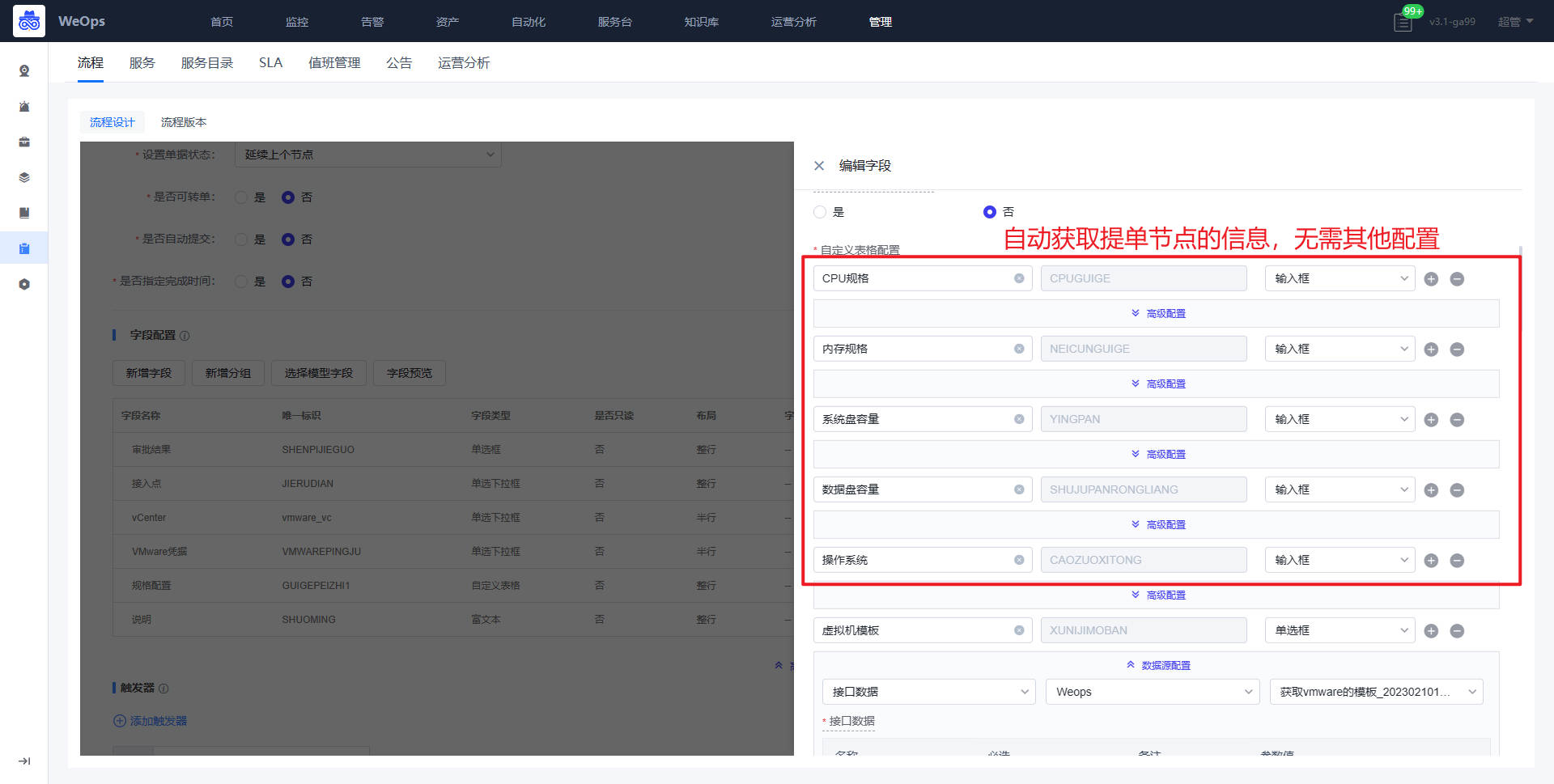

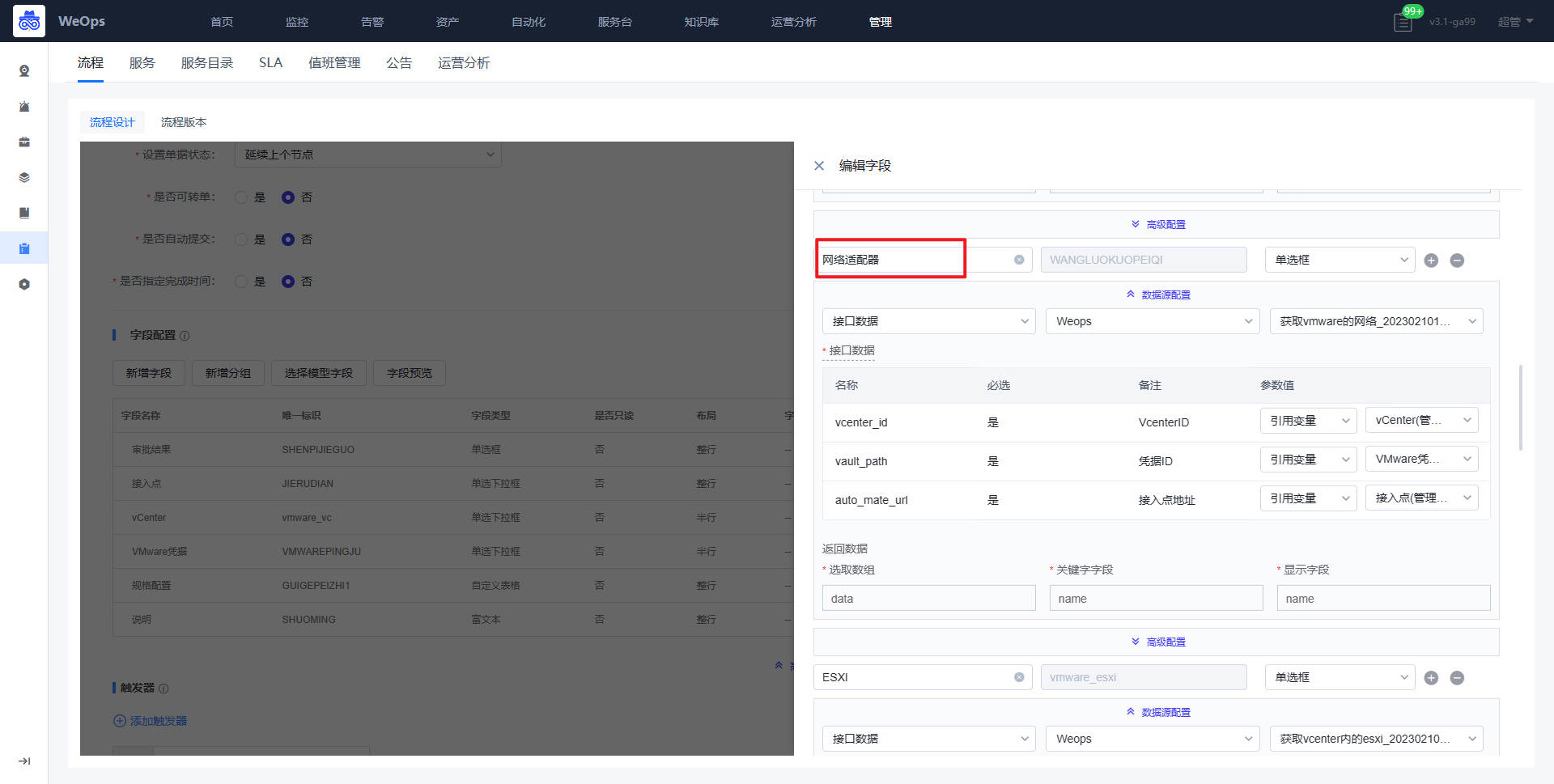


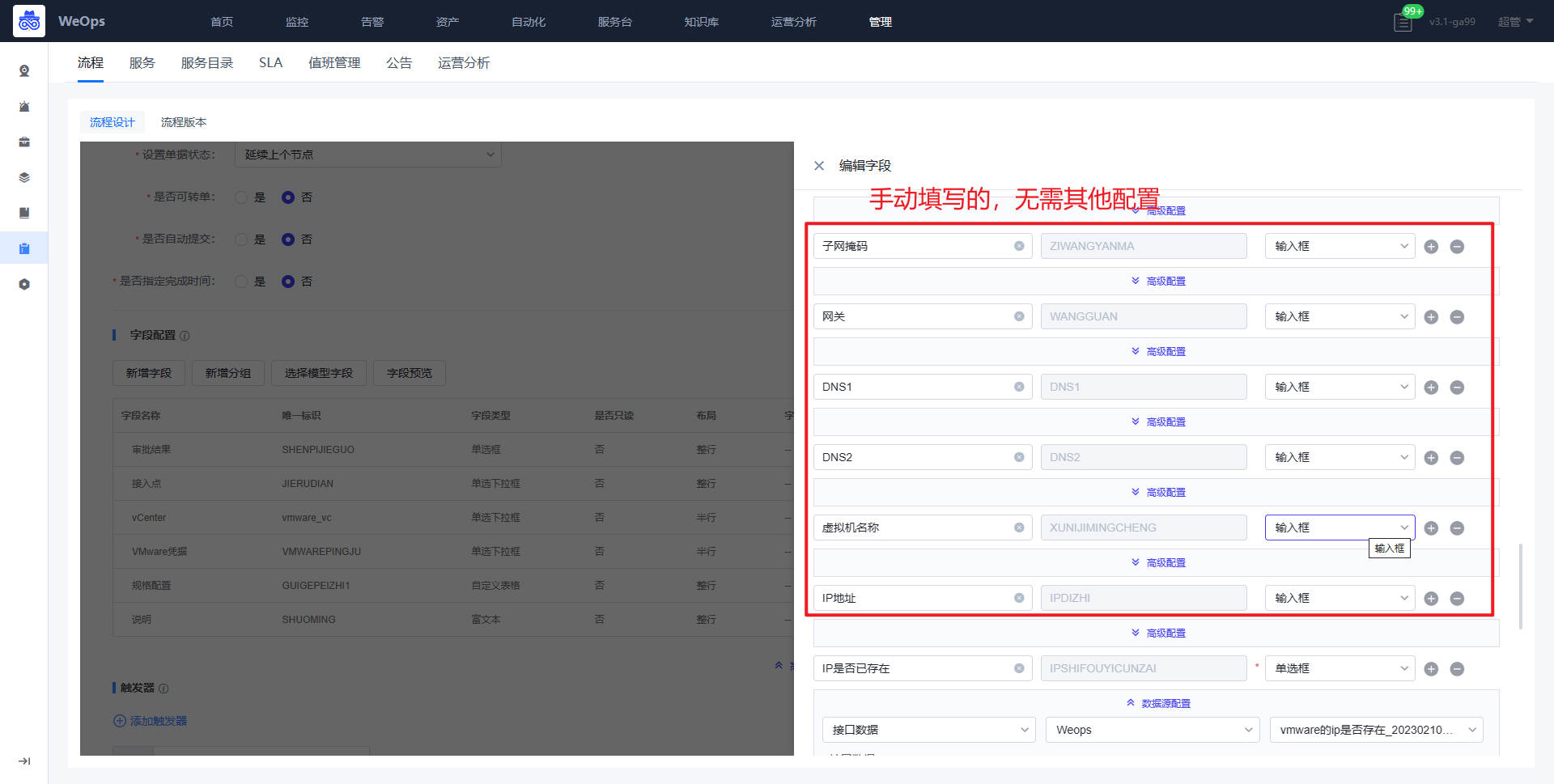

- 获取API详情节点:选择对应接口,填写对应的输入参数,勾选返回数据
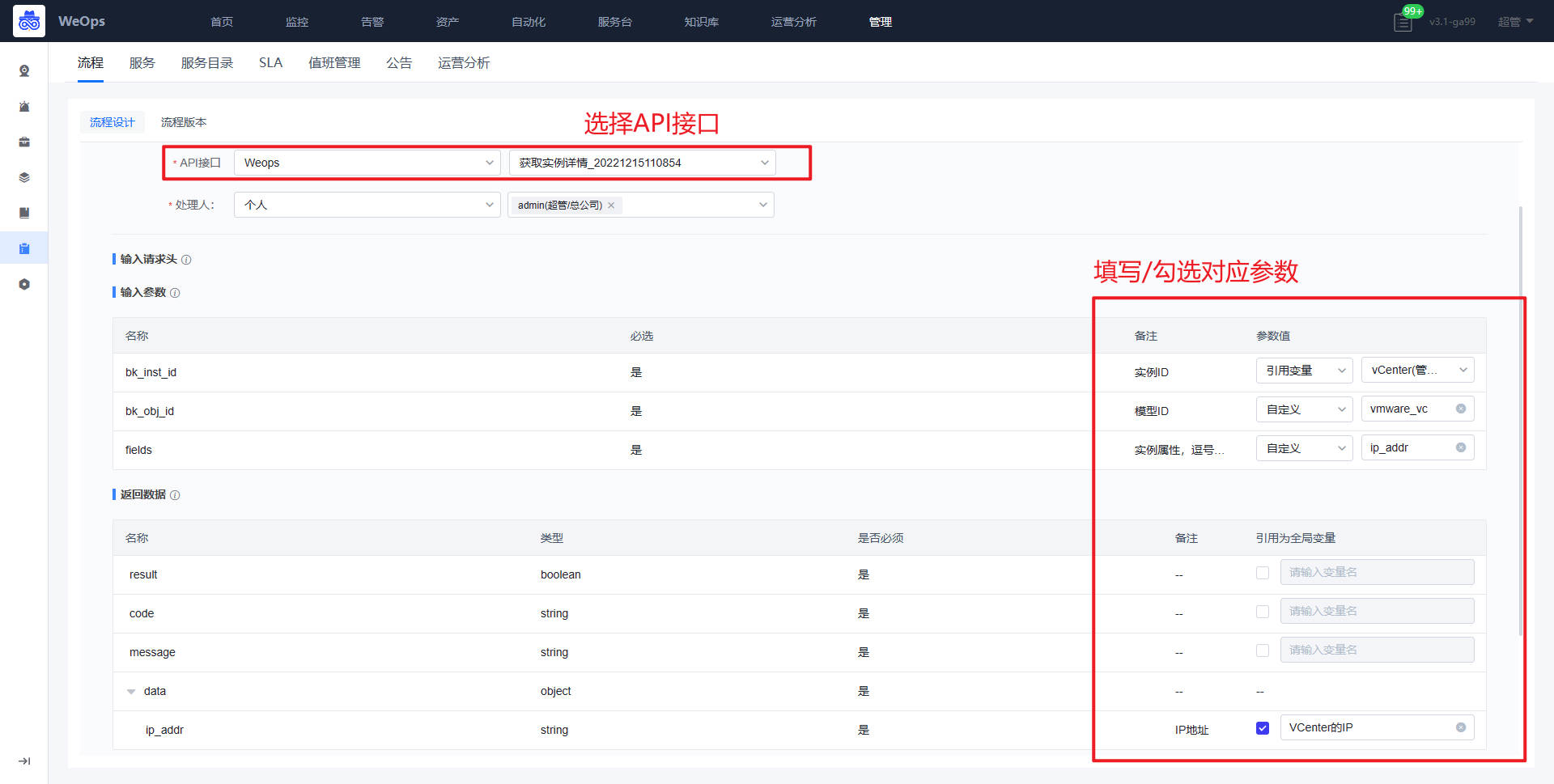
