监控告警配置
关于WeOps各个对象的监控告警配置总示意图如下
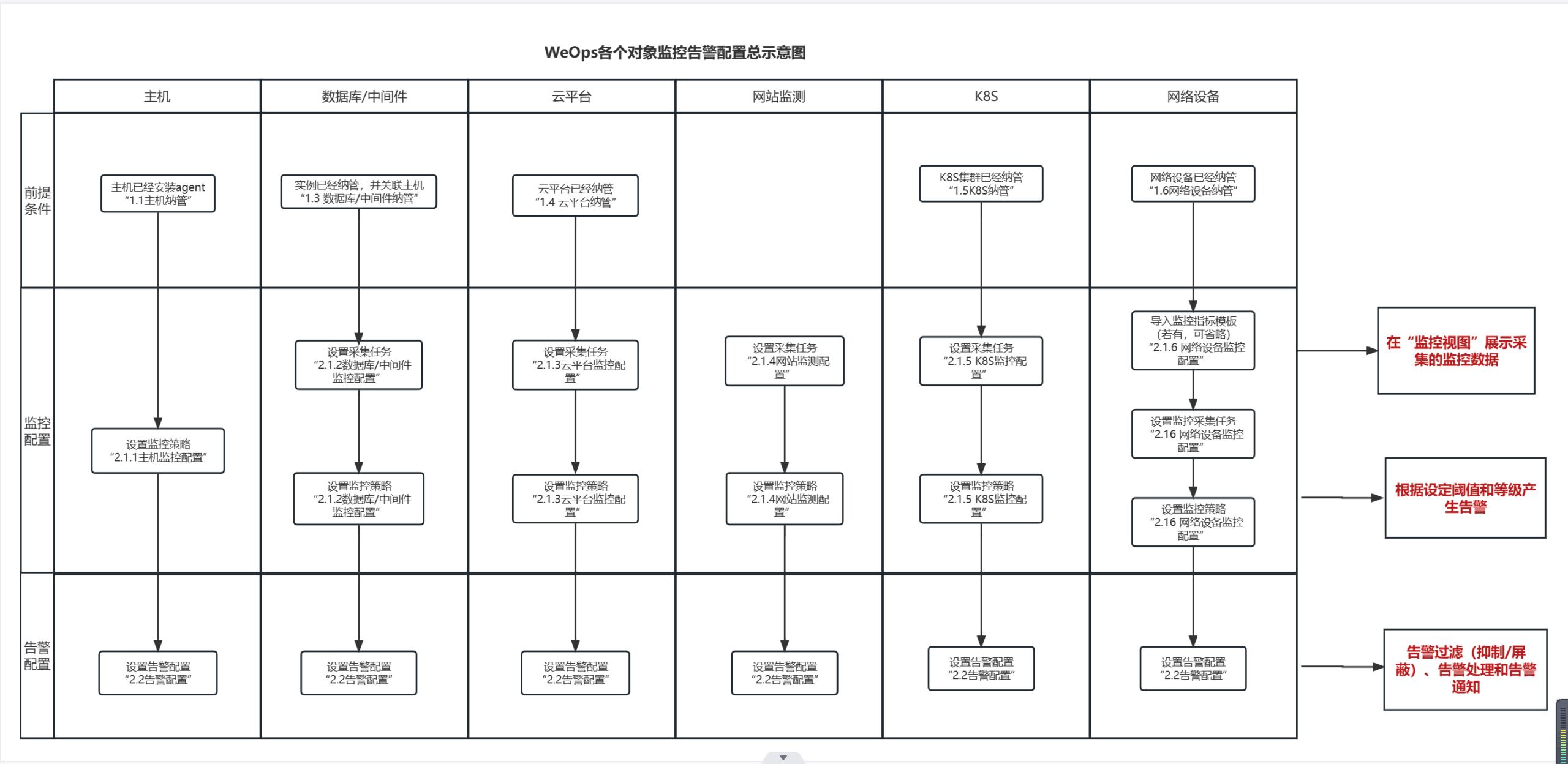
- 关于主机/数据库/中间件/k8s/云平台/网络设备的纳管,详情可参考“1、资源纳管”
- 各类对象的监控采集和监控策略配置,详情可参考“2.1 监控配置-分对象介绍”
- 各类对象的告警配置,包括告警抑制/告警屏蔽/自动处理/自动分派、人员通知,详情可参考“2.2告警配置”,各对象配置方法通用
2.1 监控配置
2.1.1主机监控配置
背景介绍:主机已经安装完Agent,已经完成纳管,纳管的步骤详情可见“1、资源纳管-主机纳管”,现需要对主机的监控策略进行配置。
Step1:监控采集
主机已经安装完Agent,就已经可以进行监控数据的采集,详情可见“1、资源纳管-主机纳管”这里不在赘述。
Step2:监控策略配置
路径:管理-监控管理-监控策略-主机
- 进入WeOps的管理中心的监控管理,找到监控策略。
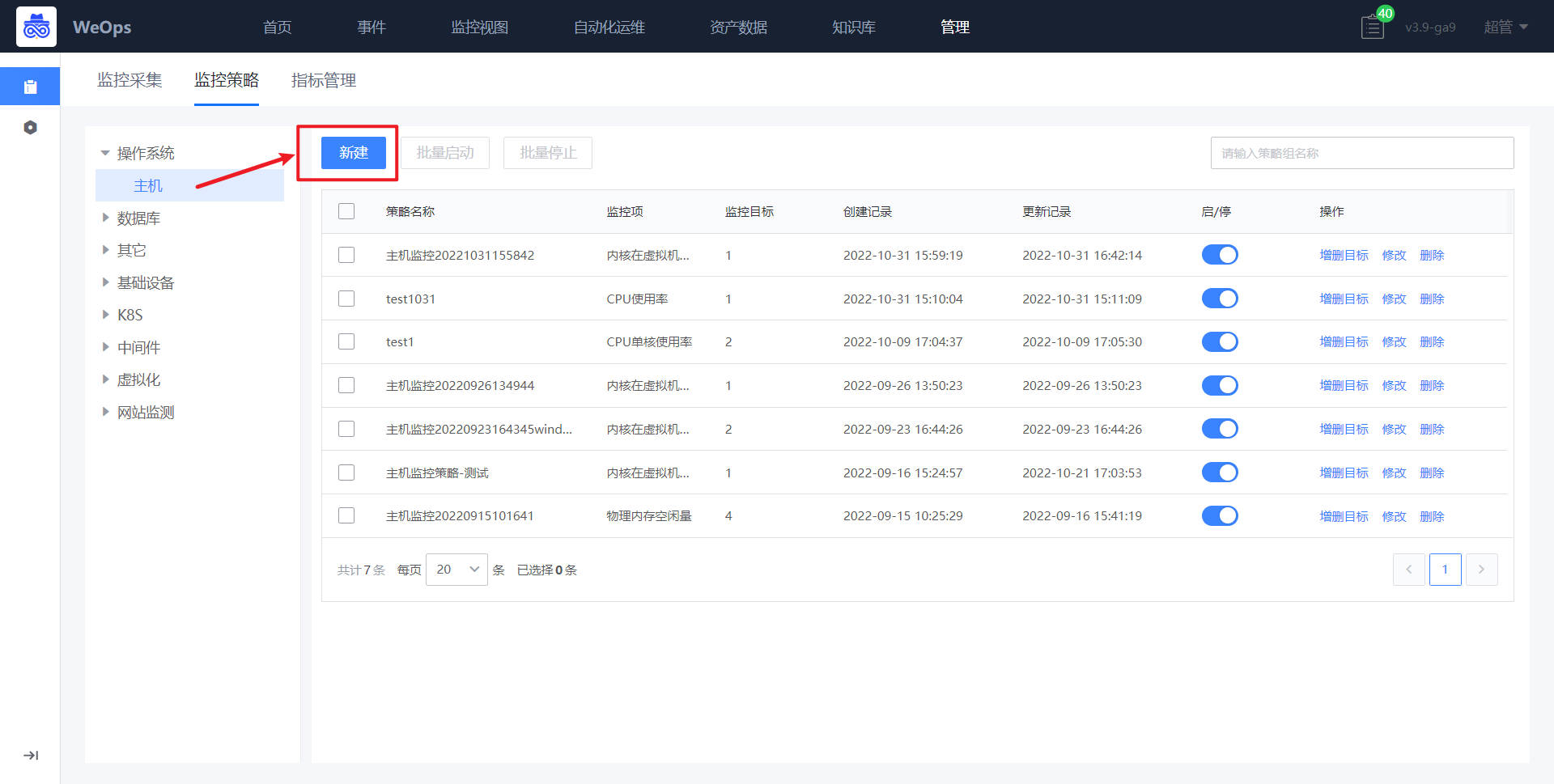
- 如下图所示,进入新建监控模板配置界面,默认填写策略名称、监控对象
- 如下图所示,点击“选择监控目标”,可以采用列表选择/静态拓扑选择的方式,选择需要监控的目标。

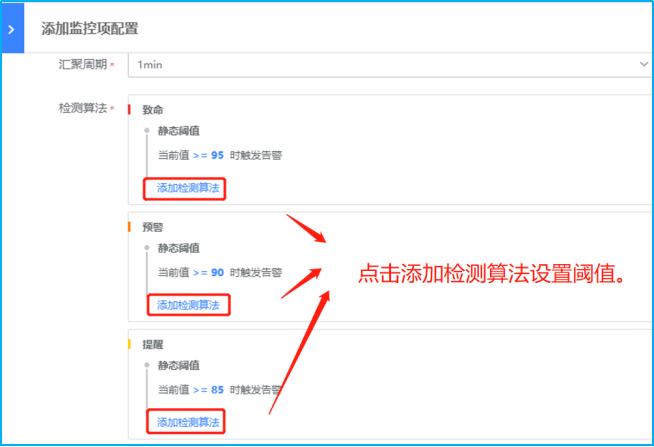
- 如下图所示,点击蓝色字体【添加监控项配置】即会弹出对应界面。主机监控项分为“指标”和“事件”两类。指标主要为常见的CPU、内存、磁盘、进程等监控指标。而事件则是指Agent心跳、Ping可达、主机重启等。

选择监控项为指标类,搜索监控项
选择汇聚方式为平均数,即AVG方式。SUM代表总数,AVG代表平均数,MAX代表最大值,MIN代表最小值,COUNT代表计数/总数。
选择汇聚周期,汇聚周期即采集数据的周期。(注:汇聚1min即是服务端每分钟向Agent采集1次数据。若是汇聚周期设置为5min则表示服务端向Agent每5分钟采集1次数据,此刻的Agent已经采集到了5次数据。之后,并根据汇聚方式将这5个数据进行计算(AVG/MAX/MIN等),计算得出的数值再于检测算法设置的阈值进行比较。)
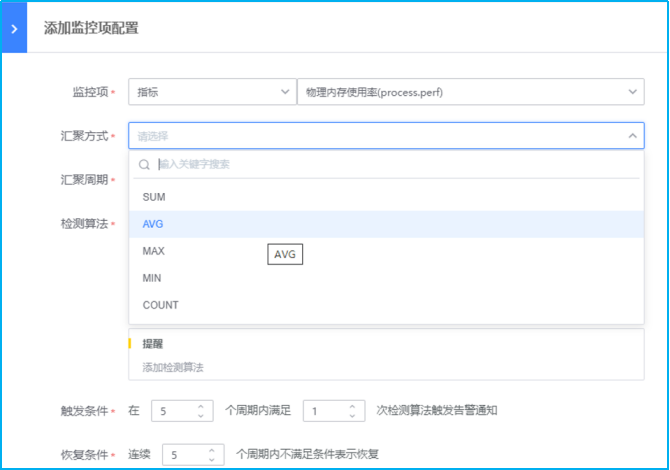
- 如下图所示,点击蓝色字体添加检测算法,进行不同监控等级阈值的设置。以下示例采用检测静态阈值触发告警。此外还有高级的阈值检测方式可选择:各种同比/环比策略,共有8种算法
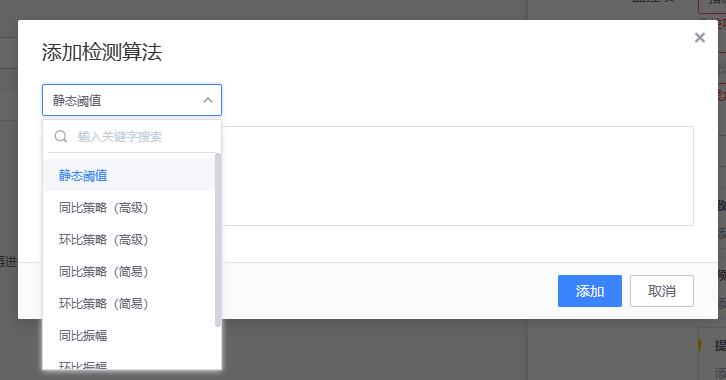
8种算法具体解释如下
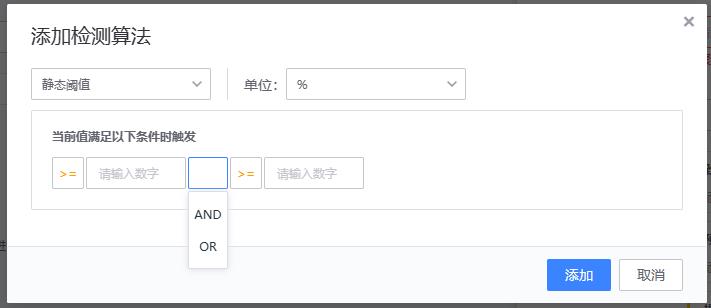
【1、静态阈值】静态阈值是最简单也是使用最普遍的检测算法,只要值满足条件即为异常。是一种固定的设定方法。大多数的都是以静态阈值为主。
适用场景: 适用于许多场景,适用可以通过固定值进行异常判断的。如磁盘使用率检测,机器负载等。
配置方法
实现原理
{value} {method} {threshold}
# value:当前值
# method:比较运算符(=,>, >=, <, <=, !=)
# threshold: 阈值
# 当前值 (value) 和阈值 (threshold) 进行比较运算
多条件时,使用and或or关联。 判断规则:or 之前为一组
例:
>= 10 and <= 100 or = 0 or >= 120 and <= 200
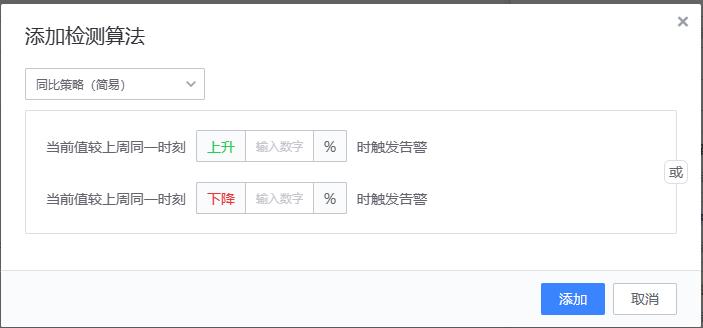
(>= 10 and <= 100) or (= 0) or (>= 120 and <= 200)【2、同比策略(简易)/同比策略(高级)】
适用场景:适用于以周为周期的曲线场景。比如 pv、在线人数等
配置方法
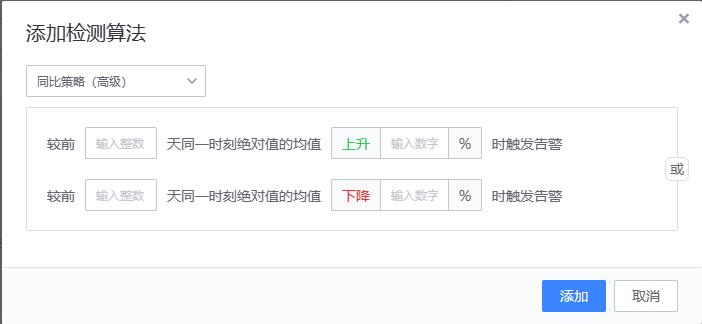
- 实现原理
同比策略(简易)
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:上周同一时刻值
# ceil:升幅
# floor:降幅
# 当前值(value) 与上周同一时刻值 (history_value)进行升幅/降幅计算
示例:当 value(90),ceil(100),history_value(40)时,则判断为异常
同比策略(高级)
# 算法原理和同比策略(简易)一致,只是用来做比较的历史值含义不一样。
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:前n天同一时刻绝对值的均值
# ceil:升幅
# floor:降幅
# 当前值(value) 与前n天同一时刻绝对值的均值 (history_value)进行升幅/降幅计算
# 前n天同一时刻绝对值的均值计算示例
以日期2019-08-26 12:00:00为例,如果n为7,历史时刻和对应值如下:
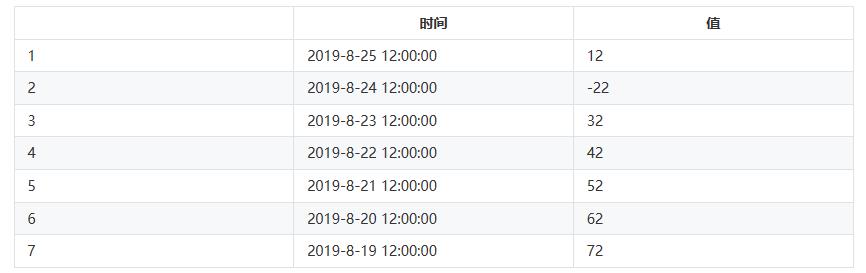
取绝对值,因此所有的值为正数
history_value = (12 + 22 + 32 + 42 + 52 + 62 +72) / 7 = 42
示例:当 value(90),ceil(100),history_value(42)时,则判断为异常
- 【3、环比策略(简易)/环比策略(高级)】
适用场景:适用于需要检测数据陡增或陡降的场景。如交易成功率、接口访问成功率等
配置方法
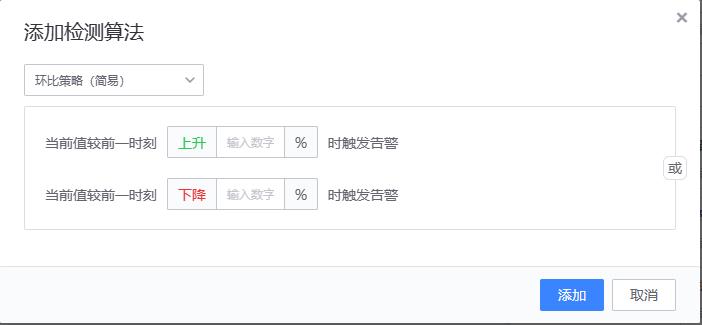
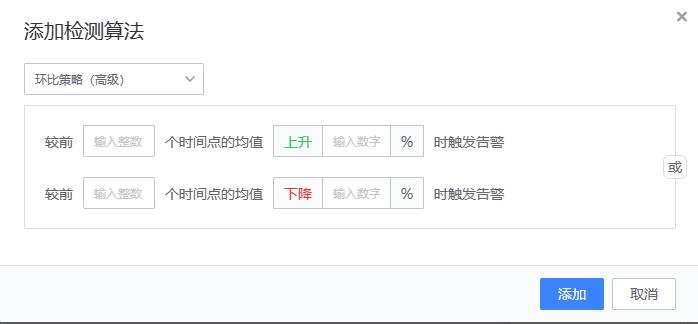
- 实现原理
环比策略(简易)
算法原理和同比策略(简易)一致,只是用来做比较的历史值含义不一样。
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:前一时刻值
# ceil:升幅
# floor:降幅
# 当前值(value) 与前一时刻值 (history_value)进行升幅/降幅计算
示例:当 value(90),ceil(100),history_value(40)时,则判断为异常
环比策略(高级)
# 算法原理和同比策略(简易)一致,只是用来做比较的历史值含义不一样。
{value} >= {history_value} * (100 + ceil) * 0.01)
or
{value} <= {history_value} * (100 - floor) * 0.01)
# value:当前值
# history_value:前n个时间点的均值
# ceil:升幅
# floor:降幅
# 当前值(value) 与前个时间点的均值 (history_value)进行升幅/降幅计算
# 前n个时间点的均值计算示例(数据周期1分钟)
以日期2019-08-26 12:00:00为例,如果n为5,历史时刻和对应值如下:

history_value = (12 + 22 + 32 + 42 + 52) / 5 = 32
示例:当 value(90),ceil(100),history_value(32)时,则判断为异常
【4、同比振幅】
适用场景:场景:适用于监控以天为周期的事件,该事件会明确导致指标的升高或者下降,但需要监控超过合理范围幅度变化的场景。比如每天上午 10 点有一个抢购活动,活动内容不变,因此请求量每天 10:00 相比 09:59 会有一定的升幅。因为活动内容不变,所以请求量的升幅是在一定范围内的。使用该策略可以发现异常的请求量。
配置方法
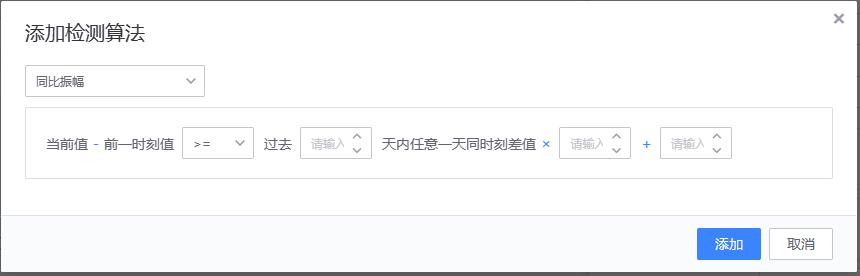
实现原理
# 算法示例:
当前值 − 前一时刻值 >= 过去 5 天内任意一天同时刻差值 × 2 + 3
以日期2019-08-26 12:00:00为例,如果n为5,历史时刻和对应值如下:
# 当前值
value = 26
# 前一时刻值
prev_value = 10
# 比较运算符(=,>, >=, <, <=, !=)
method = ">="
# 波动率
ratio = 2
# 振幅
shock = 3
# 当前值一前一时刻值的差值
current_diff = 16
# 5天内同时刻差值
prev5_diffs = [7, 6, 8, 10, 12]
前第二天(2019-8-24)同时刻差值: 6 * ratio(2) + shock(3) = 15
current_diff(16) >= 15
# 当前值(26) - 前一时刻值(10) >= 2天前的同一时刻差值6 * 2 + 3
此时算法检测判定为检测结果为异常:
【5、同比区间】
适用场景:温水煮青蛙型 - 数据缓慢上升或下降,适用于以天为周期的曲线场景。由于该模型中数据是缓慢变化的,所以使用【环比策略】、【同比振几幅】都检测不出告警,因为这两种模型主要使用于突升、突降、大于或小于指定值的情况。【同比区间】才适用于这种情况,因为随着数据的变化,当前值和模型值差距越来越大,而区间比较主要就是那当前值和历史模型值做比较。
配置方法

实现原理
# 算法示例:
当前值 >= 过去 5 天内同时刻绝对值 × 2 + 3
以日期2019-08-26 12:00:00为例,如果n为5,历史时刻和对应值如下:
# 当前值
value = 11
# 比较运算符(=,>, >=, <, <=, !=)
method = ">="
# 波动率
ratio = 2
# 振幅
shock = 3
前第3天(2019-8-23)同时刻值: 13 * ratio(2) + shock(3) = 26
value(26) >= 26
# 当前值(26) >= 3天前的同一时刻绝对值13 * 2 + 3
此时算法检测判定为检测结果为异常:【6、环比振幅】
适用场景:适用于指标陡增或陡降的场景,如果陡降场景,ratio(波动率)配置的值需要 < -1 该算法将环比算法自由开放,可以通过配置 波动率 和 振幅,来达到对数据陡变的监控。同时最小阈值可以过滤无效的数据
配置方法

实现原理
# 当前值(value) 与前一时刻值 (prev_value)均>= (threshold),且之间差值>=前一时刻值 (prev_value) * (ratio) + (shock)
# value:当前值
# prev_value:前一时刻值
# threshold:阈值下限
# ratio:波动率
# shock:振幅
以日期2019-08-26 12:00:00为例:
# 当前值
value = 46
# 前一时刻值
prev_value = 12
# 波动率
ratio = 2
# 振幅
shock = 3
value(46) >= 10 and prev_value(12) >=10
value(46) >= prev_value(12) * (ratio(2) + 1) + shock(3)
此时算法检测判定为检测结果为异常:
# 当前值(46)与前一时刻值(12)均>= (10),且之间差值>=前一时刻值 (12) * (2) + (3)
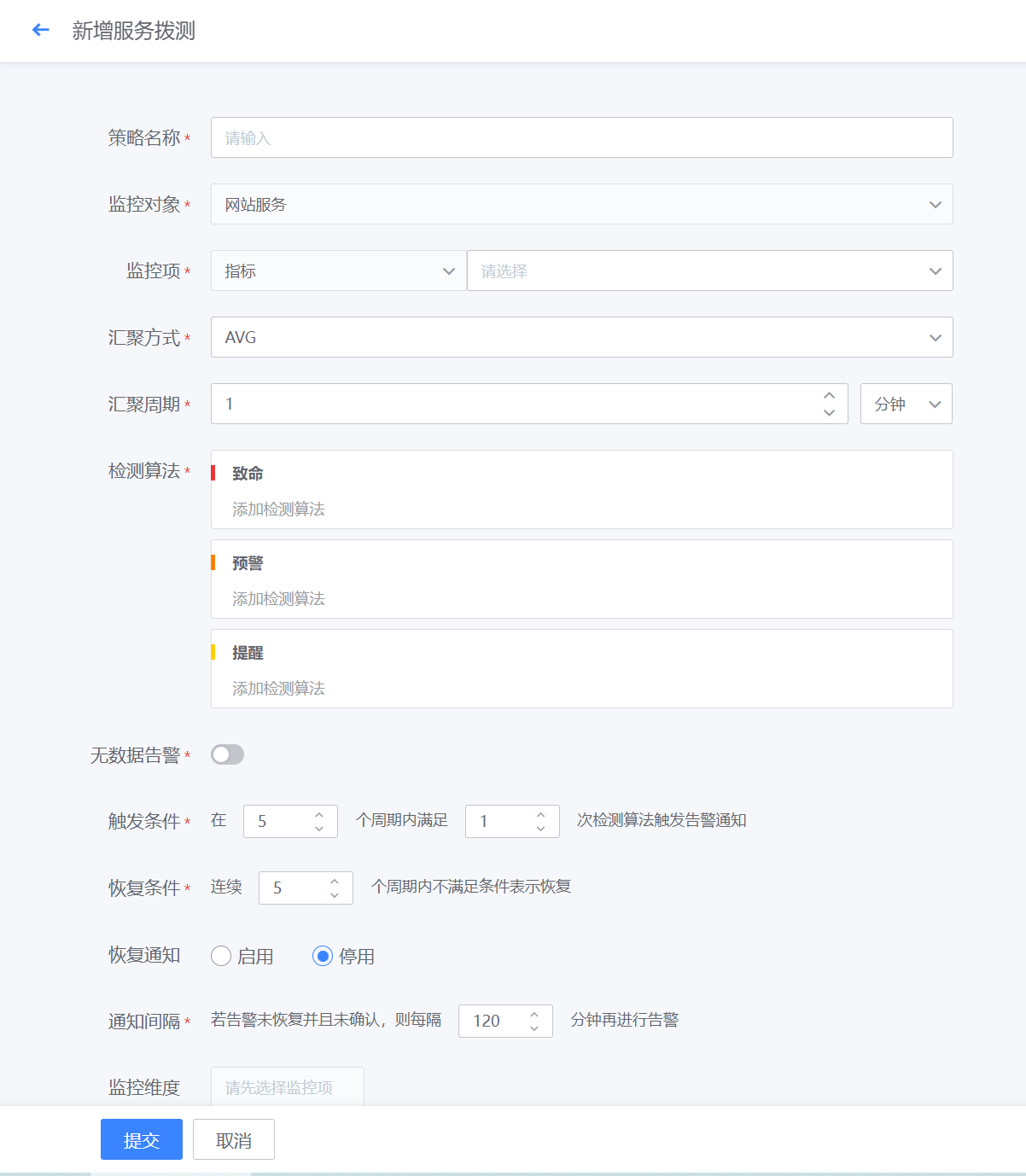
- 如下图所示,进行“触发条件”、“恢复条件”、“无数据告警”、“监控纬度”以及“监控条件”的设置。
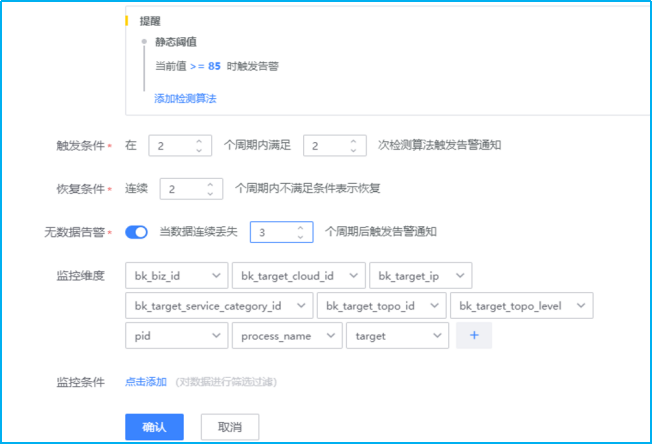
触发条件:2个周期内满足2次检测算法触发告警。结合以上汇聚周期1min(监控数据采集周期也是1min),汇聚方式设置为AVG平均数(1个数的平均数亦是其本身)。综上,每分钟检测1次,连续2次检测满足检测算法设置的阈值即会触发对应的告警等级。
恢复条件:连续2个周期内不满足条件表示恢复。表示:每分钟检测1次,连续2次检测不满足即表示恢复。
无数据告警:开启。当数据连续丢失3个周期后触发告警通知。表示:每分钟检测1次数据汇聚情况,若是连续3次(即3分钟内无任何数据),则触发无数据告警通知。
监控纬度:不同的监控项有不同的监控纬度。默认监控所有纬度,可以根据需求进行增删。默认情况下是监控所有纬度。例如监控项磁盘空间,那么windows的监控纬度则会是自发现的C:\ D:\ E:\等,而Linux则会是/、/root、/dev等。
监控条件:监控条件是对监控纬度的筛选,若是不选择则代表监控所有纬度。磁盘监控项中若是监控条件选择C:\则代表只监控磁盘C分区。
如下图所示,对监控项进行一一添加后再进行其他配置即可完成监控策略的配置。
主机监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
下一步“告警配置”可查看“2.2告警配置”
2.1.2 进程监控配置
背景介绍:进程监控采集任务配置好下发到目标机器后,会基于采集的任务信息进行工作。通过配置需要监控的进程名,条件可以选择包含/不包含(排除)某些命令行的关键字,过滤出需要的进程,然后探测该进程是否开启端口(可选功能),同时会采集该进程的相关使用情况。
Step1:监控采集
监控采集的创建有两种路径进入
- 第一种,通过主机监控视图进入
路径:监控-基础监控-主机
如下图,第一步,一键获取主机进程列表:在主机监控中,可以直接获取进程列表。二三步,快捷创建监控任务:对需要监控的进程,快捷创建监控采集任务,并且自动填充关键信息。第四步,任务创建完成后,可以在进程视图中,正常查看该进程的监控情况