自动执行节点:选择需要的自动流程,填写参数
虚拟机快照创建
工单流程的重新配置重点在第二步“定义与配置流程”,接下来重点介绍下每个节点的流程应该如何配置。
- 提单节点:所属应用、虚拟机信息(IP地址和虚拟机名称)需要对应配置API接口,作用如下:所属应用展示提单人有权限的应用,提单人选择应用后,可以展示该应用下的虚拟机IP列表和名称,便于提单人找下需要创建快照的虚拟机
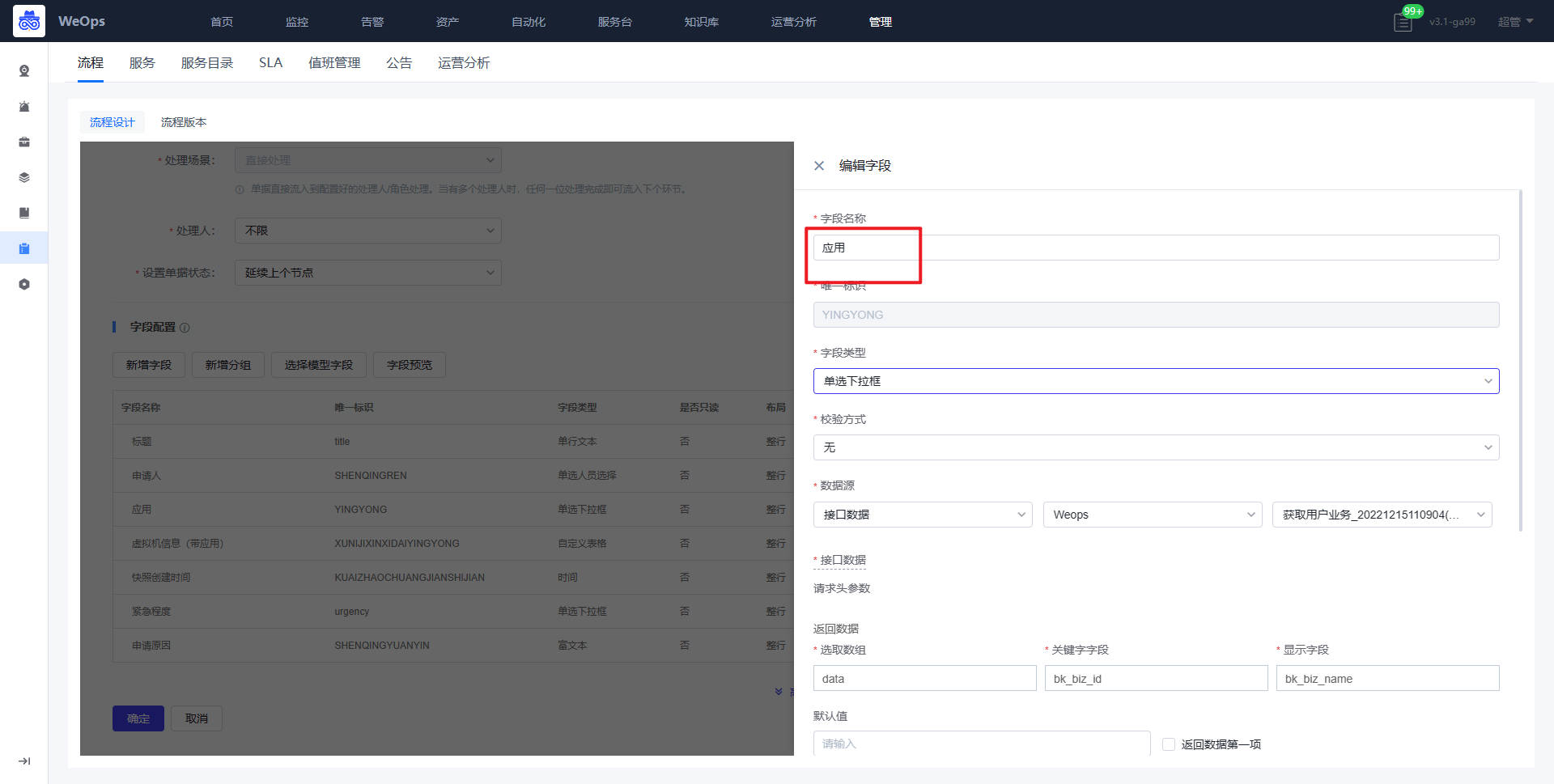
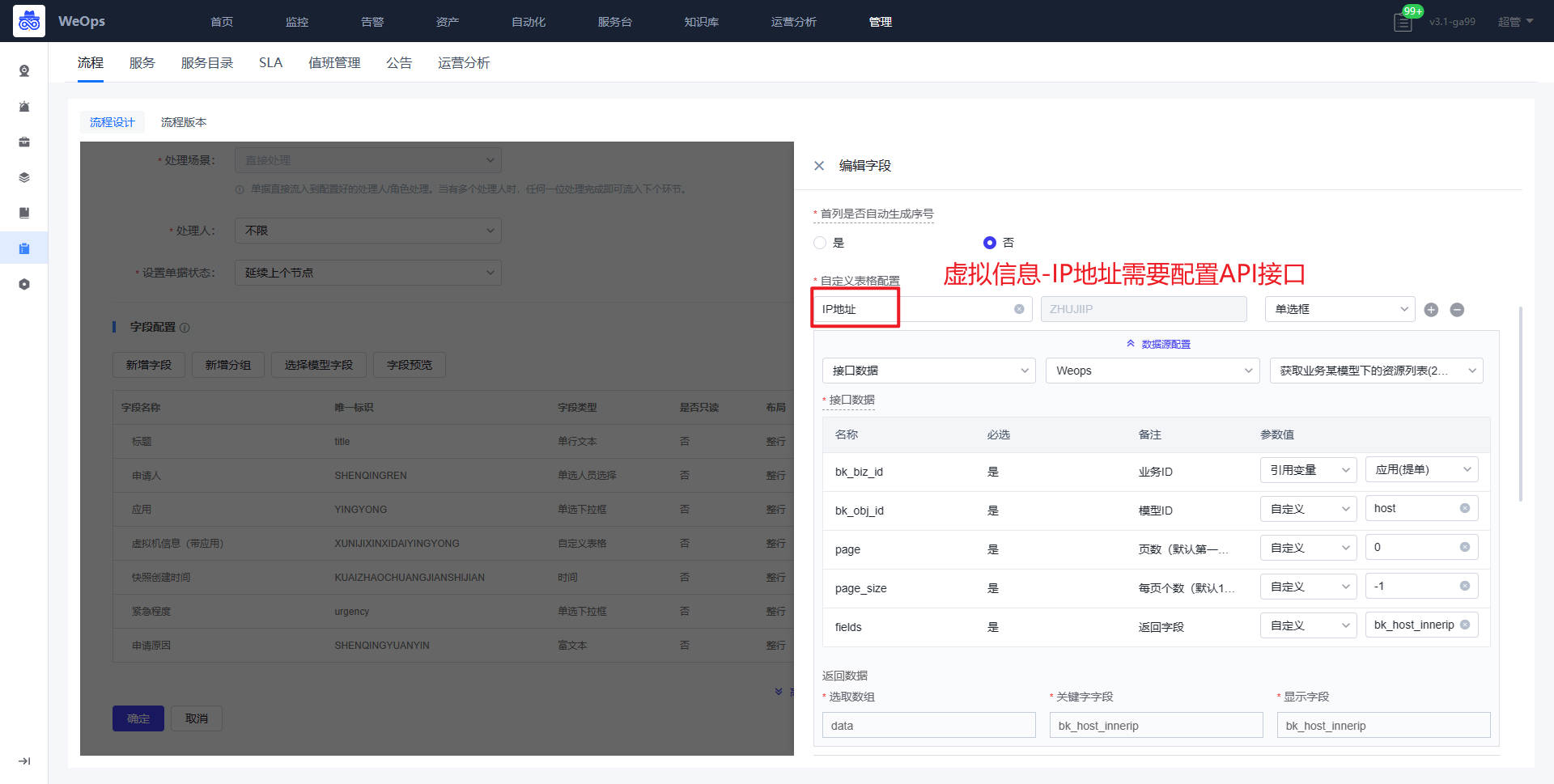
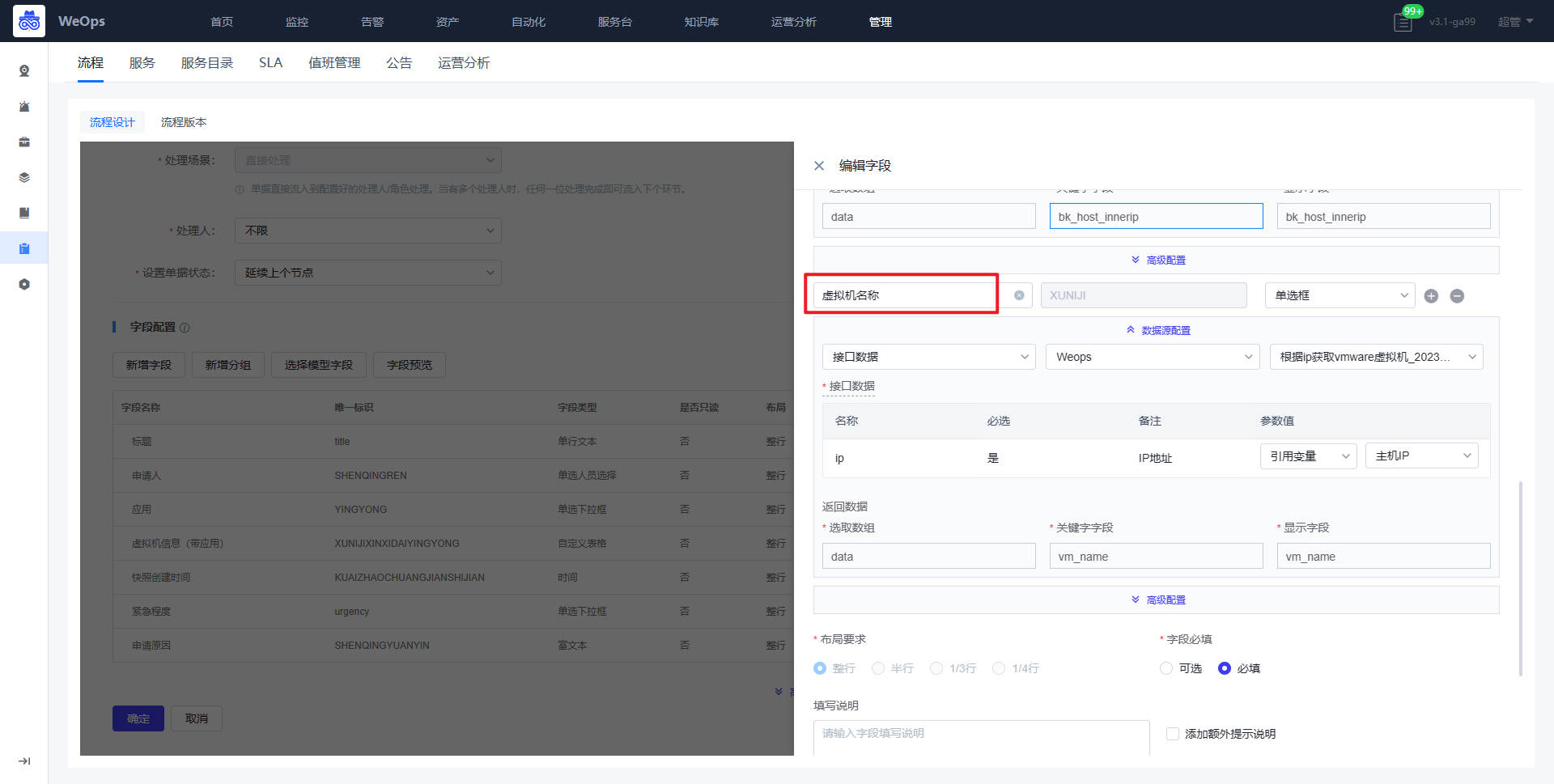
审批节点:接入点、Vcenter、VMware凭据三个字段需要配置API接口,作用如下:管理员对提单人提交申请,选择对应接入点,创建虚拟机的Vcenter以及其凭据,便于确定这个虚拟机创建的位置。