- 第二种,直接在监控采集创建
路径:管理-监控管理-监控采集
如下图,进入到进程采集的页面,点击进行端口采集新建。目前仅支持主机的进程采集和监控。

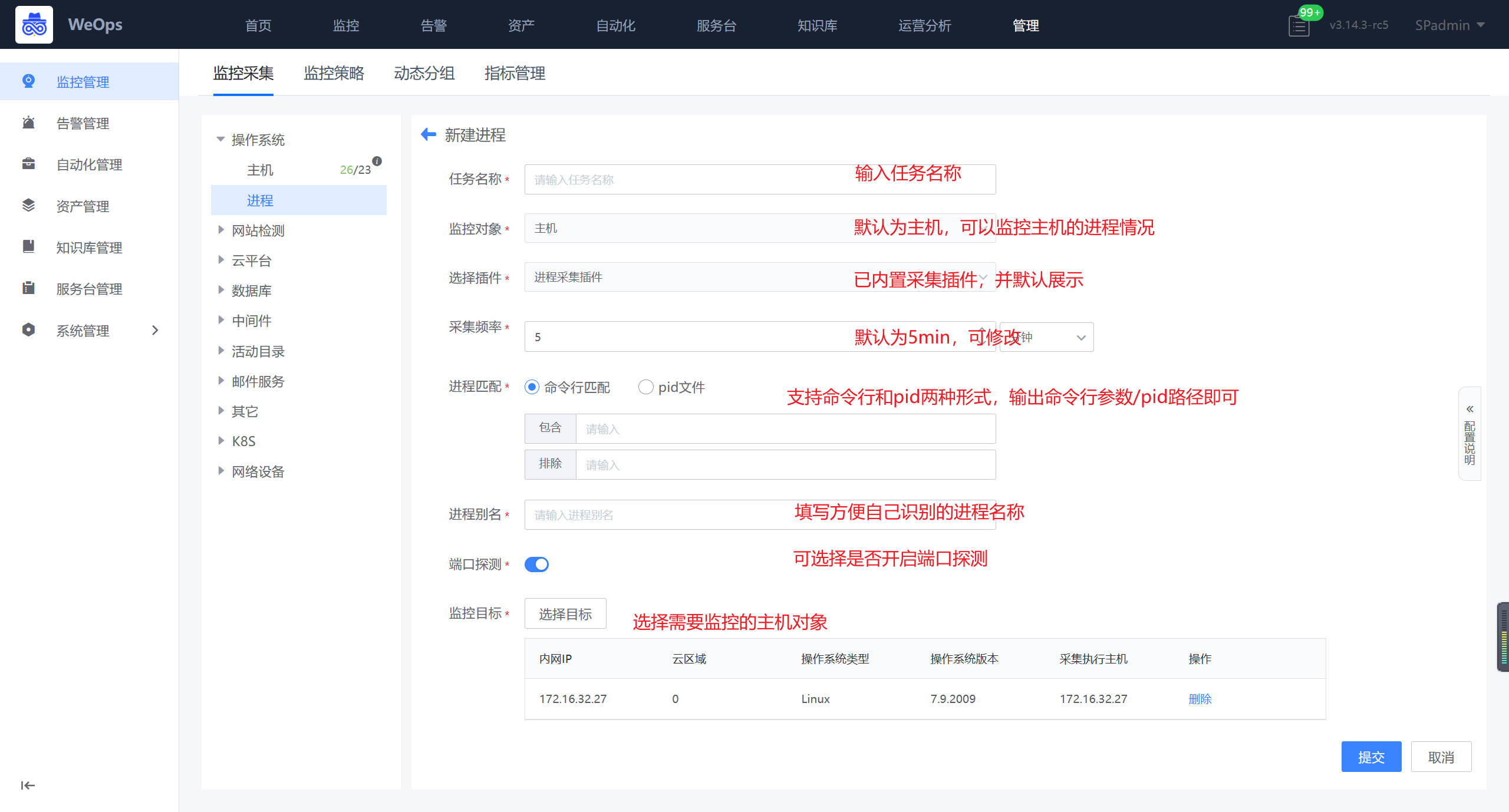
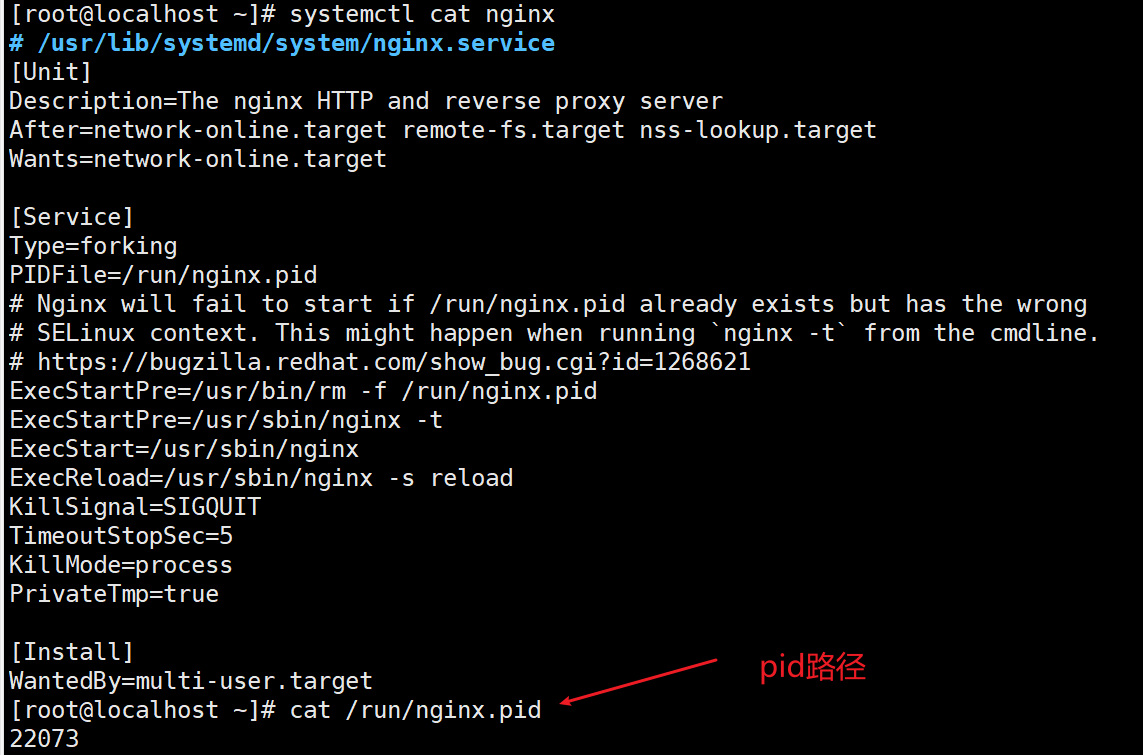
- 两种匹配方式,一种是命令行匹配,查询到命令行关键词,把参数复制进来就可以了,一种是pid路径匹配,把pid路径复制进来,命令行和pid两类详细说明如下
1、命令行参数:通过命令 ps -ef 获取到需要监控的进程的命令参数,在进程监控配置中,填写命令行参数,如果出现命令行参数无法区分两个进程的情况,可以采用排除关键词的方式,准确定位到需要监控测进程。
包含:进程匹配字符串,一般是进程的名称,注意Linux是cmdline, windows是匹配进程名。
排除:即不上报的进程,可以填写正则表达式,如(\d+),不采集匹配数字的进程。
如下图是通过命令 ps -ef 搜索到所有进程,以及进程的命令行参数(linux)

2、pid比较准确,可以准确识别到需要监控的进程,但是对程序的运行有要求,并非每个进程都会有pid文件,所以建议使用命令行的方式进行监控进程。
- 主机的进程采集设置完成后,可以在主机的对应监控视图中,查看该主机所有进程的监控情况,如下图

Step2:监控策略配置
路径:管理-监控管理-监控策略
如下图,在监控策略页面,找到主机,点击“创建”按钮,进行主机进程的监控策略的创建
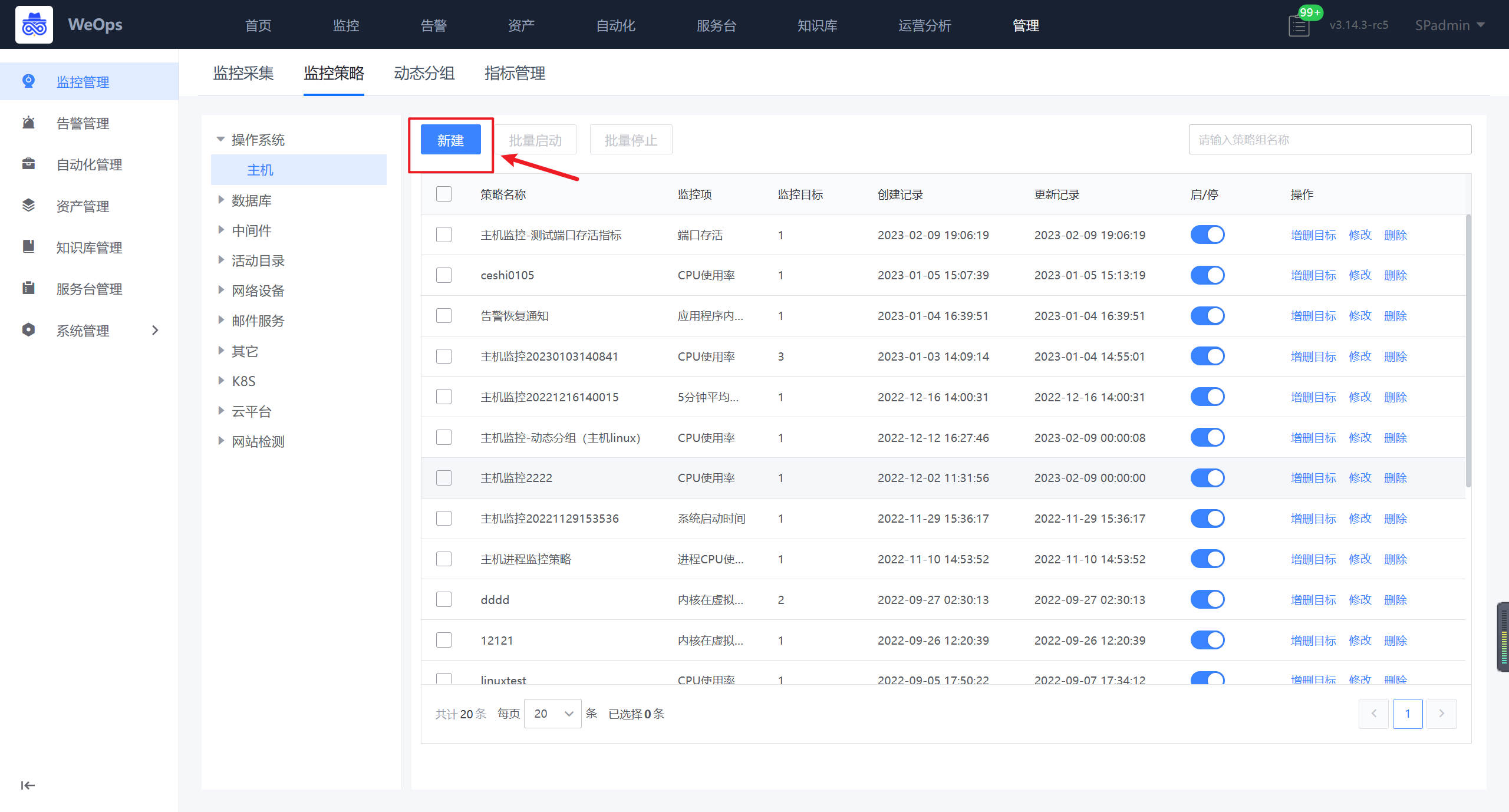
- 如下图所示,填写策略名称,进行监控项的添加(选择进程类的指标)、监控阈值的配置、监控对象的选择等之后,点击保存即完成监控阈值的配置。
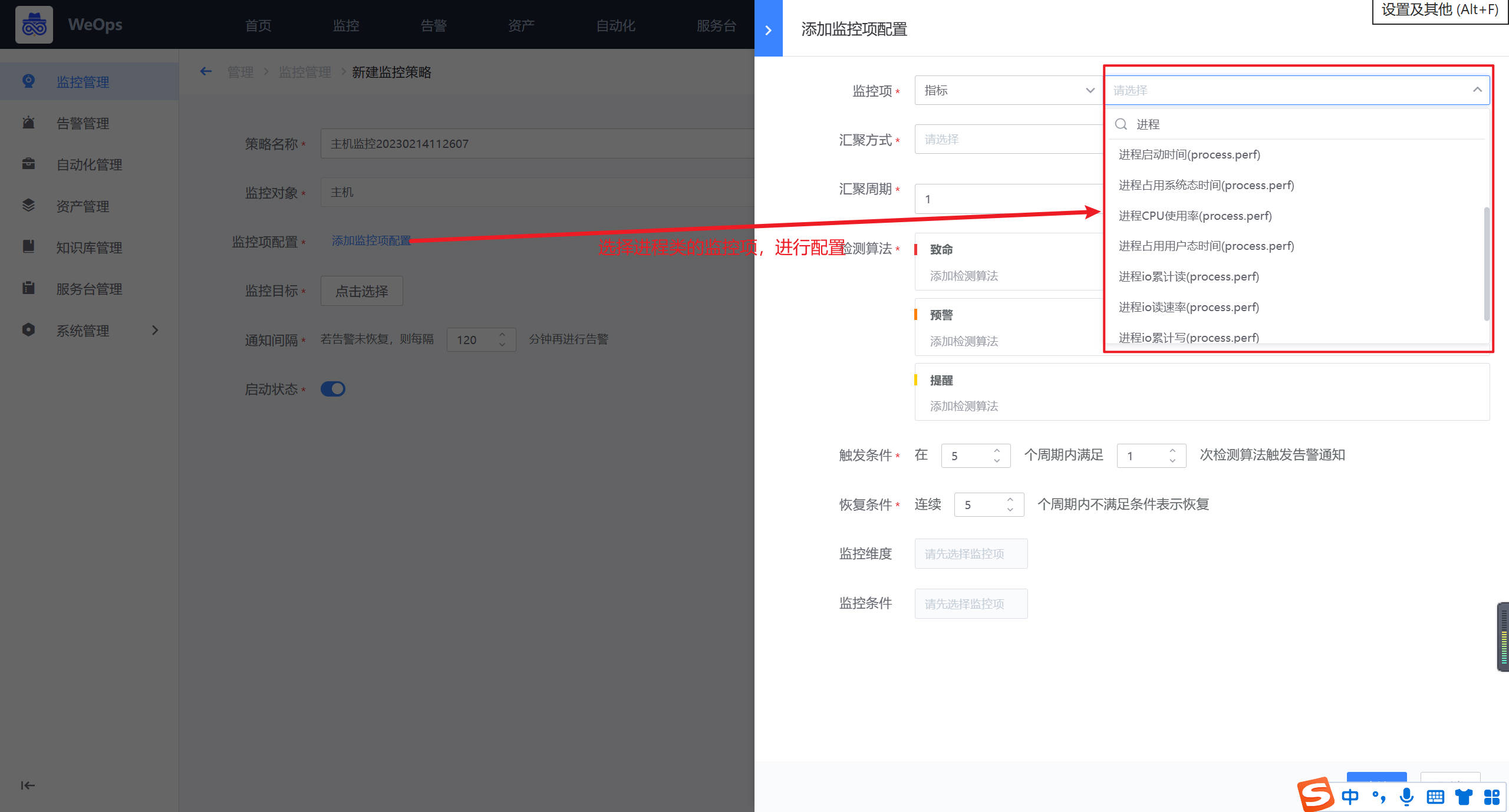
配置完成后,可以根据设定的指标、阈值和告警等级等产生对应的告警。
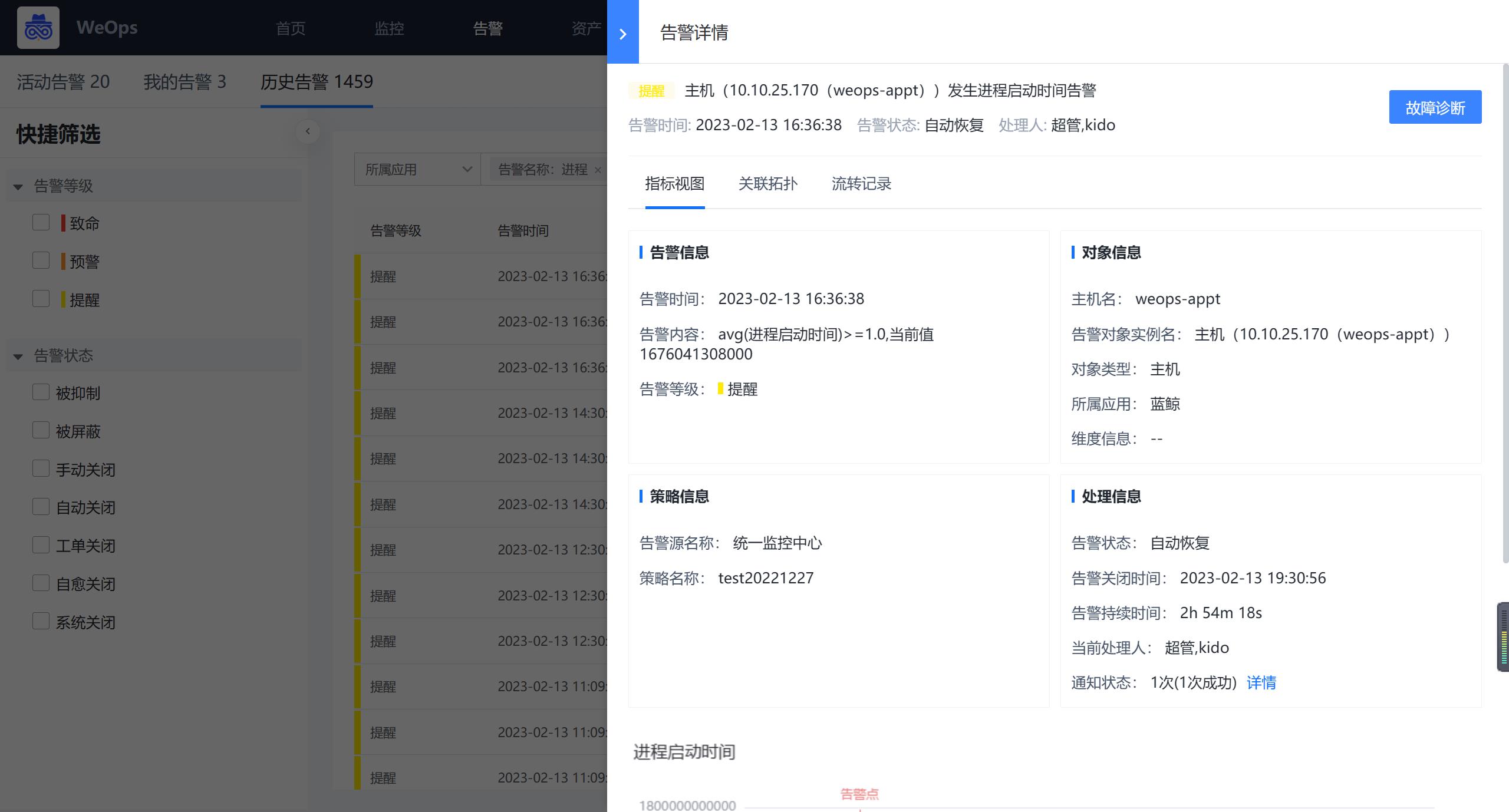
2.1.3 数据库/中间件监控配置
背景介绍:需要将数据库/中间件的实例已经新建完成,并且与对应主机已经建立了关联,数据库/中间件纳管的步骤详情可见“1.3 数据库/中间件纳管”,现需要对该实例进行监控采集和监控策略的设置。(这里以oracle为例进行介绍。)
Step1:监控采集
路径:管理-监控管理-监控采集
- 如下图所示,进入监控采集页面,点击数据库-oracle,进行oracle监控采集任务新建。
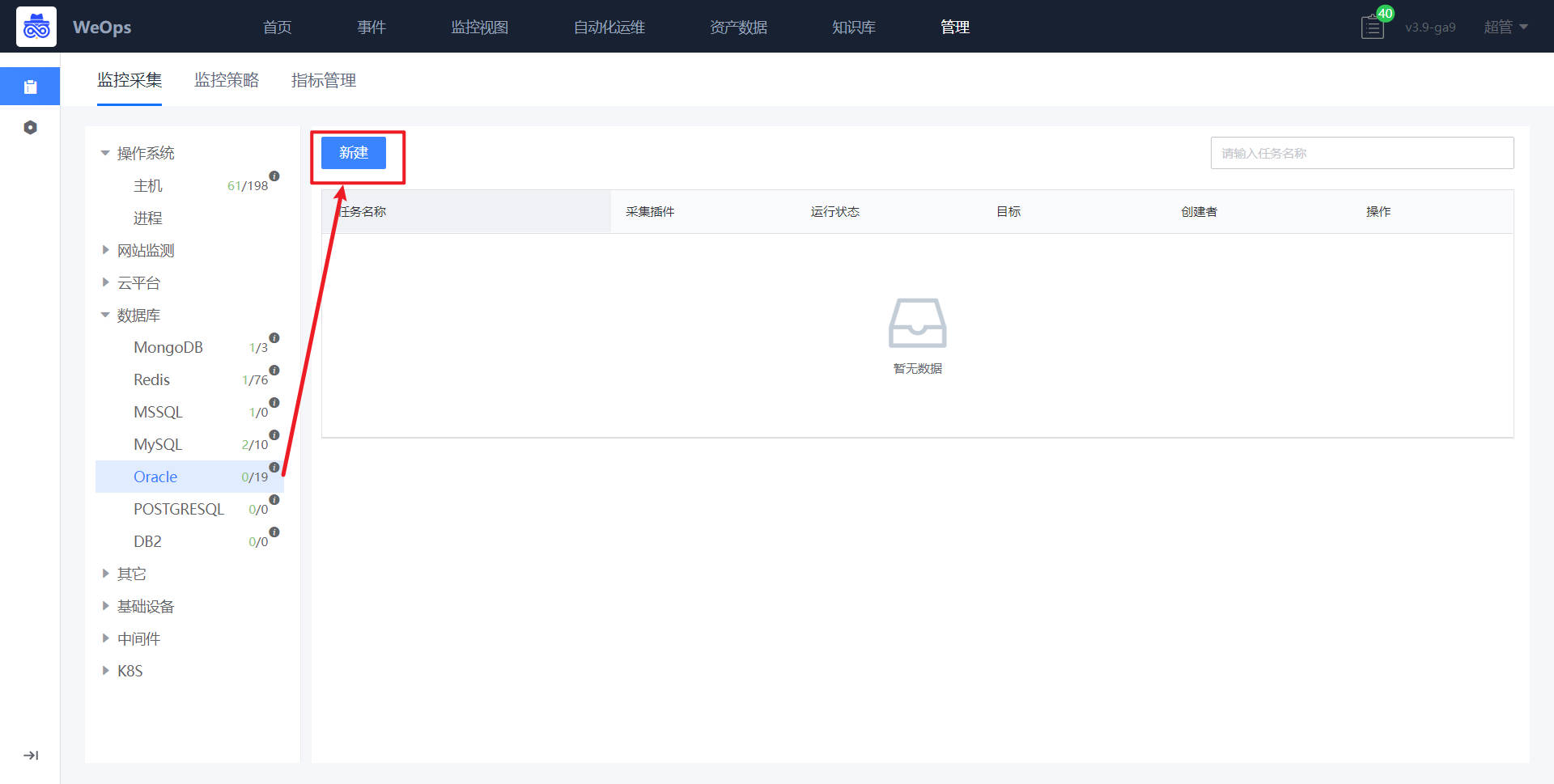
如下图所示,采集任务、监控对象、采集插件、采集频率等信息已经默认填写,只需要选择目标(监控oracle主机)
如下图所示,在选择完监控目标后,若所有目标的监控采集参数一致,则在全局参数中填写,若是特殊oracle主机节点有不同的监控采集参数,例如账号密码等,则在对应监控目标后填写。
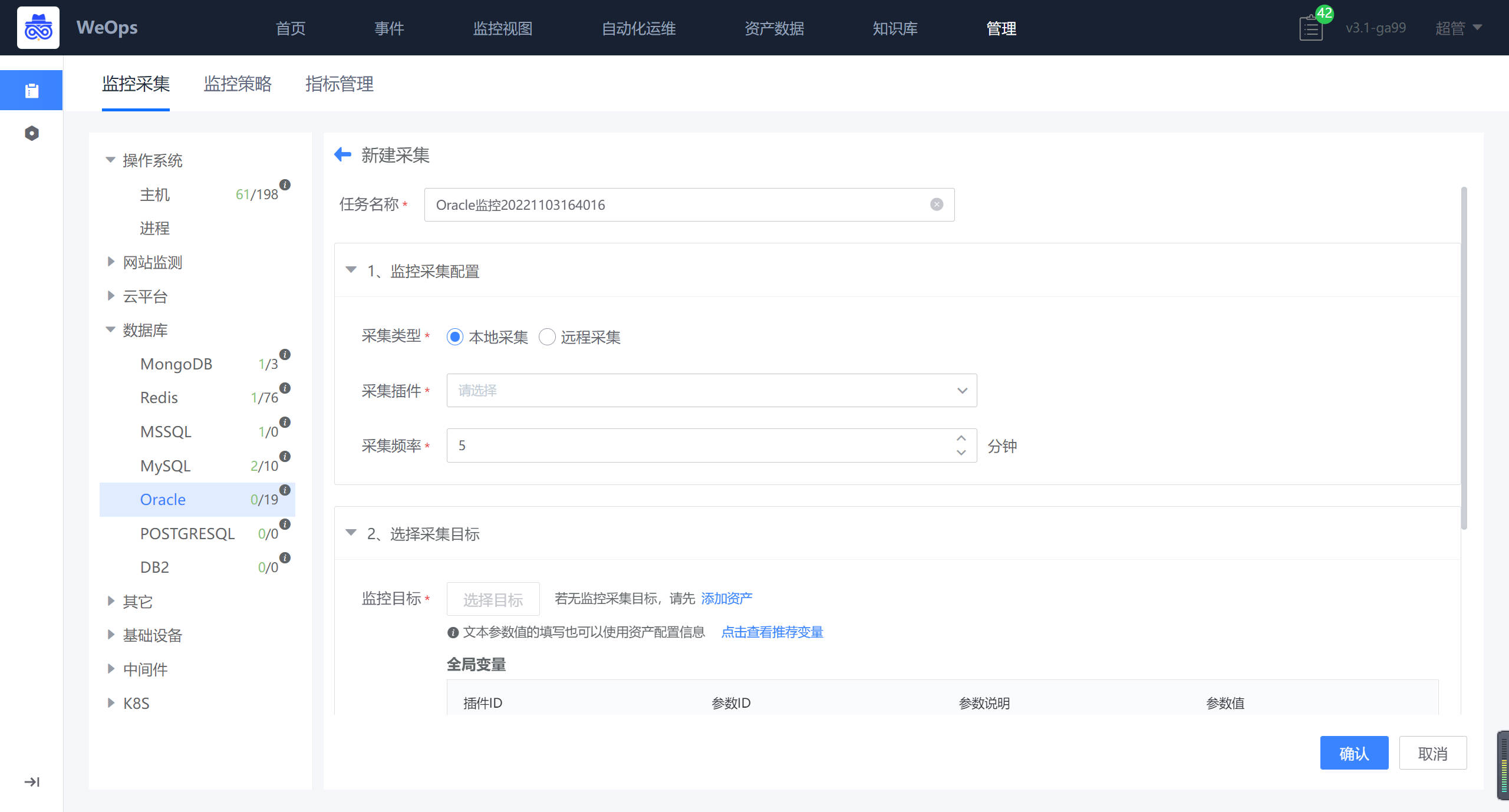
- 数据库/中间件的监控采集配置完成后,可在“监控视图-基础监控-数据库/中间件”中查看对应的监控情况和监控视图。
Step2:监控策略配置
路径:管理-监控管理-监控策略
- 如下图所示,进入到监控管理的监控策略页面,点击新增监控配置。
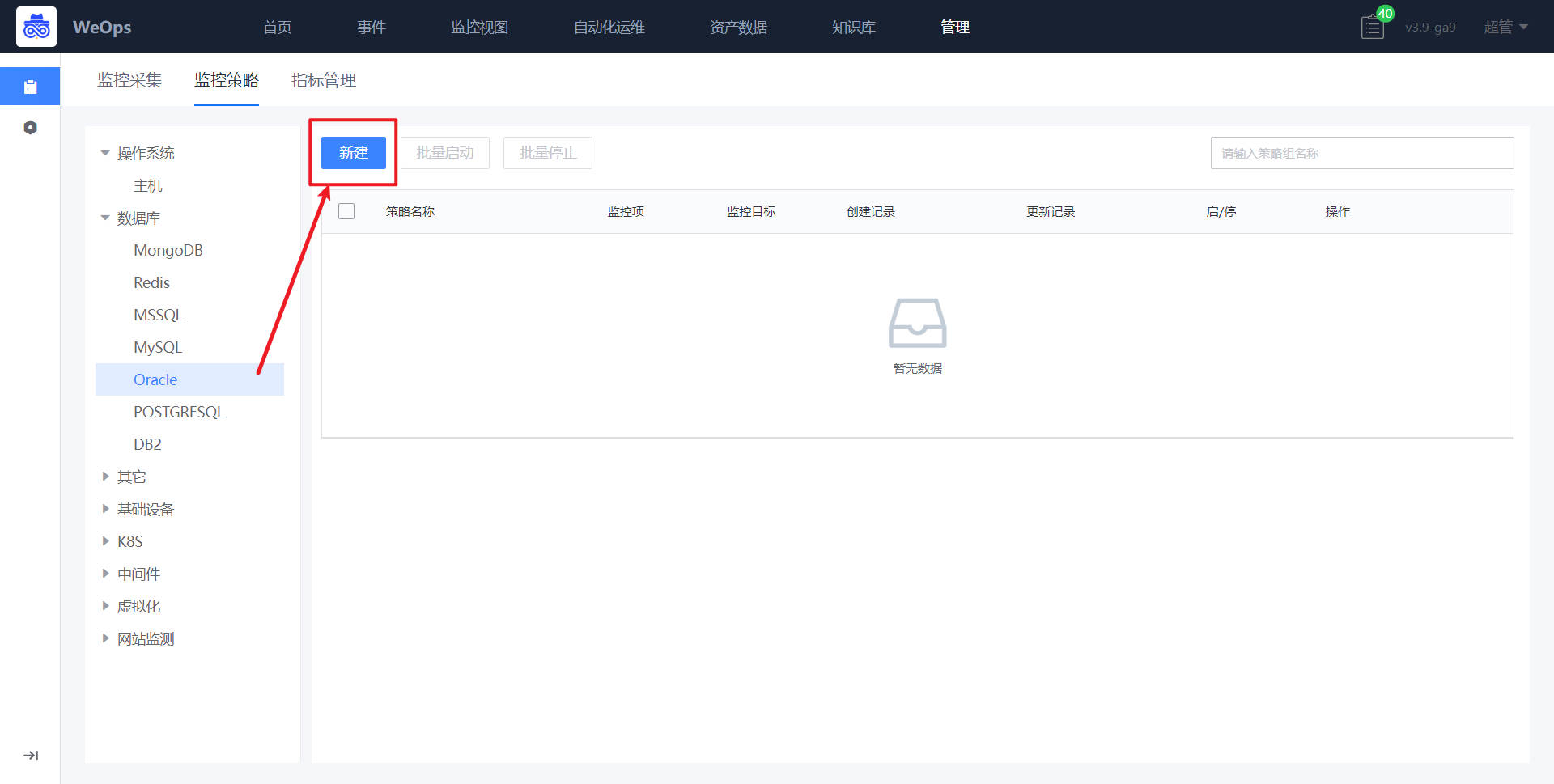
- 如下图所示,依照主机监控配置方式(可参见“1、资源配置-监控配置-主机监控配置”),进行监控项的添加、监控阈值的配置、监控对象的选择等之后,点击保存即完成监控阈值的配置。
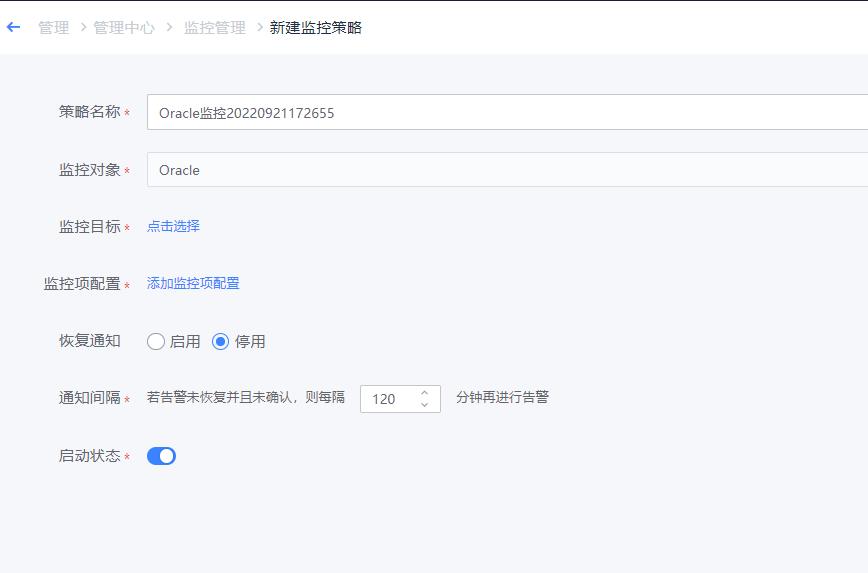
- 数据库/中间件监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
2.1.4 云平台监控配置(以腾讯云为例)
背景介绍:需要将云平台纳入监控数据采集中,包括VMware、腾讯云和阿里云等,并设置对应监控策略。
Step1:监控采集
路径:管理-监控管理-监控采集
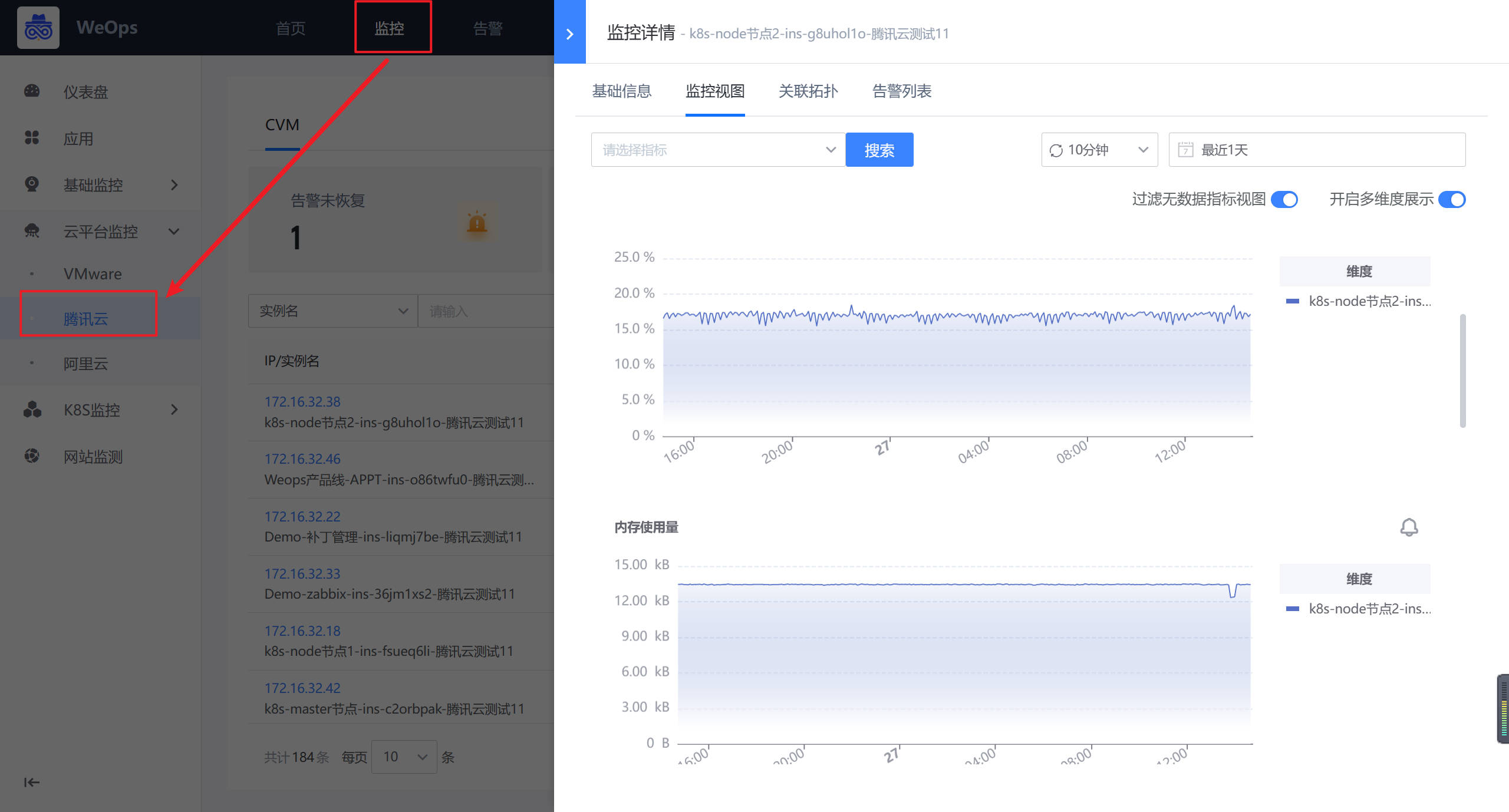
- 如下图所示,进入云平台的监控采集界面,进行新增。
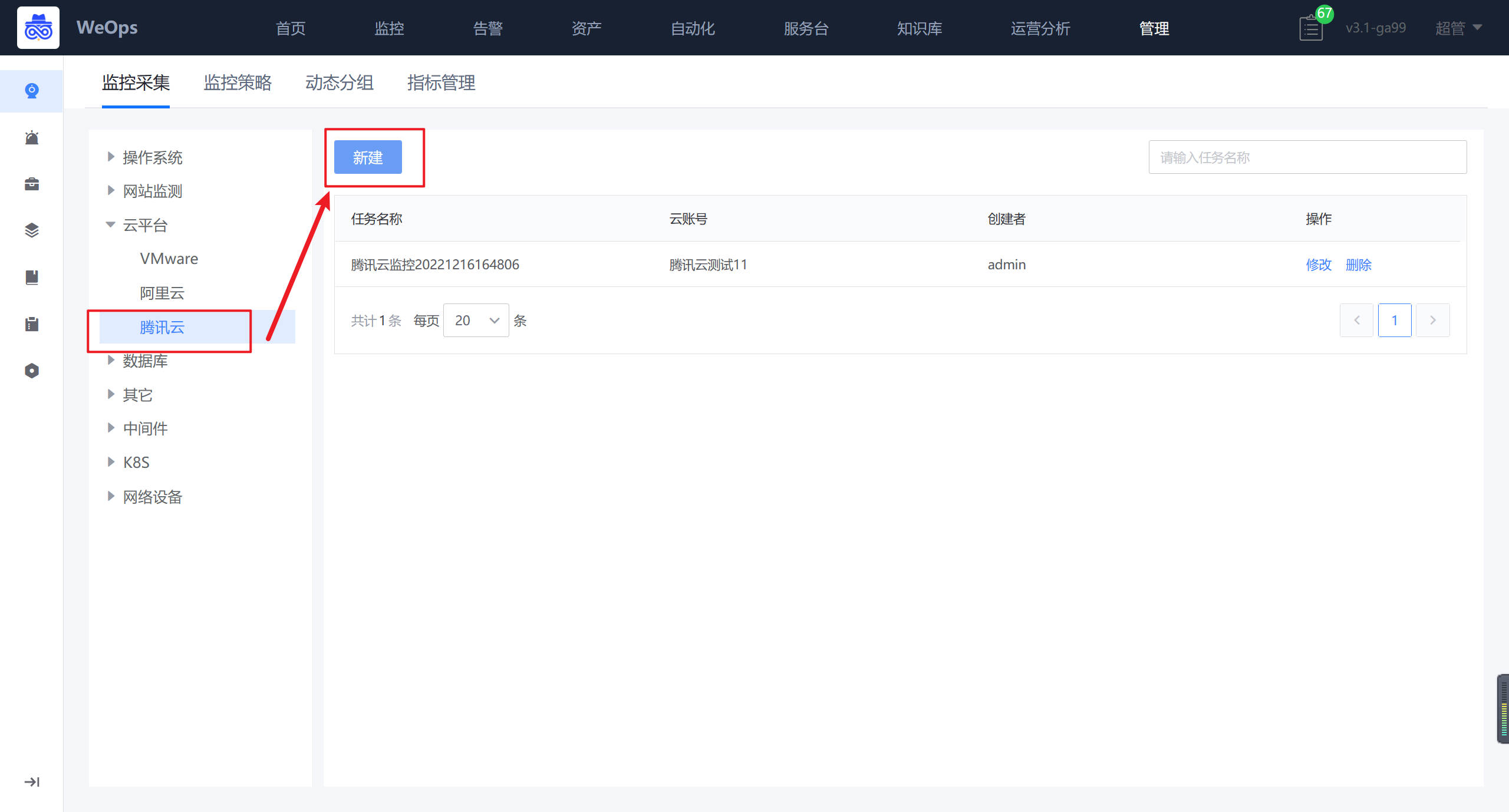
- 如下图所示,依次填写任务名称、腾讯云账号、对应凭据、采集频率等