(和虚拟机创建流程的配置方式一致)
审批节点:虚拟机信息中IP地址、虚拟机名称直接获取提单节点的信息,快照名称和描述为手填的,无需特殊配置。

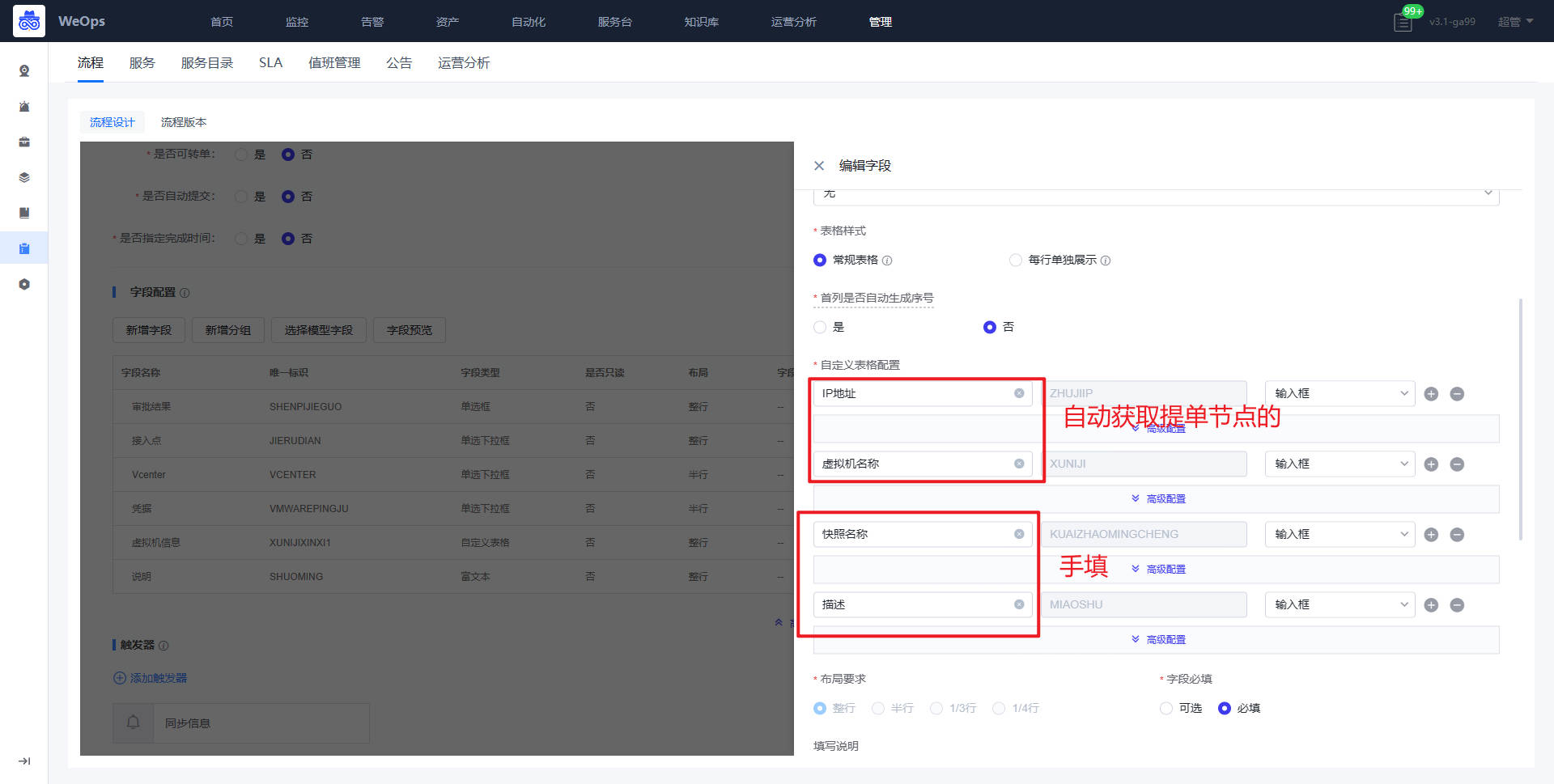
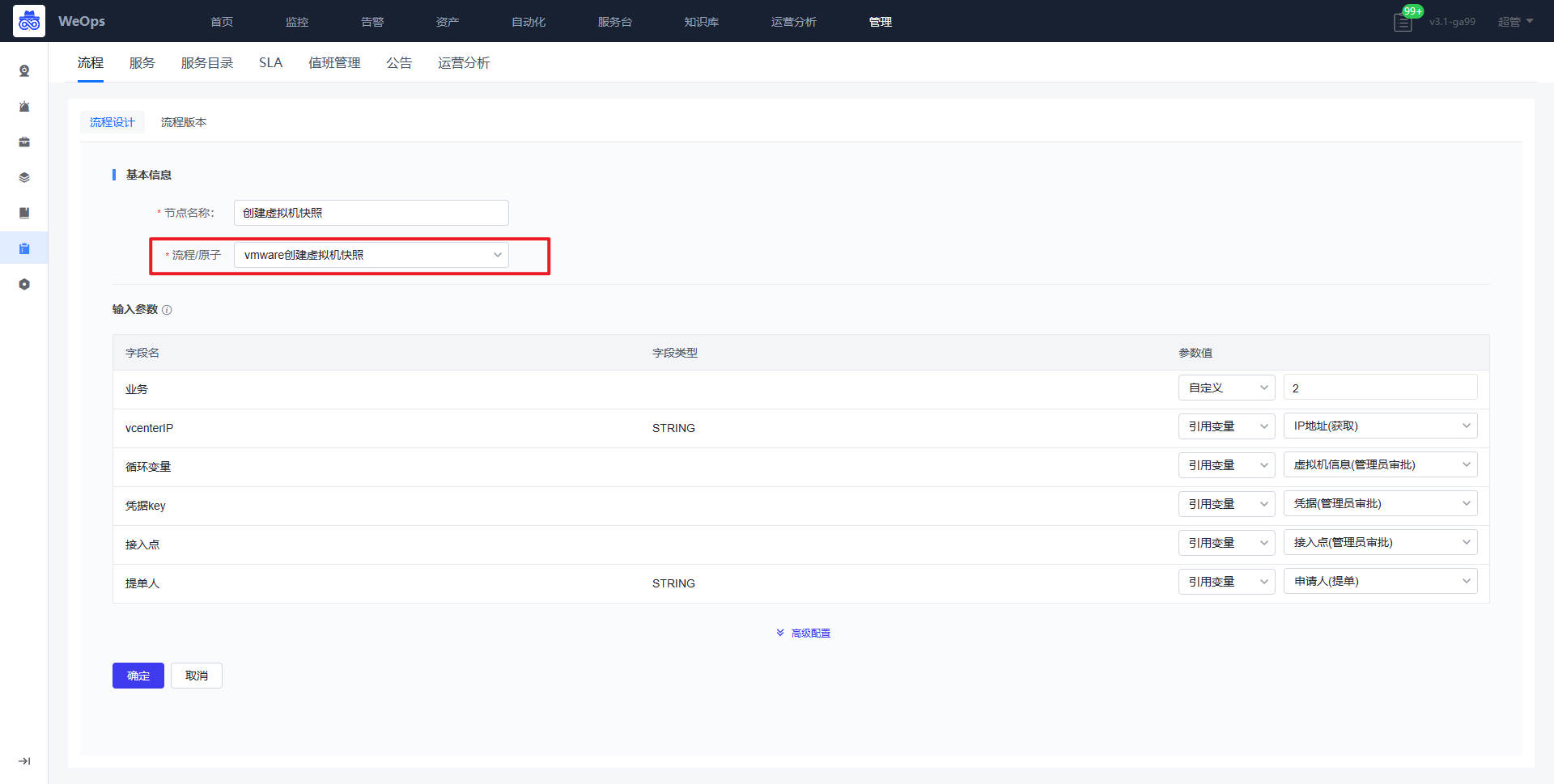