- 新建完成后,,可对该腾讯云账号下所有的CVM进行监控数据的采集,并可以在WeOps-监控视图-云平台监控-腾讯云(CVM)中查看已经采集监控数据和监控视图
Step2:监控策略配置
路径:管理-监控管理-监控策略(虚拟化监控)
- 如下图所示,进入到监控管理的监控策略页面,点击新增云平台-腾讯云监控策略。

- 如下图所示,默认填写策略名称、监控对象,只需要选择监控项和监控目标即可(与主机监控策略配置操作一致)

- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。

- 下一步“告警配置”可查看“2.2告警配置”
2.1.5 网站监控配置
背景介绍:需要将新的网站纳入拨测监控中,并配置相应的监控策略。
Step1:监控采集
路径:管理-监控管理-网站监测
- 如下图所示,进入网站监测的纳管界面,进行新增拨测任务。
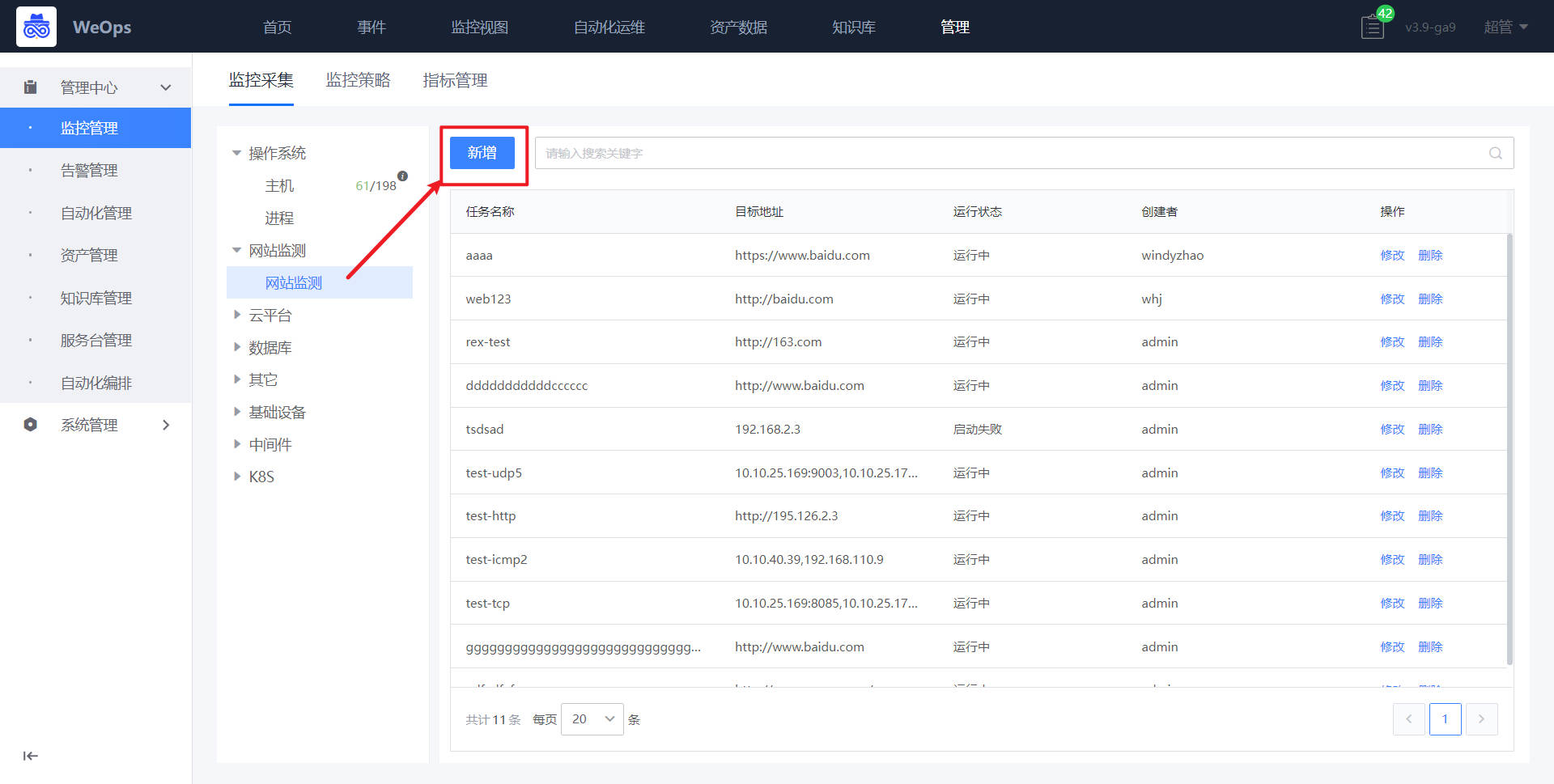
- 如下图所示,对任务进行配置后点击提交。提交之际系统会进行一次拨测,拨测成功后该任务才算创建成功,否则无法创建。若是创建失败请检查相关配置。

- 新建完成后,可以在监控视图-网站监测中查看已经采集监控数据和监控视图
Step2:监控策略配置
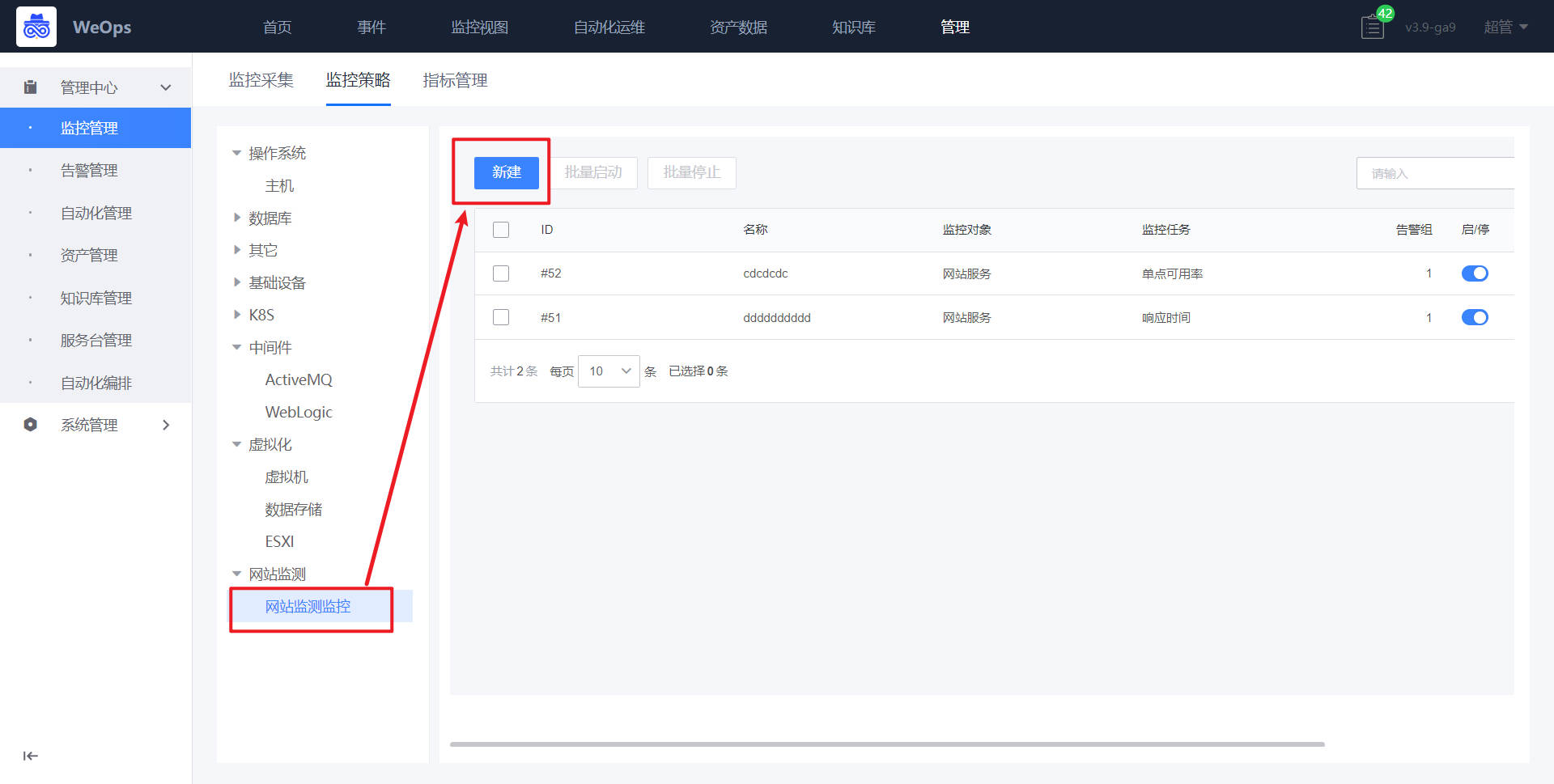
路径:管理-监控管理-监控策略(网站监测)
- 如下图所示,进入网站监测的配置界面,进行新增拨测监控。
- 如下图所示,进行监控项的相关配置,并配置触发和恢复规则,以及选择监控对象,点击确定,即完成对应服务拨测的监控配置
- 网站监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
2.1.6 K8S监控配置
背景介绍:需要将K8S集群中的pod/node纳入监控中,并配置相应的监控策略。
Step1:监控采集
路径:管理-监控管理-监控采集
- 如下图,进入监控采集页面,选择K8S,K8S采集任务的新建。

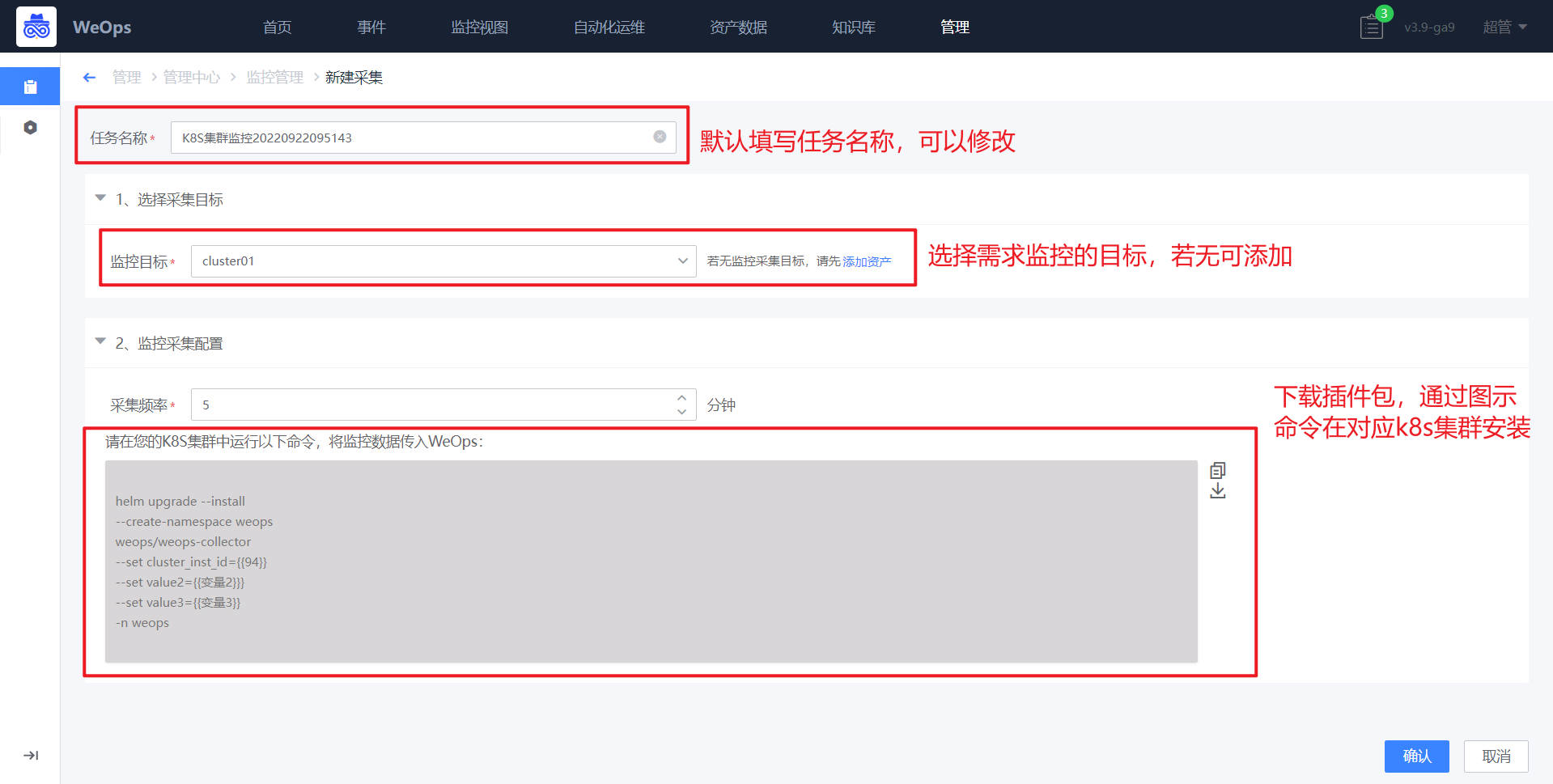
如下图,在采集新建界面,选择需要采集的K8S集群名称(若无可以在该页面进行添加)、配置采集频率,进行K8S监控需要将对应的安装包安装到对应的k8s集群里面,可以从该界面下载安装包,并运行一下命令进行部署
【注】 监控的采集安装包和自动发现的一样的,如果该K8S已经在自动发现时进行了的部署,配置监控采集时可以省去“部署安装包”这一步操作
注:有以下两种情况
(1)若集群可以使用公网镜像源时,解压安装包,进行安装即可
tar -zxvf weops-kubernetes.tgz
helm install weops-collecter weops-kubenetes-discovery-3.11.0.tgz -n weops --create-namespace --set remoteWrtieUrl=http://$(接收数据的Prometheus IP,一版为weops的appt ip):$(接收数据的Prometheus端口,一般为9093)/api/v1/write
(2)若不能使用公网镜像源时,需要先手动导入镜像并推送到私有仓库中,当集群不能使用公网镜像源时,需要手动导入镜像并推送到私有仓库中,压缩包里附带了需要用到的镜像文件,kube-state-metrics.tgz,node_exporter.tgz,cadvisor.tgz,prometheus.tgz
需要在helm install时指定本地仓库镜像helm install weops-collecter weops-kubenetes-discovery-3.11.0.tgz -n weops --create-namespace \
--set remoteWrtieUrl=http://$(接收数据的Prometheus IP,一般为weops的appt ip):$(接收数据的Prometheus端口,一般为9093)/api/v1/write \
--set image.repository=$(prometheus的私有仓库,如10.10.10.10:5000\prometheus) \
--set kube-state-metrics.image.repository=$(kube-state-metrics的私有仓库,如10.10.10.10:5000\kube-state-metrics) \
--set cadvisor-exporter.image=$(cadvisor的私有仓库,如10.10.10.10:5000\cadvisor):latest \
--set node-exporter.image=$(node-exporter的私有仓库,如.10.10.10:5000\cadvisor):latest
Step2:监控策略配置(以node为例)
路径:管理-监控管理-监控策略(K8S)
K8S集群监控采集新建完成以后,可以对pod和node进行监控策略的配置。
如下图,进入到监控策略页面,选择K8S-node,点击“新建”按钮
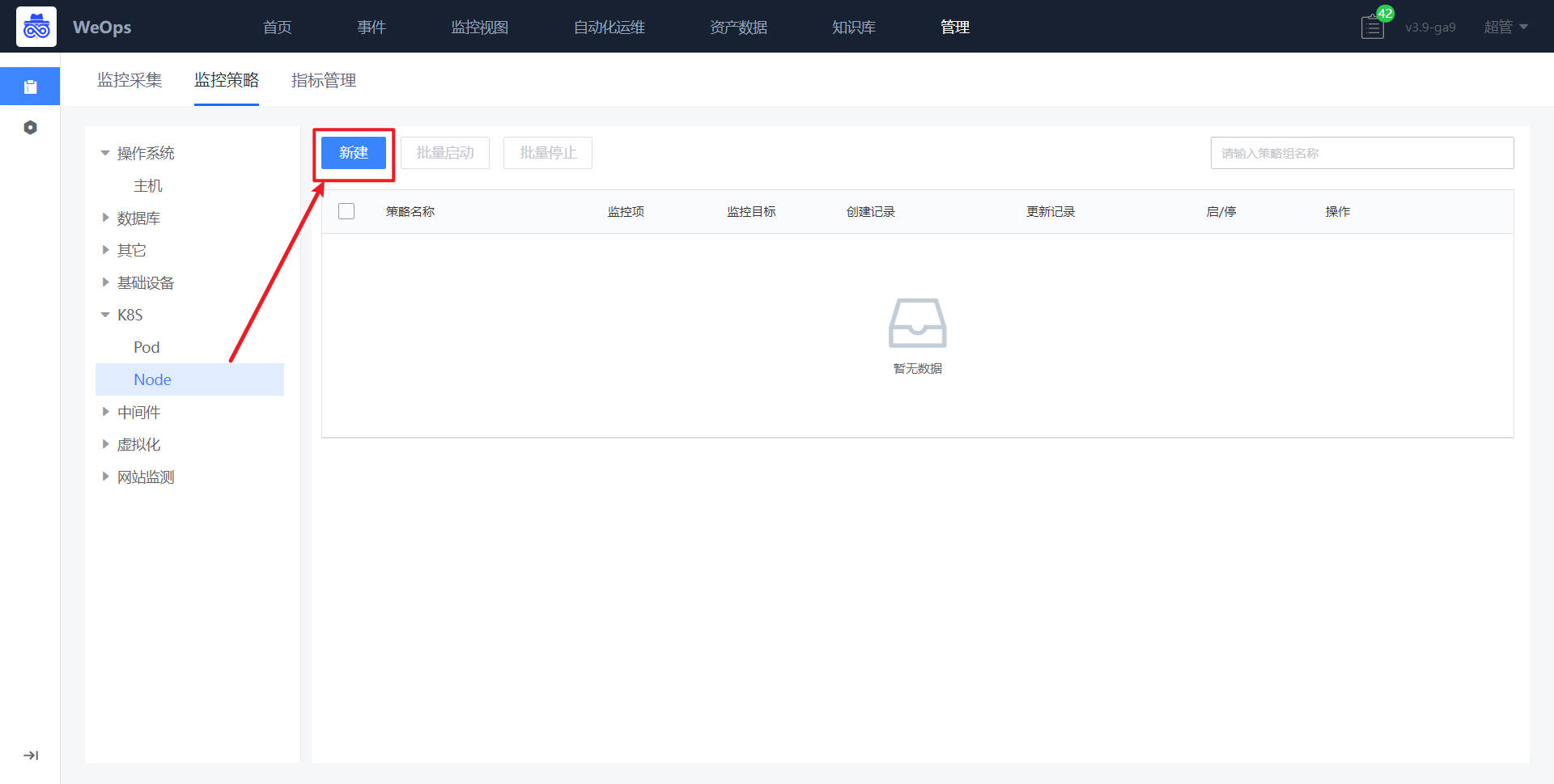
- 在新建界面,策略名称、和监控对象已经默认填写。
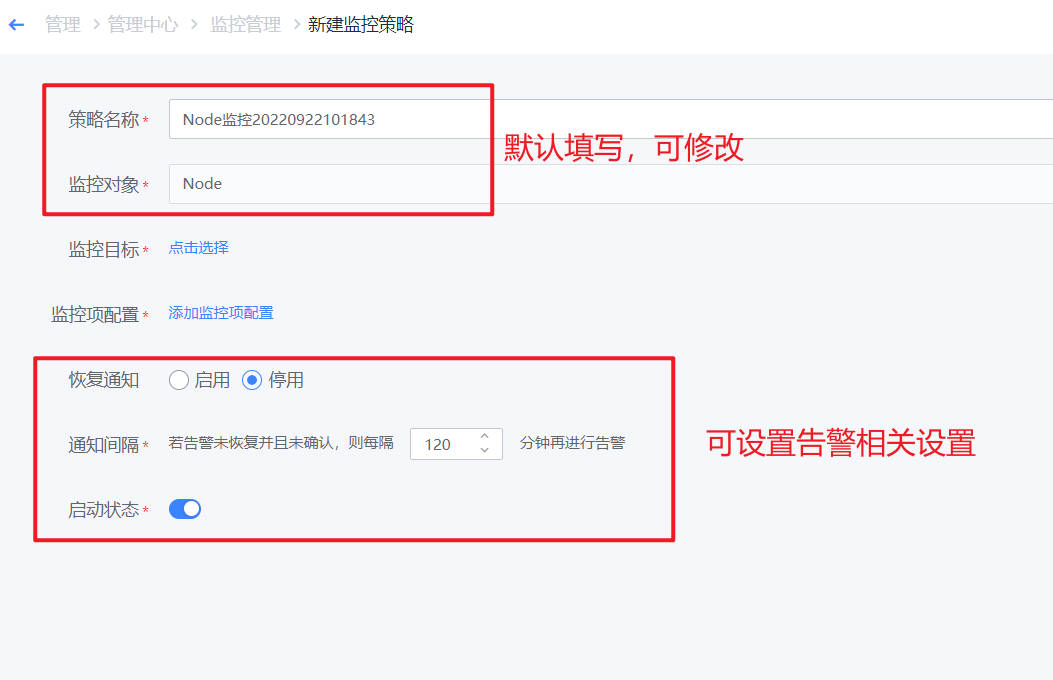
- 如下图,点击“选择监控目标”,进行监控对象的选择
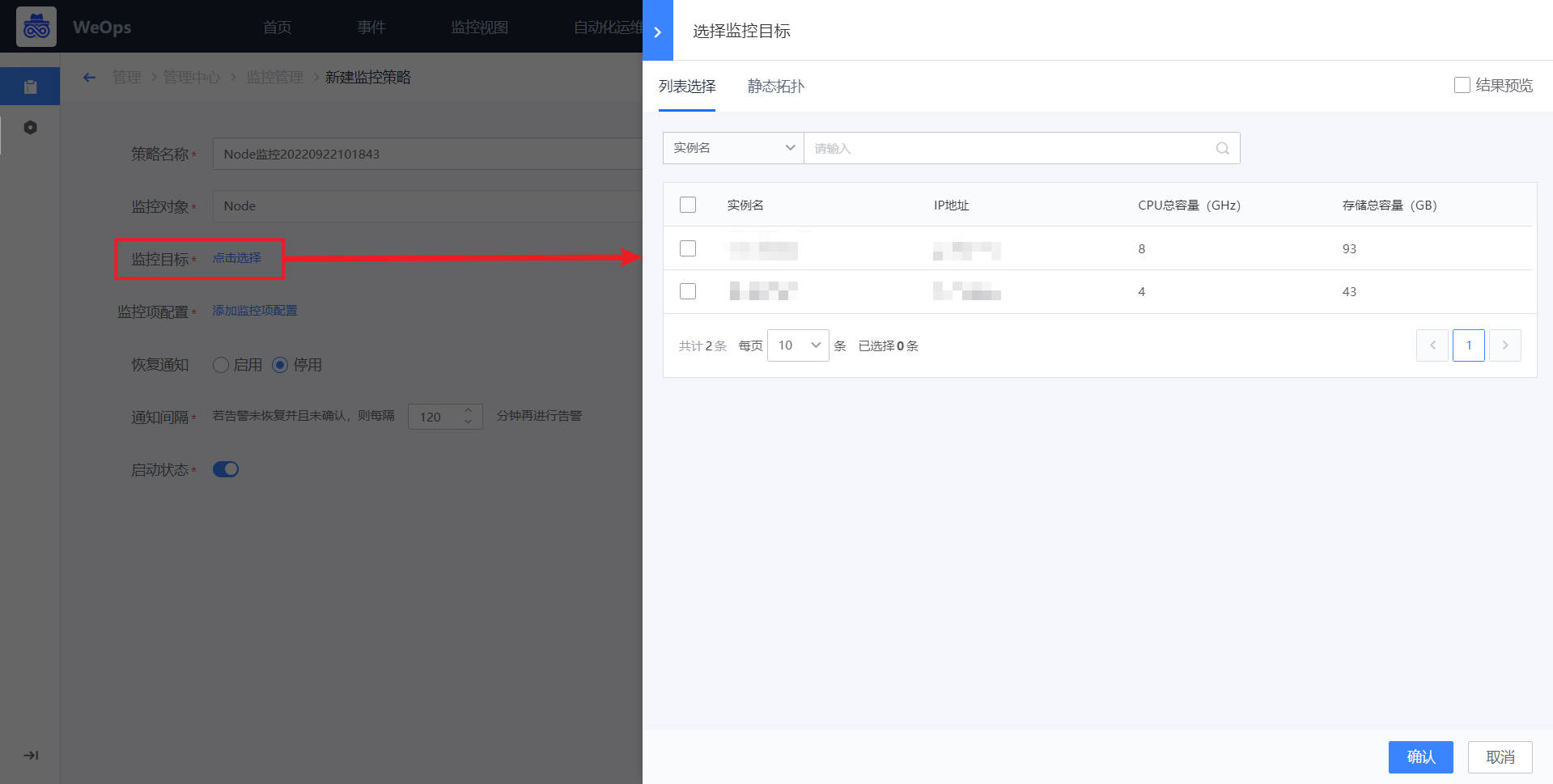
*如下图,点击“添加监控项配置”,可进行监控项的选择和配置,这里需要说明的是,由于K8S的特性,监控目标(pod和node)常常处于变化中,可以采取设置监控维度的方式,对某个集群/某个命名空间/某个工作负载下的pod/node进行监控策略的配置,配置成功后,无需选择具体的监控目标,该策略即可生效。
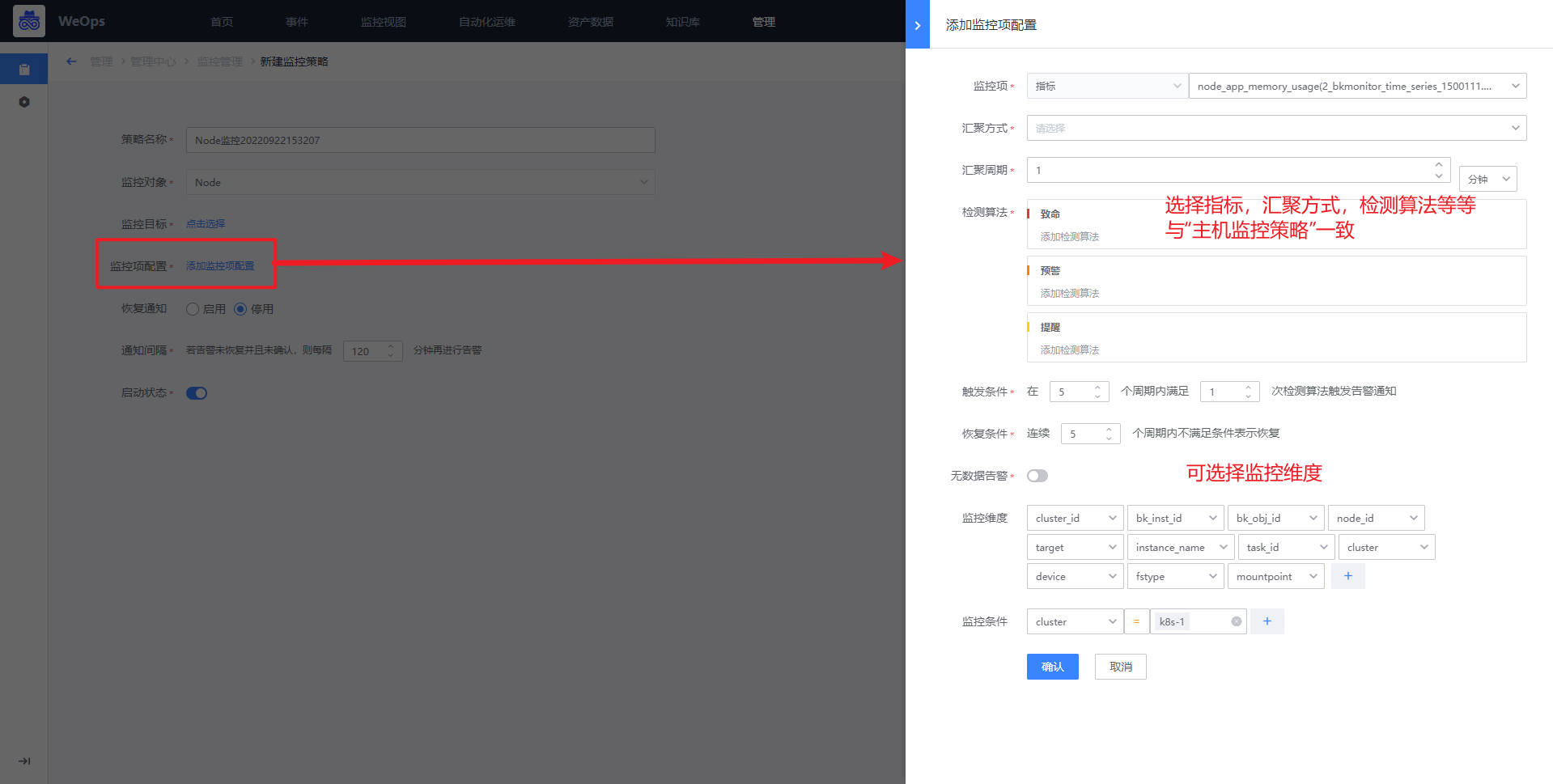
- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
2.1.7 网络设备监控配置(以交换机为例)
背景介绍:需要将网络设备纳入监控中,并配置相应的监控策略,前提是已经将网络设备手动/自动发现纳入到资产中了
Step1:导入/新建网络设备指标模板
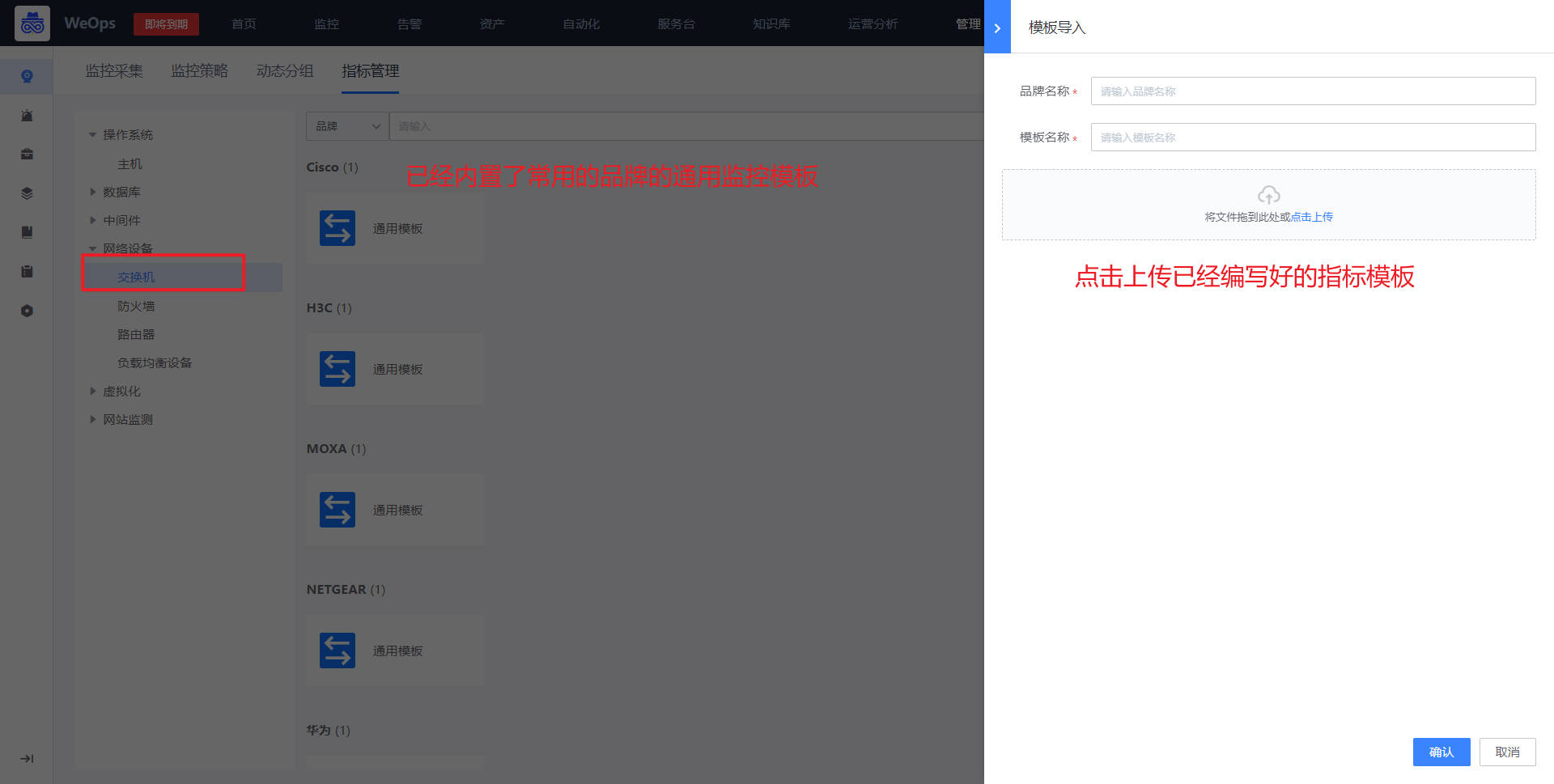
路径:管理-监控管理-指标管理
如下图,在指标管理中,选择网络设备-交换机,点击导入模板,可以进行不同品牌和型号的指标模板导入(WeOps提供了网络设备指标模板导入的入口,可监控的设备品牌、型号等支持拓展。)
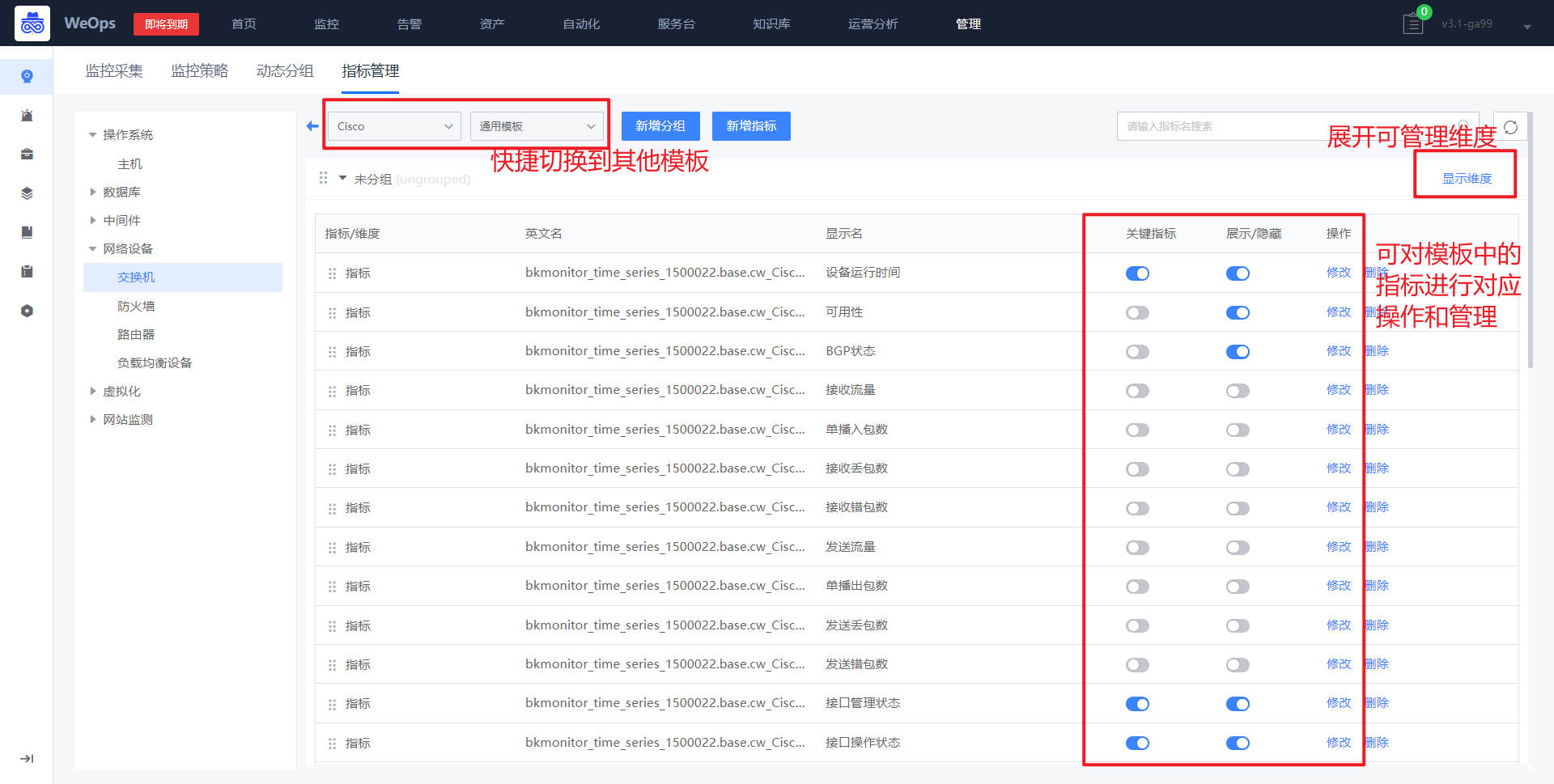
如下图,对于导入好的指标模板可以进行对应维度/指标的编辑,便于后续使用。
也可以进行指标的新建,具体说明如下
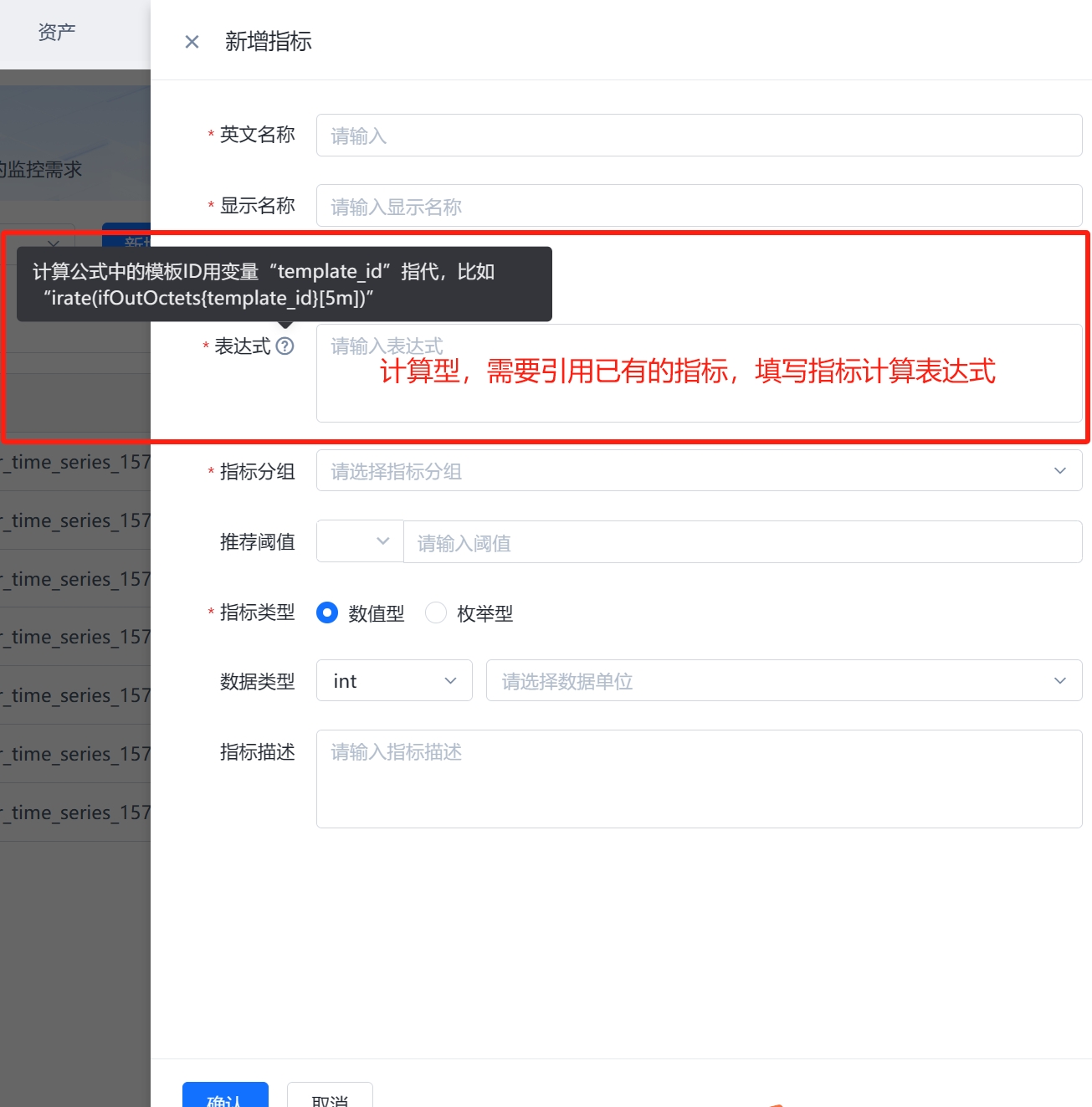
(1)指标型:指标型指标是通过设备的OID(对象标识符)来采集设备的实际数值。所以当某个指标可以找到对应oid进行数据采集时,可以创建指标型指标进行采集。
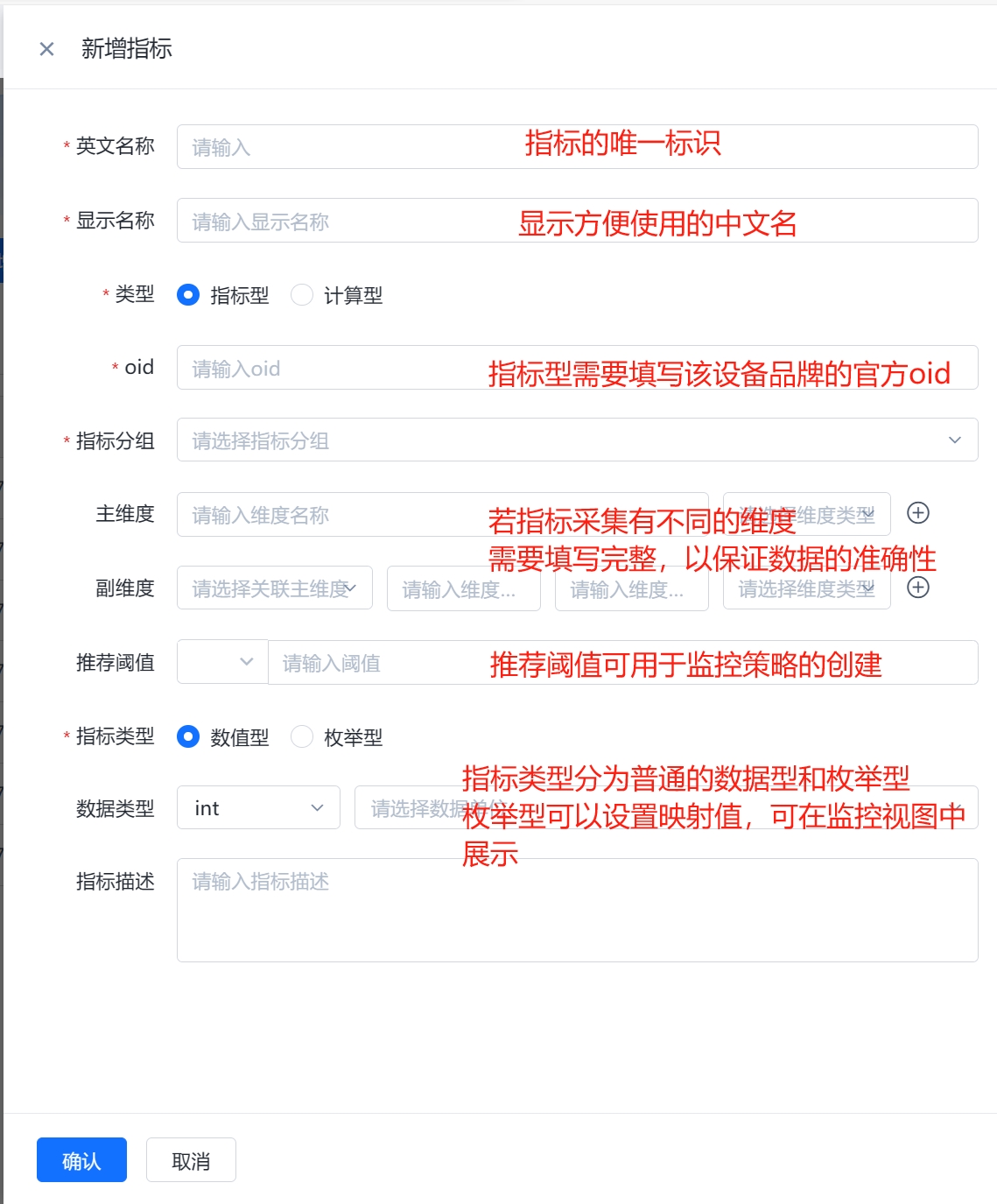
(2)计算型:对指标型指标的数值进行计算得到的指标。计算型指标可以用于更细粒度地监控设备性能,在计算型指标的公式中,需要引用现有指标,可以采用(指标英文名{template_id})的格式进行引用,公式中固定变量“template_id”为指标所在的模板ID,固定不变。比如“irate(ifOutOctets{template_id}[5m])”。
Step2:监控采集
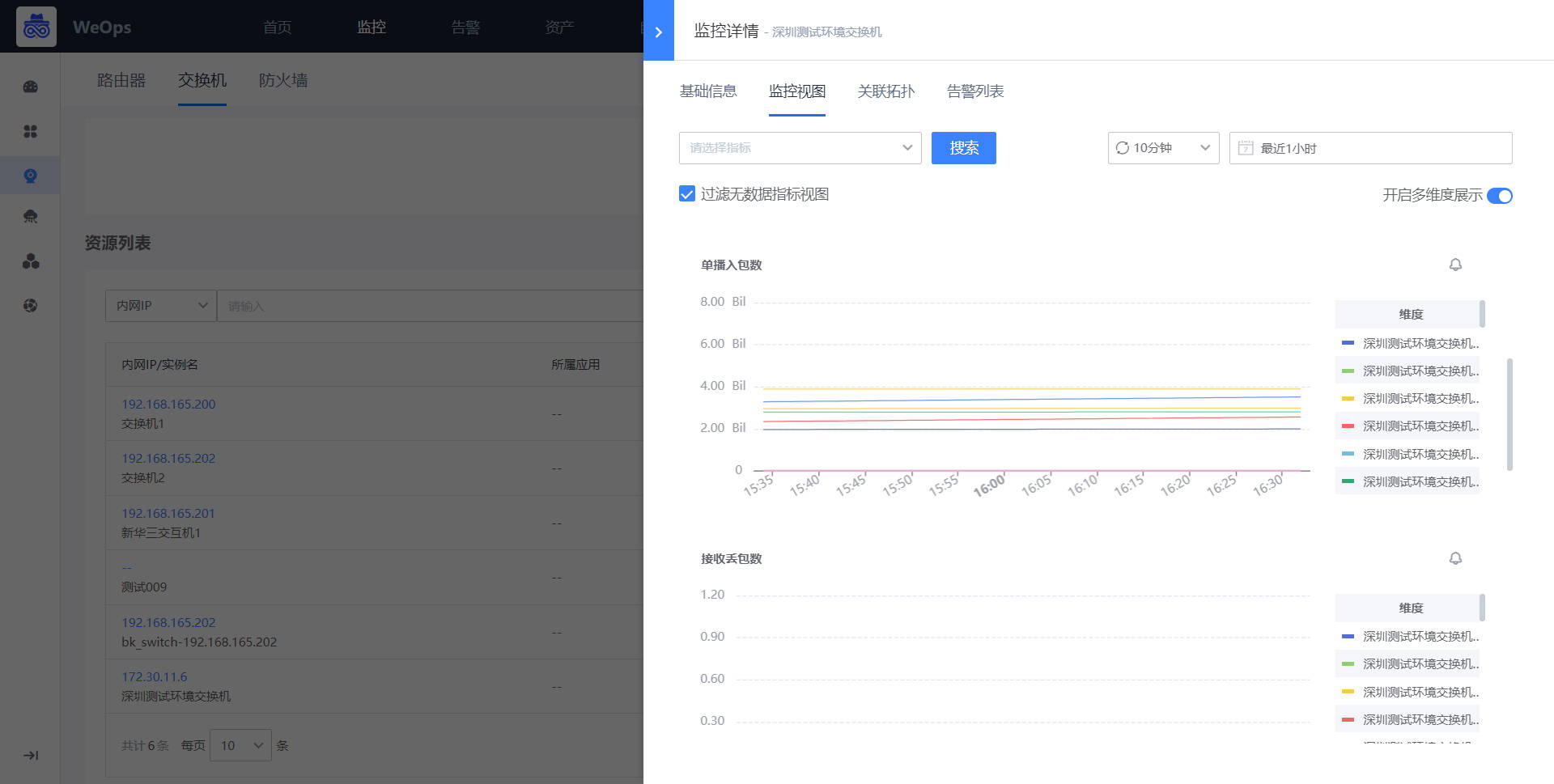
当需要监控的网络设备已经纳管,并且有适用的监控指标模板(可以是内置的,也可以是导入创建的),可以对网络设备进行监控采集的创建,选择对应的目标,适用的指标模板,并填写凭据信息。