- 获取API详情节点:选择对应接口,填写对应的输入参数,勾选返回数据
- 自动执行节点:选择需要的自动流程,填写参数
虚拟机快照回滚
工单流程的重新配置重点在第二步“定义与配置流程”,接下来重点介绍下每个节点的流程应该如何配置。
- 提单节点:所属应用、虚拟机信息(IP地址、虚拟机名称、快照名称)需要对应配置API接口,作用如下:所属应用展示提单人有权限的应用,提单人选择应用后,可以展示该应用下的虚拟机IP列表和名称,便于提单人找下需要回滚的快照。

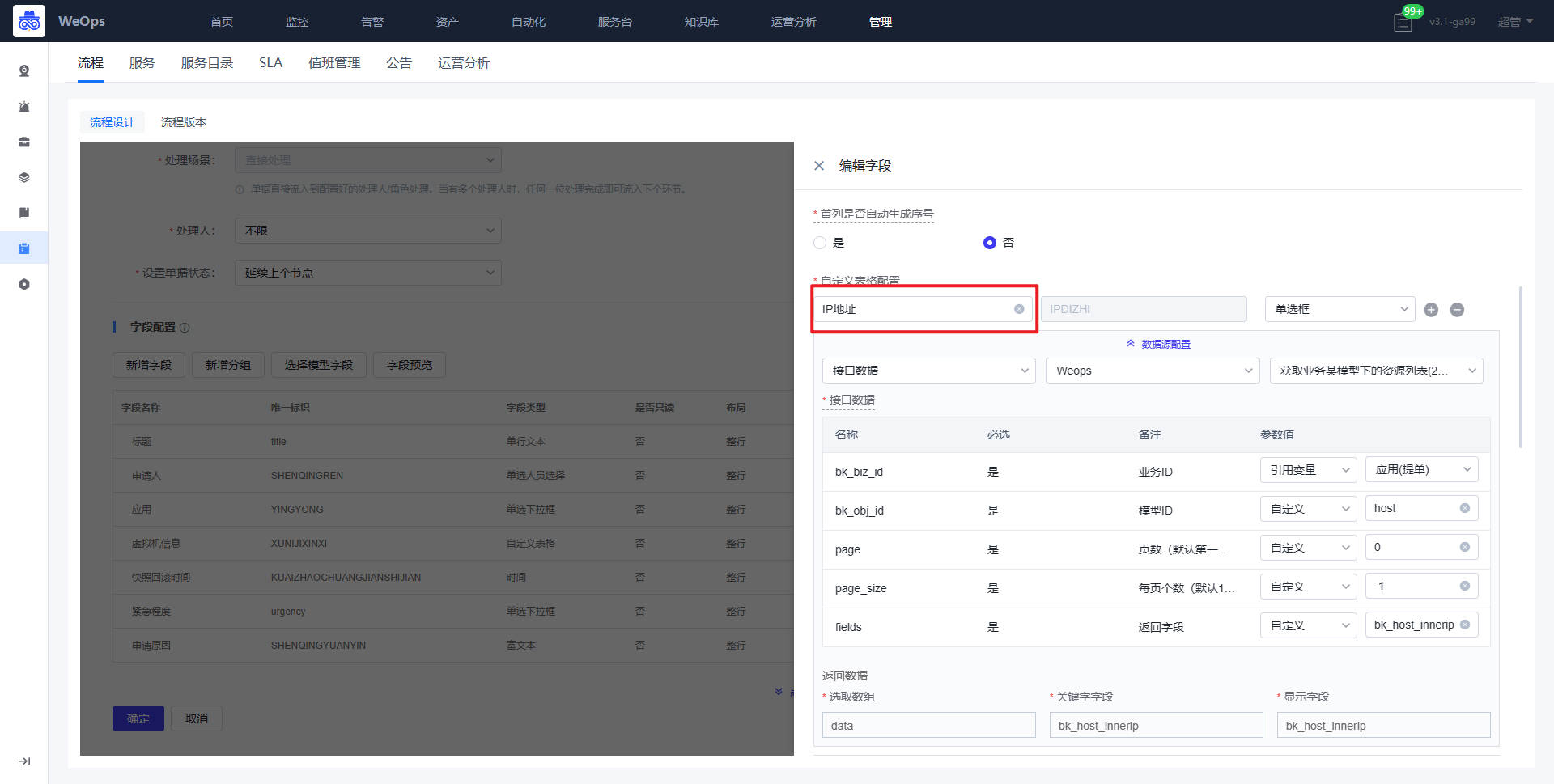
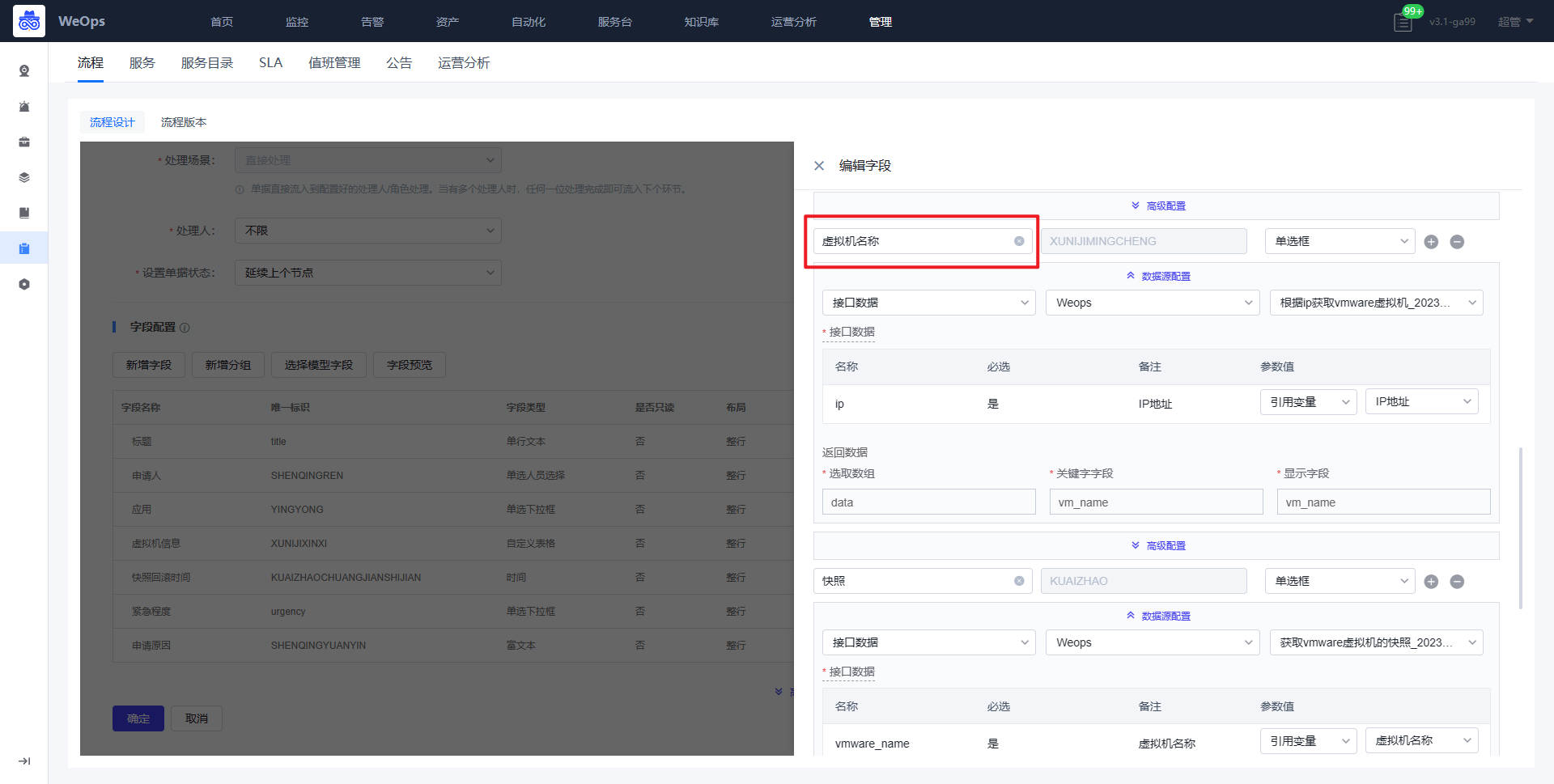

审批节点:接入点、Vcenter、VMware凭据三个字段需要配置API接口,作用如下:管理员对提单人提交申请,选择对应接入点和Vcenter以及其凭据,便于确定这个虚拟机的位置。(和虚拟机创建流程的API配置方式一致)