如下图,监控采集创建完成以后,可以在监控视图中,查看对应监控对象的监控信息
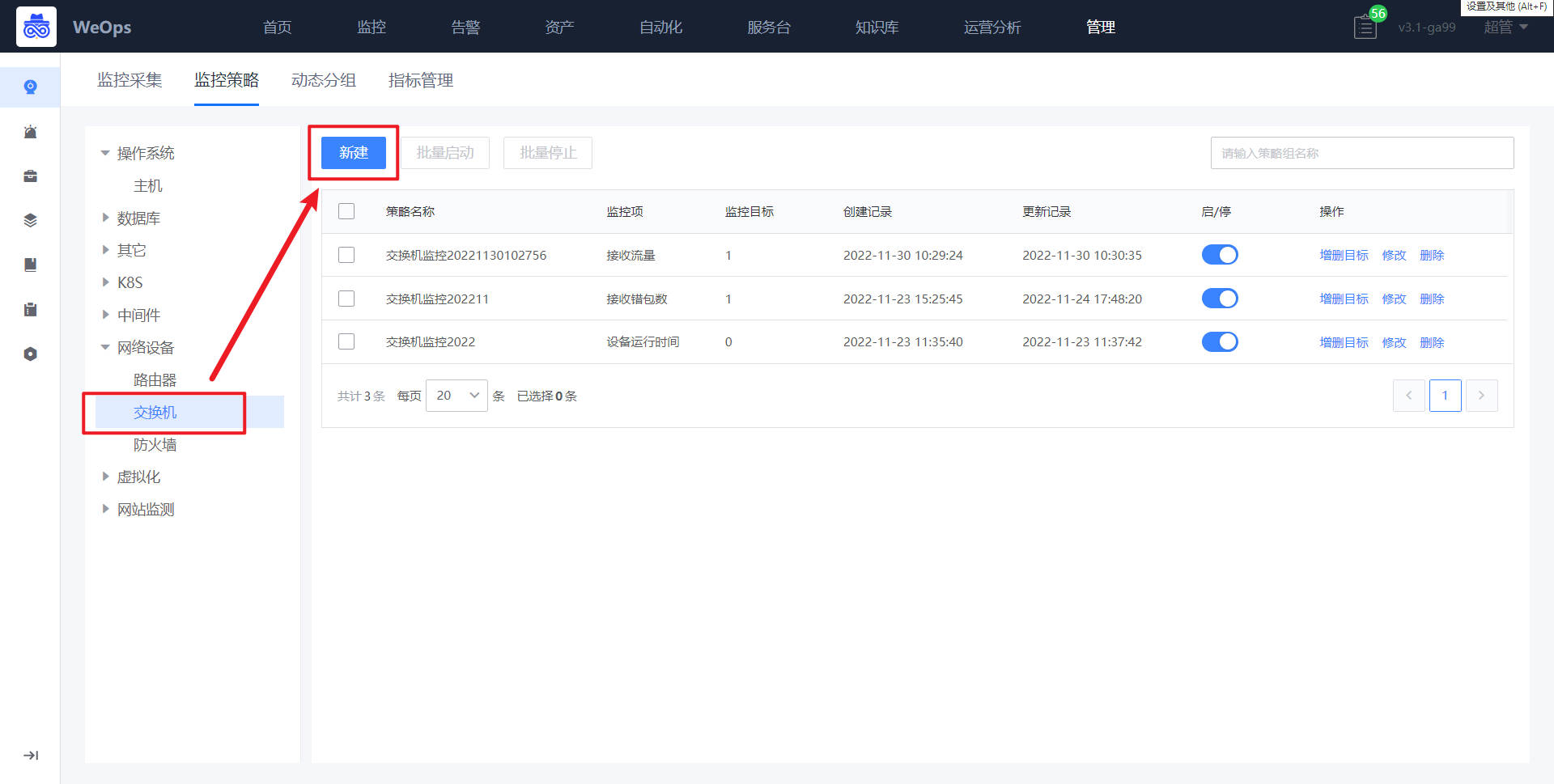
Step3:监控策略配置(以交换机为例)
网络设备监控采集新建完成以后,可以网络设备进行监控策略的配置。
如下图,进入到监控策略页面,选择网络设备-交换机,点击“新建”按钮
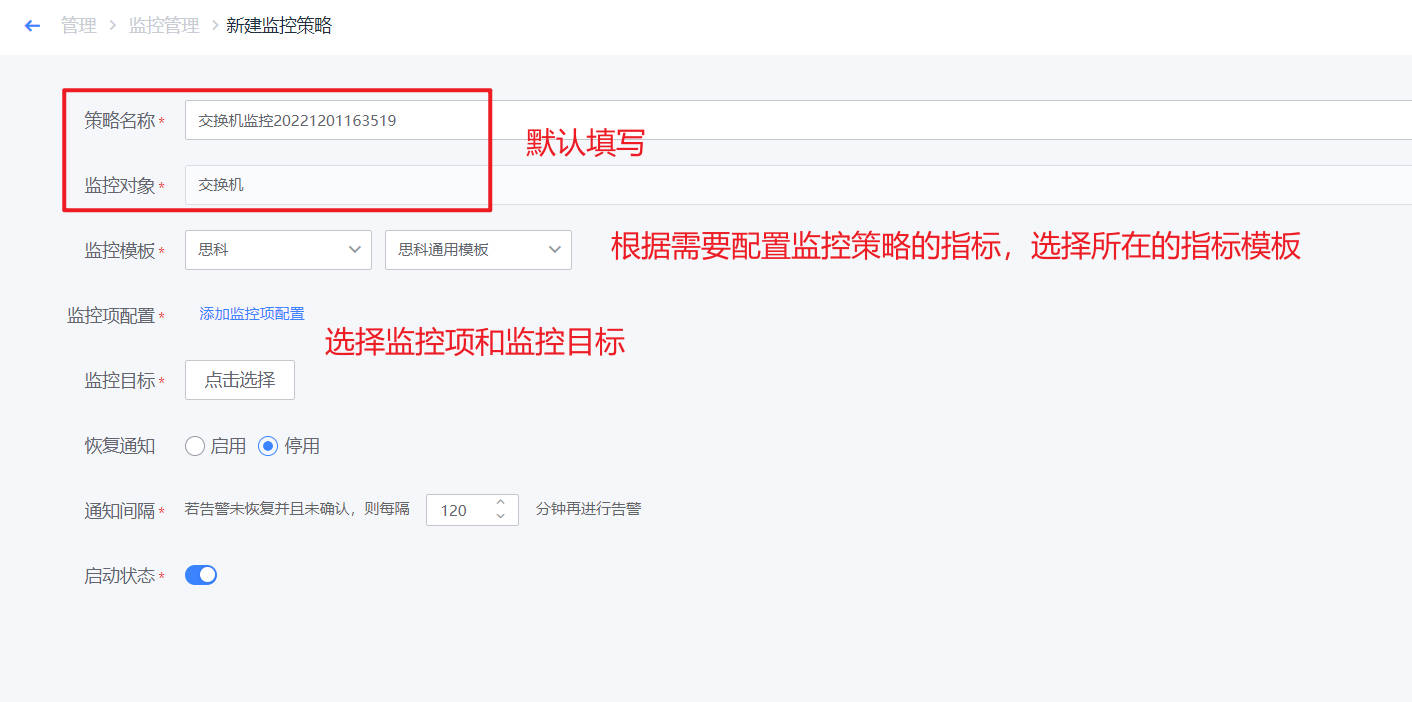
- 在新建界面,策略名称、和监控对象已经默认填写。点击“选择监控目标”,进行监控对象的选择点击“添加监控项配置”,可进行监控项的选择和配置
- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
- 下一步“告警配置”可查看“2.2告警配置”
2.1.8 硬件设备监控配置
背景介绍:需要将硬件设备纳入监控数据采集中,并设置对应监控策略。
注意:ipmi采集暂时不支持自定义端口
Step1:监控采集
路径:管理-监控管理-监控采集
- 如下图所示,进入硬件服务器的监控采集界面,进行新增。
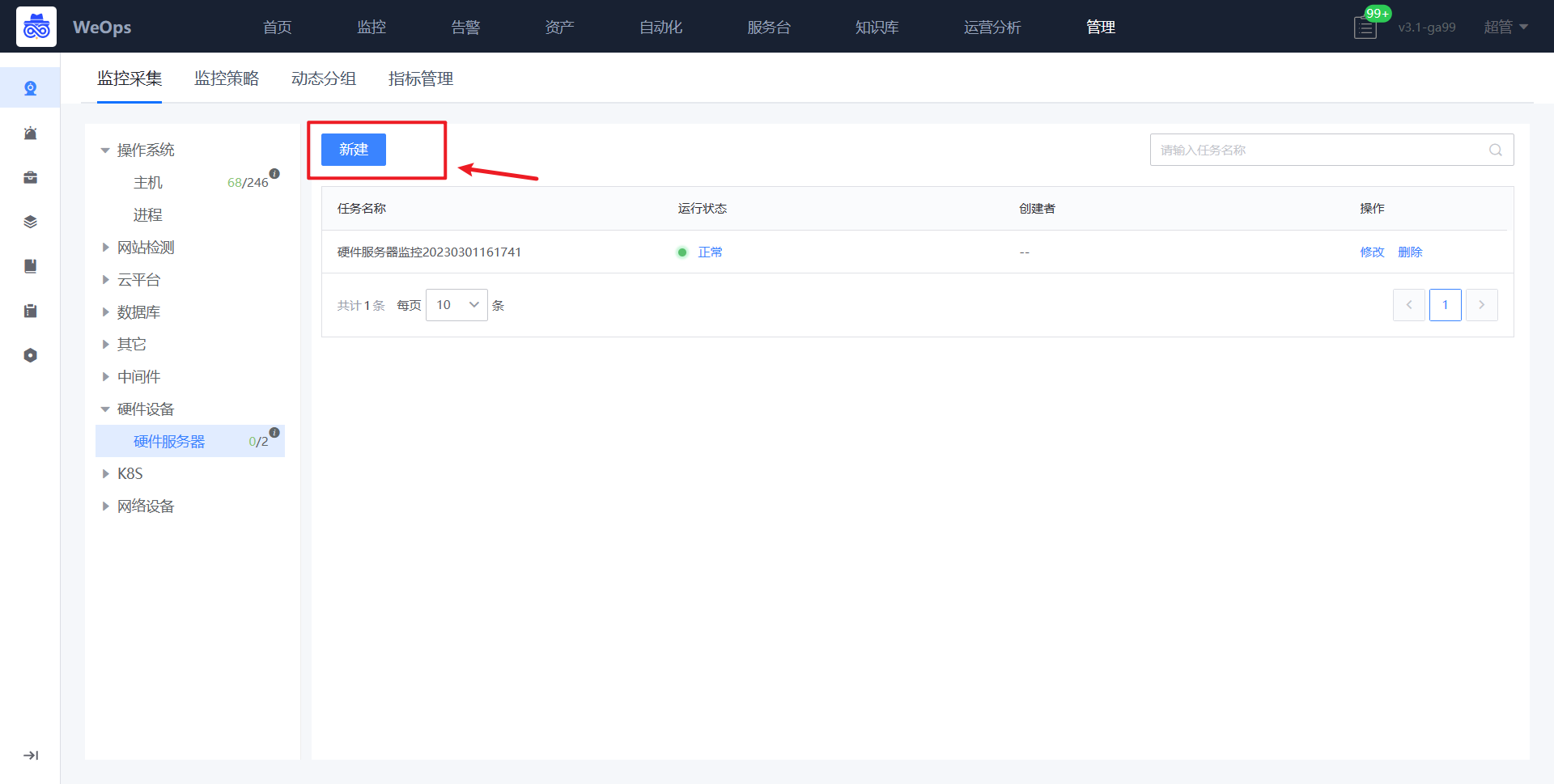
- 如下图所示,依次填写任务名称、腾讯云账号、对应凭据、采集频率等
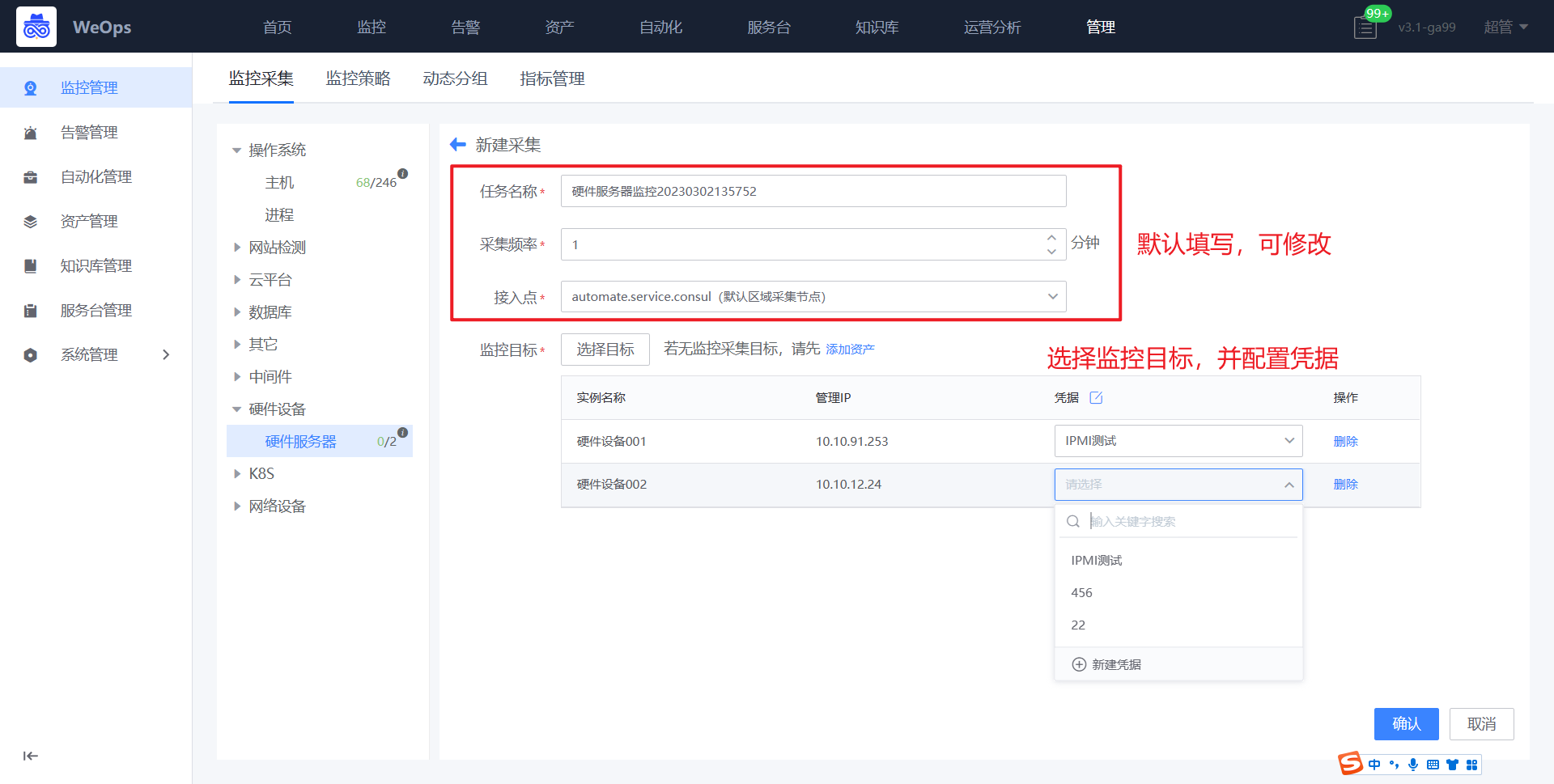
- 新建完成后,可对该设置的硬件设备进行监控数据的采集,并可以在WeOps-监控视图-基础监控-硬件设备中查看已经采集监控数据和监控视图
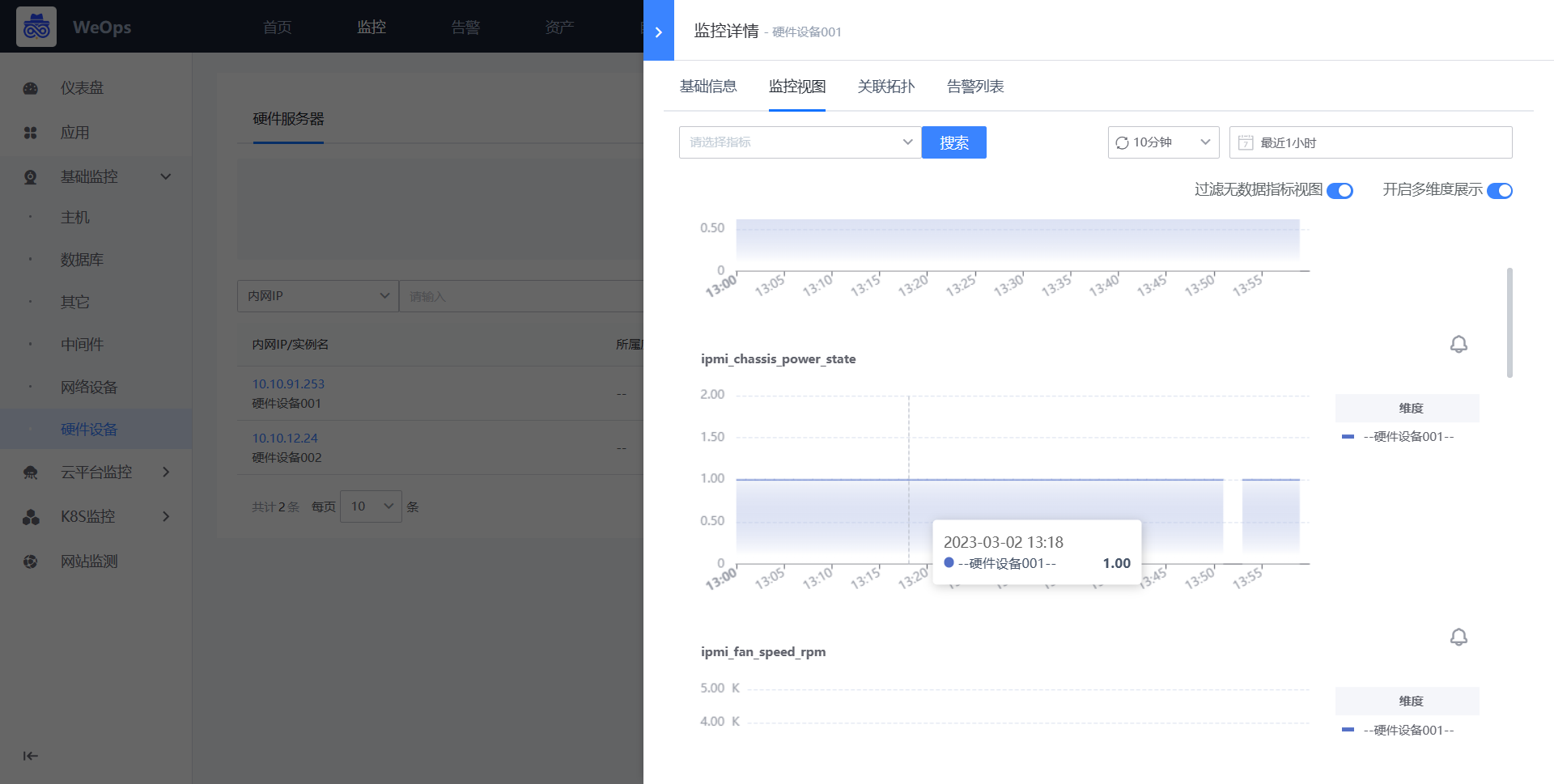
Step2:监控策略配置
路径:管理-监控管理-监控策略(硬件监控)
- 如下图所示,进入到监控管理的监控策略页面,点击新增硬件设备-硬件服务器监控策略。
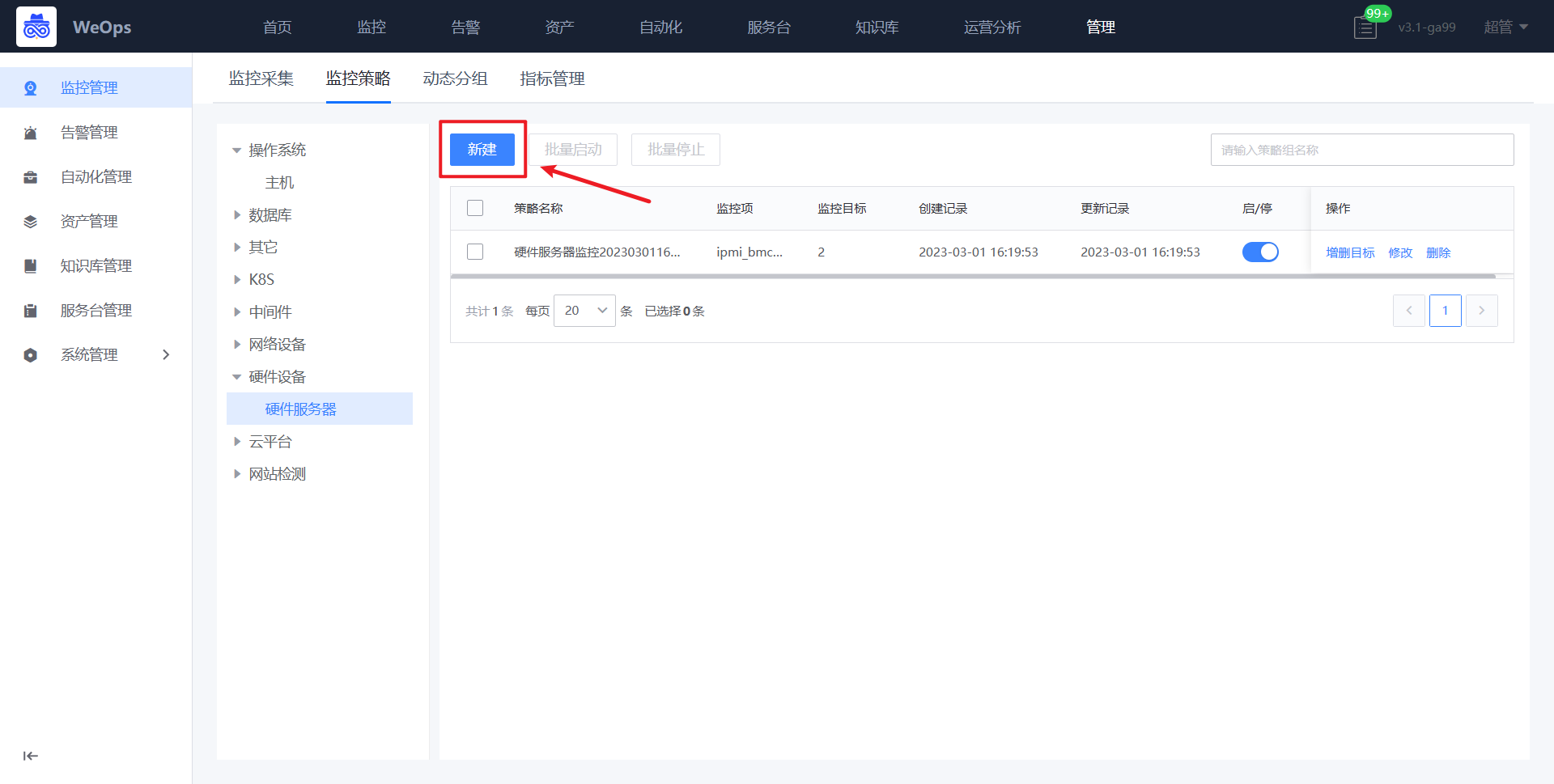
- 如下图所示,默认填写策略名称、监控对象,只需要选择监控项和监控目标即可(与主机监控策略配置操作一致)
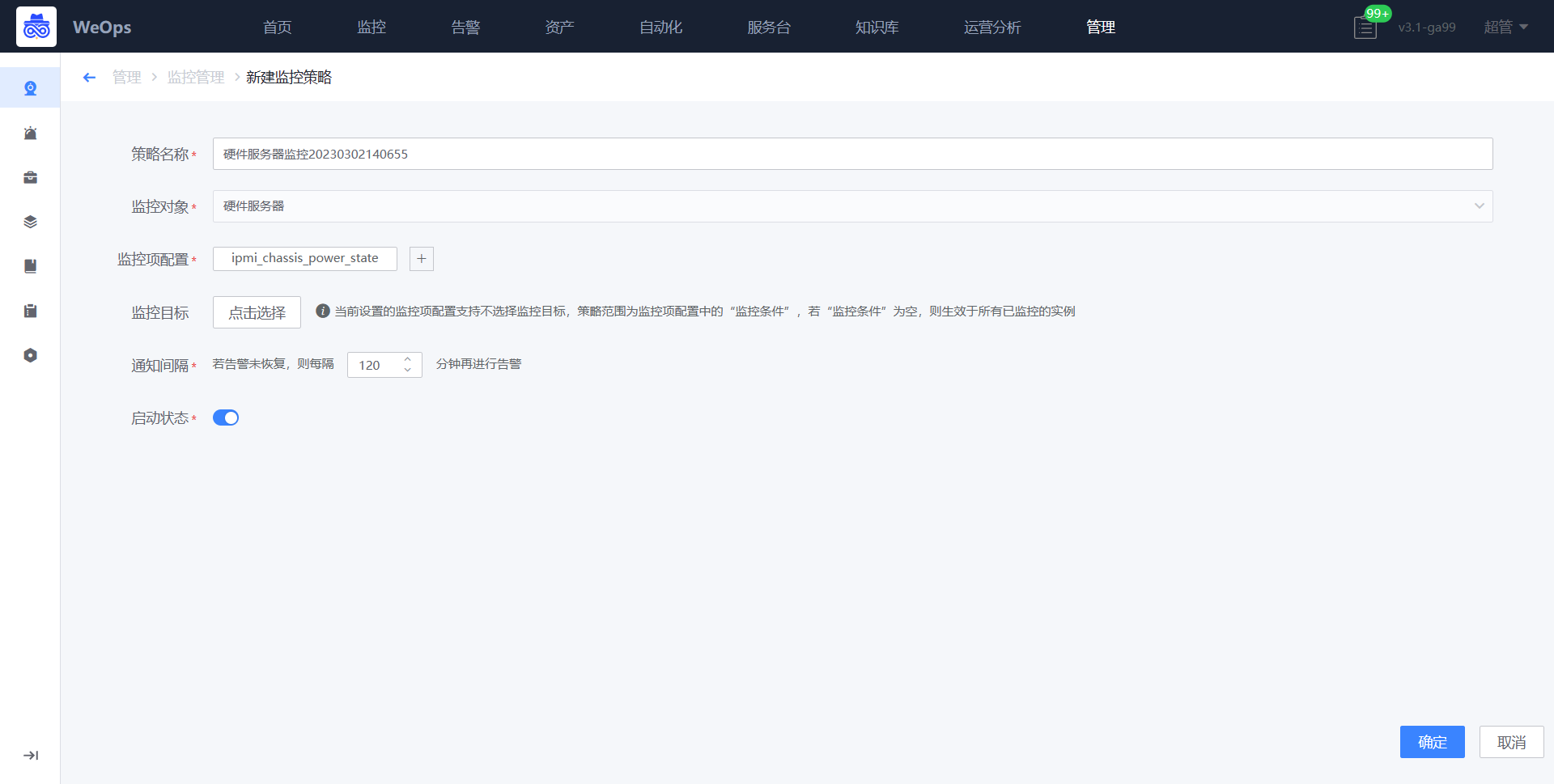
- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
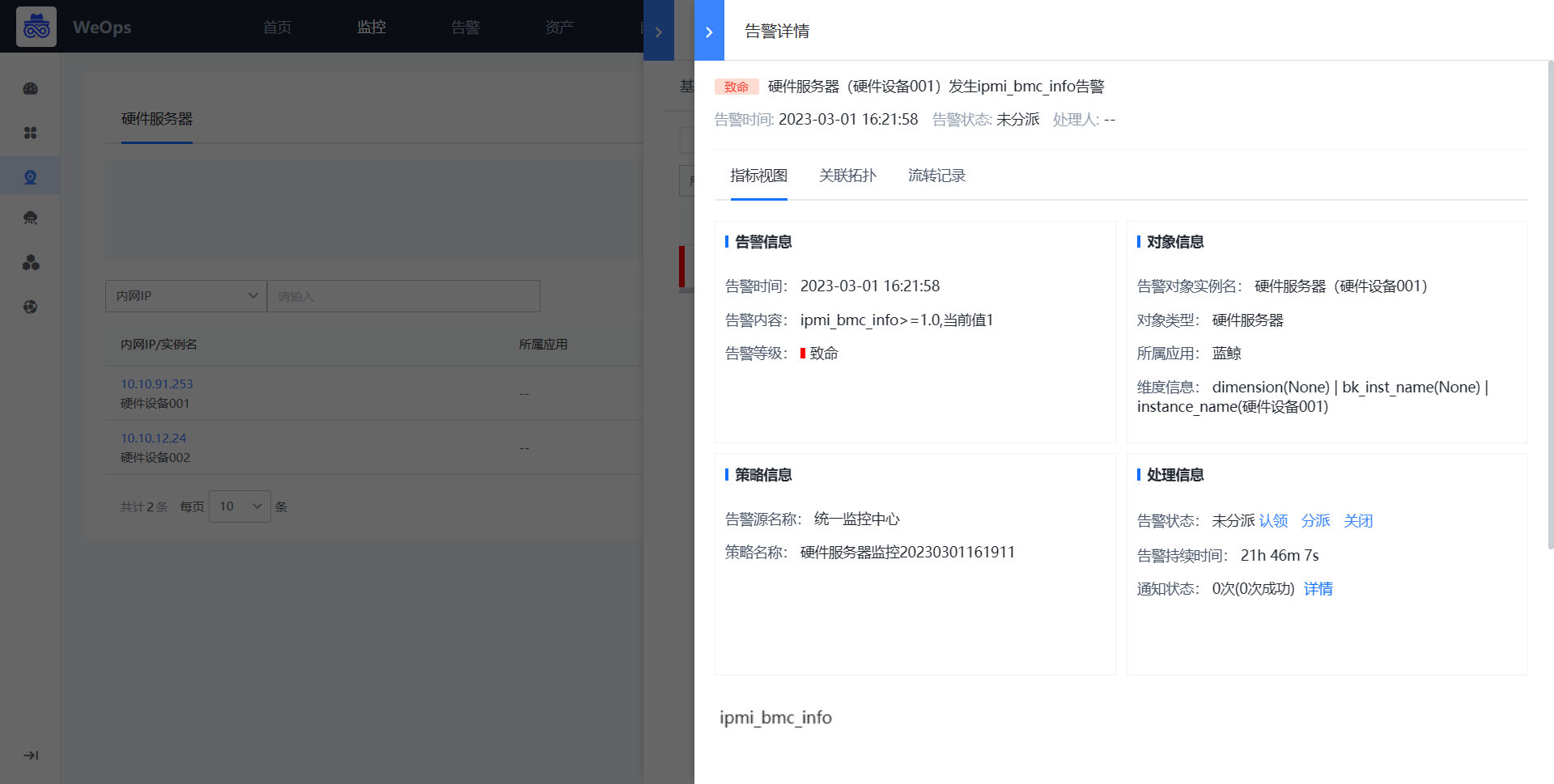
- 下一步“告警配置”可查看“2.2告警配置”
2.2 告警配置
背景介绍:监控对象已经进行监控数据采集,并配置好相关的监控策略,需要对产生的告警配置抑制、屏蔽、自动分派、自动处理等策略,或设置人员通知。各个对象的告警配置一致,此处介绍通用方法。
告警抑制
通过用户自定义配置告警抑制策略,让符合筛选条件的告警被抑制(即不会成为有效告警)。
路径:管理-告警管理-告警处理-抑制策略
- 如下图所示,点击新增告警抑制策略规则。
- 如下图所示,按照如下指示输入匹配规则相关信息,随后点击提交即可完成配置。

注:目前有三种抑制策略
【第一种,内置的自动去重策略】:统一告警中心的告警都有一个告警事件 ID 字段,由告警源插件来设定这个字段的清洗规则,当一条告警成为有效告警后,在此条告警未关闭也未恢复的情况下,相同告警事件 ID 的告警自动被收敛。
【第二种,防抖抑制】:抑制抖动类指标偶发性产生的告警事件,如: CPU 使用率、内存使用率、磁盘 IO、网卡流量等
抑制规则: n 时间内出现 x 次则产生一条有效告警, 且告警关闭前不再产生新的告警。假设用户设定, 5min 内出现 4 次则产生一条有效告警;那么当告警中心接收到 1 条告警后,没有被自动去重,它会等待 5min,如果这 5 分钟内再次产生了 3 条及以上告警(除告警时间外,其他字段都相同),才会产生有效告警,5min 内产生的告警数量不足以达到数量要求,那这些告警全部被收敛,不会产生有效告警。
【第三种,关联聚合】:将关联字段相同的告警聚合,如: 7 分钟内“ 告警源+告警指标+告警对象+CMDB 业务+告警等级” 告警相同的告警聚合为 1 条有效告警。
聚合:第一条有效告警产生后,如果设定的时间窗口内产生关联字段相同的告警,那么这些告警被收敛。
执行顺序:如果一条告警被接收到后,之前没有相同告警事件 ID 的有效告警,则自动去重无法生效,执行告警抑制策略匹配,待产生有效告警后,后续接收的,相同告警事件 ID 的告警,会被自动去重;如果一条告警被接收到后,之前已有相同告警事件 ID 的有效告警,则优先执行自动去重,不会也不必再去执行抑制策略。
告警屏蔽
某些主机在执行一些日常任务的时候,例如定时备份任务,会导致CPU或是磁盘IO超过监控阈值。生成了”无效”告警,故可以采取该功能进行将特定条件下生成的告警事件进行屏蔽。
路径:管理-告警管理-告警处理-屏蔽策略
- 如下图所示,点击新增告警屏蔽策略规则。

- 如下图所示,按照如下指示输入匹配规则相关信息,随后点击提交即可完成配置。
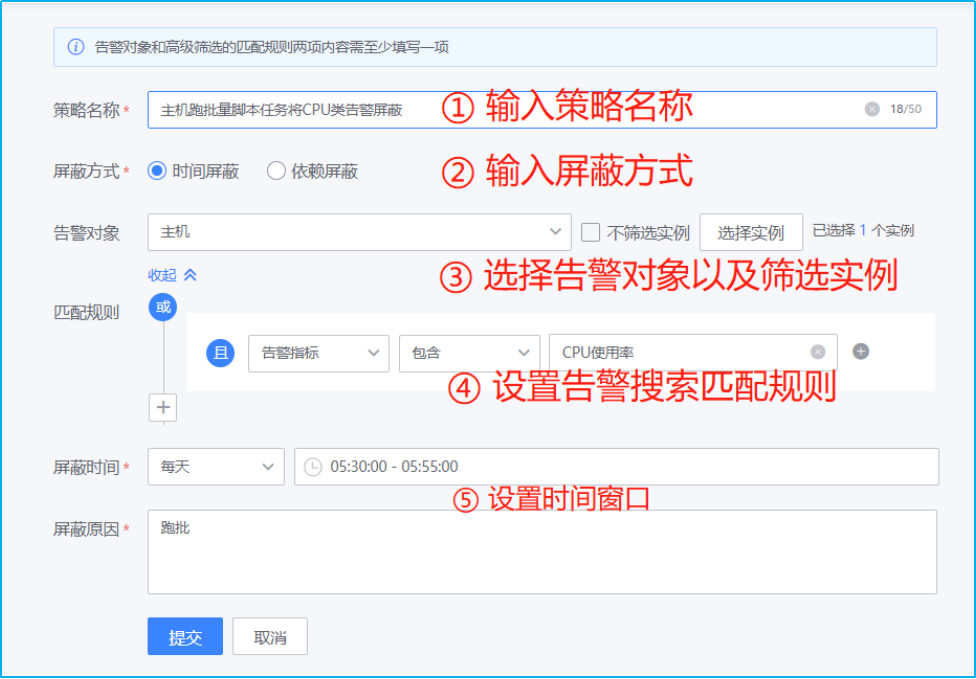
注:支持两种屏蔽方式:时间屏蔽(即维护期屏蔽,按时间段屏蔽符合筛选条件的告警)、依赖屏蔽(当符合 A 筛选条件的告警产生时,屏蔽之后 XX 时间段内的符合B 筛选条件的告警)。
告警自动处理
管理-告警管理-告警处理-自动处理
- 如下图所示,点击新增告警处理策略规则

- 如下图所示,新建页面,配置自动处理策略,让符合筛选条件的告警,根据策略优先级执行自动处理方案(包括自动转工单、自愈处理、自动关闭),可设置策略优先级、生效时间、分派人员、通知方式等
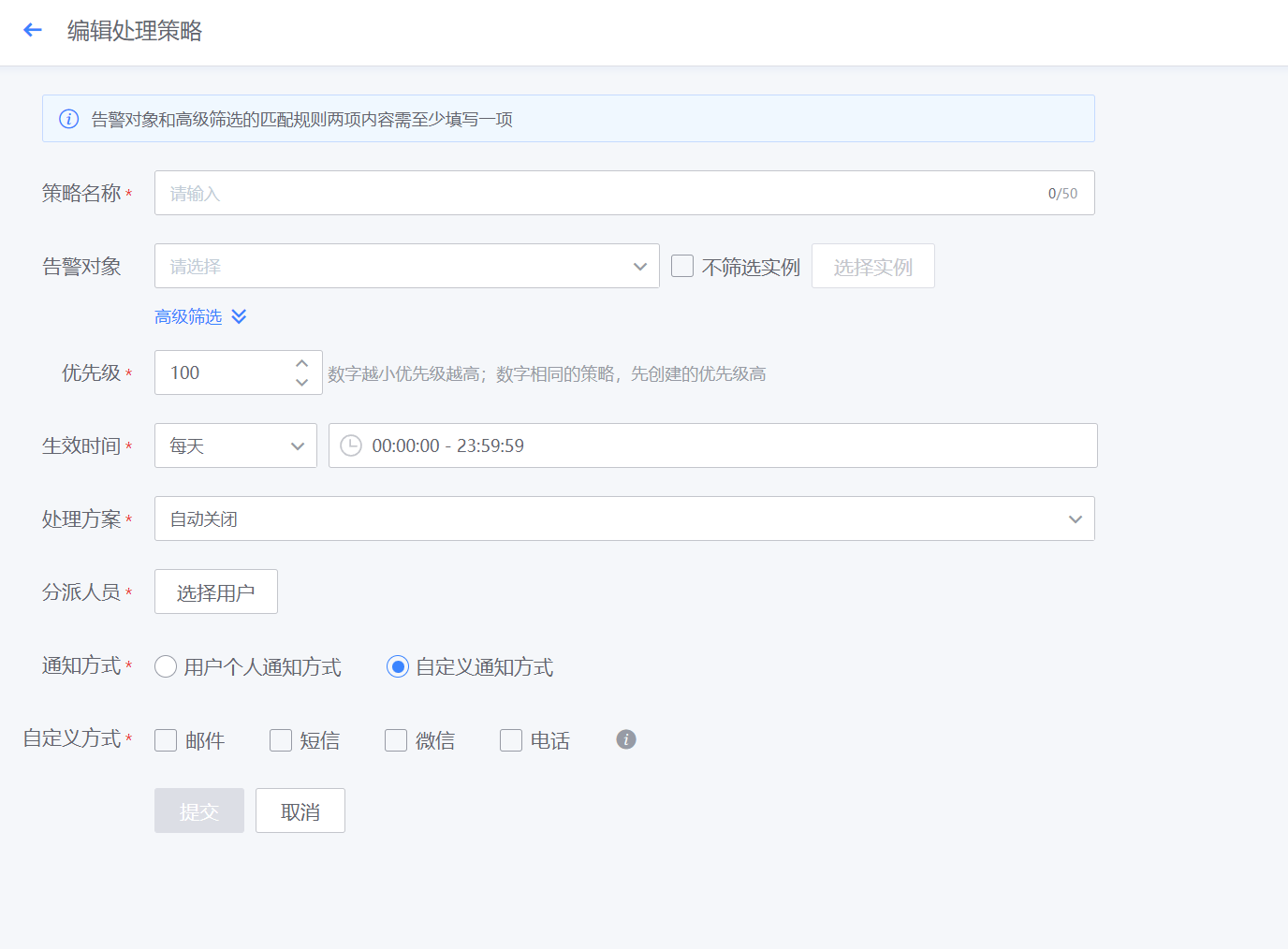
优先级: 1~100,数字越小执行该条策略的优先级越靠前,相同优先级数字的策略,创建时间早的的优先级更靠前。
分派人员:可根据组织目录的展开,选择用户;也可切换为全部用户,对用户名进行模糊搜索;还可以选择用户组(包括内置通知用户组和统一告警中心用户与组页面创建的用户组)。
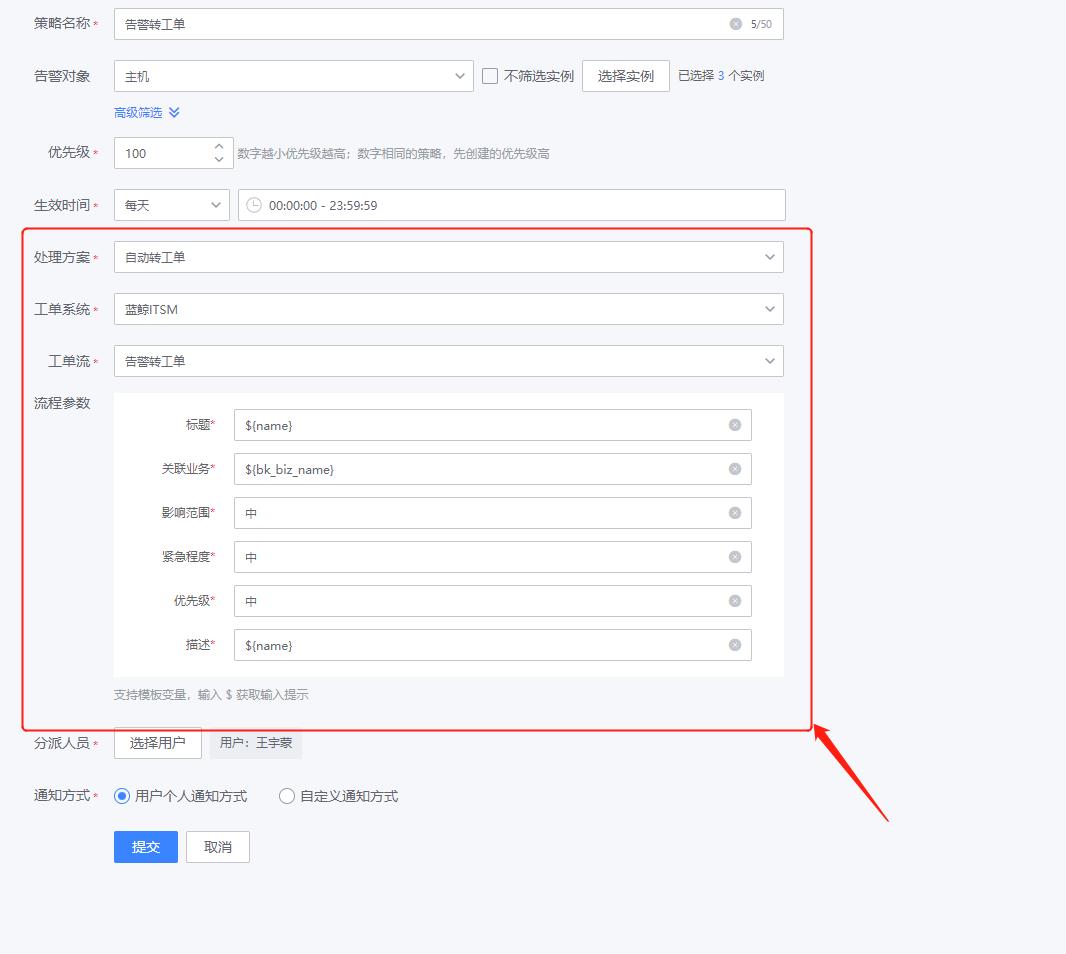
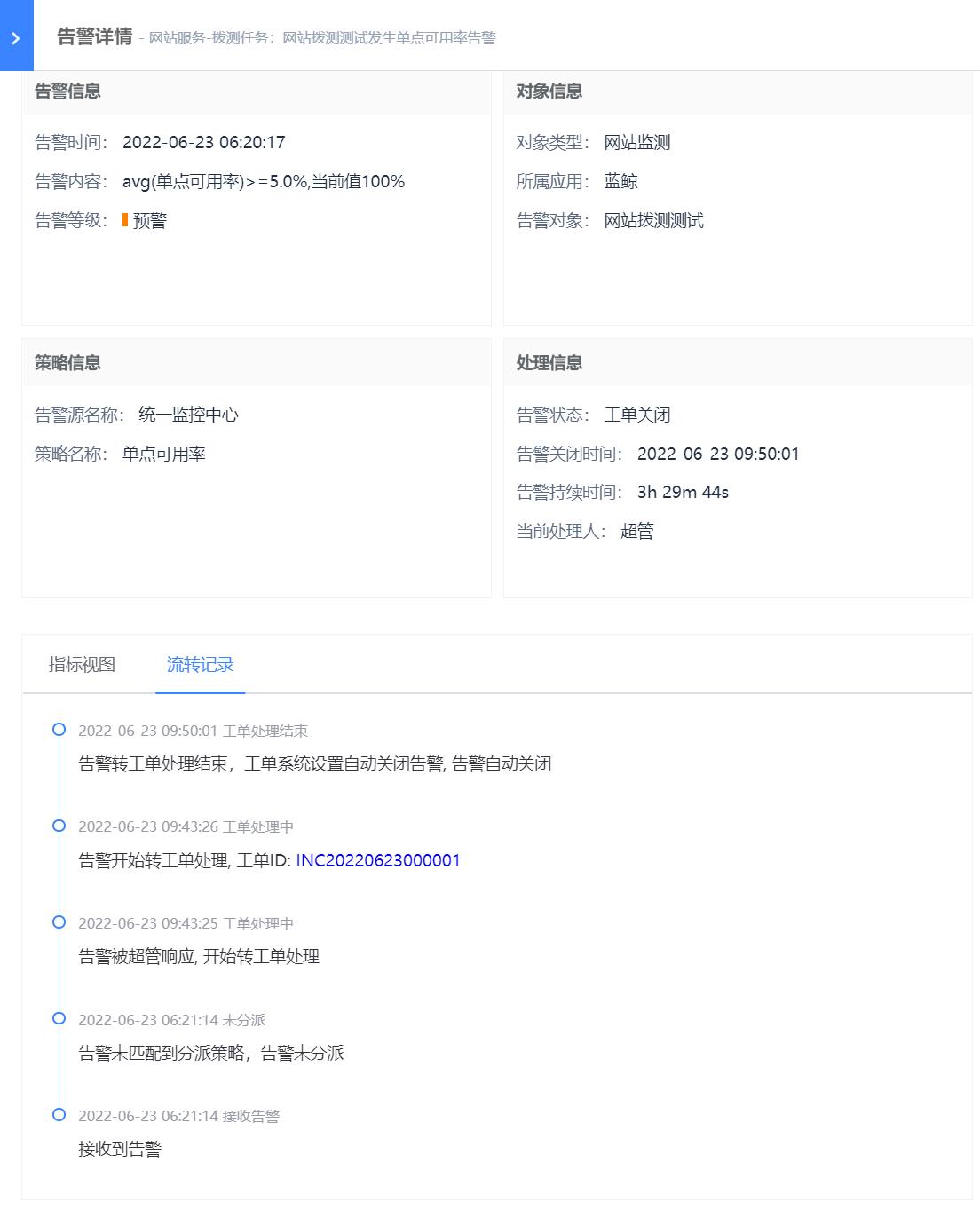
这里特殊说明下告警转工单,在“自动处理”中选择处理方案为“自动转工单”,按照工单模块内置的告警转工单流程进行相关字段的填写,设置完成后,符合该策略的告警将会转为工单处理,工单处理结束后,告警会自动关闭。
告警自动分派
配置告警自动分派策略,让符合筛选条件的告警,分派给指定人员或用户组,并可选添加附言、是否通知、通知方式等,这里以【短信】通知的形式来进行介绍
路径:管理-告警管理-告警处理-自动分派
- 如下图所示,进入到告警分派的界面,点击新增告警分派规则。
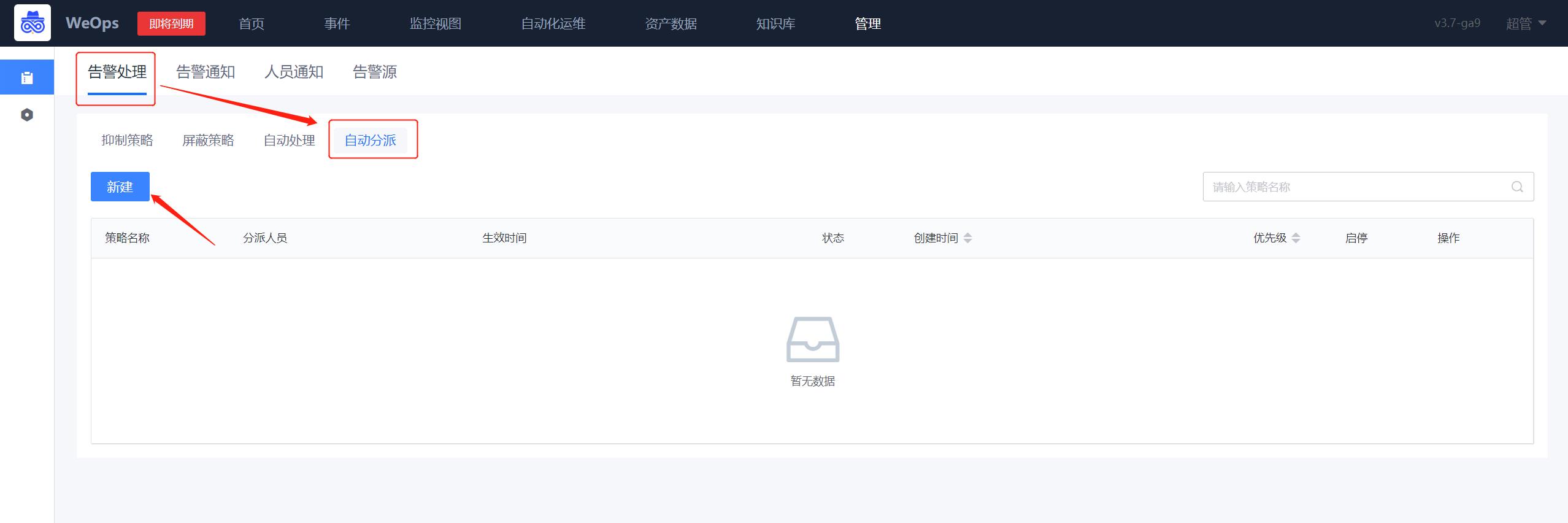
- 如下图所示,在第②步选择告警对象,若是不筛选实例则勾选【√不筛选实例】,若是需要筛选则按照第③步进行oracle主机的选择。随后按照第④步添加告警通知人员。在第⑤步选择“自定义通知方式-短信“。随后点击保存即可完成配置。

*分派策略优先级,同处理策略,优先级1~100,数字越小执行该条策略的优先级越靠前,相同优先级数字的策略,创建时间早的的优先级更靠前。
*优先执行告警处理策略,其后再执行告警分派策略。
*支持分派升级,当告警被分派,且分派用户在设定时间内未响应,可以升级分派给其他人,支持多级升级通知。还可设置分派通知规则,当告警未响应/未关闭时,重复通知给被分派用户。
*可设置通知频率,当告警未响应/未关闭时,重复发送通知。
人员通知
路径:管理-告警管理-人员通知
- 如下图,进入通知配置界面,选择对应的用户,点击“配置”按钮,可以进行通知方式的配置,可选“邮件、短信、微信、电话”等形式