审批节点:虚拟机信息中IP地址、虚拟机名称、快照名称直接获取提单节点的信息,无需特殊配置。

- 获取API详情节点:选择对应接口,填写对应的输入参数,勾选返回数据
- 自动执行节点:选择需要的自动流程,填写参数

Step3:使用工单流程提单,进行虚拟机创建/快照创建/快照回滚
当流程配置好以后,可以进行提单操作(以虚拟机创建为例)
- 提单:用户提单时需要选择需要新建的虚拟机的配置信息,已经应用信息等,补充其他信息,进行提交。
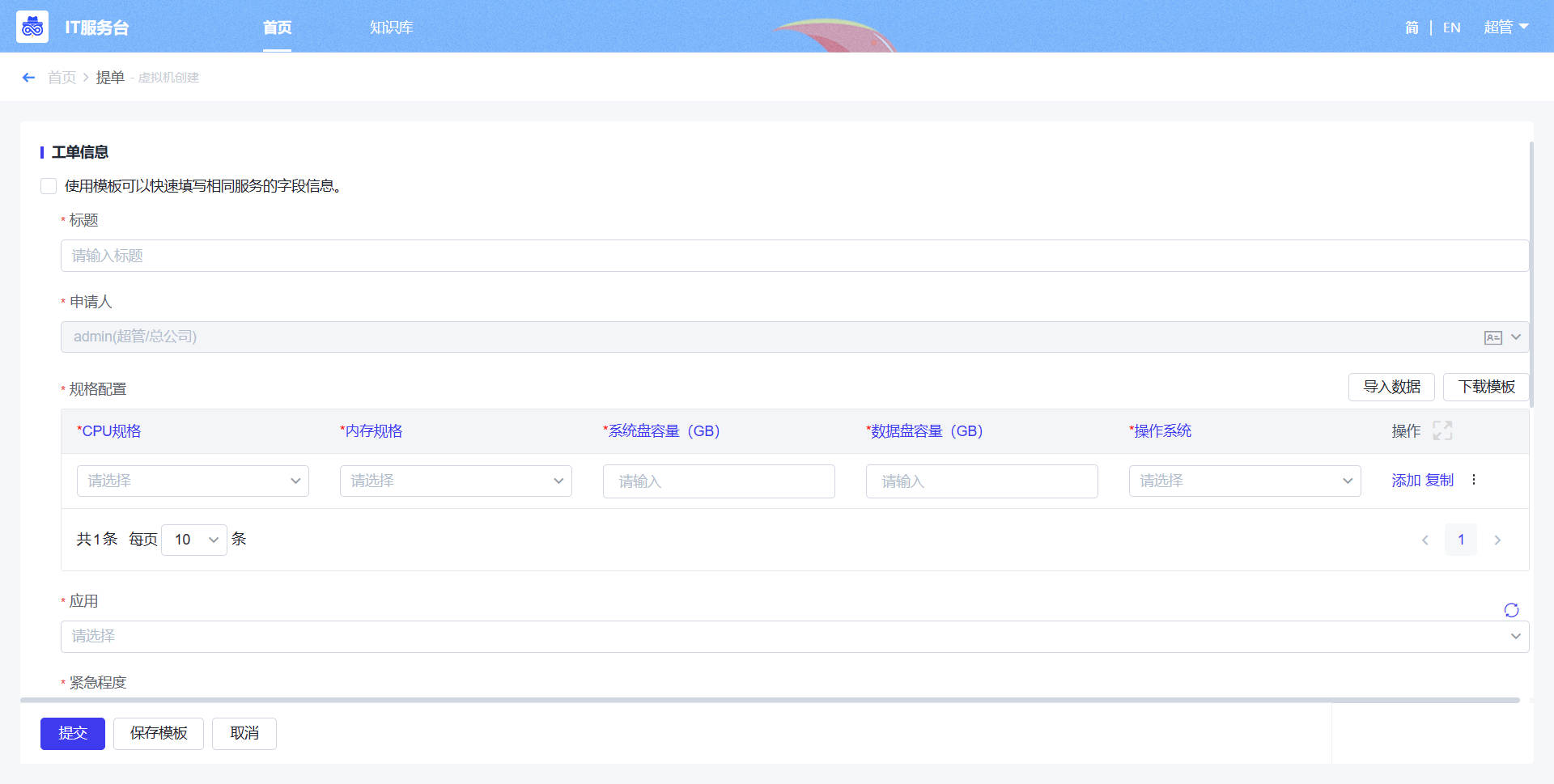
- 审批:管理员对提单人的申请信息进行审批,并选择对应的Vcenter,补齐虚拟机的相关配置信息后,提交进入到自动创建

- 自动执行:根据提单节点和审批节点填写的配置信息,进行自动的创建,创建完成之后,提单人会收到对应的通知。