2.3 动态分组配置
背景介绍:当监控策略的监控对象经常变动的时候,可以采用动态分组的方式,设置动态分组并设置监控策略。
分组设置
路径:管理-监控管理-动态分组
如下图,点击“新建“按钮,可以针对不同的对象,设置不同的分组条件。设置完成后,符合添加的对象会动态展示,一旦对象发生变化,该动态分组也会发生变化

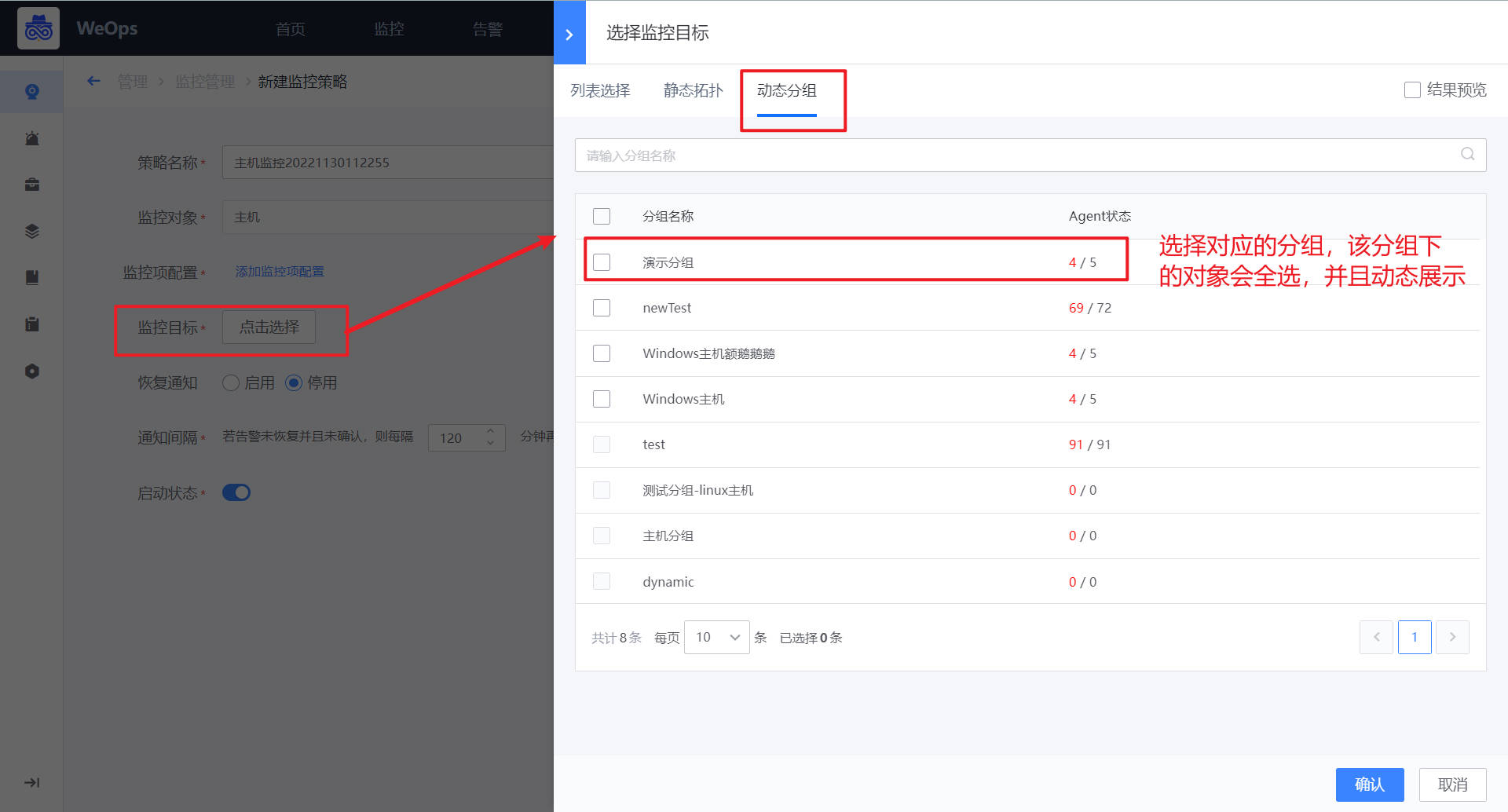
分组效果
路径:管理-监控管理-监控策略
如下图,在监控策略中,选择监控目标的时候,可以选择该分组,当对象发生变化的时候,动态分组里面的对象也会对应变化,保证该监控策略始终监控的是符合条件的对象。
2.4 监控指标配置
2.4.1 监控指标通用配置
背景介绍:监控对象已经纳管进来,并进行监控指标采集,需要对监控指标进行管理和分组,便于在监控视图中更方便的查看各个指标视图。
指标管理设置
路径:管理-监控管理-指标管理
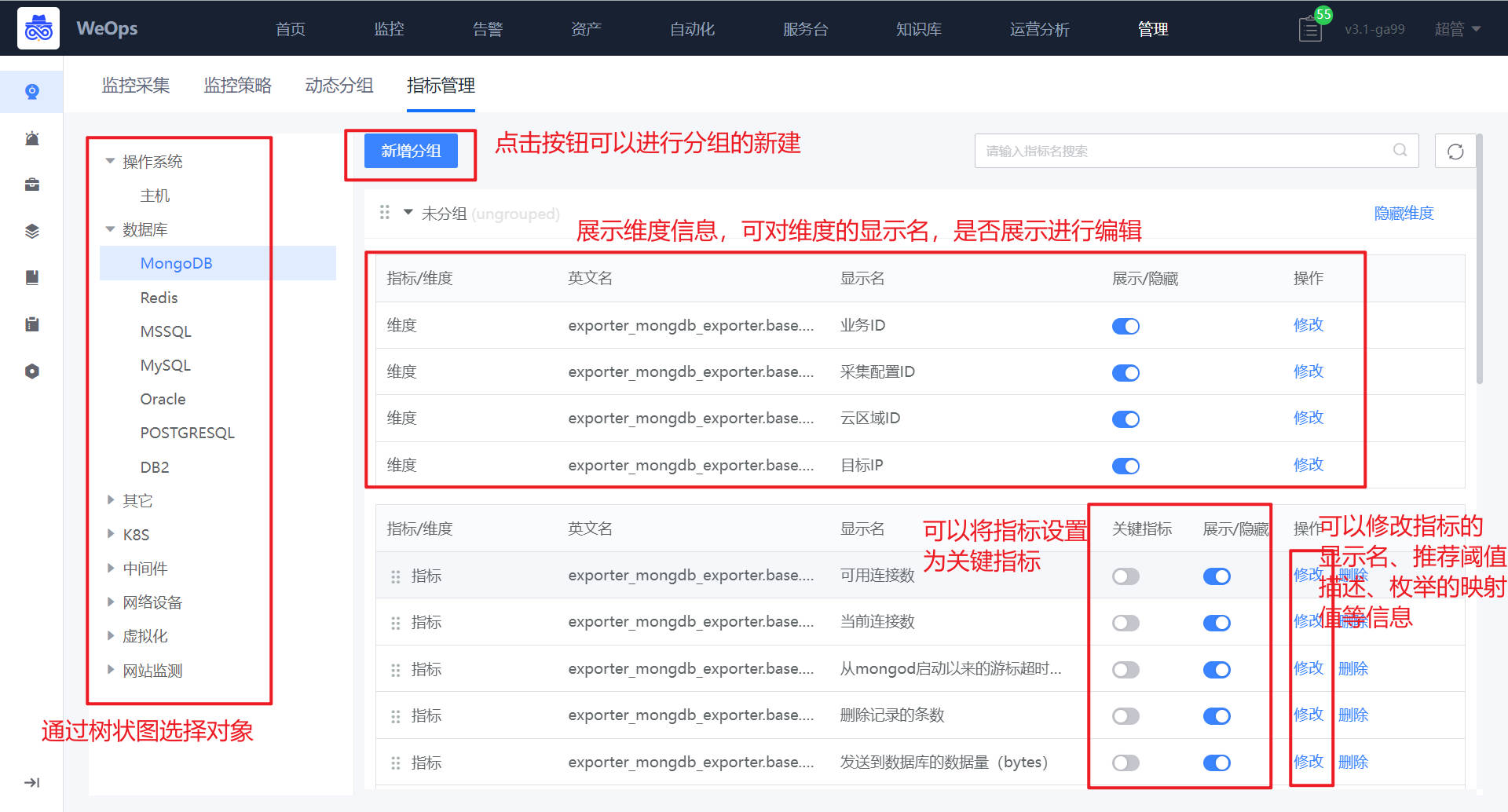
如下图可以对指标的分组、设置关键指标、指标内容等方面的设置/编辑
指标分组:针对不同对象可以进行指标分组新建,分组创建完成后,可以通过拖拽的方式把指标拖拽至对应分组中。
设置关键指标:可以将指标设置为“关键指标”,设置成功后,在监控视图的顶端就可以看到“关键指标”的分组。
指标编辑:支持对指标的显示名、分组、推荐阈值和描述进行编辑,可以修改指标类型,对于枚举值的指标可以设置映射值,设置成功后可以在对应的监控视图看到设置的映射值。
指标维度:展示对应指标的维度,可以对维度的显示名,是否显示等进行编辑
指标视图展示
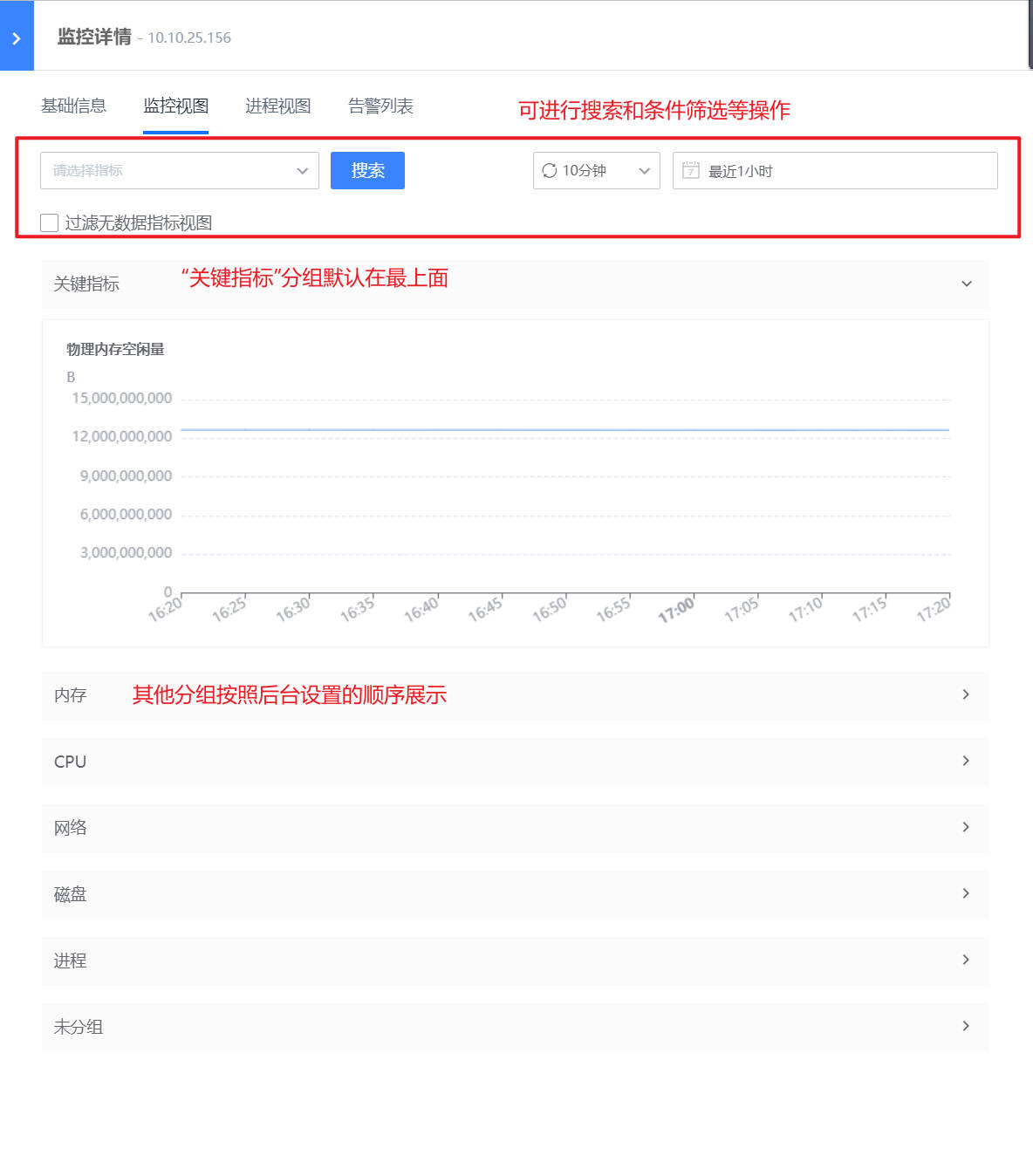
路径:监控视图-应用/基础监控-主机/数据库/中间件等
如下图,指标管理配置完成后,在“监控视图-应用/基础监控”中的监控视图抽屉中,可以看到分组后的监控视图。
关键指标:标为关键指标的指标,在监控视图中的顶端可以看到“关键指标”的分组以及对应指标视图
指标分组:按照后台设置的分组情况进行展示,可进行搜索和条件筛选等操作
2.4.2 自定义监控插件(脚本插件)
背景介绍:脚本的是一种灵活和快速的监控采集方式,不同层的监控对象都可以用本来完成。只要目标对象能够提供对应的脚本运行环境,就有对应的命令或脚本方法能够获取相应的指标数据; 此类型插件由于是调用已经封装好的命令,导致性能较低,采集耗时和资源占用多。
支持的脚本有:
Linux:Shell,Python
Windows:Shell,Python,PowerShell
脚本(Script)适用的对象有:操作系统、数据库、中间件
Step1:自定义插件制作
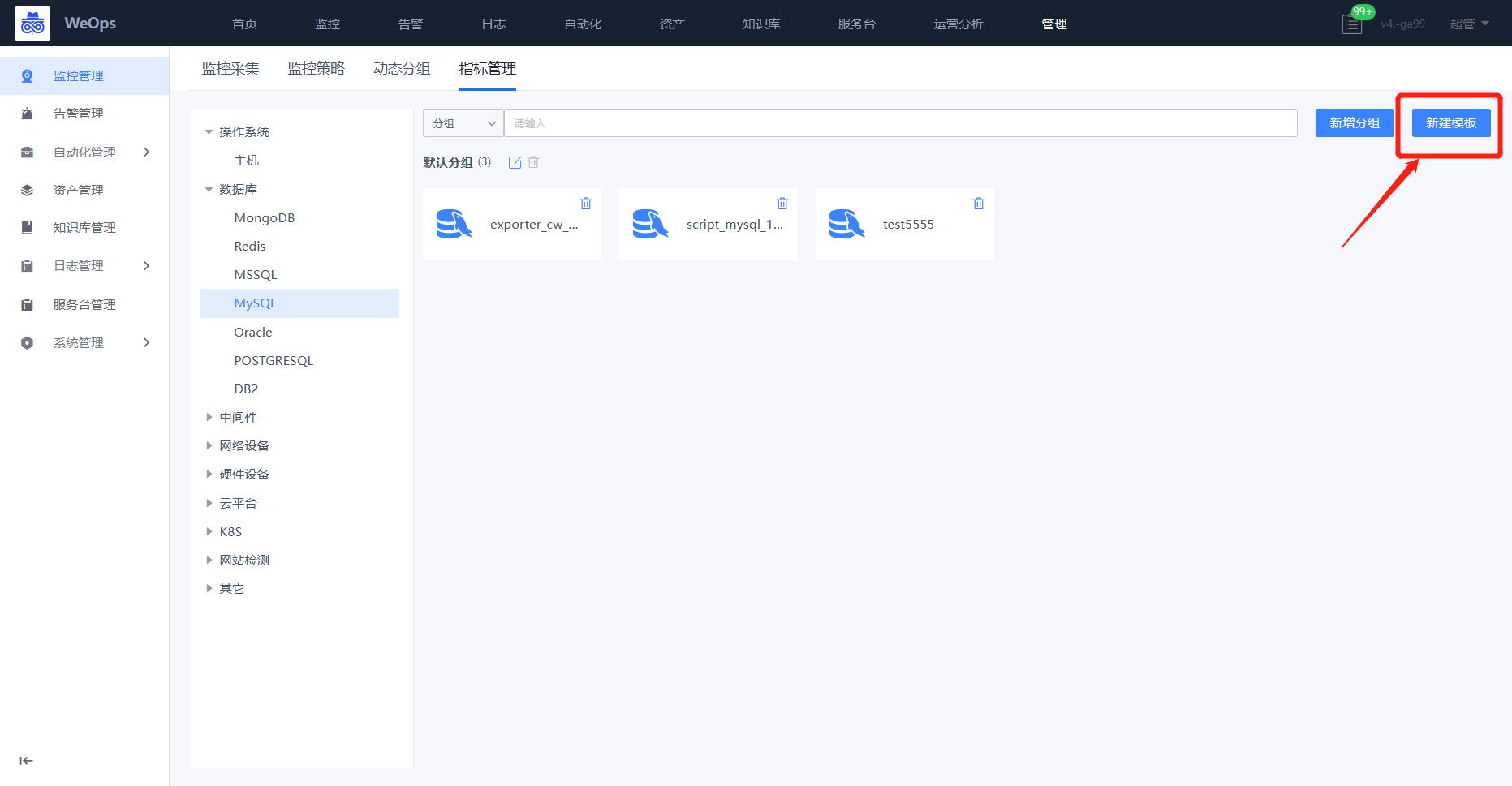
路径:管理-监控管理-监控指标-新建模板
如下图,点击“新建模板”,进入到插件定义页面,脚本插件的制作分为三步:插件定义、插件调试、编辑指标和维度等信息
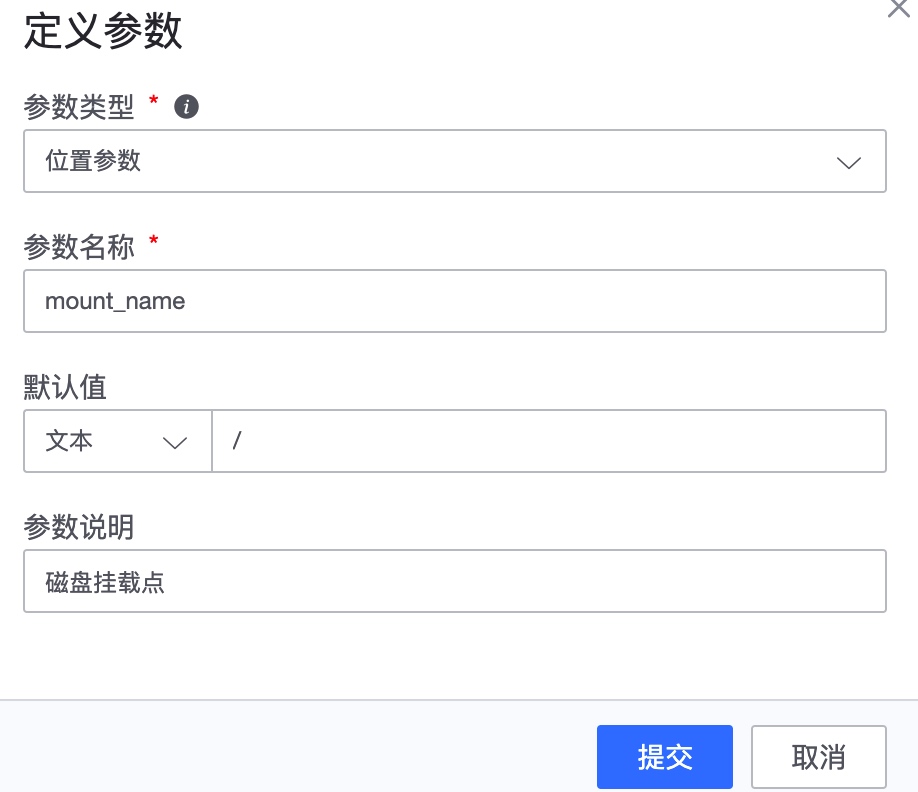
第一步,插件定义:如下图,需要填写插件基本信息、脚本内容、参数信息等。若需要定义监控采集时需要的参数,可以点击新增参数,并在脚本中用$1、$2来确定位置参数
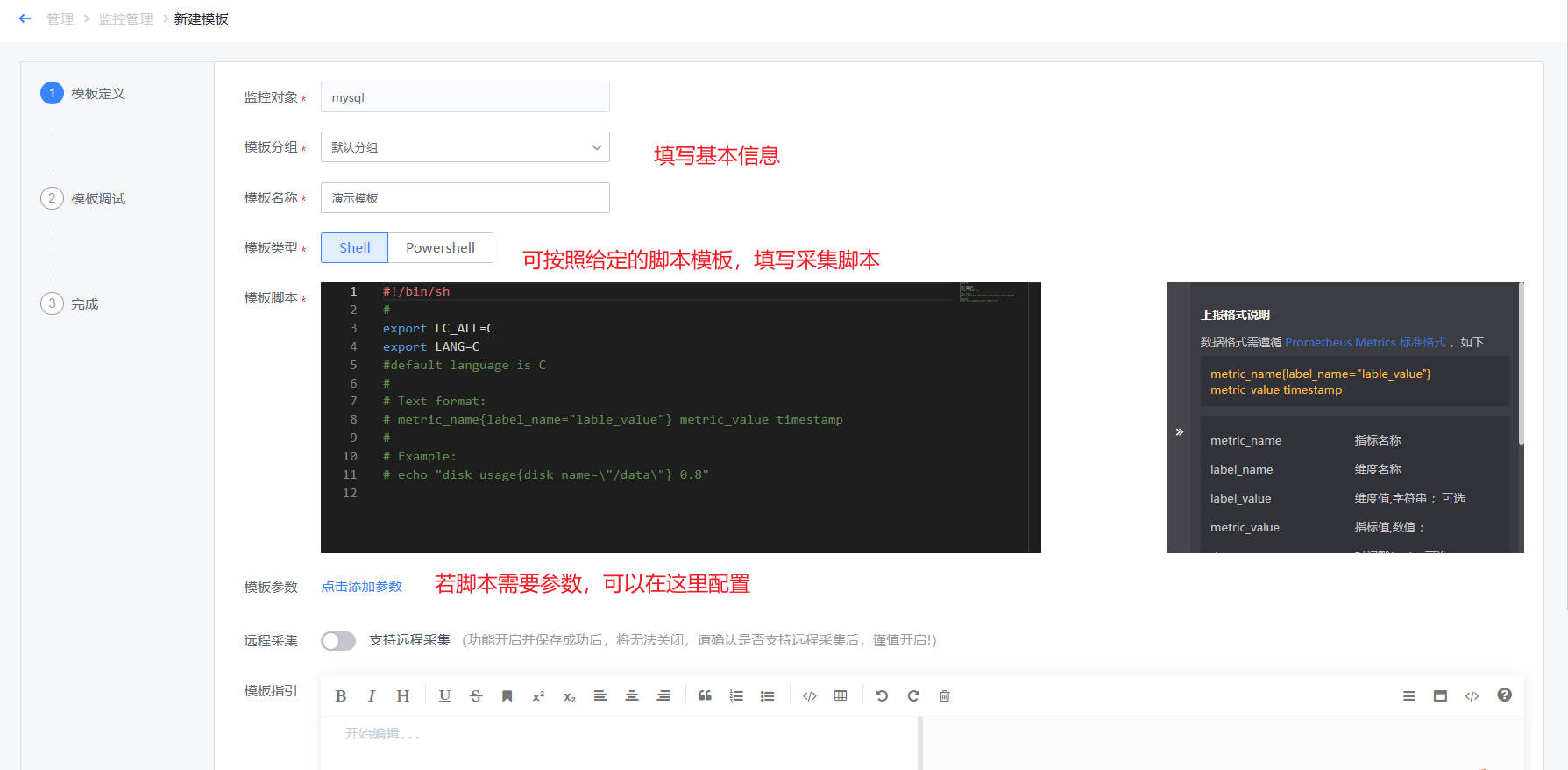
接下来以 磁盘使用率为例 为例实现脚本采集以及指标监控,脚本内容可参考如下脚本格式
#!/bin/bash
#获取磁盘使用率
disk_name="$1"
diskUsage=`df -h | grep ${disk_name} | awk -F '[ %]+' '{print $5}'`
echo "disk_usage{disk_name=\"${disk_name}\"} ${diskUsage}"
- 脚本参数,脚本中使用到的参数以$1、$2等来确定位置参数,并填写在参数定义中,以便后续下发时填写。
第二步,进行调试,这里的服务和下发都是测试联调的。填写的内容在后面的监控采集配置是一样的,主要就是为了验证插件制作是否合理,结果是否如预期。
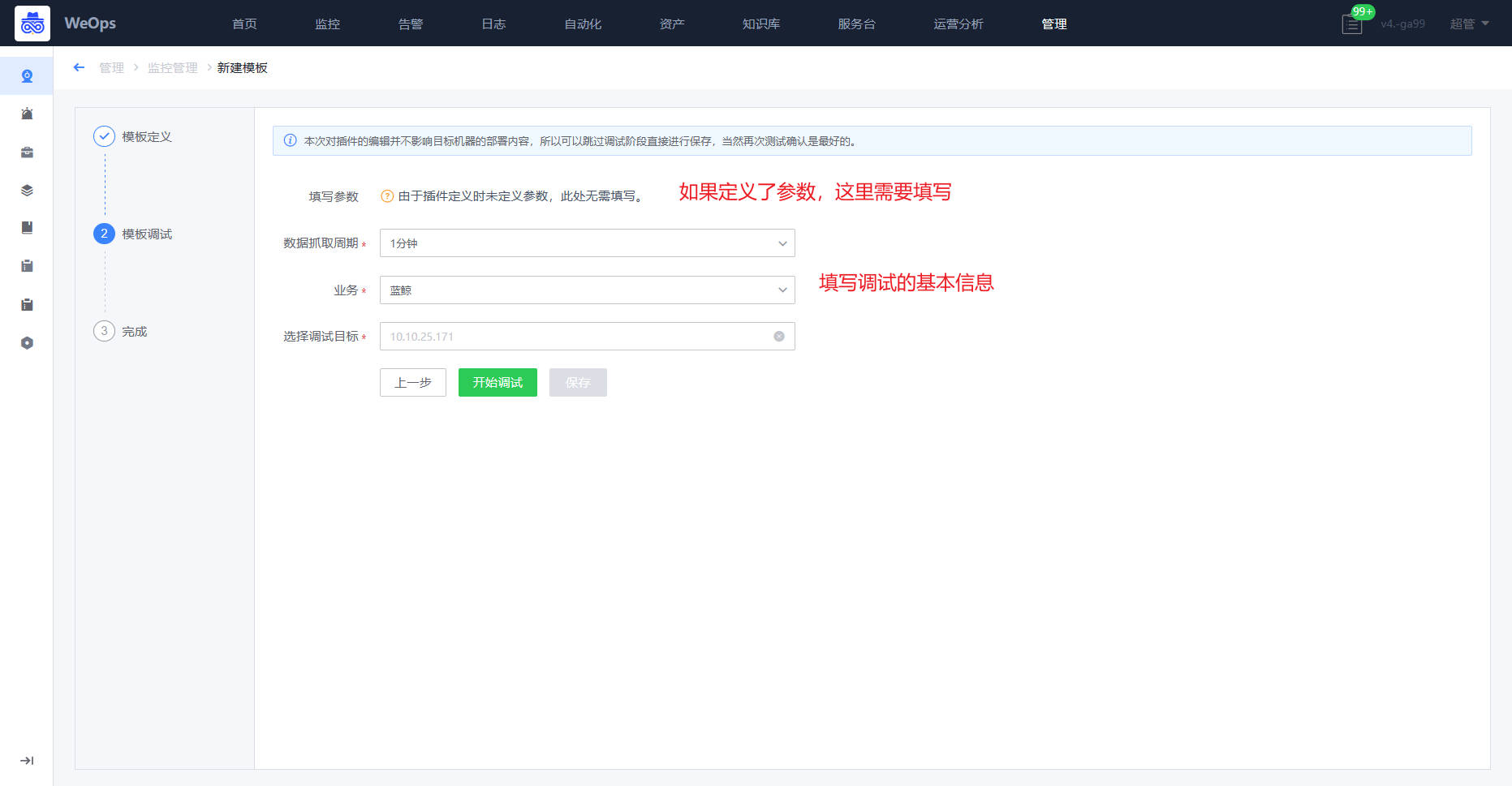
注意:整个调试过程超时时间为 600 秒,如果 600 秒内没有保存就会关闭这个调试过程,保证服务器上不会有残留的调试进程。
当联调获取到数据后会进行指标维度的设置确认。
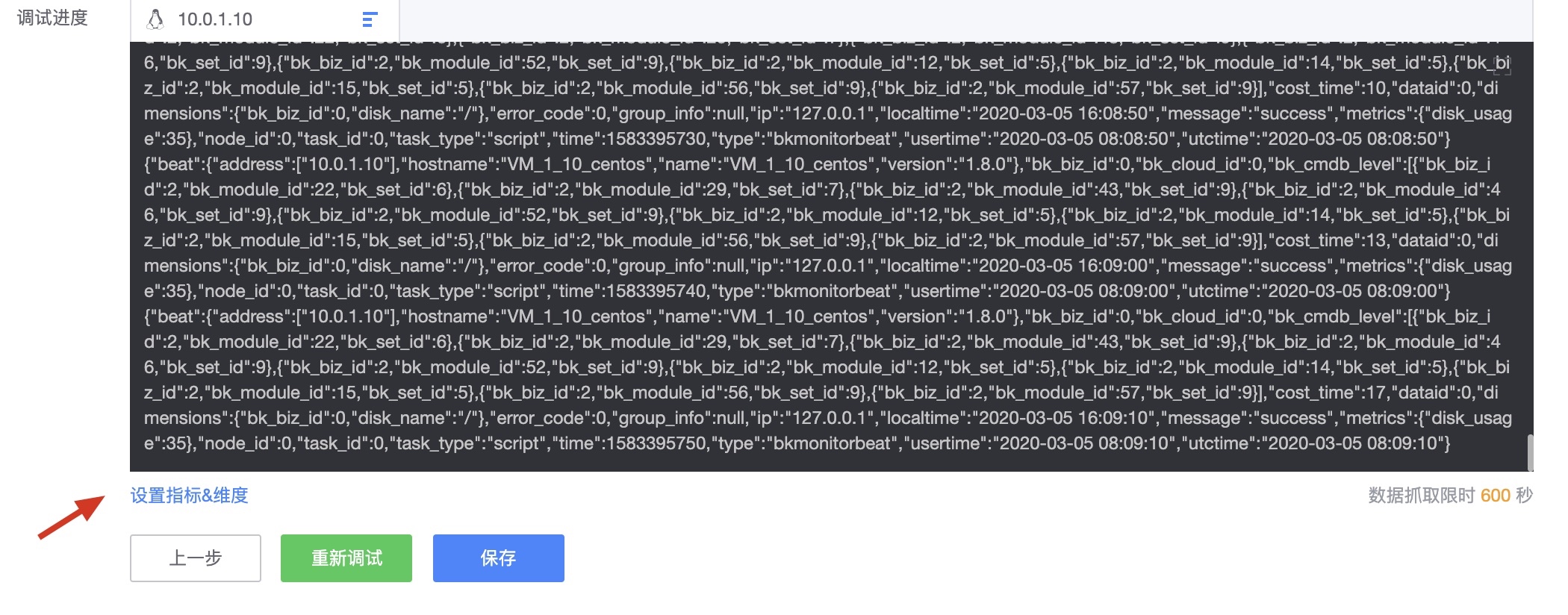
确认联调结果并设置指标和维度,WeOps可识别脚本中的指标和维度,可以进行编辑和设置,比如设置中文名称等。此外,支持数据预览,方便的看到调试获取的数据值是否符合预期
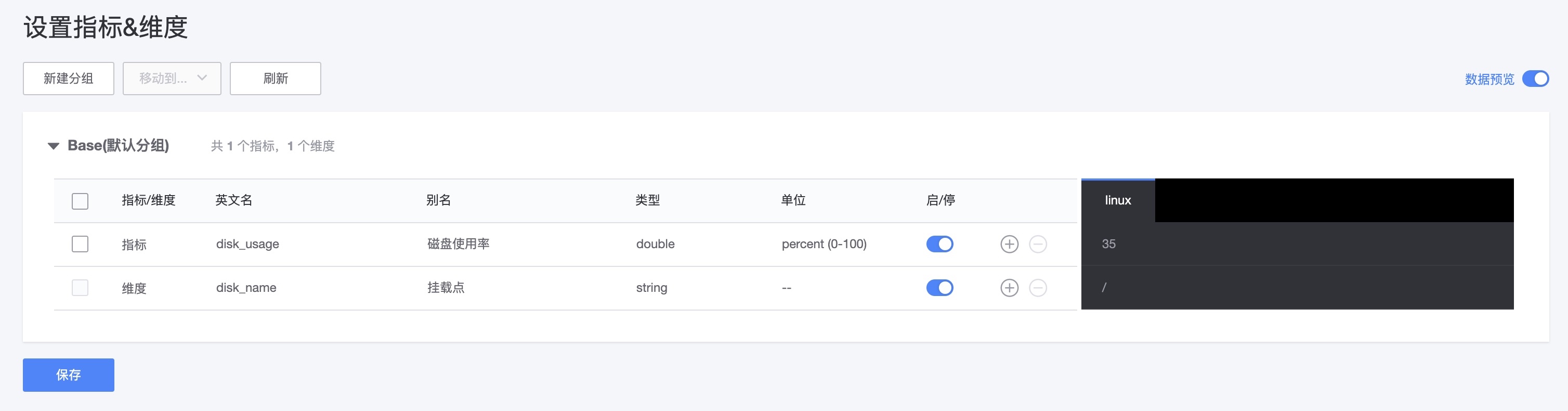
第三步,保存插件。后续可在监控采集中使用该监控插件进行采集
Step2:设置监控采集
路径:管理-监控管理-监控采集
自定义插件制作完成后,可以在“监控采集”中对监控目标进行监控插件的下发和采集。
Step3:设置监控数据呈现
路径:监控视图-仪表盘/基础监控
监控采集设置完成后,和内置的监控插件一样,监控数据就可以上报,在监控视图、仪表盘可以展示出该插件采集上来的数据。
2.4.3 自定义监控插件(JMX插件)
背景介绍:可以采集任何开启了JMX服务端口的Java进程的服务状态,通过JMX采集Java进程的JVM信息;使用前提目标对象能够支持远程JMX协议连接,配置JMX远程支持需要重启中间件。 适用于所有的Java类型中间件软件的监控,无需开发,仅需提供配置信息;
step1:开启 JMX 远程访问功能
java 默认自带的了 JMX RMI 的连接器。所以,只需要在启动 java 程序的时候带上运行参数,就可以开启 Agent 的 RMI 协议的连接器。
对于自研 java 程序,例如 java 程序为 app.jar,其启动命令为:
java -jar app.jar对于第三方组件:各个组件的远程 JMX 开启方式,请参考各组件文档。
检查是否启动成功
客户端可以通过以下 URL 去远程访问 JMX 服务。其中,hostName 为目标服务的主机名/IP,portNum 为以上配置的 jmxremote.port。
service:jmx:rmi:///jndi/rmi://${hostName}:${portNum}/jmxrmi
可通过以下两种方式检查是否已经配置成功:
1.简单地可通过检查端口是否存在,以及 PID 是否匹配,来确认 JMX 远程访问是否已经成功启动
netstat -anpt | grep ${portNum}
2.如果安装了 JConsole,也可直接连接测试
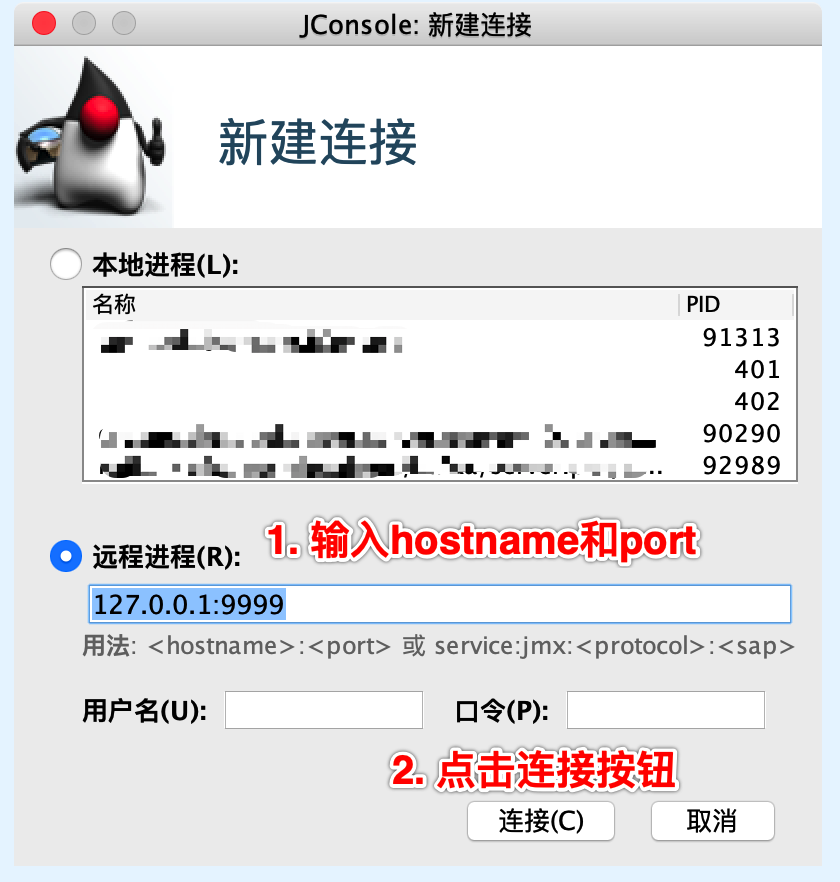
Step1:自定义插件制作
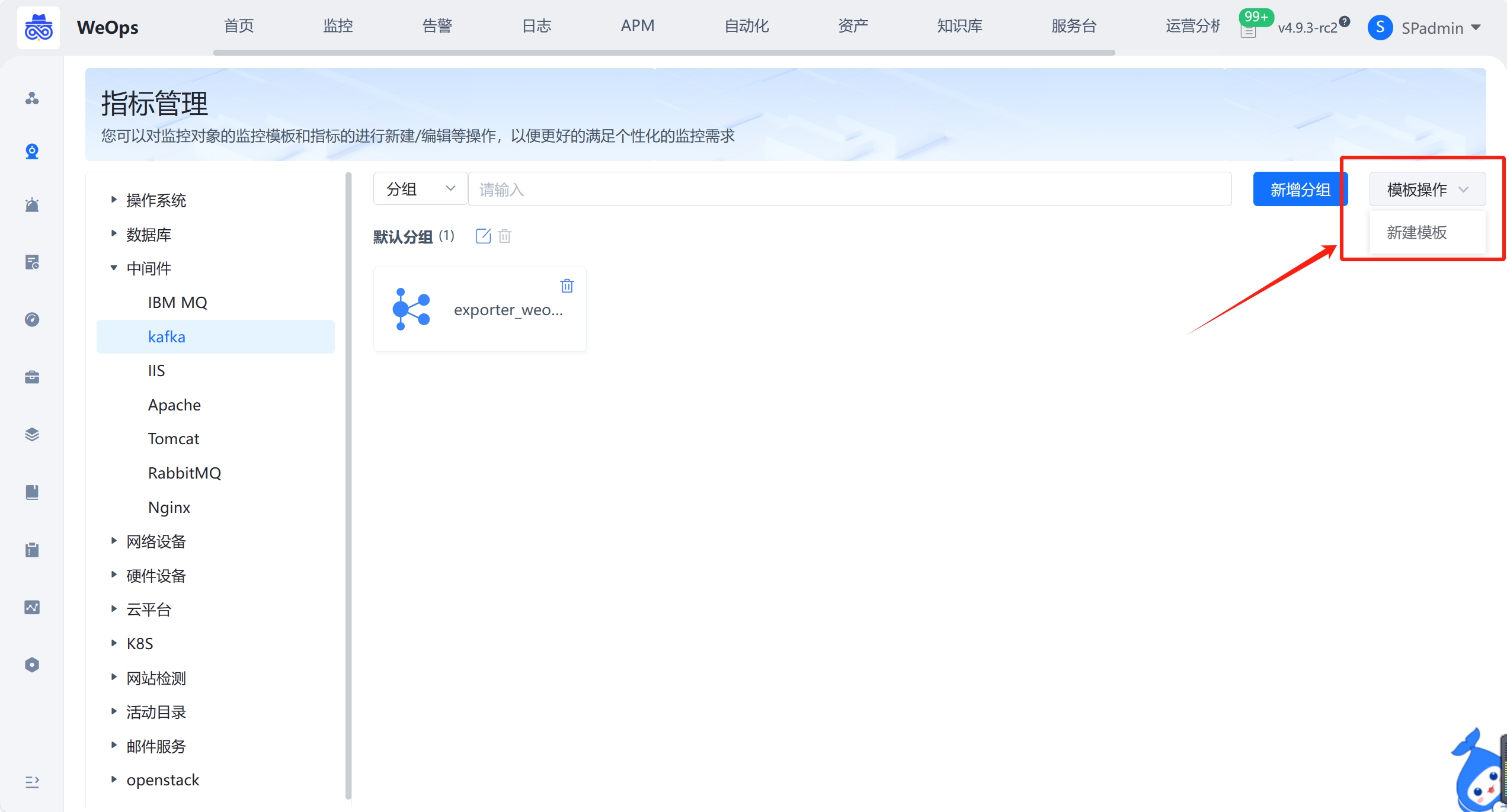
路径:管理-监控管理-监控指标-新建模板
如下图,点击“新建模板”,进入到插件定义页面,脚本插件的制作分为三步:插件定义、插件调试、编辑指标和维度等信息
- 第一步,模板定义,填写对应采集配置,可参考以下示例:
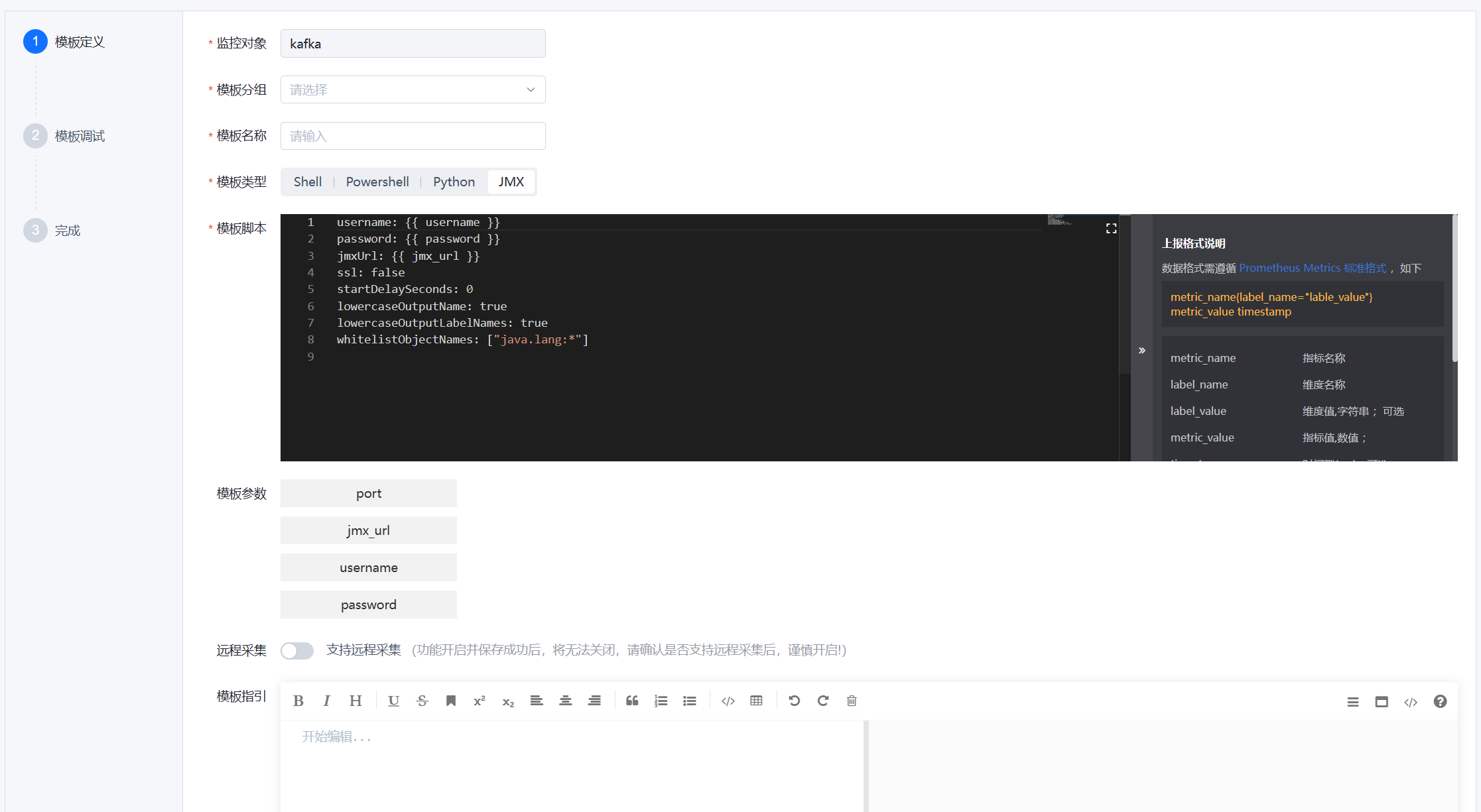
# ==== 固定配置开始 ====
username:
password:
jmxUrl:
ssl: false
# ==== 固定配置结束 ====
# ==== 自定义配置开始 ====
startDelaySeconds: 0
lowercaseOutputName: false
lowercaseOutputLabelNames: false
whitelistObjectNames: ["Catalina:*", "java.lang:*"]
blacklistObjectNames: ["Catalina:j2eeType=Servlet,*"]
rules:
- pattern: 'Catalina<type=ThreadPool, name="(\w+-\w+)-(\d+)"><>(currentThreadCount|currentThreadsBusy|keepAliveCount|pollerThreadCount|connectionCount):(.*)'
name: tomcat_threadpool_$3
value: $4
valueFactor: 1
labels:
port: "$2"
protocol: "$1"
自定义配置结束
- 固定配置都必须严格包含以下属性。否则将无法正确地进行指标采集。
username:
password:
jmxUrl:
ssl: false
- 自定义配置的字段的说明如下
| 字段名 | 含义 |
|---|---|
| startDelaySeconds | 启动延迟。延迟期内的任何请求都将返回空指标 |
| lowercaseOutputName | 小写输出指标名称。适用于 name。默认为 false |
| lowercaseOutputLabelNames | 小写输出指标的标签名称。适用于 labels。默认为 false |
| whitelistObjectNames | 要查询的 ObjectNames 列表。默认为所有 mBeans |
| blacklistObjectNames | 要查询的 ObjectNames 列表。优先级高于 whitelistObjectNames。默认为 none |
| rules | 要按顺序应用的规则列表,在第一个匹配到的规则处停止处理。不收集不匹配的属性。如果未指定,则默认以默认格式收集所有内容 |
| pattern | 用正则表达式模式匹配每个 bean 属性。匹配值(用小括号标识一个匹配值)可被其他选项引用,引用方式为$n(表示第 n 个匹配值)。默认为匹配所有内容 |
| name | 指标名称。可以引用来自 pattern 的匹配值。如果未指定,将使用默认格式:domainbeanPropertyValue1_key1_key2…keyN_attrName |
| value | 指标的值。可以使用静态值或引用来自 pattern 的匹配值。如果未指定,将使用 mBean 值 |
| valueFactor | 用于将指标的值 value 乘以该设置值,主要用于将 mBean 值从毫秒转换为秒。默认为 1 |
| labels | 标签名称到标签值的映射。可以引用来自 pattern 的匹配值。使用该参数必须先设置 name。如果使用了 name 但未指定该值,则不会输出任何标签 |
定义参数,JMX 插件不支持自定义参数,均为固定参数,各固定参数含义如下:
监听端口:JMX Exporter 启动时监听的 HTTP 端口,注意不是 JMX 端口
连接字符串:JMX RMI 的 URL,格式为 service:jmx:rmi:///jndi/rmi://${hostName}:${portNum}/jmxrmi。hostName 为目标服务的主机 IP,portNum 为 JMX 监听的端口号。将替换采集配置中的
用户名:若开启了用户认证,则需要输入,否则置空。将替换采集配置中的
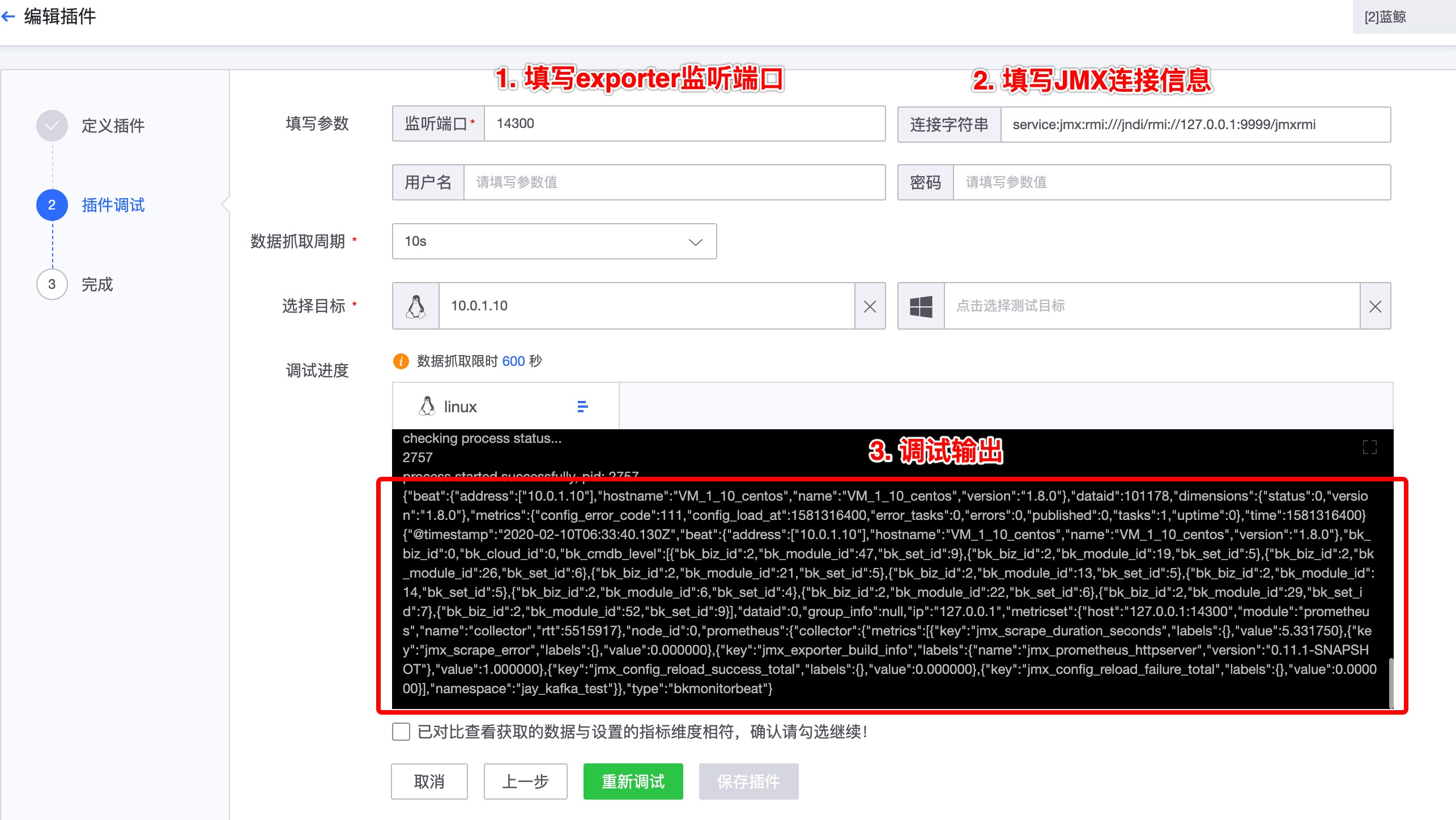
密码:若开启了用户认证,则需要输入,否则置空。将替换采集配置中的第二步,模板调试
填写相关参数,然后点击“开始调试”,稍等片刻后可查看调试输出。
指标维度,在插件调试获取到结果后,根据实际需要定义指标和维度。
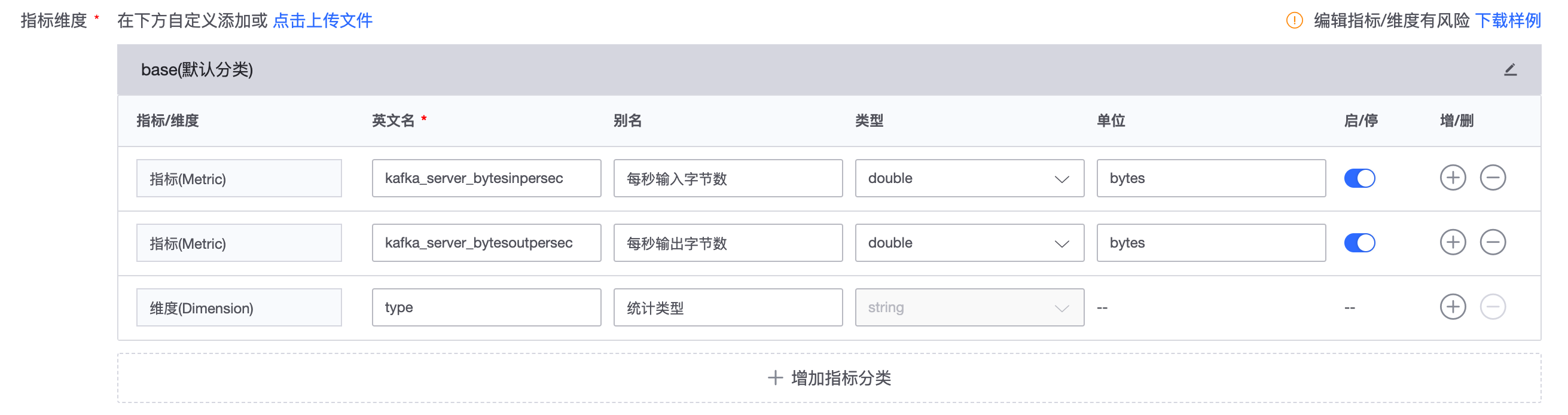
- 第三步,保存插件,调试并确认数据上报正常后,可进入下一步进行保存。自此,一个 JMX 插件即制作完成。
Step2:设置监控采集
路径:管理-监控管理-监控采集
自定义插件制作完成后,可以在“监控采集”中对监控目标进行监控插件的下发和采集。
Step3:设置监控数据呈现
路径:监控视图-仪表盘/基础监控
监控采集设置完成后,和内置的监控插件一样,监控数据就可以上报,在监控视图、仪表盘可以展示出该插件采集上来的数据。
2.4.4 自定义监控插件(snmp插件)
背景介绍:SNMP是一个被业界广泛接受的,用于监测网络设备(计算机、路由器)甚至其他设备(例如UPS)的网络协议,属于应用层协议。
使用前提:用户具备可用的MIB库和被监控设备的oid值,用于生成采集监控模板。OID:设备通用的SNMP标识,格式是一段数字如1.3.6.1,使用snmp协议并通过oid访问 设备,即可获取对应oid下的设备信息,如启动时间等。MIB库:各设备官方提供的 设备oid描述文件,可以根据该文件得到能够用于监控的oid以及oid的内容描述信息
SNMP模板的适用对象:网络设备、硬件设备
1:导入SNMP指标模板
路径:管理-监控管理-指标管理
如下图,在指标管理中,选择网络设备-交换机,点击导入模板,可以进行不同品牌和型号的指标模板导入(WeOps提供了网络设备指标模板导入的入口,可监控的设备品牌、型号等支持拓展。可直接使用WeOps产研提供的文件进行导入拓展)
2:创建SNMP指标模板
路径:管理-监控管理-指标管理
点击进行snmp模板的新建,对于snmp模板可以进行对应指标的新增,便于后续使用。
具体说明如下
(1)指标型:指标型指标是通过设备的OID(对象标识符)来采集设备的实际数值。所以当某个指标可以找到对应oid进行数据采集时,可以创建指标型指标进行采集。
(2)计算型:对指标型指标的数值进行计算得到的指标。计算型指标可以用于更细粒度地监控设备性能,在计算型指标的公式中,需要引用现有指标,可以采用(指标英文名{template_id})的格式进行引用,公式中固定变量“template_id”为指标所在的模板ID,固定不变。比如“irate(ifOutOctets{template_id}[5m])”。
Step2:监控采集
当需要监控的网络设备已经纳管,并且有适用的监控指标模板(可以是内置的,也可以是导入创建的),可以对网络设备进行监控采集的创建,选择对应的目标,适用的指标模板,并填写凭据信息。
如下图,监控采集创建完成以后,可以在监控视图中,查看对应监控对象的监控信息
Step3:监控策略配置(以交换机为例)
网络设备监控采集新建完成以后,可以网络设备进行监控策略的配置。
如下图,进入到监控策略页面,选择网络设备-交换机,点击“新建”按钮
- 在新建界面,策略名称、和监控对象已经默认填写。点击“选择监控目标”,进行监控对象的选择点击“添加监控项配置”,可进行监控项的选择和配置
- 监控策略配置完成后,若采集的监控数据超过设定的阈值,则按照致命/预警/提醒三个等级进行告警。
Step1:创建模板
Step2:创建模板